 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressed Map Priors for 3D Perception
Dec 31, 2025Human drivers rarely travel where no person has gone before. After all, thousands of drivers use busy city roads every day, and only one can claim to be the first. The same holds for autonomous computer vision systems. The vast majority of the deployment area of an autonomous vision system will have been visited before. Yet, most autonomous vehicle vision systems act as if they are encountering each location for the first time. In this work, we present Compressed Map Priors (CMP), a simple but effective framework to learn spatial priors from historic traversals. The map priors use a binarized hashmap that requires only $32\text{KB}/\text{km}^2$, a $20\times$ reduction compared to the dense storage. Compressed Map Priors easily integrate into leading 3D perception systems at little to no extra computational costs, and lead to a significant and consistent improvement in 3D object detection on the nuScenes dataset across several architectures.
Cross-view Transformers for real-time Map-view Semantic Segmentation
May 05, 2022



We present cross-view transformers, an efficient attention-based model for map-view semantic segmentation from multiple cameras. Our architecture implicitly learns a mapping from individual camera views into a canonical map-view representation using a camera-aware cross-view attention mechanism. Each camera uses positional embeddings that depend on its intrinsic and extrinsic calibration. These embeddings allow a transformer to learn the mapping across different views without ever explicitly modeling it geometrically. The architecture consists of a convolutional image encoder for each view and cross-view transformer layers to infer a map-view semantic segmentation. Our model is simple, easily parallelizable, and runs in real-time. The presented architecture performs at state-of-the-art on the nuScenes dataset, with 4x faster inference speeds. Code is available at https://github.com/bradyz/cross_view_transformers.
Domain Adaptation Through Task Distillation
Aug 27, 2020
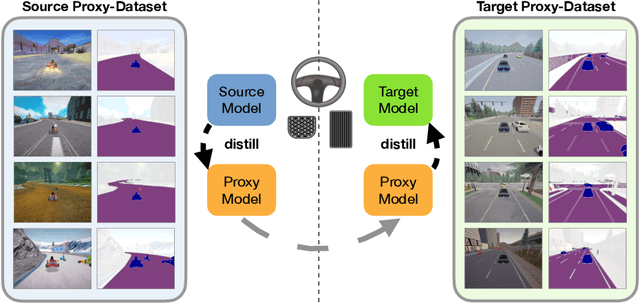

Deep networks devour millions of precisely annotated images to build their complex and powerful representations. Unfortunately, tasks like autonomous driving have virtually no real-world training data. Repeatedly crashing a car into a tree is simply too expensive. The commonly prescribed solution is simple: learn a representation in simulation and transfer it to the real world. However, this transfer is challenging since simulated and real-world visual experiences vary dramatically. Our core observation is that for certain tasks, such as image recognition, datasets are plentiful. They exist in any interesting domain, simulated or real, and are easy to label and extend. We use these recognition datasets to link up a source and target domain to transfer models between them in a task distillation framework. Our method can successfully transfer navigation policies between drastically different simulators: ViZDoom, SuperTuxKart, and CARLA. Furthermore, it shows promising results on standard domain adaptation benchmarks.
Learning by Cheating
Dec 27, 2019



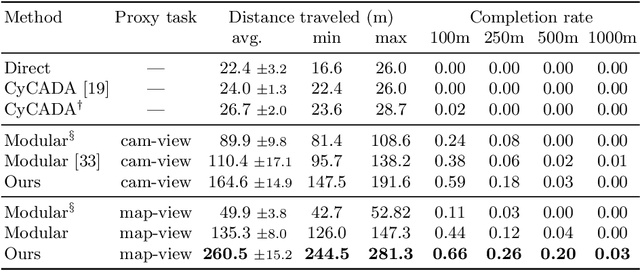
Vision-based urban driving is hard. The autonomous system needs to learn to perceive the world and act in it. We show that this challenging learning problem can be simplified by decomposing it into two stages. We first train an agent that has access to privileged information. This privileged agent cheats by observing the ground-truth layout of the environment and the positions of all traffic participants. In the second stage, the privileged agent acts as a teacher that trains a purely vision-based sensorimotor agent. The resulting sensorimotor agent does not have access to any privileged information and does not cheat. This two-stage training procedure is counter-intuitive at first, but has a number of important advantages that we analyze and empirically demonstrate. We use the presented approach to train a vision-based autonomous driving system that substantially outperforms the state of the art on the CARLA benchmark and the recent NoCrash benchmark. Our approach achieves, for the first time, 100% success rate on all tasks in the original CARLA benchmark, sets a new record on the NoCrash benchmark, and reduces the frequency of infractions by an order of magnitude compared to the prior state of the art. For the video that summarizes this work, see https://youtu.be/u9ZCxxD-UUw
Does computer vision matter for action?
May 30, 2019Computer vision produces representations of scene content. Much computer vision research is predicated on the assumption that these intermediate representations are useful for action. Recent work at the intersection of machine learning and robotics calls this assumption into question by training sensorimotor systems directly for the task at hand, from pixels to actions, with no explicit intermediate representations. Thus the central question of our work: Does computer vision matter for action? We probe this question and its offshoots via immersive simulation, which allows us to conduct controlled reproducible experiments at scale. We instrument immersive three-dimensional environments to simulate challenges such as urban driving, off-road trail traversal, and battle. Our main finding is that computer vision does matter. Models equipped with intermediate representations train faster, achieve higher task performance, and generalize better to previously unseen environments. A video that summarizes the work and illustrates the results can be found at https://youtu.be/4MfWa2yZ0Jc
* Published in Science Robotics, 4(30), May 2019