 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoVLM: Leveraging Consensus from Vision-Language Models for Semi-supervised Multi-modal Fake News Detection
Oct 06, 2024



In this work, we address the real-world, challenging task of out-of-context misinformation detection, where a real image is paired with an incorrect caption for creating fake news. Existing approaches for this task assume the availability of large amounts of labeled data, which is often impractical in real-world, since it requires extensive manual intervention and domain expertise. In contrast, since obtaining a large corpus of unlabeled image-text pairs is much easier, here, we propose a semi-supervised protocol, where the model has access to a limited number of labeled image-text pairs and a large corpus of unlabeled pairs. Additionally, the occurrence of fake news being much lesser compared to the real ones, the datasets tend to be highly imbalanced, thus making the task even more challenging. Towards this goal, we propose a novel framework, Consensus from Vision-Language Models (CoVLM), which generates robust pseudo-labels for unlabeled pairs using thresholds derived from the labeled data. This approach can automatically determine the right threshold parameters of the model for selecting the confident pseudo-labels. Experimental results on benchmark datasets across challenging conditions and comparisons with state-of-the-art approaches demonstrate the effectiveness of our framework.
Beyond Few-shot Object Detection: A Detailed Survey
Aug 26, 2024Object detection is a critical field in computer vision focusing on accurately identifying and locating specific objects in images or videos. Traditional methods for object detection rely on large labeled training datasets for each object category, which can be time-consuming and expensive to collect and annotate. To address this issue, researchers have introduced few-shot object detection (FSOD) approaches that merge few-shot learning and object detection principles. These approaches allow models to quickly adapt to new object categories with only a few annotated samples. While traditional FSOD methods have been studied before, this survey paper comprehensively reviews FSOD research with a specific focus on covering different FSOD settings such as standard FSOD, generalized FSOD, incremental FSOD, open-set FSOD, and domain adaptive FSOD. These approaches play a vital role in reducing the reliance on extensive labeled datasets, particularly as the need for efficient machine learning models continues to rise. This survey paper aims to provide a comprehensive understanding of the above-mentioned few-shot settings and explore the methodologies for each FSOD task. It thoroughly compares state-of-the-art methods across different FSOD settings, analyzing them in detail based on their evaluation protocols. Additionally, it offers insights into their applications, challenges, and potential future directions in the evolving field of object detection with limited data.
AggSS: An Aggregated Self-Supervised Approach for Class-Incremental Learning
Aug 08, 2024



This paper investigates the impact of self-supervised learning, specifically image rotations, on various class-incremental learning paradigms. Here, each image with a predefined rotation is considered as a new class for training. At inference, all image rotation predictions are aggregated for the final prediction, a strategy we term Aggregated Self-Supervision (AggSS). We observe a shift in the deep neural network's attention towards intrinsic object features as it learns through AggSS strategy. This learning approach significantly enhances class-incremental learning by promoting robust feature learning. AggSS serves as a plug-and-play module that can be seamlessly incorporated into any class-incremental learning framework, leveraging its powerful feature learning capabilities to enhance performance across various class-incremental learning approaches. Extensive experiments conducted on standard incremental learning datasets CIFAR-100 and ImageNet-Subset demonstrate the significant role of AggSS in improving performance within these paradigms.
TACLE: Task and Class-aware Exemplar-free Semi-supervised Class Incremental Learning
Jul 10, 2024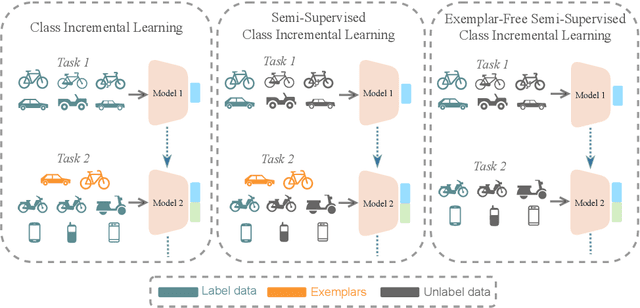
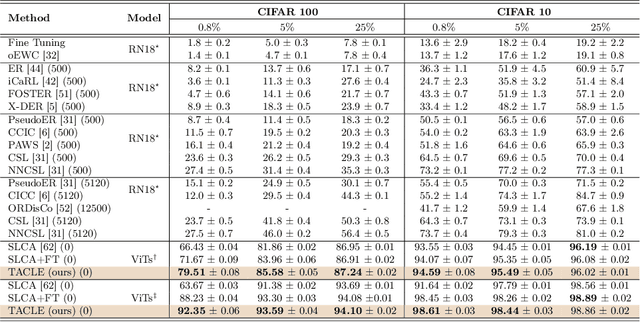
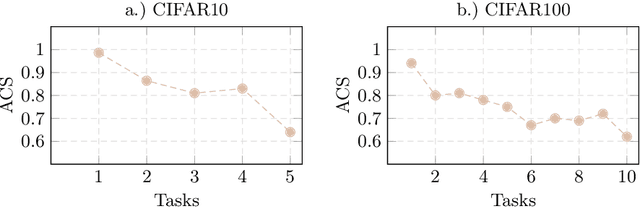
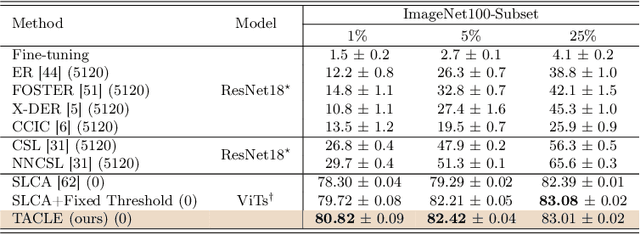
We propose a novel TACLE (TAsk and CLass-awarE) framework to address the relatively unexplored and challenging problem of exemplar-free semi-supervised class incremental learning. In this scenario, at each new task, the model has to learn new classes from both (few) labeled and unlabeled data without access to exemplars from previous classes. In addition to leveraging the capabilities of pre-trained models, TACLE proposes a novel task-adaptive threshold, thereby maximizing the utilization of the available unlabeled data as incremental learning progresses. Additionally, to enhance the performance of the under-represented classes within each task, we propose a class-aware weighted cross-entropy loss. We also exploit the unlabeled data for classifier alignment, which further enhances the model performance. Extensive experiments on benchmark datasets, namely CIFAR10, CIFAR100, and ImageNet-Subset100 demonstrate the effectiveness of the proposed TACLE framework. We further showcase its effectiveness when the unlabeled data is imbalanced and also for the extreme case of one labeled example per class.
Robust Feature Learning and Global Variance-Driven Classifier Alignment for Long-Tail Class Incremental Learning
Nov 02, 2023



This paper introduces a two-stage framework designed to enhance long-tail class incremental learning, enabling the model to progressively learn new classes, while mitigating catastrophic forgetting in the context of long-tailed data distributions. Addressing the challenge posed by the under-representation of tail classes in long-tail class incremental learning, our approach achieves classifier alignment by leveraging global variance as an informative measure and class prototypes in the second stage. This process effectively captures class properties and eliminates the need for data balancing or additional layer tuning. Alongside traditional class incremental learning losses in the first stage, the proposed approach incorporates mixup classes to learn robust feature representations, ensuring smoother boundaries. The proposed framework can seamlessly integrate as a module with any class incremental learning method to effectively handle long-tail class incremental learning scenarios. Extensive experimentation on the CIFAR-100 and ImageNet-Subset datasets validates the approach's efficacy, showcasing its superiority over state-of-the-art techniques across various long-tail CIL settings.
S3C: Self-Supervised Stochastic Classifiers for Few-Shot Class-Incremental Learning
Jul 05, 2023Few-shot class-incremental learning (FSCIL) aims to learn progressively about new classes with very few labeled samples, without forgetting the knowledge of already learnt classes. FSCIL suffers from two major challenges: (i) over-fitting on the new classes due to limited amount of data, (ii) catastrophically forgetting about the old classes due to unavailability of data from these classes in the incremental stages. In this work, we propose a self-supervised stochastic classifier (S3C) to counter both these challenges in FSCIL. The stochasticity of the classifier weights (or class prototypes) not only mitigates the adverse effect of absence of large number of samples of the new classes, but also the absence of samples from previously learnt classes during the incremental steps. This is complemented by the self-supervision component, which helps to learn features from the base classes which generalize well to unseen classes that are encountered in future, thus reducing catastrophic forgetting. Extensive evaluation on three benchmark datasets using multiple evaluation metrics show the effectiveness of the proposed framework. We also experiment on two additional realistic scenarios of FSCIL, namely where the number of annotated data available for each of the new classes can be different, and also where the number of base classes is much lesser, and show that the proposed S3C performs significantly better than the state-of-the-art for all these challenging scenarios.