 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Guide Random Search
Apr 25, 2020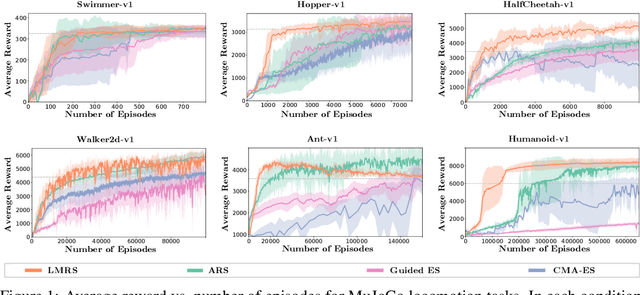
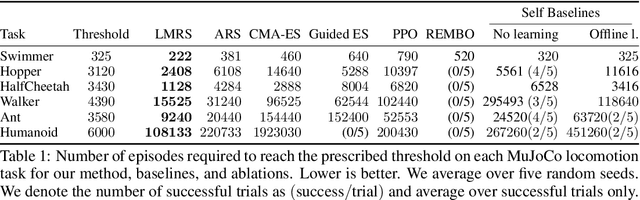
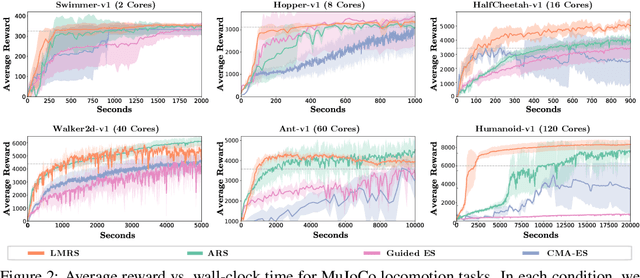

We are interested in derivative-free optimization of high-dimensional functions. The sample complexity of existing methods is high and depends on problem dimensionality, unlike the dimensionality-independent rates of first-order methods. The recent success of deep learning suggests that many datasets lie on low-dimensional manifolds that can be represented by deep nonlinear models. We therefore consider derivative-free optimization of a high-dimensional function that lies on a latent low-dimensional manifold. We develop an online learning approach that learns this manifold while performing the optimization. In other words, we jointly learn the manifold and optimize the function. Our analysis suggests that the presented method significantly reduces sample complexity. We empirically evaluate the method on continuous optimization benchmarks and high-dimensional continuous control problems. Our method achieves significantly lower sample complexity than Augmented Random Search, Bayesian optimization, covariance matrix adaptation (CMA-ES), and other derivative-free optimization algorithms.
Tracking Objects as Points
Apr 02, 2020
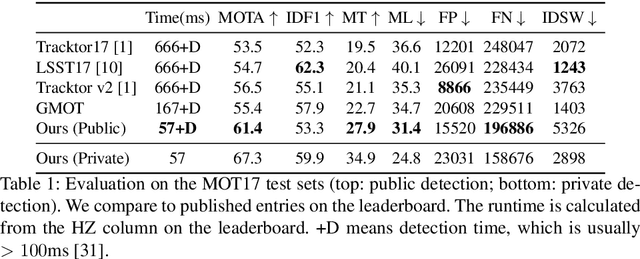

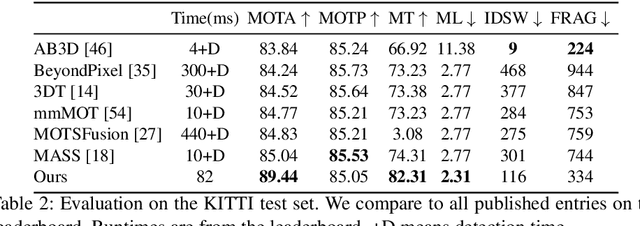
Tracking has traditionally been the art of following interest points through space and time. This changed with the rise of powerful deep networks. Nowadays, tracking is dominated by pipelines that perform object detection followed by temporal association, also known as tracking-by-detection. In this paper, we present a simultaneous detection and tracking algorithm that is simpler, faster, and more accurate than the state of the art. Our tracker, CenterTrack, applies a detection model to a pair of images and detections from the prior frame. Given this minimal input, CenterTrack localizes objects and predicts their associations with the previous frame. That's it. CenterTrack is simple, online (no peeking into the future), and real-time. It achieves 67.3% MOTA on the MOT17 challenge at 22 FPS and 89.4% MOTA on the KITTI tracking benchmark at 15 FPS, setting a new state of the art on both datasets. CenterTrack is easily extended to monocular 3D tracking by regressing additional 3D attributes. Using monocular video input, it achieves 28.3% AMOTA@0.2 on the newly released nuScenes 3D tracking benchmark, substantially outperforming the monocular baseline on this benchmark while running at 28 FPS.
Learning to Control PDEs with Differentiable Physics
Jan 21, 2020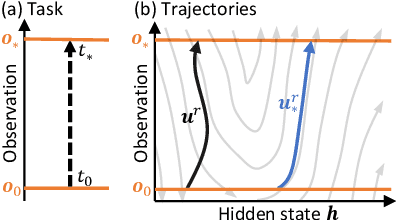

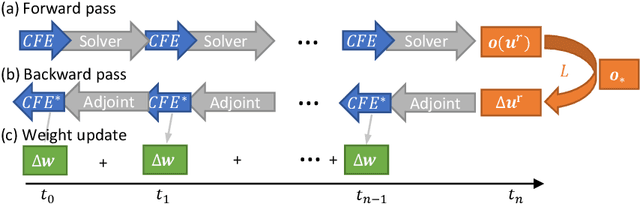
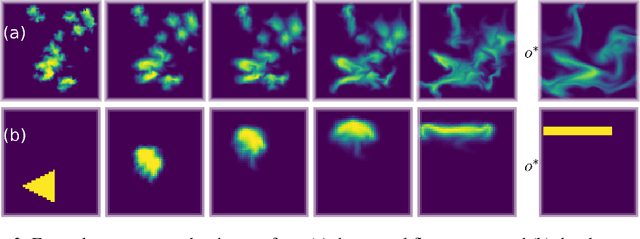
Predicting outcomes and planning interactions with the physical world are long-standing goals for machine learning. A variety of such tasks involves continuous physical systems, which can be described by partial differential equations (PDEs) with many degrees of freedom. Existing methods that aim to control the dynamics of such systems are typically limited to relatively short time frames or a small number of interaction parameters. We present a novel hierarchical predictor-corrector scheme which enables neural networks to learn to understand and control complex nonlinear physical systems over long time frames. We propose to split the problem into two distinct tasks: planning and control. To this end, we introduce a predictor network that plans optimal trajectories and a control network that infers the corresponding control parameters. Both stages are trained end-to-end using a differentiable PDE solver. We demonstrate that our method successfully develops an understanding of complex physical systems and learns to control them for tasks involving PDEs such as the incompressible Navier-Stokes equations.
Learning by Cheating
Dec 27, 2019



Vision-based urban driving is hard. The autonomous system needs to learn to perceive the world and act in it. We show that this challenging learning problem can be simplified by decomposing it into two stages. We first train an agent that has access to privileged information. This privileged agent cheats by observing the ground-truth layout of the environment and the positions of all traffic participants. In the second stage, the privileged agent acts as a teacher that trains a purely vision-based sensorimotor agent. The resulting sensorimotor agent does not have access to any privileged information and does not cheat. This two-stage training procedure is counter-intuitive at first, but has a number of important advantages that we analyze and empirically demonstrate. We use the presented approach to train a vision-based autonomous driving system that substantially outperforms the state of the art on the CARLA benchmark and the recent NoCrash benchmark. Our approach achieves, for the first time, 100% success rate on all tasks in the original CARLA benchmark, sets a new record on the NoCrash benchmark, and reduces the frequency of infractions by an order of magnitude compared to the prior state of the art. For the video that summarizes this work, see https://youtu.be/u9ZCxxD-UUw
Deep Equilibrium Models
Sep 03, 2019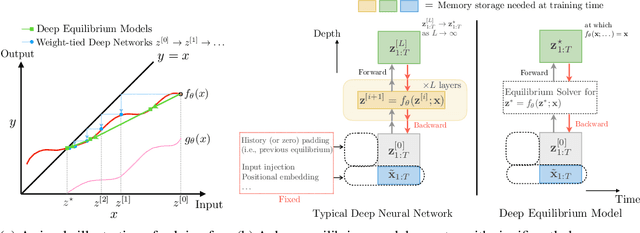

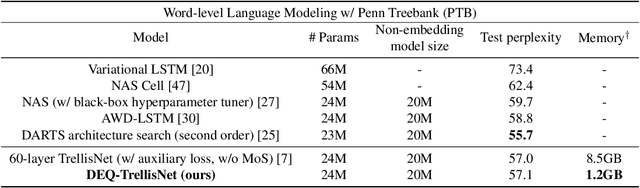
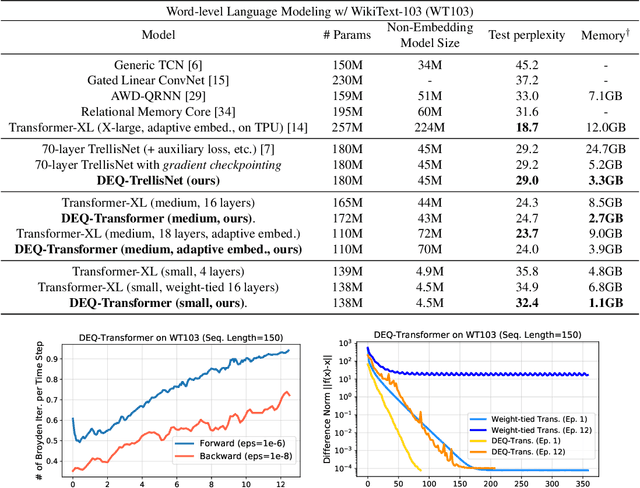
We present a new approach to modeling sequential data: the deep equilibrium model (DEQ). Motivated by an observation that the hidden layers of many existing deep sequence models converge towards some fixed point, we propose the DEQ approach that directly finds these equilibrium points via root-finding. Such a method is equivalent to running an infinite depth (weight-tied) feedforward network, but has the notable advantage that we can analytically backpropagate through the equilibrium point using implicit differentiation. Using this approach, training and prediction in these networks require only constant memory, regardless of the effective "depth" of the network. We demonstrate how DEQs can be applied to two state-of-the-art deep sequence models: self-attention transformers and trellis networks. On large-scale language modeling tasks, such as the WikiText-103 benchmark, we show that DEQs 1) often improve performance over these state-of-the-art models (for similar parameter counts); 2) have similar computational requirements as existing models; and 3) vastly reduce memory consumption (often the bottleneck for training large sequence models), demonstrating an up-to 88% memory reduction in our experiments. The code is available at https://github. com/locuslab/deq .
Consensus Maximization Tree Search Revisited
Aug 25, 2019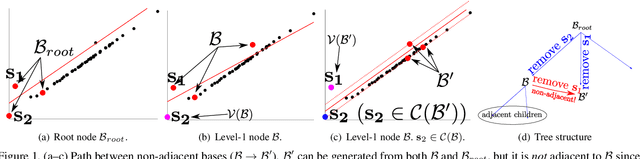

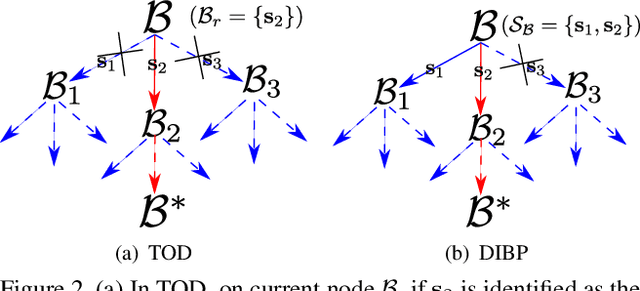

Consensus maximization is widely used for robust fitting in computer vision. However, solving it exactly, i.e., finding the globally optimal solution, is intractable. A* tree search, which has been shown to be fixed-parameter tractable, is one of the most efficient exact methods, though it is still limited to small inputs. We make two key contributions towards improving A* tree search. First, we show that the consensus maximization tree structure used previously actually contains paths that connect nodes at both adjacent and non-adjacent levels. Crucially, paths connecting non-adjacent levels are redundant for tree search, but they were not avoided previously. We propose a new acceleration strategy that avoids such redundant paths. In the second contribution, we show that the existing branch pruning technique also deteriorates quickly with the problem dimension. We then propose a new branch pruning technique that is less dimension-sensitive to address this issue. Experiments show that both new techniques can significantly accelerate A* tree search, making it reasonably efficient on inputs that were previously out of reach.
Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer
Jul 02, 2019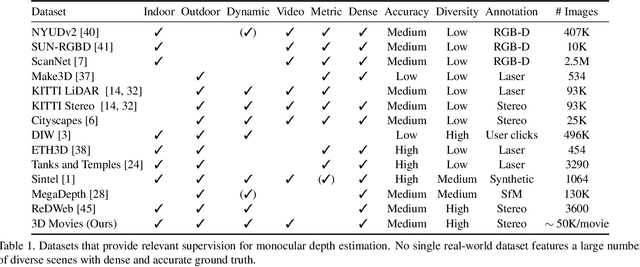

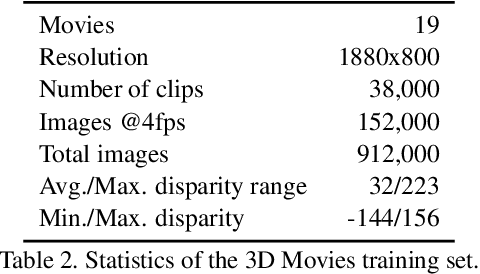
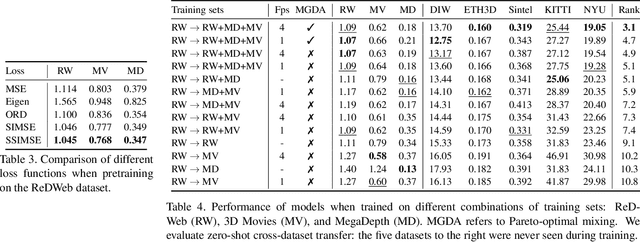
The success of monocular depth estimation relies on large and diverse training sets. Due to the challenges associated with acquiring dense ground-truth depth across different environments at scale, a number of datasets with distinct characteristics and biases have emerged. We develop tools that enable mixing multiple datasets during training, even if their annotations are incompatible. In particular, we propose a training objective that is invariant to changes in depth range and scale. Armed with this objective, we explore an abundant source of training data: 3D films. We demonstrate that despite pervasive inaccuracies, 3D films constitute a useful source of data that is complementary to existing training sets. We evaluate the presented approach on diverse datasets, focusing on zero-shot cross-dataset transfer: testing the generality of the learned model by evaluating it on datasets that were not seen during training. The experiments confirm that mixing data from complementary sources yields improved depth estimates, particularly on previously unseen datasets. Some results are shown in the supplementary video: https://youtu.be/ITI0YS6IrUQ
The Limited Multi-Label Projection Layer
Jun 22, 2019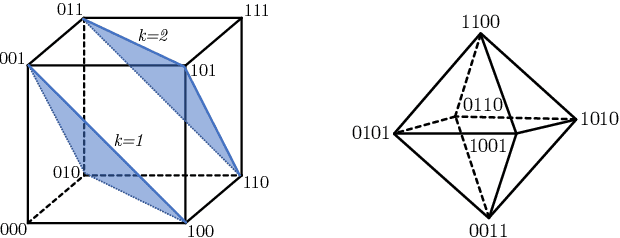
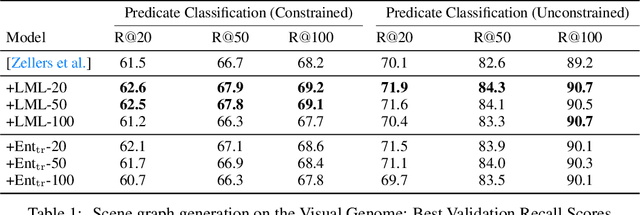
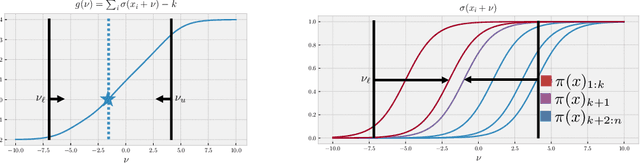
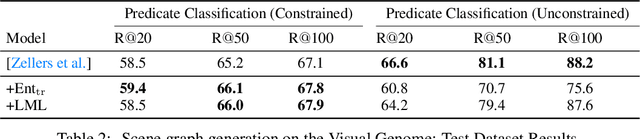
We propose the Limited Multi-Label (LML) projection layer as a new primitive operation for end-to-end learning systems. The LML layer provides a probabilistic way of modeling multi-label predictions limited to having exactly k labels. We derive efficient forward and backward passes for this layer and show how the layer can be used to optimize the top-k recall for multi-label tasks with incomplete label information. We evaluate LML layers on top-k CIFAR-100 classification and scene graph generation. We show that LML layers add a negligible amount of computational overhead, strictly improve the model's representational capacity, and improve accuracy. We also revisit the truncated top-k entropy method as a competitive baseline for top-k classification.
High Speed and High Dynamic Range Video with an Event Camera
Jun 15, 2019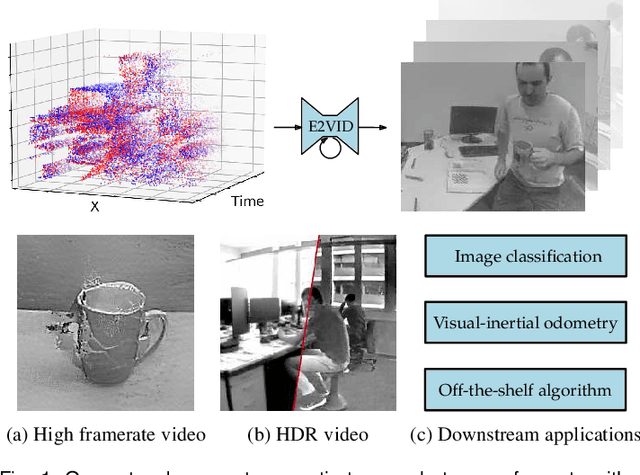
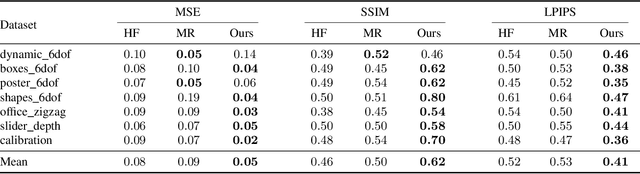
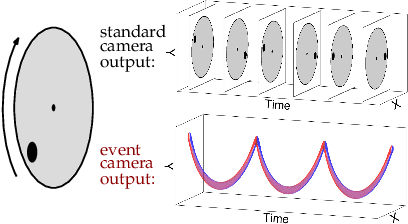
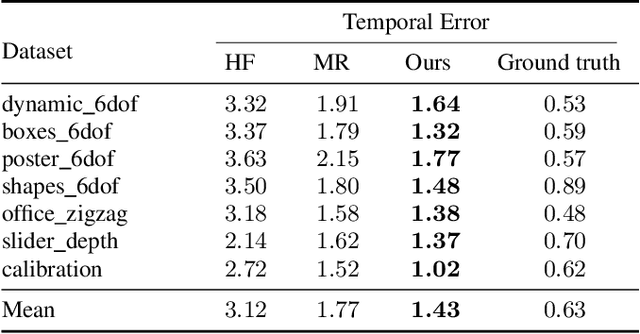
Event cameras are novel sensors that report brightness changes in the form of a stream of asynchronous "events" instead of intensity frames. They offer significant advantages with respect to conventional cameras: high temporal resolution, high dynamic range, and no motion blur. While the stream of events encodes in principle the complete visual signal, the reconstruction of an intensity image from a stream of events is an ill-posed problem in practice. Existing reconstruction approaches are based on hand-crafted priors and strong assumptions about the imaging process as well as the statistics of natural images. In this work we propose to learn to reconstruct intensity images from event streams directly from data instead of relying on any hand-crafted priors. We propose a novel recurrent network to reconstruct videos from a stream of events, and train it on a large amount of simulated event data. During training we propose to use a perceptual loss to encourage reconstructions to follow natural image statistics. We further extend our approach to synthesize color images from color event streams. Our network surpasses state-of-the-art reconstruction methods by a large margin in terms of image quality (> 20%), while comfortably running in real-time. We show that the network is able to synthesize high framerate videos (> 5,000 frames per second) of high-speed phenomena (e.g. a bullet hitting an object) and is able to provide high dynamic range reconstructions in challenging lighting conditions. We also demonstrate the effectiveness of our reconstructions as an intermediate representation for event data. We show that off-the-shelf computer vision algorithms can be applied to our reconstructions for tasks such as object classification and visual-inertial odometry and that this strategy consistently outperforms algorithms that were specifically designed for event data.
Does computer vision matter for action?
May 30, 2019Computer vision produces representations of scene content. Much computer vision research is predicated on the assumption that these intermediate representations are useful for action. Recent work at the intersection of machine learning and robotics calls this assumption into question by training sensorimotor systems directly for the task at hand, from pixels to actions, with no explicit intermediate representations. Thus the central question of our work: Does computer vision matter for action? We probe this question and its offshoots via immersive simulation, which allows us to conduct controlled reproducible experiments at scale. We instrument immersive three-dimensional environments to simulate challenges such as urban driving, off-road trail traversal, and battle. Our main finding is that computer vision does matter. Models equipped with intermediate representations train faster, achieve higher task performance, and generalize better to previously unseen environments. A video that summarizes the work and illustrates the results can be found at https://youtu.be/4MfWa2yZ0Jc
* Published in Science Robotics, 4(30), May 2019