 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECT: Harnessing LLM-assisted Fine-Grained Linguistic Knowledge and Label-Switched and Label-Preserved Data Generation for Diagnosis of Alzheimer's Disease
Feb 06, 2025Alzheimer's Disease (AD) is an irreversible neurodegenerative disease affecting 50 million people worldwide. Low-cost, accurate identification of key markers of AD is crucial for timely diagnosis and intervention. Language impairment is one of the earliest signs of cognitive decline, which can be used to discriminate AD patients from normal control individuals. Patient-interviewer dialogues may be used to detect such impairments, but they are often mixed with ambiguous, noisy, and irrelevant information, making the AD detection task difficult. Moreover, the limited availability of AD speech samples and variability in their speech styles pose significant challenges in developing robust speech-based AD detection models. To address these challenges, we propose DECT, a novel speech-based domain-specific approach leveraging large language models (LLMs) for fine-grained linguistic analysis and label-switched label-preserved data generation. Our study presents four novelties: We harness the summarizing capabilities of LLMs to identify and distill key Cognitive-Linguistic information from noisy speech transcripts, effectively filtering irrelevant information. We leverage the inherent linguistic knowledge of LLMs to extract linguistic markers from unstructured and heterogeneous audio transcripts. We exploit the compositional ability of LLMs to generate AD speech transcripts consisting of diverse linguistic patterns to overcome the speech data scarcity challenge and enhance the robustness of AD detection models. We use the augmented AD textual speech transcript dataset and a more fine-grained representation of AD textual speech transcript data to fine-tune the AD detection model. The results have shown that DECT demonstrates superior model performance with an 11% improvement in AD detection accuracy on the datasets from DementiaBank compared to the baselines.
Show Me How To Revise: Improving Lexically Constrained Sentence Generation with XLNet
Sep 13, 2021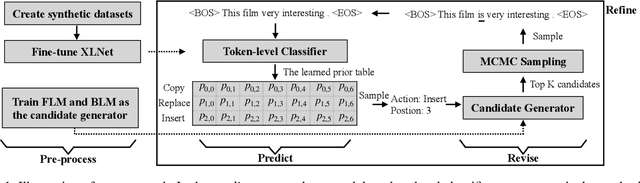
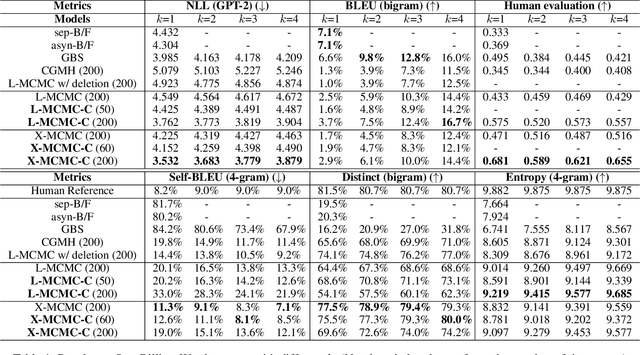
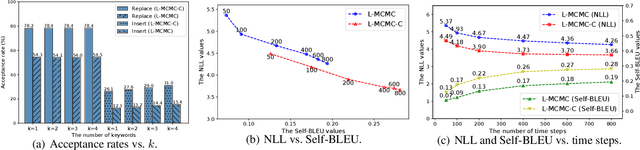
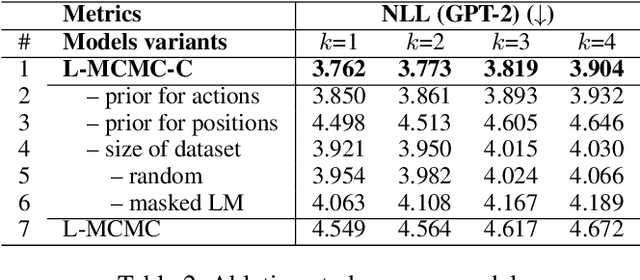
Lexically constrained sentence generation allows the incorporation of prior knowledge such as lexical constraints into the output. This technique has been applied to machine translation, and dialog response generation. Previous work usually used Markov Chain Monte Carlo (MCMC) sampling to generate lexically constrained sentences, but they randomly determined the position to be edited and the action to be taken, resulting in many invalid refinements. To overcome this challenge, we used a classifier to instruct the MCMC-based models where and how to refine the candidate sentences. First, we developed two methods to create synthetic data on which the pre-trained model is fine-tuned to obtain a reliable classifier. Next, we proposed a two-step approach, "Predict and Revise", for constrained sentence generation. During the predict step, we leveraged the classifier to compute the learned prior for the candidate sentence. During the revise step, we resorted to MCMC sampling to revise the candidate sentence by conducting a sampled action at a sampled position drawn from the learned prior. We compared our proposed models with many strong baselines on two tasks, generating sentences with lexical constraints and text infilling. Experimental results have demonstrated that our proposed model performs much better than the previous work in terms of sentence fluency and diversity. Our code and pre-trained models are available at https://github.com/NLPCode/MCMCXLNet.
Deep-AIR: A Hybrid CNN-LSTM Framework for Air Quality Modeling in Metropolitan Cities
Mar 25, 2021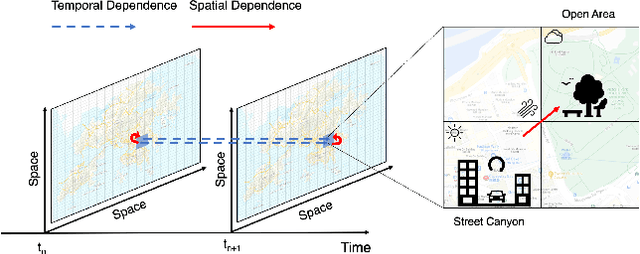
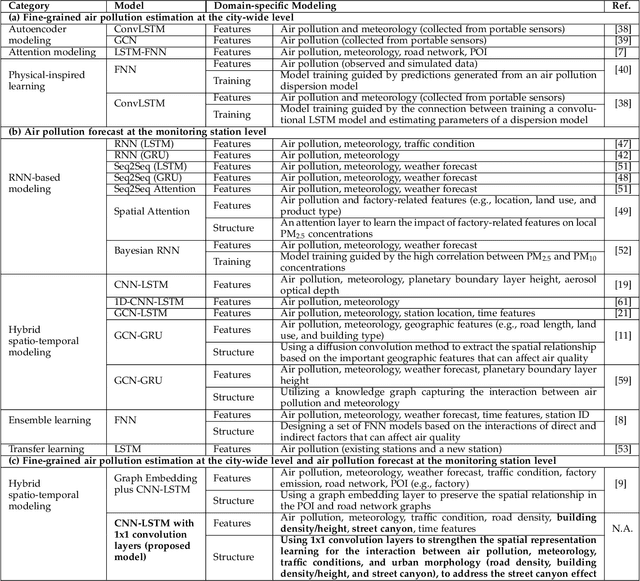
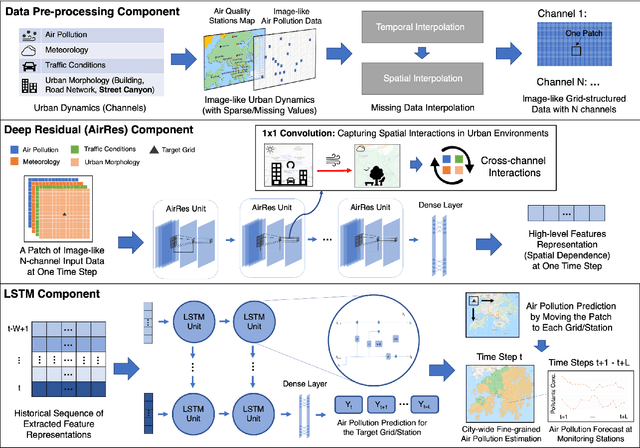
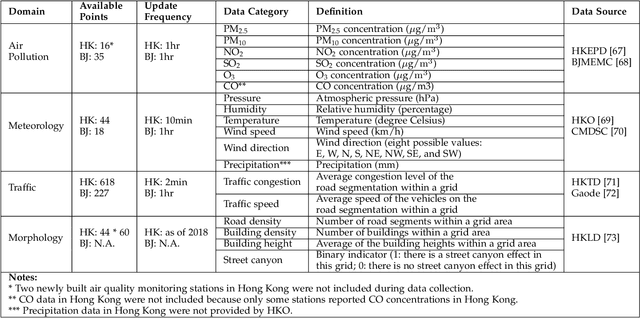
Air pollution has long been a serious environmental health challenge, especially in metropolitan cities, where air pollutant concentrations are exacerbated by the street canyon effect and high building density. Whilst accurately monitoring and forecasting air pollution are highly crucial, existing data-driven models fail to fully address the complex interaction between air pollution and urban dynamics. Our Deep-AIR, a novel hybrid deep learning framework that combines a convolutional neural network with a long short-term memory network, aims to address this gap to provide fine-grained city-wide air pollution estimation and station-wide forecast. Our proposed framework creates 1x1 convolution layers to strengthen the learning of cross-feature spatial interaction between air pollution and important urban dynamic features, particularly road density, building density/height, and street canyon effect. Using Hong Kong and Beijing as case studies, Deep-AIR achieves a higher accuracy than our baseline models. Our model attains an accuracy of 67.6%, 77.2%, and 66.1% in fine-grained hourly estimation, 1-hr, and 24-hr air pollution forecast for Hong Kong, and an accuracy of 65.0%, 75.3%, and 63.5% for Beijing. Our saliency analysis has revealed that for Hong Kong, street canyon and road density are the best estimators for NO2, while meteorology is the best estimator for PM2.5.
On the Sparsity of Neural Machine Translation Models
Oct 06, 2020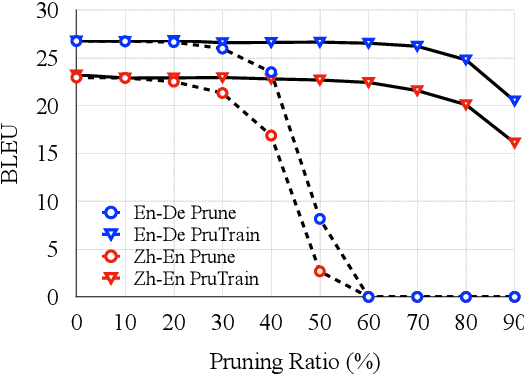
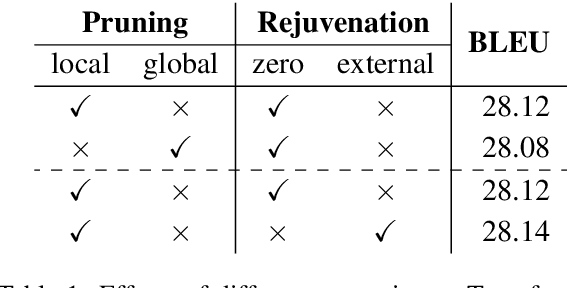
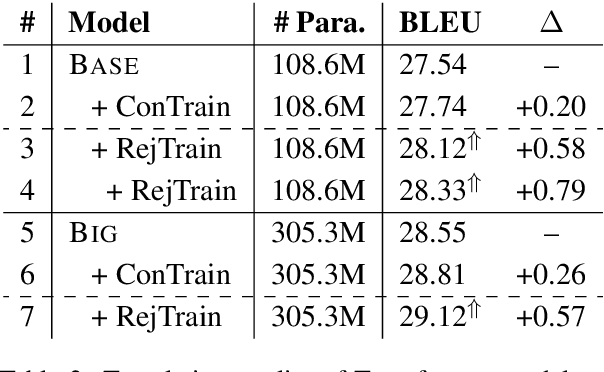
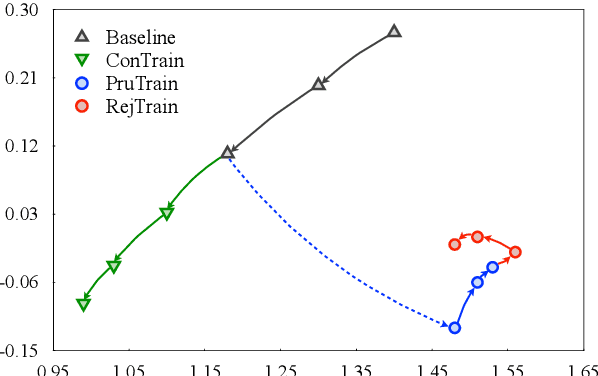
Modern neural machine translation (NMT) models employ a large number of parameters, which leads to serious over-parameterization and typically causes the underutilization of computational resources. In response to this problem, we empirically investigate whether the redundant parameters can be reused to achieve better performance. Experiments and analyses are systematically conducted on different datasets and NMT architectures. We show that: 1) the pruned parameters can be rejuvenated to improve the baseline model by up to +0.8 BLEU points; 2) the rejuvenated parameters are reallocated to enhance the ability of modeling low-level lexical information.
Facial Action Unit Intensity Estimation via Semantic Correspondence Learning with Dynamic Graph Convolution
Apr 20, 2020
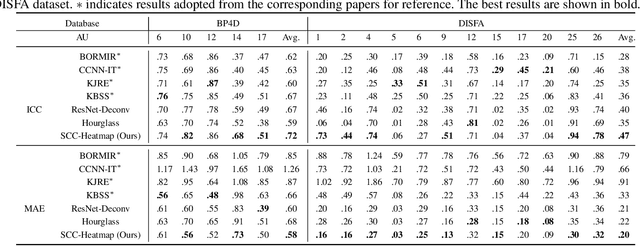
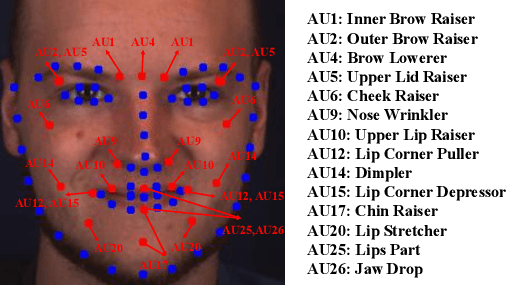
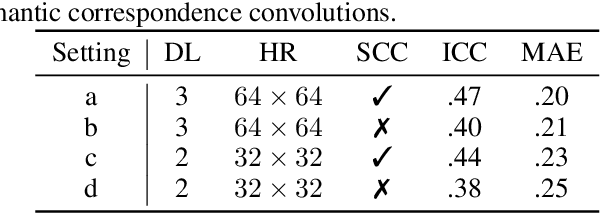
The intensity estimation of facial action units (AUs) is challenging due to subtle changes in the person's facial appearance. Previous approaches mainly rely on probabilistic models or predefined rules for modeling co-occurrence relationships among AUs, leading to limited generalization. In contrast, we present a new learning framework that automatically learns the latent relationships of AUs via establishing semantic correspondences between feature maps. In the heatmap regression-based network, feature maps preserve rich semantic information associated with AU intensities and locations. Moreover, the AU co-occurring pattern can be reflected by activating a set of feature channels, where each channel encodes a specific visual pattern of AU. This motivates us to model the correlation among feature channels, which implicitly represents the co-occurrence relationship of AU intensity levels. Specifically, we introduce a semantic correspondence convolution (SCC) module to dynamically compute the correspondences from deep and low resolution feature maps, and thus enhancing the discriminability of features. The experimental results demonstrate the effectiveness and the superior performance of our method on two benchmark datasets.
Go From the General to the Particular: Multi-Domain Translation with Domain Transformation Networks
Nov 22, 2019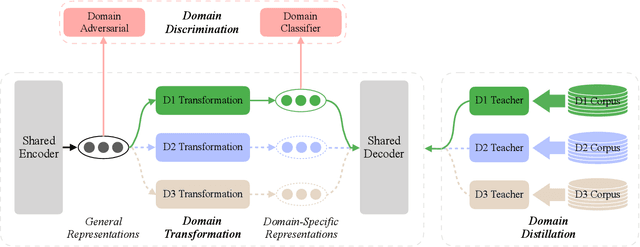
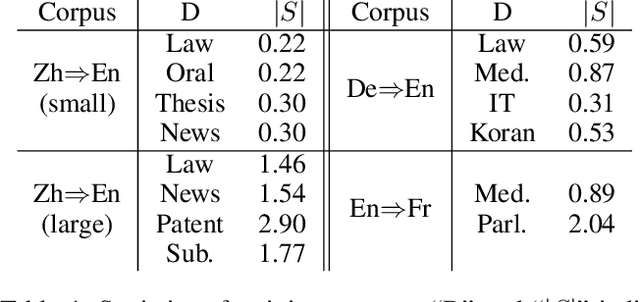
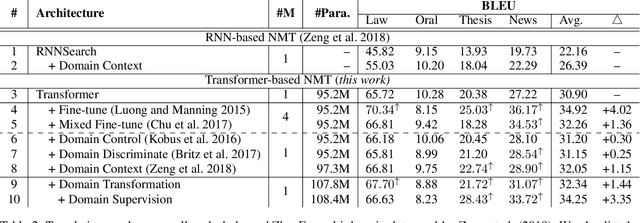
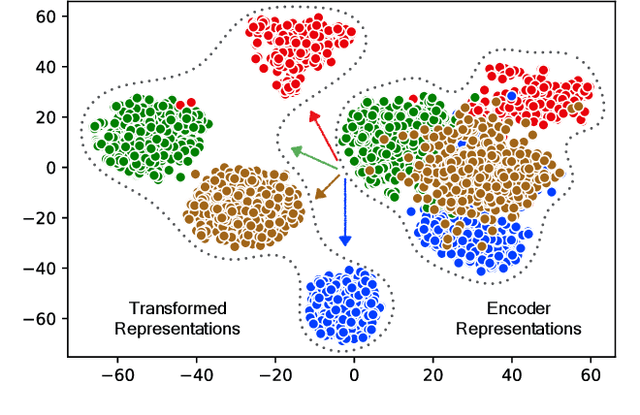
The key challenge of multi-domain translation lies in simultaneously encoding both the general knowledge shared across domains and the particular knowledge distinctive to each domain in a unified model. Previous work shows that the standard neural machine translation (NMT) model, trained on mixed-domain data, generally captures the general knowledge, but misses the domain-specific knowledge. In response to this problem, we augment NMT model with additional domain transformation networks to transform the general representations to domain-specific representations, which are subsequently fed to the NMT decoder. To guarantee the knowledge transformation, we also propose two complementary supervision signals by leveraging the power of knowledge distillation and adversarial learning. Experimental results on several language pairs, covering both balanced and unbalanced multi-domain translation, demonstrate the effectiveness and universality of the proposed approach. Encouragingly, the proposed unified model achieves comparable results with the fine-tuning approach that requires multiple models to preserve the particular knowledge. Further analyses reveal that the domain transformation networks successfully capture the domain-specific knowledge as expected.
Improved Zero-shot Neural Machine Translation via Ignoring Spurious Correlations
Jun 04, 2019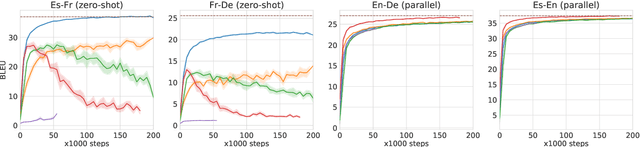

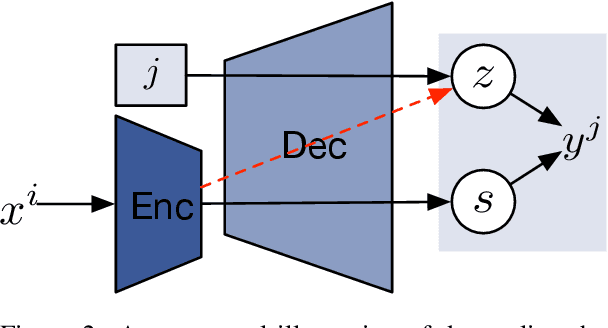
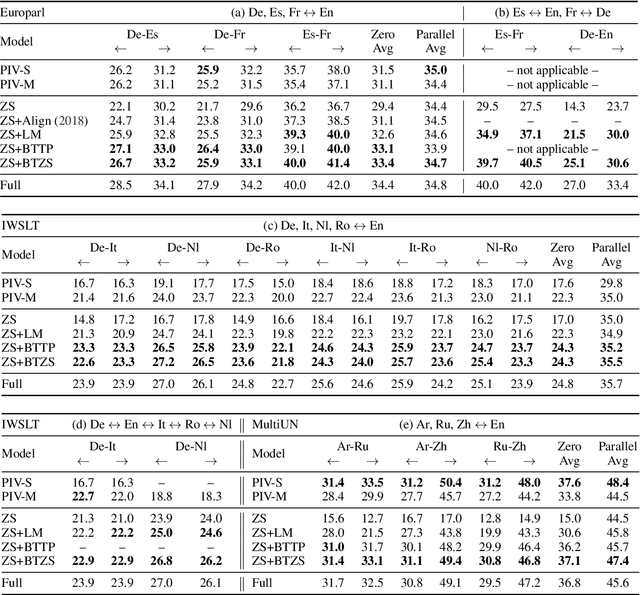
Zero-shot translation, translating between language pairs on which a Neural Machine Translation (NMT) system has never been trained, is an emergent property when training the system in multilingual settings. However, naive training for zero-shot NMT easily fails, and is sensitive to hyper-parameter setting. The performance typically lags far behind the more conventional pivot-based approach which translates twice using a third language as a pivot. In this work, we address the degeneracy problem due to capturing spurious correlations by quantitatively analyzing the mutual information between language IDs of the source and decoded sentences. Inspired by this analysis, we propose to use two simple but effective approaches: (1) decoder pre-training; (2) back-translation. These methods show significant improvement (4~22 BLEU points) over the vanilla zero-shot translation on three challenging multilingual datasets, and achieve similar or better results than the pivot-based approach.
Large Margin Few-Shot Learning
Sep 21, 2018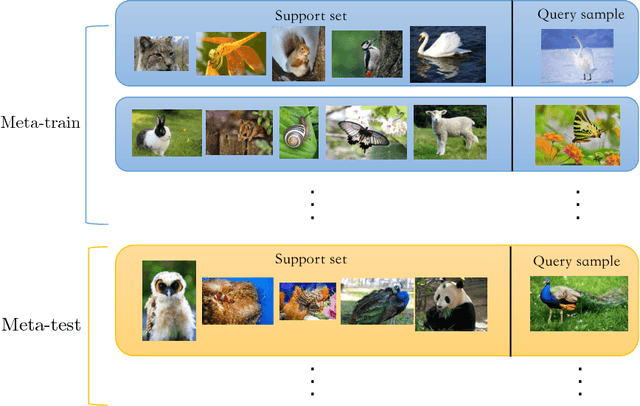
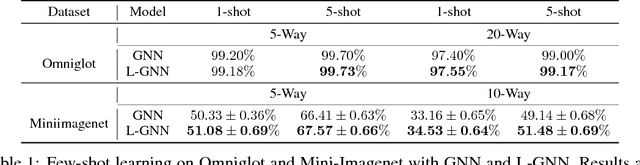
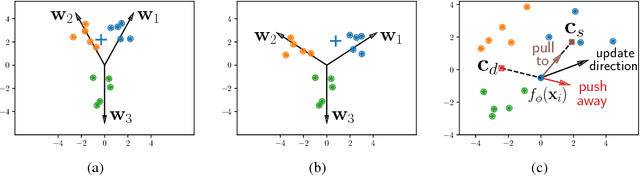
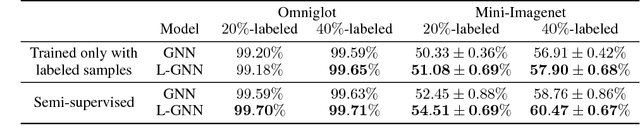
The key issue of few-shot learning is learning to generalize. This paper proposes a large margin principle to improve the generalization capacity of metric based methods for few-shot learning. To realize it, we develop a unified framework to learn a more discriminative metric space by augmenting the classification loss function with a large margin distance loss function for training. Extensive experiments on two state-of-the-art few-shot learning methods, graph neural networks and prototypical networks, show that our method can improve the performance of existing models substantially with very little computational overhead, demonstrating the effectiveness of the large margin principle and the potential of our method.
A Stable and Effective Learning Strategy for Trainable Greedy Decoding
Aug 28, 2018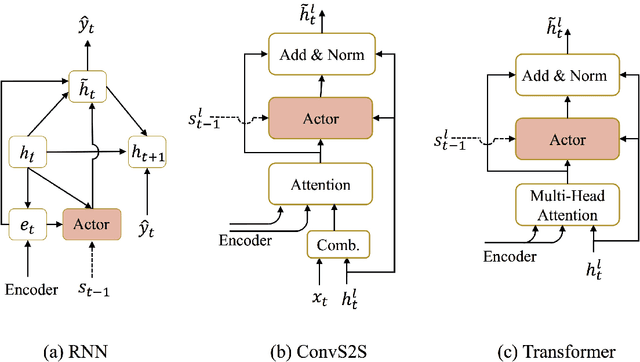
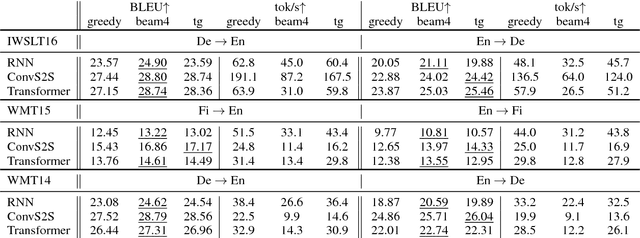
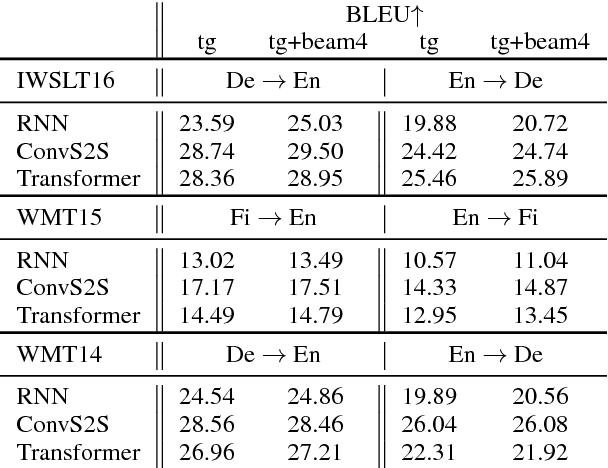
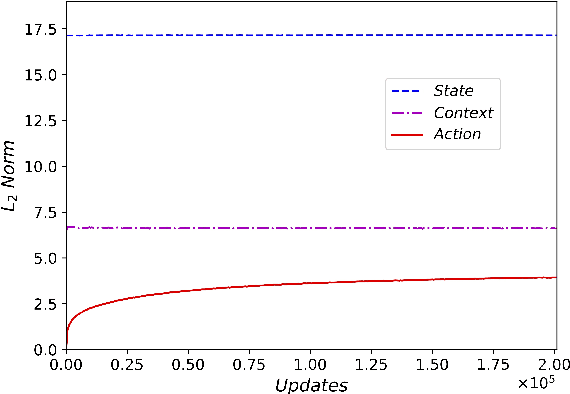
Beam search is a widely used approximate search strategy for neural network decoders, and it generally outperforms simple greedy decoding on tasks like machine translation. However, this improvement comes at substantial computational cost. In this paper, we propose a flexible new method that allows us to reap nearly the full benefits of beam search with nearly no additional computational cost. The method revolves around a small neural network actor that is trained to observe and manipulate the hidden state of a previously-trained decoder. To train this actor network, we introduce the use of a pseudo-parallel corpus built using the output of beam search on a base model, ranked by a target quality metric like BLEU. Our method is inspired by earlier work on this problem, but requires no reinforcement learning, and can be trained reliably on a range of models. Experiments on three parallel corpora and three architectures show that the method yields substantial improvements in translation quality and speed over each base system.
Meta-Learning for Low-Resource Neural Machine Translation
Aug 25, 2018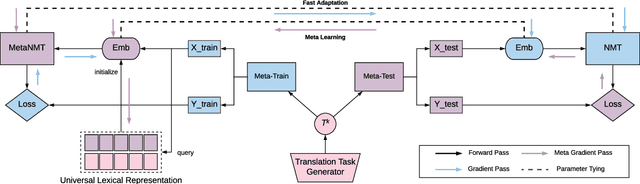
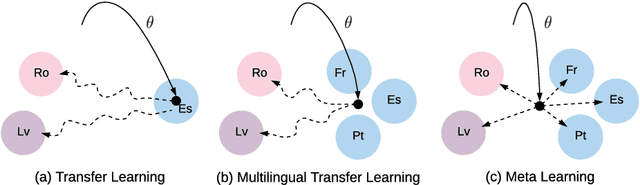
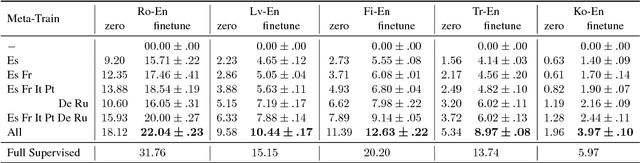
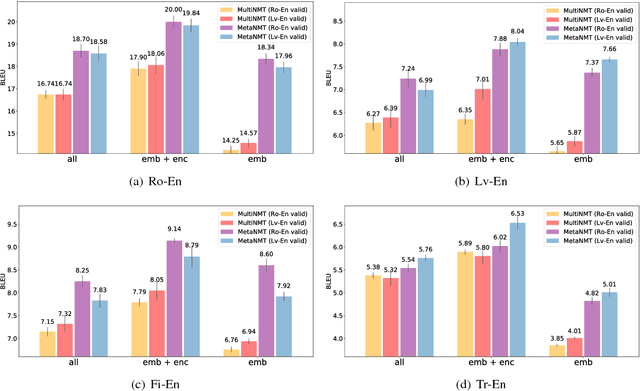
In this paper, we propose to extend the recently introduced model-agnostic meta-learning algorithm (MAML) for low-resource neural machine translation (NMT). We frame low-resource translation as a meta-learning problem, and we learn to adapt to low-resource languages based on multilingual high-resource language tasks. We use the universal lexical representation~\citep{gu2018universal} to overcome the input-output mismatch across different languages. We evaluate the proposed meta-learning strategy using eighteen European languages (Bg, Cs, Da, De, El, Es, Et, Fr, Hu, It, Lt, Nl, Pl, Pt, Sk, Sl, Sv and Ru) as source tasks and five diverse languages (Ro, Lv, Fi, Tr and Ko) as target tasks. We show that the proposed approach significantly outperforms the multilingual, transfer learning based approach~\citep{zoph2016transfer} and enables us to train a competitive NMT system with only a fraction of training examples. For instance, the proposed approach can achieve as high as 22.04 BLEU on Romanian-English WMT'16 by seeing only 16,000 translated words (~600 parallel sentences).