 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Vocabulary-Free Fine-Grained Visual Recognition in the Age of Multimodal LLMs
May 02, 2025Fine-grained Visual Recognition (FGVR) involves distinguishing between visually similar categories, which is inherently challenging due to subtle inter-class differences and the need for large, expert-annotated datasets. In domains like medical imaging, such curated datasets are unavailable due to issues like privacy concerns and high annotation costs. In such scenarios lacking labeled data, an FGVR model cannot rely on a predefined set of training labels, and hence has an unconstrained output space for predictions. We refer to this task as Vocabulary-Free FGVR (VF-FGVR), where a model must predict labels from an unconstrained output space without prior label information. While recent Multimodal Large Language Models (MLLMs) show potential for VF-FGVR, querying these models for each test input is impractical because of high costs and prohibitive inference times. To address these limitations, we introduce \textbf{Nea}rest-Neighbor Label \textbf{R}efinement (NeaR), a novel approach that fine-tunes a downstream CLIP model using labels generated by an MLLM. Our approach constructs a weakly supervised dataset from a small, unlabeled training set, leveraging MLLMs for label generation. NeaR is designed to handle the noise, stochasticity, and open-endedness inherent in labels generated by MLLMs, and establishes a new benchmark for efficient VF-FGVR.
Can Better Text Semantics in Prompt Tuning Improve VLM Generalization?
May 13, 2024Going beyond mere fine-tuning of vision-language models (VLMs), learnable prompt tuning has emerged as a promising, resource-efficient alternative. Despite their potential, effectively learning prompts faces the following challenges: (i) training in a low-shot scenario results in overfitting, limiting adaptability and yielding weaker performance on newer classes or datasets; (ii) prompt-tuning's efficacy heavily relies on the label space, with decreased performance in large class spaces, signaling potential gaps in bridging image and class concepts. In this work, we ask the question if better text semantics can help address these concerns. In particular, we introduce a prompt-tuning method that leverages class descriptions obtained from large language models (LLMs). Our approach constructs part-level description-guided views of both image and text features, which are subsequently aligned to learn more generalizable prompts. Our comprehensive experiments, conducted across 11 benchmark datasets, outperform established methods, demonstrating substantial improvements.
Unseen Classes at a Later Time? No Problem
Mar 30, 2022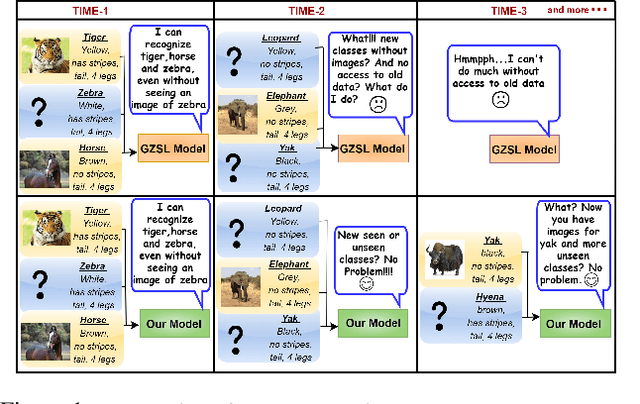
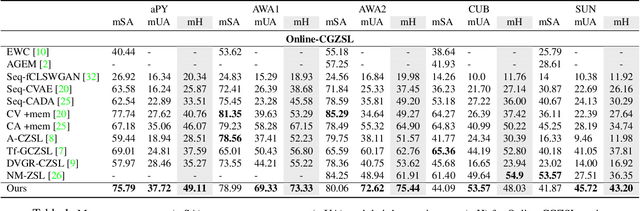
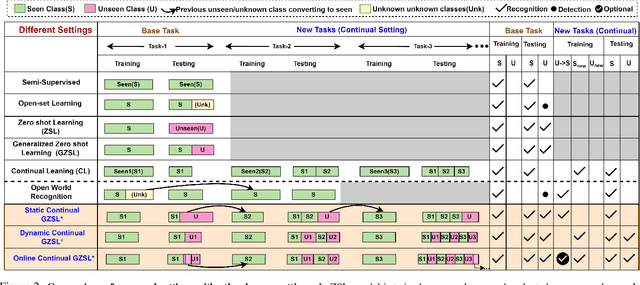
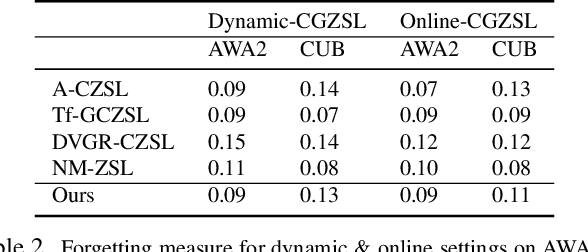
Recent progress towards learning from limited supervision has encouraged efforts towards designing models that can recognize novel classes at test time (generalized zero-shot learning or GZSL). GZSL approaches assume knowledge of all classes, with or without labeled data, beforehand. However, practical scenarios demand models that are adaptable and can handle dynamic addition of new seen and unseen classes on the fly (that is continual generalized zero-shot learning or CGZSL). One solution is to sequentially retrain and reuse conventional GZSL methods, however, such an approach suffers from catastrophic forgetting leading to suboptimal generalization performance. A few recent efforts towards tackling CGZSL have been limited by difference in settings, practicality, data splits and protocols followed-inhibiting fair comparison and a clear direction forward. Motivated from these observations, in this work, we firstly consolidate the different CGZSL setting variants and propose a new Online-CGZSL setting which is more practical and flexible. Secondly, we introduce a unified feature-generative framework for CGZSL that leverages bi-directional incremental alignment to dynamically adapt to addition of new classes, with or without labeled data, that arrive over time in any of these CGZSL settings. Our comprehensive experiments and analysis on five benchmark datasets and comparison with baselines show that our approach consistently outperforms existing methods, especially on the more practical Online setting.