 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning, Computing, and Trustworthiness in Intelligent IoT Environments: Performance-Energy Tradeoffs
Oct 04, 2021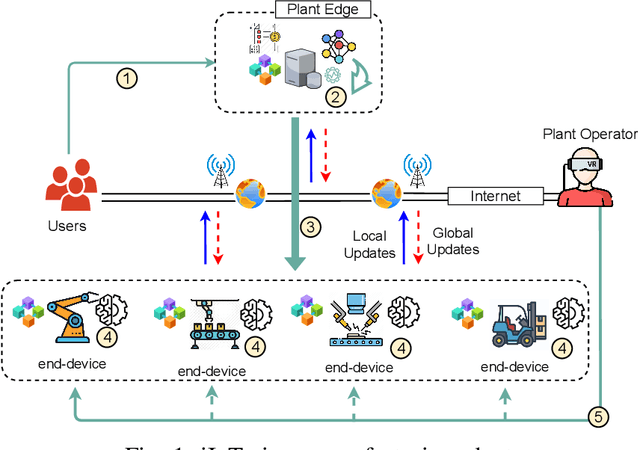
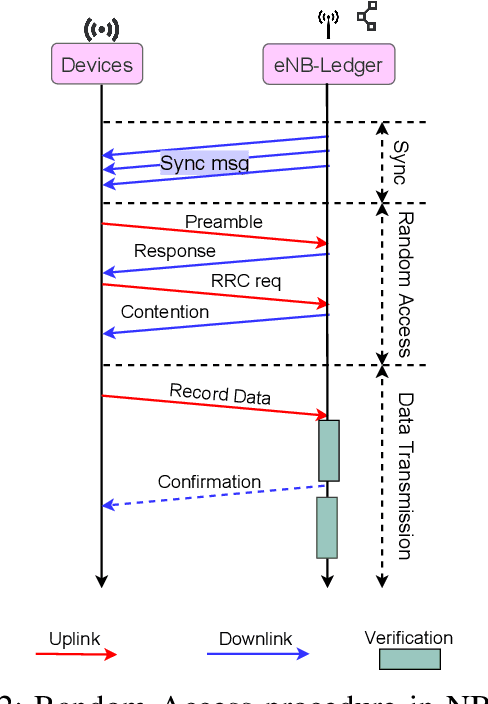
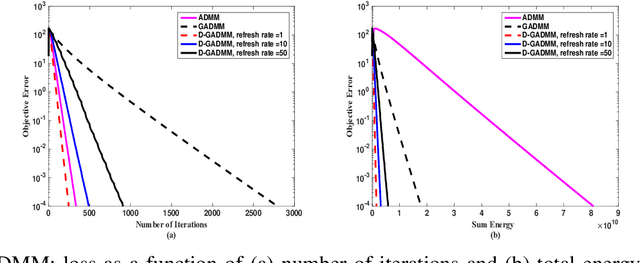
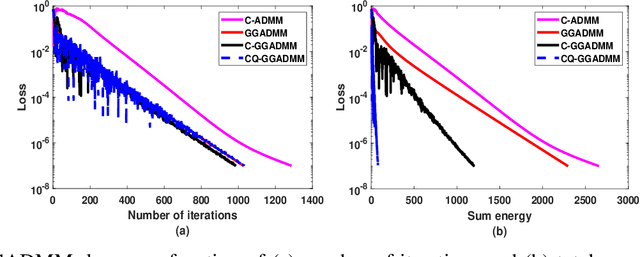
An Intelligent IoT Environment (iIoTe) is comprised of heterogeneous devices that can collaboratively execute semi-autonomous IoT applications, examples of which include highly automated manufacturing cells or autonomously interacting harvesting machines. Energy efficiency is key in such edge environments, since they are often based on an infrastructure that consists of wireless and battery-run devices, e.g., e-tractors, drones, Automated Guided Vehicle (AGV)s and robots. The total energy consumption draws contributions from multipleiIoTe technologies that enable edge computing and communication, distributed learning, as well as distributed ledgers and smart contracts. This paper provides a state-of-the-art overview of these technologies and illustrates their functionality and performance, with special attention to the tradeoff among resources, latency, privacy and energy consumption. Finally, the paper provides a vision for integrating these enabling technologies in energy-efficient iIoTe and a roadmap to address the open research challenges
TopicBERT for Energy Efficient Document Classification
Oct 15, 2020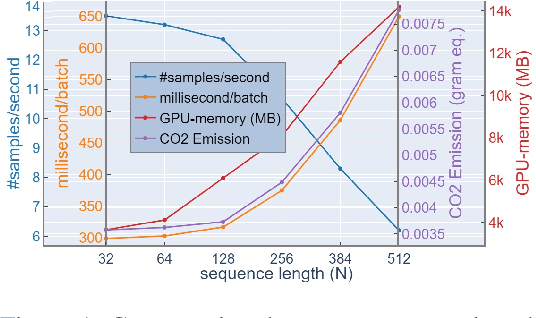
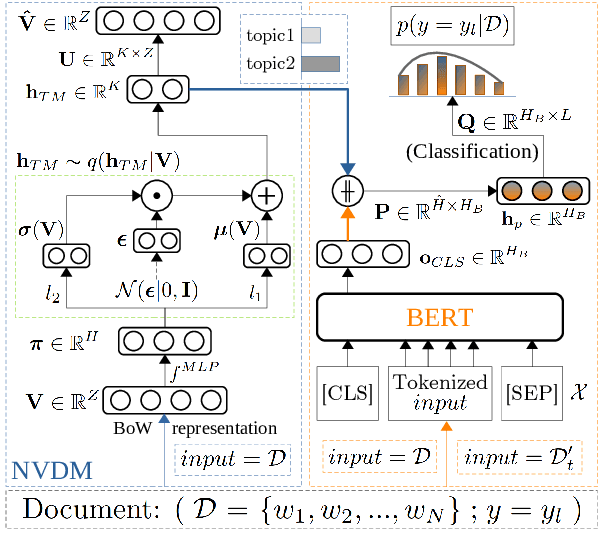

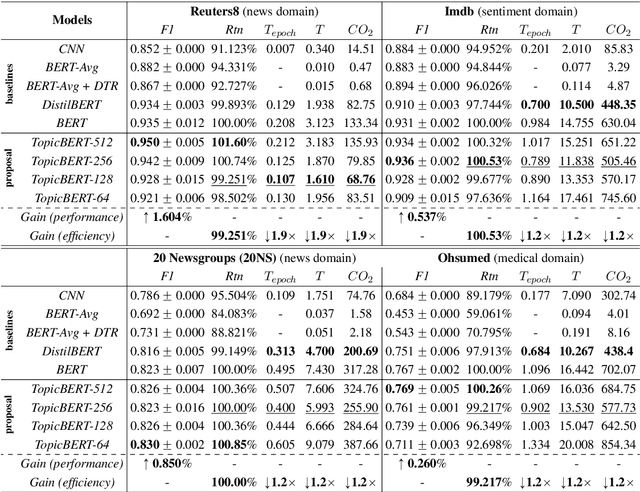
Prior research notes that BERT's computational cost grows quadratically with sequence length thus leading to longer training times, higher GPU memory constraints and carbon emissions. While recent work seeks to address these scalability issues at pre-training, these issues are also prominent in fine-tuning especially for long sequence tasks like document classification. Our work thus focuses on optimizing the computational cost of fine-tuning for document classification. We achieve this by complementary learning of both topic and language models in a unified framework, named TopicBERT. This significantly reduces the number of self-attention operations - a main performance bottleneck. Consequently, our model achieves a 1.4x ($\sim40\%$) speedup with $\sim40\%$ reduction in $CO_2$ emission while retaining $99.9\%$ performance over 5 datasets.
DialectGram: Detecting Dialectal Variation at Multiple Geographic Resolutions
Oct 16, 2019
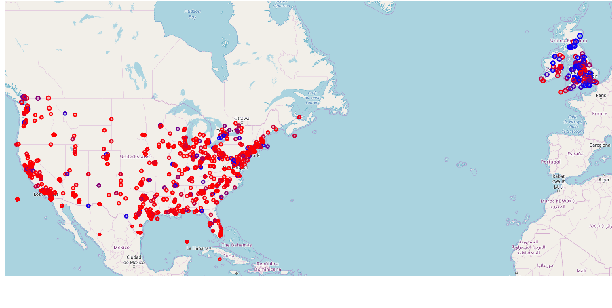
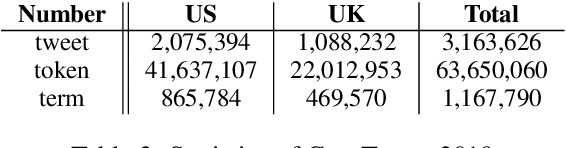
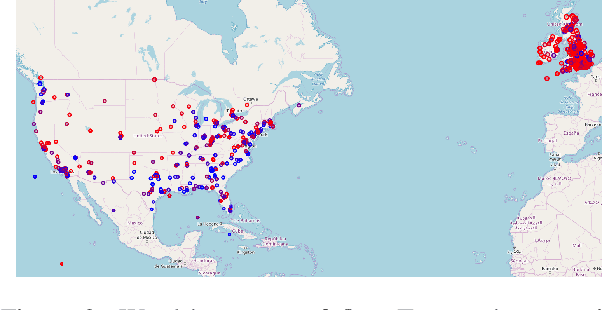
Several computational models have been developed to detect and analyze dialect variation in recent years. Most of these models assume a predefined set of geographical regions over which they detect and analyze dialectal variation. However, dialect variation occurs at multiple levels of geographic resolution ranging from cities within a state, states within a country, and between countries across continents. In this work, we propose a model that enables detection of dialectal variation at multiple levels of geographic resolution obviating the need for a-priori definition of the resolution level. Our method DialectGram, learns dialect-sensitive word embeddings while being agnostic of the geographic resolution. Specifically it only requires one-time training and enables analysis of dialectal variation at a chosen resolution post-hoc -- a significant departure from prior models which need to be re-trained whenever the pre-defined set of regions changes. Furthermore, DialectGram explicitly models senses thus enabling one to estimate the proportion of each sense usage in any given region. Finally, we quantitatively evaluate our model against other baselines on a new evaluation dataset DialectSim (in English) and show that DialectGram can effectively model linguistic variation.
* Hang Jiang, Haoshen Hong, and Yuxing Chen are equal contributors
What Should I Ask? Using Conversationally Informative Rewards for Goal-Oriented Visual Dialog
Jul 28, 2019
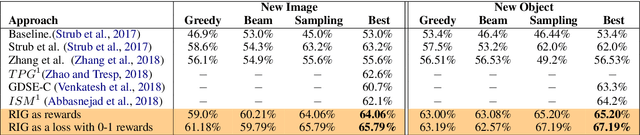
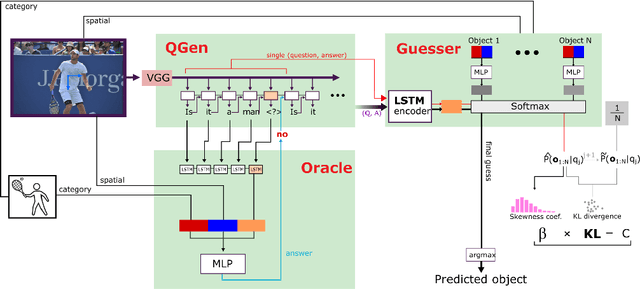
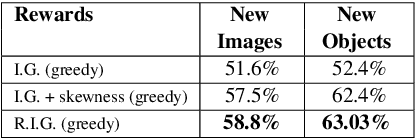
The ability to engage in goal-oriented conversations has allowed humans to gain knowledge, reduce uncertainty, and perform tasks more efficiently. Artificial agents, however, are still far behind humans in having goal-driven conversations. In this work, we focus on the task of goal-oriented visual dialogue, aiming to automatically generate a series of questions about an image with a single objective. This task is challenging since these questions must not only be consistent with a strategy to achieve a goal, but also consider the contextual information in the image. We propose an end-to-end goal-oriented visual dialogue system, that combines reinforcement learning with regularized information gain. Unlike previous approaches that have been proposed for the task, our work is motivated by the Rational Speech Act framework, which models the process of human inquiry to reach a goal. We test the two versions of our model on the GuessWhat?! dataset, obtaining significant results that outperform the current state-of-the-art models in the task of generating questions to find an undisclosed object in an image.
TWEETQA: A Social Media Focused Question Answering Dataset
Jul 14, 2019
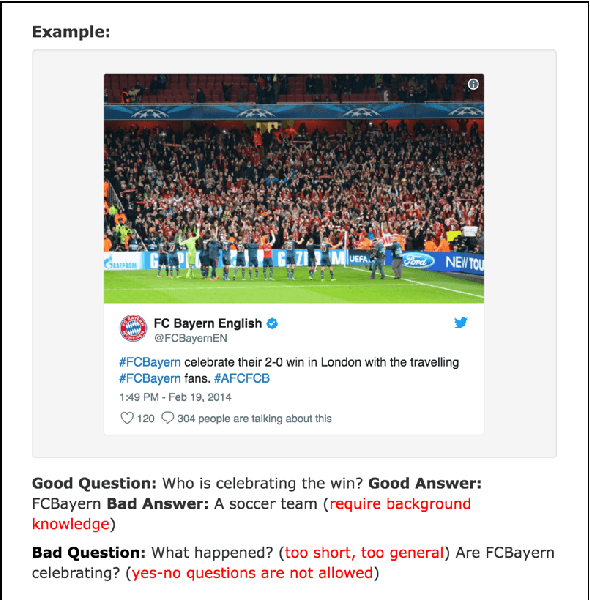
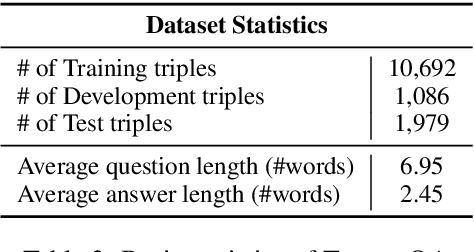

With social media becoming increasingly pop-ular on which lots of news and real-time eventsare reported, developing automated questionanswering systems is critical to the effective-ness of many applications that rely on real-time knowledge. While previous datasets haveconcentrated on question answering (QA) forformal text like news and Wikipedia, wepresent the first large-scale dataset for QA oversocial media data. To ensure that the tweetswe collected are useful, we only gather tweetsused by journalists to write news articles. Wethen ask human annotators to write questionsand answers upon these tweets. Unlike otherQA datasets like SQuAD in which the answersare extractive, we allow the answers to be ab-stractive. We show that two recently proposedneural models that perform well on formaltexts are limited in their performance when ap-plied to our dataset. In addition, even the fine-tuned BERT model is still lagging behind hu-man performance with a large margin. Our re-sults thus point to the need of improved QAsystems targeting social media text.
MOHONE: Modeling Higher Order Network Effects in KnowledgeGraphs via Network Infused Embeddings
Nov 01, 2018

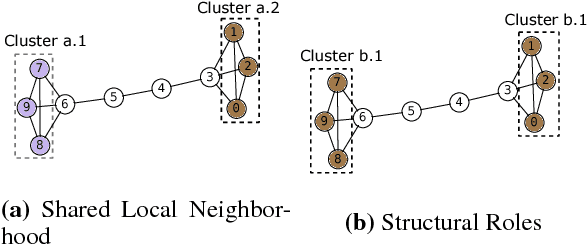
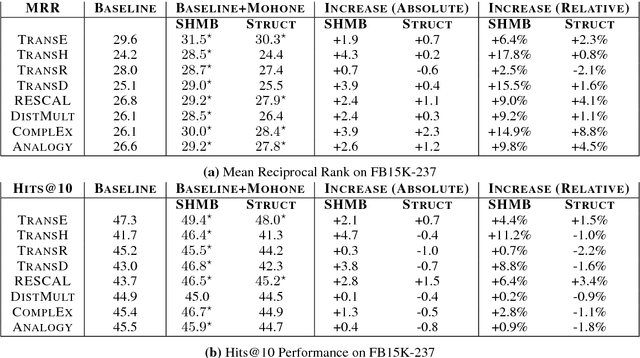
Many knowledge graph embedding methods operate on triples and are therefore implicitly limited by a very local view of the entire knowledge graph. We present a new framework MOHONE to effectively model higher order network effects in knowledge-graphs, thus enabling one to capture varying degrees of network connectivity (from the local to the global). Our framework is generic, explicitly models the network scale, and captures two different aspects of similarity in networks: (a) shared local neighborhood and (b) structural role-based similarity. First, we introduce methods that learn network representations of entities in the knowledge graph capturing these varied aspects of similarity. We then propose a fast, efficient method to incorporate the information captured by these network representations into existing knowledge graph embeddings. We show that our method consistently and significantly improves the performance on link prediction of several different knowledge-graph embedding methods including TRANSE, TRANSD, DISTMULT, and COMPLEX(by at least 4 points or 17% in some cases).
DOLORES: Deep Contextualized Knowledge Graph Embeddings
Oct 31, 2018
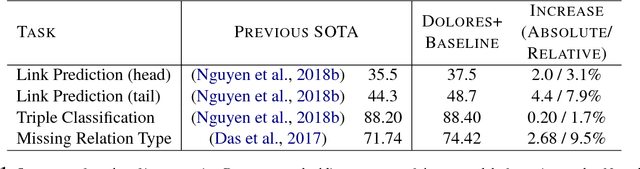
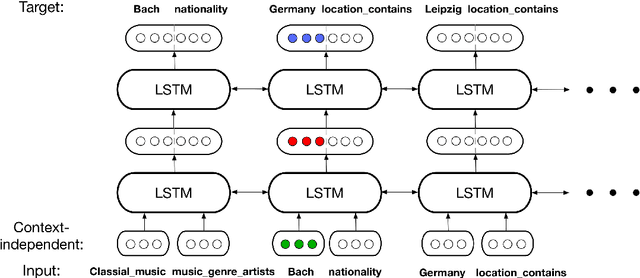
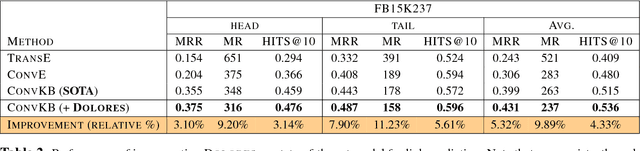
We introduce a new method DOLORES for learning knowledge graph embeddings that effectively captures contextual cues and dependencies among entities and relations. First, we note that short paths on knowledge graphs comprising of chains of entities and relations can encode valuable information regarding their contextual usage. We operationalize this notion by representing knowledge graphs not as a collection of triples but as a collection of entity-relation chains, and learn embeddings for entities and relations using deep neural models that capture such contextual usage. In particular, our model is based on Bi-Directional LSTMs and learn deep representations of entities and relations from constructed entity-relation chains. We show that these representations can very easily be incorporated into existing models to significantly advance the state of the art on several knowledge graph prediction tasks like link prediction, triple classification, and missing relation type prediction (in some cases by at least 9.5%).
Multi-view Models for Political Ideology Detection of News Articles
Sep 10, 2018
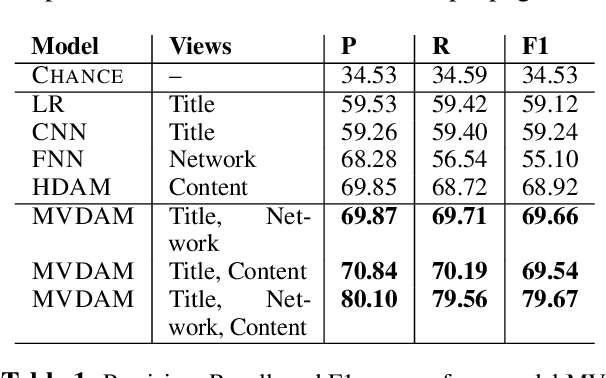
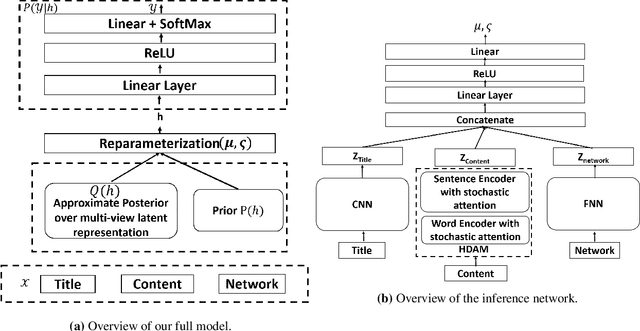

A news article's title, content and link structure often reveal its political ideology. However, most existing works on automatic political ideology detection only leverage textual cues. Drawing inspiration from recent advances in neural inference, we propose a novel attention based multi-view model to leverage cues from all of the above views to identify the ideology evinced by a news article. Our model draws on advances in representation learning in natural language processing and network science to capture cues from both textual content and the network structure of news articles. We empirically evaluate our model against a battery of baselines and show that our model outperforms state of the art by 10 percentage points F1 score.
Hate Lingo: A Target-based Linguistic Analysis of Hate Speech in Social Media
Apr 11, 2018
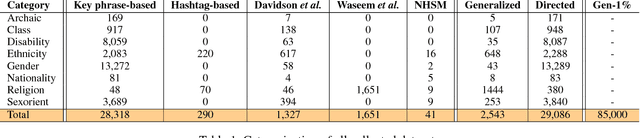

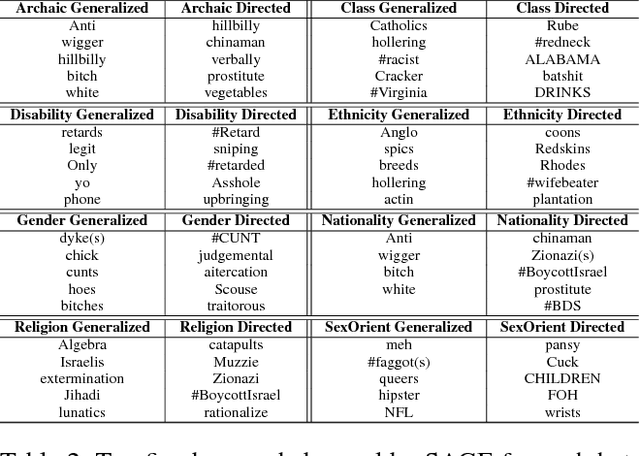
While social media empowers freedom of expression and individual voices, it also enables anti-social behavior, online harassment, cyberbullying, and hate speech. In this paper, we deepen our understanding of online hate speech by focusing on a largely neglected but crucial aspect of hate speech -- its target: either "directed" towards a specific person or entity, or "generalized" towards a group of people sharing a common protected characteristic. We perform the first linguistic and psycholinguistic analysis of these two forms of hate speech and reveal the presence of interesting markers that distinguish these types of hate speech. Our analysis reveals that Directed hate speech, in addition to being more personal and directed, is more informal, angrier, and often explicitly attacks the target (via name calling) with fewer analytic words and more words suggesting authority and influence. Generalized hate speech, on the other hand, is dominated by religious hate, is characterized by the use of lethal words such as murder, exterminate, and kill; and quantity words such as million and many. Altogether, our work provides a data-driven analysis of the nuances of online-hate speech that enables not only a deepened understanding of hate speech and its social implications but also its detection.
Simple Models for Word Formation in English Slang
Apr 07, 2018
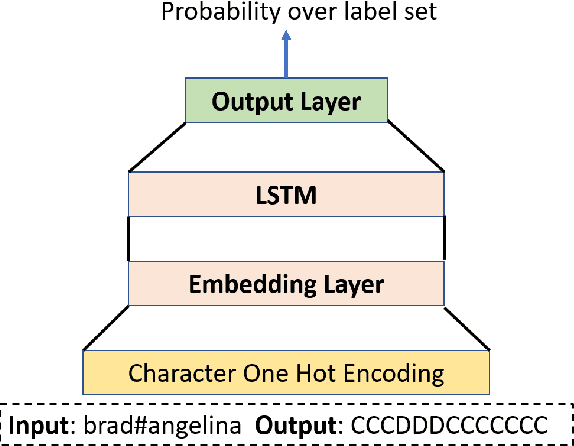
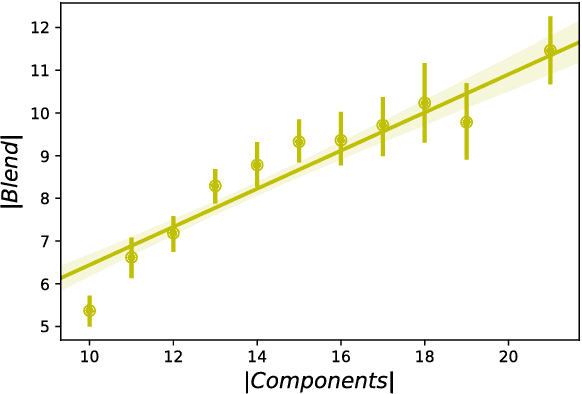

We propose generative models for three types of extra-grammatical word formation phenomena abounding in English slang: Blends, Clippings, and Reduplicatives. Adopting a data-driven approach coupled with linguistic knowledge, we propose simple models with state of the art performance on human annotated gold standard datasets. Overall, our models reveal insights into the generative processes of word formation in slang -- insights which are increasingly relevant in the context of the rising prevalence of slang and non-standard varieties on the Internet.