 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-environment lifelong deep reinforcement learning for medical imaging
May 31, 2023Deep reinforcement learning(DRL) is increasingly being explored in medical imaging. However, the environments for medical imaging tasks are constantly evolving in terms of imaging orientations, imaging sequences, and pathologies. To that end, we developed a Lifelong DRL framework, SERIL to continually learn new tasks in changing imaging environments without catastrophic forgetting. SERIL was developed using selective experience replay based lifelong learning technique for the localization of five anatomical landmarks in brain MRI on a sequence of twenty-four different imaging environments. The performance of SERIL, when compared to two baseline setups: MERT(multi-environment-best-case) and SERT(single-environment-worst-case) demonstrated excellent performance with an average distance of $9.90\pm7.35$ pixels from the desired landmark across all 120 tasks, compared to $10.29\pm9.07$ for MERT and $36.37\pm22.41$ for SERT($p<0.05$), demonstrating the excellent potential for continuously learning multiple tasks across dynamically changing imaging environments.
AutoCoreset: An Automatic Practical Coreset Construction Framework
May 19, 2023



A coreset is a tiny weighted subset of an input set, that closely resembles the loss function, with respect to a certain set of queries. Coresets became prevalent in machine learning as they have shown to be advantageous for many applications. While coreset research is an active research area, unfortunately, coresets are constructed in a problem-dependent manner, where for each problem, a new coreset construction algorithm is usually suggested, a process that may take time or may be hard for new researchers in the field. Even the generic frameworks require additional (problem-dependent) computations or proofs to be done by the user. Besides, many problems do not have (provable) small coresets, limiting their applicability. To this end, we suggest an automatic practical framework for constructing coresets, which requires (only) the input data and the desired cost function from the user, without the need for any other task-related computation to be done by the user. To do so, we reduce the problem of approximating a loss function to an instance of vector summation approximation, where the vectors we aim to sum are loss vectors of a specific subset of the queries, such that we aim to approximate the image of the function on this subset. We show that while this set is limited, the coreset is quite general. An extensive experimental study on various machine learning applications is also conducted. Finally, we provide a ``plug and play" style implementation, proposing a user-friendly system that can be easily used to apply coresets for many problems. Full open source code can be found at \href{https://github.com/alaamaalouf/AutoCoreset}{\text{https://github.com/alaamaalouf/AutoCoreset}}. We believe that these contributions enable future research and easier use and applications of coresets.
Implicit Bias of Gradient Descent for Logistic Regression at the Edge of Stability
May 19, 2023


Recent research has observed that in machine learning optimization, gradient descent (GD) often operates at the edge of stability (EoS) [Cohen, et al., 2021], where the stepsizes are set to be large, resulting in non-monotonic losses induced by the GD iterates. This paper studies the convergence and implicit bias of constant-stepsize GD for logistic regression on linearly separable data in the EoS regime. Despite the presence of local oscillations, we prove that the logistic loss can be minimized by GD with any constant stepsize over a long time scale. Furthermore, we prove that with any constant stepsize, the GD iterates tend to infinity when projected to a max-margin direction (the hard-margin SVM direction) and converge to a fixed vector that minimizes a strongly convex potential when projected to the orthogonal complement of the max-margin direction. In contrast, we also show that in the EoS regime, GD iterates may diverge catastrophically under the exponential loss, highlighting the superiority of the logistic loss. These theoretical findings are in line with numerical simulations and complement existing theories on the convergence and implicit bias of GD, which are only applicable when the stepsizes are sufficiently small.
Fixed Design Analysis of Regularization-Based Continual Learning
Mar 17, 2023We consider a continual learning (CL) problem with two linear regression tasks in the fixed design setting, where the feature vectors are assumed fixed and the labels are assumed to be random variables. We consider an $\ell_2$-regularized CL algorithm, which computes an Ordinary Least Squares parameter to fit the first dataset, then computes another parameter that fits the second dataset under an $\ell_2$-regularization penalizing its deviation from the first parameter, and outputs the second parameter. For this algorithm, we provide tight bounds on the average risk over the two tasks. Our risk bounds reveal a provable trade-off between forgetting and intransigence of the $\ell_2$-regularized CL algorithm: with a large regularization parameter, the algorithm output forgets less information about the first task but is intransigent to extract new information from the second task; and vice versa. Our results suggest that catastrophic forgetting could happen for CL with dissimilar tasks (under a precise similarity measurement) and that a well-tuned $\ell_2$-regularization can partially mitigate this issue by introducing intransigence.
Asynchronous Decentralized Federated Lifelong Learning for Landmark Localization in Medical Imaging
Mar 12, 2023



Federated learning is a recent development in the machine learning area that allows a system of devices to train on one or more tasks without sharing their data to a single location or device. However, this framework still requires a centralized global model to consolidate individual models into one, and the devices train synchronously, which both can be potential bottlenecks for using federated learning. In this paper, we propose a novel method of asynchronous decentralized federated lifelong learning (ADFLL) method that inherits the merits of federated learning and can train on multiple tasks simultaneously without the need for a central node or synchronous training. Thus, overcoming the potential drawbacks of conventional federated learning. We demonstrate excellent performance on the brain tumor segmentation (BRATS) dataset for localizing the left ventricle on multiple image sequences and image orientation. Our framework allows agents to achieve the best performance with a mean distance error of 7.81, better than the conventional all-knowing agent's mean distance error of 11.78, and significantly (p=0.01) better than a conventional lifelong learning agent with a distance error of 15.17 after eight rounds of training. In addition, all ADFLL agents have comparable or better performance than a conventional LL agent. In conclusion, we developed an ADFLL framework with excellent performance and speed-up compared to conventional RL agents.
Provable Data Subset Selection For Efficient Neural Network Training
Mar 09, 2023



Radial basis function neural networks (\emph{RBFNN}) are {well-known} for their capability to approximate any continuous function on a closed bounded set with arbitrary precision given enough hidden neurons. In this paper, we introduce the first algorithm to construct coresets for \emph{RBFNNs}, i.e., small weighted subsets that approximate the loss of the input data on any radial basis function network and thus approximate any function defined by an \emph{RBFNN} on the larger input data. In particular, we construct coresets for radial basis and Laplacian loss functions. We then use our coresets to obtain a provable data subset selection algorithm for training deep neural networks. Since our coresets approximate every function, they also approximate the gradient of each weight in a neural network, which is a particular function on the input. We then perform empirical evaluations on function approximation and dataset subset selection on popular network architectures and data sets, demonstrating the efficacy and accuracy of our coreset construction.
Learning High-Dimensional Single-Neuron ReLU Networks with Finite Samples
Mar 03, 2023This paper considers the problem of learning a single ReLU neuron with squared loss (a.k.a., ReLU regression) in the overparameterized regime, where the input dimension can exceed the number of samples. We analyze a Perceptron-type algorithm called GLM-tron (Kakade et al., 2011), and provide its dimension-free risk upper bounds for high-dimensional ReLU regression in both well-specified and misspecified settings. Our risk bounds recover several existing results as special cases. Moreover, in the well-specified setting, we also provide an instance-wise matching risk lower bound for GLM-tron. Our upper and lower risk bounds provide a sharp characterization of the high-dimensional ReLU regression problems that can be learned via GLM-tron. On the other hand, we provide some negative results for stochastic gradient descent (SGD) for ReLU regression with symmetric Bernoulli data: if the model is well-specified, the excess risk of SGD is provably no better than that of GLM-tron ignoring constant factors, for each problem instance; and in the noiseless case, GLM-tron can achieve a small risk while SGD unavoidably suffers from a constant risk in expectation. These results together suggest that GLM-tron might be preferable than SGD for high-dimensional ReLU regression.
Selective experience replay compression using coresets for lifelong deep reinforcement learning in medical imaging
Feb 25, 2023Selective experience replay is a popular strategy for integrating lifelong learning with deep reinforcement learning. Selective experience replay aims to recount selected experiences from previous tasks to avoid catastrophic forgetting. Furthermore, selective experience replay based techniques are model agnostic and allow experiences to be shared across different models. However, storing experiences from all previous tasks make lifelong learning using selective experience replay computationally very expensive and impractical as the number of tasks increase. To that end, we propose a reward distribution-preserving coreset compression technique for compressing experience replay buffers stored for selective experience replay. We evaluated the coreset compression technique on the brain tumor segmentation (BRATS) dataset for the task of ventricle localization and on the whole-body MRI for localization of left knee cap, left kidney, right trochanter, left lung, and spleen. The coreset lifelong learning models trained on a sequence of 10 different brain MR imaging environments demonstrated excellent performance localizing the ventricle with a mean pixel error distance of 12.93 for the compression ratio of 10x. In comparison, the conventional lifelong learning model localized the ventricle with a mean pixel distance of 10.87. Similarly, the coreset lifelong learning models trained on whole-body MRI demonstrated no significant difference (p=0.28) between the 10x compressed coreset lifelong learning models and conventional lifelong learning models for all the landmarks. The mean pixel distance for the 10x compressed models across all the landmarks was 25.30, compared to 19.24 for the conventional lifelong learning models. Our results demonstrate that the potential of the coreset-based ERB compression method for compressing experiences without a significant drop in performance.
From Local to Global: Spectral-Inspired Graph Neural Networks
Sep 24, 2022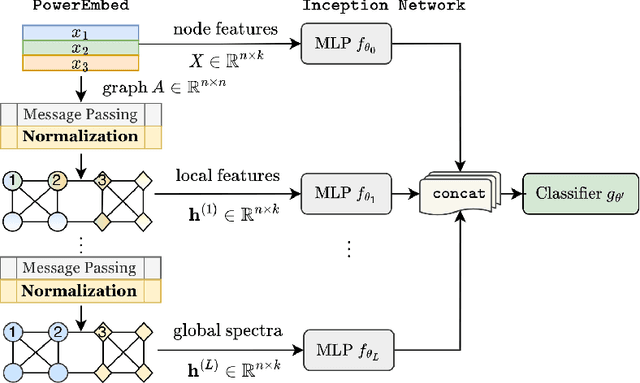
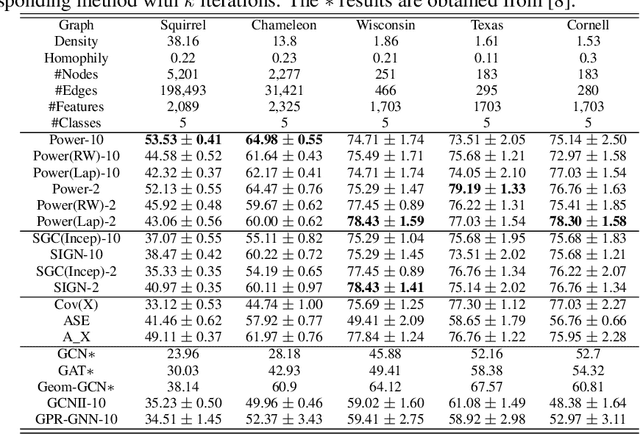
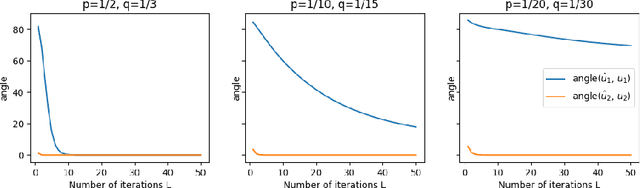
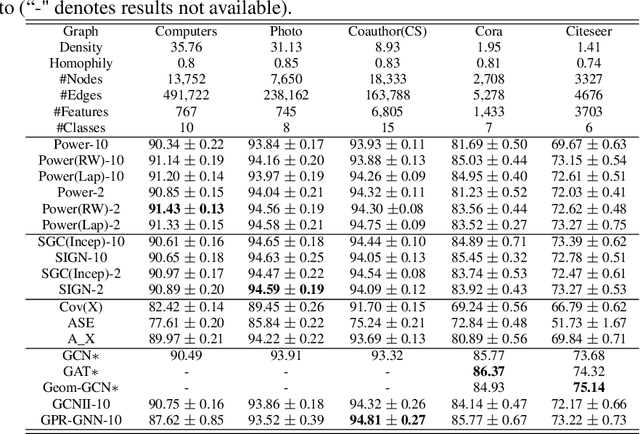
Graph Neural Networks (GNNs) are powerful deep learning methods for Non-Euclidean data. Popular GNNs are message-passing algorithms (MPNNs) that aggregate and combine signals in a local graph neighborhood. However, shallow MPNNs tend to miss long-range signals and perform poorly on some heterophilous graphs, while deep MPNNs can suffer from issues like over-smoothing or over-squashing. To mitigate such issues, existing works typically borrow normalization techniques from training neural networks on Euclidean data or modify the graph structures. Yet these approaches are not well-understood theoretically and could increase the overall computational complexity. In this work, we draw inspirations from spectral graph embedding and propose $\texttt{PowerEmbed}$ -- a simple layer-wise normalization technique to boost MPNNs. We show $\texttt{PowerEmbed}$ can provably express the top-$k$ leading eigenvectors of the graph operator, which prevents over-smoothing and is agnostic to the graph topology; meanwhile, it produces a list of representations ranging from local features to global signals, which avoids over-squashing. We apply $\texttt{PowerEmbed}$ in a wide range of simulated and real graphs and demonstrate its competitive performance, particularly for heterophilous graphs.
The Power and Limitation of Pretraining-Finetuning for Linear Regression under Covariate Shift
Aug 03, 2022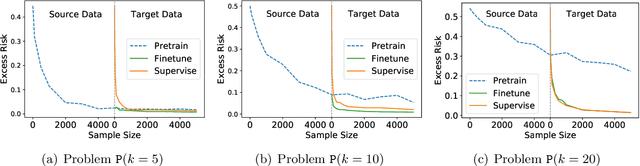
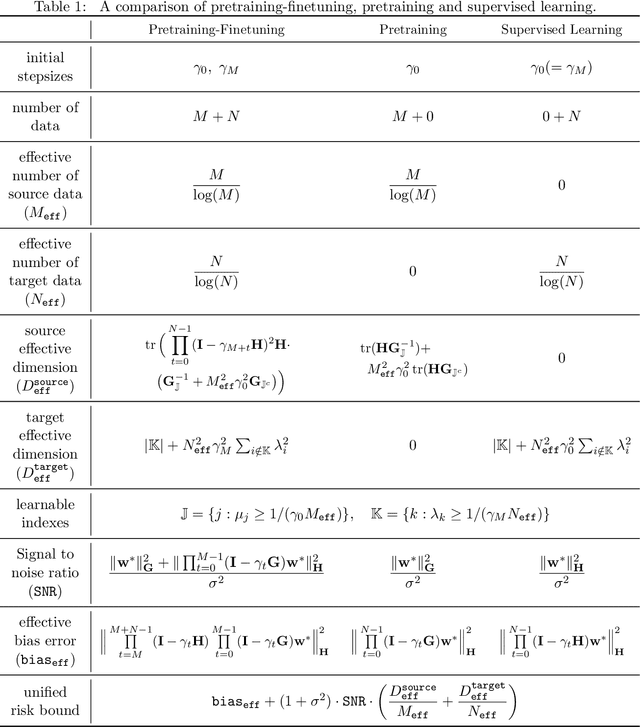
We study linear regression under covariate shift, where the marginal distribution over the input covariates differs in the source and the target domains, while the conditional distribution of the output given the input covariates is similar across the two domains. We investigate a transfer learning approach with pretraining on the source data and finetuning based on the target data (both conducted by online SGD) for this problem. We establish sharp instance-dependent excess risk upper and lower bounds for this approach. Our bounds suggest that for a large class of linear regression instances, transfer learning with $O(N^2)$ source data (and scarce or no target data) is as effective as supervised learning with $N$ target data. In addition, we show that finetuning, even with only a small amount of target data, could drastically reduce the amount of source data required by pretraining. Our theory sheds light on the effectiveness and limitation of pretraining as well as the benefits of finetuning for tackling covariate shift problems.