 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonteBoxFinder: Detecting and Filtering Primitives to Fit a Noisy Point Cloud
Jul 28, 2022
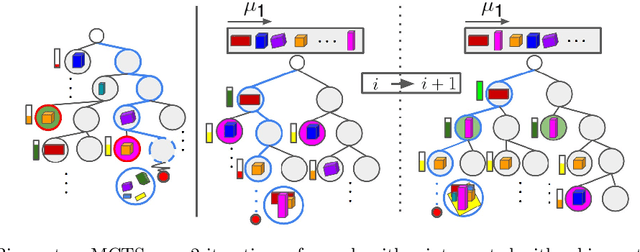
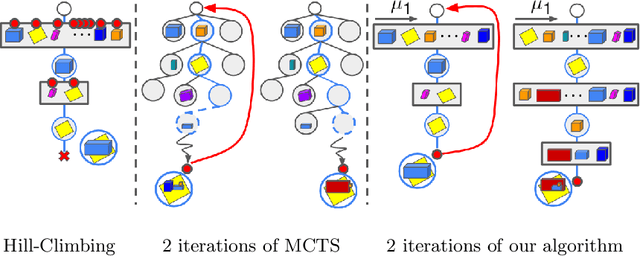
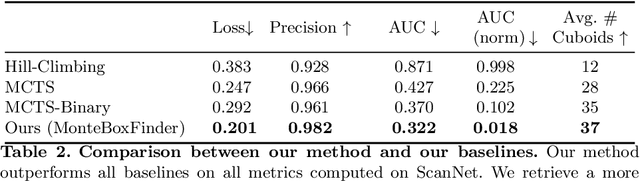
We present MonteBoxFinder, a method that, given a noisy input point cloud, fits cuboids to the input scene. Our primary contribution is a discrete optimization algorithm that, from a dense set of initially detected cuboids, is able to efficiently filter good boxes from the noisy ones. Inspired by recent applications of MCTS to scene understanding problems, we develop a stochastic algorithm that is, by design, more efficient for our task. Indeed, the quality of a fit for a cuboid arrangement is invariant to the order in which the cuboids are added into the scene. We develop several search baselines for our problem and demonstrate, on the ScanNet dataset, that our approach is more efficient and precise. Finally, we strongly believe that our core algorithm is very general and that it could be extended to many other problems in 3D scene understanding.
MCTS with Refinement for Proposals Selection Games in Scene Understanding
Jul 07, 2022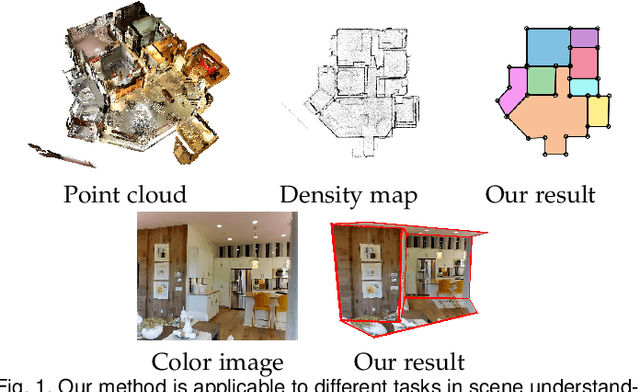
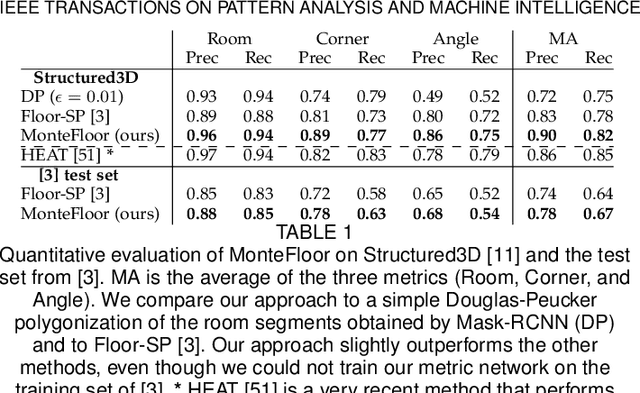
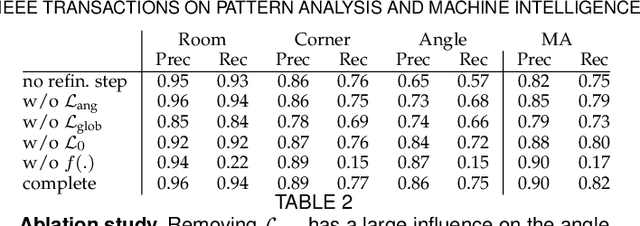
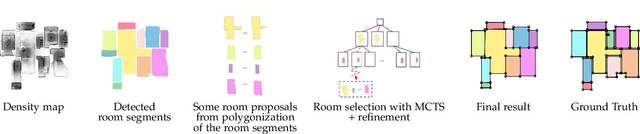
We propose a novel method applicable in many scene understanding problems that adapts the Monte Carlo Tree Search (MCTS) algorithm, originally designed to learn to play games of high-state complexity. From a generated pool of proposals, our method jointly selects and optimizes proposals that minimize the objective term. In our first application for floor plan reconstruction from point clouds, our method selects and refines the room proposals, modelled as 2D polygons, by optimizing on an objective function combining the fitness as predicted by a deep network and regularizing terms on the room shapes. We also introduce a novel differentiable method for rendering the polygonal shapes of these proposals. Our evaluations on the recent and challenging Structured3D and Floor-SP datasets show significant improvements over the state-of-the-art, without imposing hard constraints nor assumptions on the floor plan configurations. In our second application, we extend our approach to reconstruct general 3D room layouts from a color image and obtain accurate room layouts. We also show that our differentiable renderer can easily be extended for rendering 3D planar polygons and polygon embeddings. Our method shows high performance on the Matterport3D-Layout dataset, without introducing hard constraints on room layout configurations.
Back to MLP: A Simple Baseline for Human Motion Prediction
Jul 04, 2022
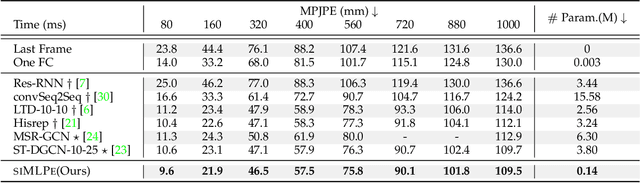
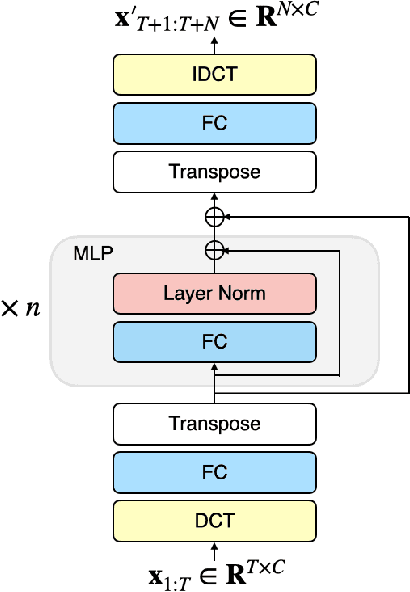

This paper tackles the problem of human motion prediction, consisting in forecasting future body poses from historically observed sequences. Despite of their performance, current state-of-the-art approaches rely on deep learning architectures of arbitrary complexity, such as Recurrent Neural Networks~(RNN), Transformers or Graph Convolutional Networks~(GCN), typically requiring multiple training stages and more than 3 million of parameters. In this paper we show that the performance of these approaches can be surpassed by a light-weight and purely MLP architecture with only 0.14M parameters when appropriately combined with several standard practices such as representing the body pose with Discrete Cosine Transform (DCT), predicting residual displacement of joints and optimizing velocity as an auxiliary loss. An exhaustive evaluation on Human3.6M, AMASS and 3DPW datasets shows that our method, which we dub siMLPe, consistently outperforms all other approaches. We hope that our simple method could serve a strong baseline to the community and allow re-thinking the problem of human motion prediction and whether current benchmarks do really need intricate architectural designs. Our code is available at \url{https://github.com/dulucas/siMLPe}.
Templates for 3D Object Pose Estimation Revisited: Generalization to New Objects and Robustness to Occlusions
Mar 31, 2022


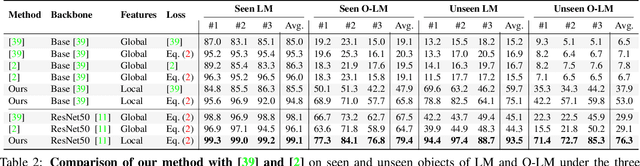
We present a method that can recognize new objects and estimate their 3D pose in RGB images even under partial occlusions. Our method requires neither a training phase on these objects nor real images depicting them, only their CAD models. It relies on a small set of training objects to learn local object representations, which allow us to locally match the input image to a set of "templates", rendered images of the CAD models for the new objects. In contrast with the state-of-the-art methods, the new objects on which our method is applied can be very different from the training objects. As a result, we are the first to show generalization without retraining on the LINEMOD and Occlusion-LINEMOD datasets. Our analysis of the failure modes of previous template-based approaches further confirms the benefits of local features for template matching. We outperform the state-of-the-art template matching methods on the LINEMOD, Occlusion-LINEMOD and T-LESS datasets. Our source code and data are publicly available at https://github.com/nv-nguyen/template-pose
UVO Challenge on Video-based Open-World Segmentation 2021: 1st Place Solution
Nov 01, 2021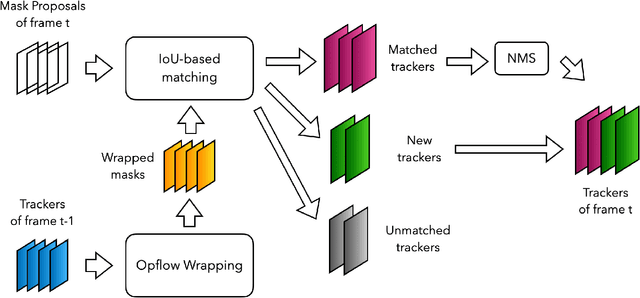
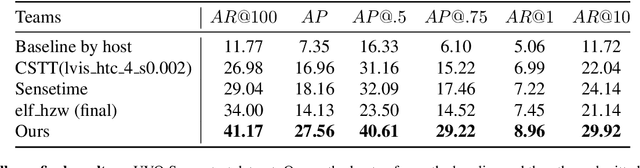

In this report, we introduce our (pretty straightforard) two-step "detect-then-match" video instance segmentation method. The first step performs instance segmentation for each frame to get a large number of instance mask proposals. The second step is to do inter-frame instance mask matching with the help of optical flow. We demonstrate that with high quality mask proposals, a simple matching mechanism is good enough for tracking. Our approach achieves the first place in the UVO 2021 Video-based Open-World Segmentation Challenge.
1st Place Solution for the UVO Challenge on Image-based Open-World Segmentation 2021
Oct 19, 2021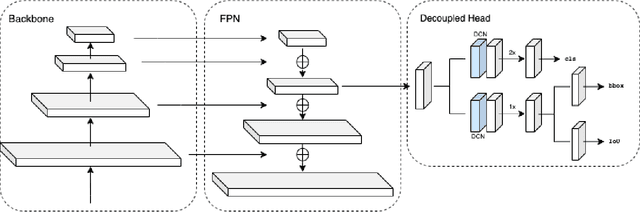
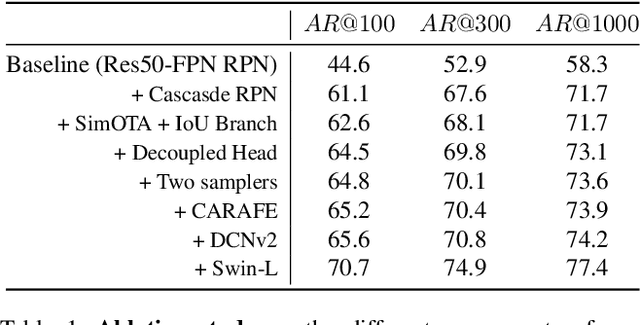

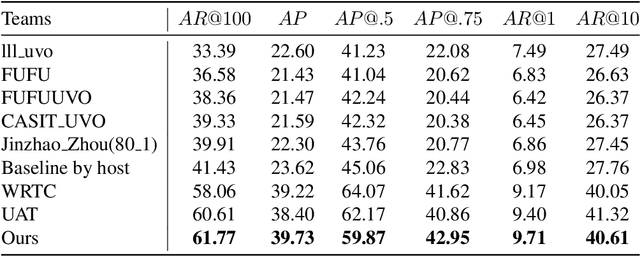
We describe our two-stage instance segmentation framework we use to compete in the challenge. The first stage of our framework consists of an object detector, which generates object proposals in the format of bounding boxes. Then, the images and the detected bounding boxes are fed to the second stage, where a segmentation network is applied to segment the objects in the bounding boxes. We train all our networks in a class-agnostic way. Our approach achieves the first place in the UVO 2021 Image-based Open-World Segmentation Challenge.
HO-3D_v3: Improving the Accuracy of Hand-Object Annotations of the HO-3D Dataset
Jul 02, 2021

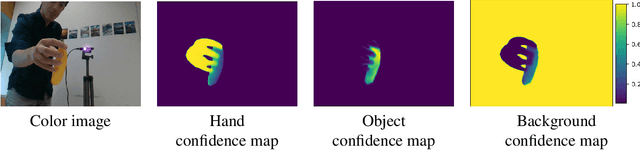
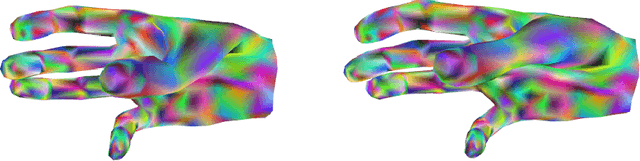
HO-3D is a dataset providing image sequences of various hand-object interaction scenarios annotated with the 3D pose of the hand and the object and was originally introduced as HO-3D_v2. The annotations were obtained automatically using an optimization method, 'HOnnotate', introduced in the original paper. HO-3D_v3 provides more accurate annotations for both the hand and object poses thus resulting in better estimates of contact regions between the hand and the object. In this report, we elaborate on the improvements to the HOnnotate method and provide evaluations to compare the accuracy of HO-3D_v2 and HO-3D_v3. HO-3D_v3 results in 4mm higher accuracy compared to HO-3D_v2 for hand poses while exhibiting higher contact regions with the object surface.
Visual Correspondence Hallucination: Towards Geometric Reasoning
Jun 17, 2021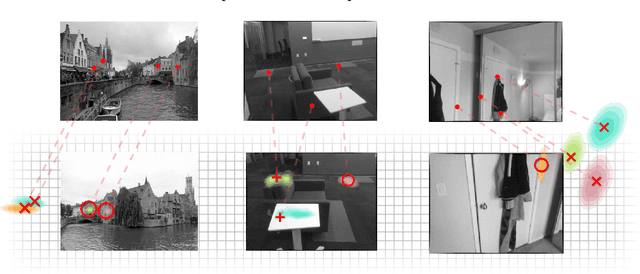
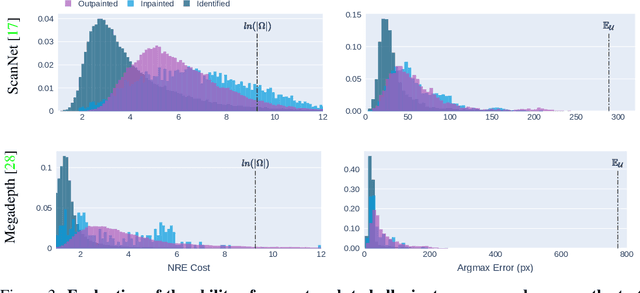
Given a pair of partially overlapping source and target images and a keypoint in the source image, the keypoint's correspondent in the target image can be either visible, occluded or outside the field of view. Local feature matching methods are only able to identify the correspondent's location when it is visible, while humans can also hallucinate its location when it is occluded or outside the field of view through geometric reasoning. In this paper, we bridge this gap by training a network to output a peaked probability distribution over the correspondent's location, regardless of this correspondent being visible, occluded, or outside the field of view. We experimentally demonstrate that this network is indeed able to hallucinate correspondences on unseen pairs of images. We also apply this network to a camera pose estimation problem and find it is significantly more robust than state-of-the-art local feature matching-based competitors.
Single Image Depth Estimation using Wavelet Decomposition
Jun 03, 2021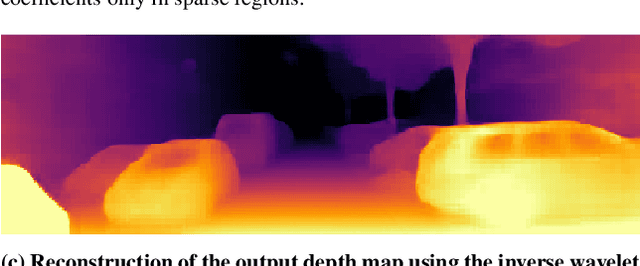
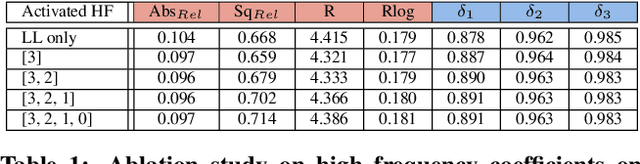
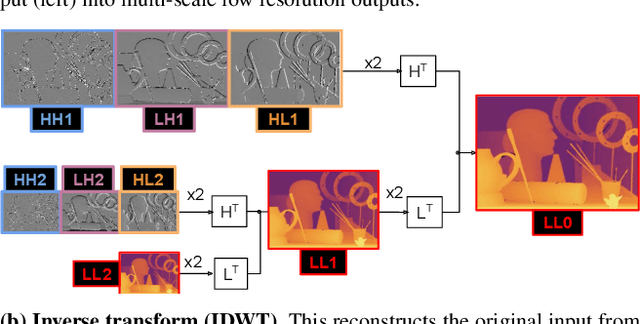

We present a novel method for predicting accurate depths from monocular images with high efficiency. This optimal efficiency is achieved by exploiting wavelet decomposition, which is integrated in a fully differentiable encoder-decoder architecture. We demonstrate that we can reconstruct high-fidelity depth maps by predicting sparse wavelet coefficients. In contrast with previous works, we show that wavelet coefficients can be learned without direct supervision on coefficients. Instead we supervise only the final depth image that is reconstructed through the inverse wavelet transform. We additionally show that wavelet coefficients can be learned in fully self-supervised scenarios, without access to ground-truth depth. Finally, we apply our method to different state-of-the-art monocular depth estimation models, in each case giving similar or better results compared to the original model, while requiring less than half the multiply-adds in the decoder network. Code at https://github.com/nianticlabs/wavelet-monodepth
HandsFormer: Keypoint Transformer for Monocular 3D Pose Estimation ofHands and Object in Interaction
Apr 29, 2021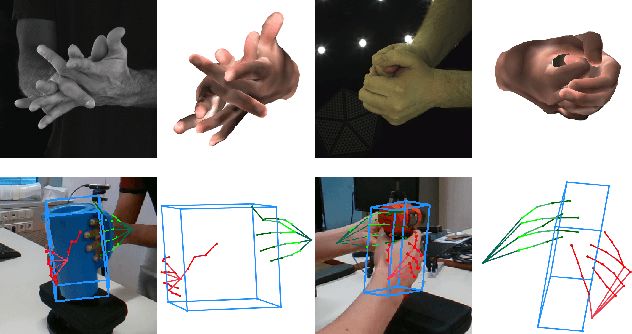
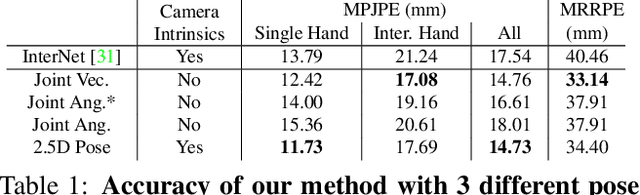
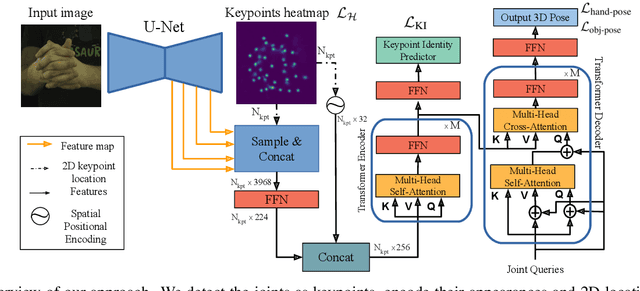

We propose a robust and accurate method for estimating the 3D poses of two hands in close interaction from a single color image. This is a very challenging problem, as large occlusions and many confusions between the joints may happen. Our method starts by extracting a set of potential 2D locations for the joints of both hands as extrema of a heatmap. We do not require that all locations correctly correspond to a joint, not that all the joints are detected. We use appearance and spatial encodings of these locations as input to a transformer, and leverage the attention mechanisms to sort out the correct configuration of the joints and output the 3D poses of both hands. Our approach thus allies the recognition power of a Transformer to the accuracy of heatmap-based methods. We also show it can be extended to estimate the 3D pose of an object manipulated by one or two hands. We evaluate our approach on the recent and challenging InterHand2.6M and HO-3D datasets. We obtain 17% improvement over the baseline. Moreover, we introduce the first dataset made of action sequences of two hands manipulating an object fully annotated in 3D and will make it publicly available.