 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Circumplex Degeneracy Behind the Rare-Class Limit in Affect Recognition
Jun 14, 2026In-the-wild expression recognition persistently fails on a few rare emotions, and the standard explanation is class imbalance. Through a controlled multi-task study on two benchmarks, we show the failure is instead a property of affect geometry: the rare classes are degenerate on Russell's circumplex, and that degeneracy bounds what any loss or cost can achieve. Our instrument is a circumplex-cost optimal-transport term that prices expression confusions by their valence-arousal distance. The term improves the official score and expression macro-F1, but a control most studies omit shows the gain is not geometric: a uniform cost, equivalent to a generic confidence penalty, matches it on Aff-Wild2 (p=0.625) and significantly exceeds it on AffectNet (+0.057 over base, larger than the circumplex). What the geometry reshapes is the structure of the errors, making them affectively nearer the truth on Aff-Wild2 (p=0.031 against the uniform control), an effect that does not survive on AffectNet, where a visual confound at the far corner of the circumplex overwhelms it. The rare-class failure, by contrast, is stable across both datasets we examine: the degenerate pairs (anger-fear on Aff-Wild2, anger-contempt on AffectNet) resist frequency-based interventions, the transport term, and an action-unit-augmented cost built specifically to separate them. We conclude that progress on rare expressions requires representations that distinguish the classes, not supervision that reprices their confusions, and we provide the controls and metrics needed to tell the two apart.
Faithful Action-unit Causal Reasoning for Counterfactually Faithful Emotion Explanations
Jun 14, 2026Multimodal models can name the action units (AUs) behind a facial emotion, but their AU->emotion rationales are typically plausible rather than faithful: nothing forces the AUs a model invokes to be the AUs that actually drive its prediction. We cast AU->emotion reasoning as a counterfactual-consistency problem between the rationale, the label, and a structural AU->emotion causal graph G, and propose FACR, which grounds the reasoner in an independently induced, polarity-aware G and trains a counterfactual-faithfulness objective: a do-intervention on an AU that G marks causal for a class must move the prediction, while one it marks irrelevant must leave it unchanged. Faithfulness is thereby both trainable and measurable through a matching interventional metric, which we evaluate against a known causal structure, the PSPI pain-AU composition, as no existing affective-reasoning benchmark allows. We are explicit that this metric tests fidelity to the supplied structure rather than its rediscovery: it asks whether the trained reasoner invokes the AUs the structure marks causal, on held-out subjects and a second dataset. Under subject-independent evaluation on UNBC-PAIN, the objective raises the agreement between the invoked AUs and the PSPI composition from a no-objective baseline of 0.08 to 0.57, at a small detection cost; an unfaithfulness control attributes the gain to the objective. On a cross-dataset emotion transfer, the objective likewise raises fidelity to G on a seven-class task (0.50 to 0.84). Finally, we attach a language verbalizer and extend the audit to the generated text: biasing each action unit's emission by its latent activation makes the rationale faithful by construction, so that ablating an AU removes it from the explanation, a property that transfers to a second language-model backbone, whereas a freely generated rationale is unfaithful.
Adaptation of Distinct Semantics for Uncertain Areas in Polyp Segmentation
May 13, 2024



Colonoscopy is a common and practical method for detecting and treating polyps. Segmenting polyps from colonoscopy image is useful for diagnosis and surgery progress. Nevertheless, achieving excellent segmentation performance is still difficult because of polyp characteristics like shape, color, condition, and obvious non-distinction from the surrounding context. This work presents a new novel architecture namely Adaptation of Distinct Semantics for Uncertain Areas in Polyp Segmentation (ADSNet), which modifies misclassified details and recovers weak features having the ability to vanish and not be detected at the final stage. The architecture consists of a complementary trilateral decoder to produce an early global map. A continuous attention module modifies semantics of high-level features to analyze two separate semantics of the early global map. The suggested method is experienced on polyp benchmarks in learning ability and generalization ability, experimental results demonstrate the great correction and recovery ability leading to better segmentation performance compared to the other state of the art in the polyp image segmentation task. Especially, the proposed architecture could be experimented flexibly for other CNN-based encoders, Transformer-based encoders, and decoder backbones.
DCTM: Dilated Convolutional Transformer Model for Multimodal Engagement Estimation in Conversation
Jul 31, 2023



Conversational engagement estimation is posed as a regression problem, entailing the identification of the favorable attention and involvement of the participants in the conversation. This task arises as a crucial pursuit to gain insights into human's interaction dynamics and behavior patterns within a conversation. In this research, we introduce a dilated convolutional Transformer for modeling and estimating human engagement in the MULTIMEDIATE 2023 competition. Our proposed system surpasses the baseline models, exhibiting a noteworthy $7$\% improvement on test set and $4$\% on validation set. Moreover, we employ different modality fusion mechanism and show that for this type of data, a simple concatenated method with self-attention fusion gains the best performance.
Multi-scale Transformer-based Network for Emotion Recognition from Multi Physiological Signals
May 08, 2023This paper presents an efficient Multi-scale Transformer-based approach for the task of Emotion recognition from Physiological data, which has gained widespread attention in the research community due to the vast amount of information that can be extracted from these signals using modern sensors and machine learning techniques. Our approach involves applying a Multi-modal technique combined with scaling data to establish the relationship between internal body signals and human emotions. Additionally, we utilize Transformer and Gaussian Transformation techniques to improve signal encoding effectiveness and overall performance. Our model achieves decent results on the CASE dataset of the EPiC competition, with an RMSE score of 1.45.
Vision Transformer for Action Units Detection
Mar 20, 2023


Facial Action Units detection (FAUs) represents a fine-grained classification problem that involves identifying different units on the human face, as defined by the Facial Action Coding System. In this paper, we present a simple yet efficient Vision Transformer-based approach for addressing the task of Action Units (AU) detection in the context of Affective Behavior Analysis in-the-wild (ABAW) competition. We employ the Video Vision Transformer(ViViT) Network to capture the temporal facial change in the video. Besides, to reduce massive size of the Vision Transformers model, we replace the ViViT feature extraction layers with the CNN backbone (Regnet). Our model outperform the baseline model of ABAW 2023 challenge, with a notable 14% difference in result. Furthermore, the achieved results are comparable to those of the top three teams in the previous ABAW 2022 challenge.
Generic Event Boundary Detection in Video with Pyramid Features
Jan 11, 2023



Generic event boundary detection (GEBD) aims to split video into chunks at a broad and diverse set of actions as humans naturally perceive event boundaries. In this study, we present an approach that considers the correlation between neighbor frames with pyramid feature maps in both spatial and temporal dimensions to construct a framework for localizing generic events in video. The features at multiple spatial dimensions of a pre-trained ResNet-50 are exploited with different views in the temporal dimension to form a temporal pyramid feature map. Based on that, the similarity between neighbor frames is calculated and projected to build a temporal pyramid similarity feature vector. A decoder with 1D convolution operations is used to decode these similarities to a new representation that incorporates their temporal relationship for later boundary score estimation. Extensive experiments conducted on the GEBD benchmark dataset show the effectiveness of our system and its variations, in which we outperformed the state-of-the-art approaches. Additional experiments on TAPOS dataset, which contains long-form videos with Olympic sport actions, demonstrated the effectiveness of our study compared to others.
The 1st Agriculture-Vision Challenge: Methods and Results
Apr 23, 2020
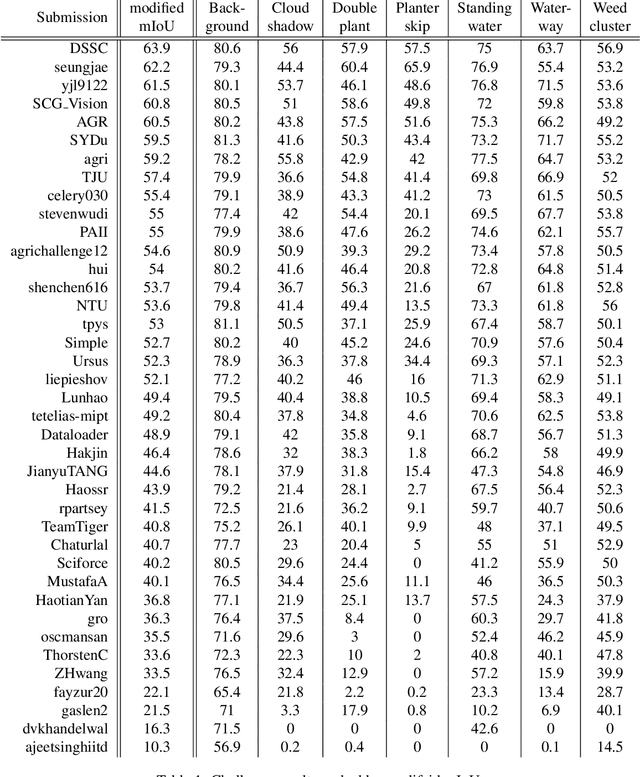
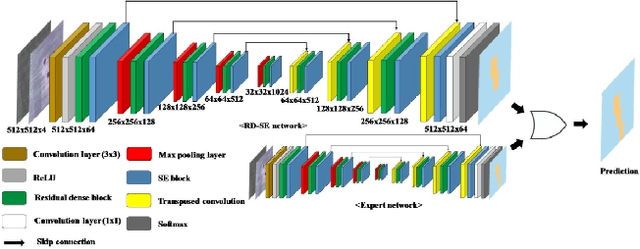
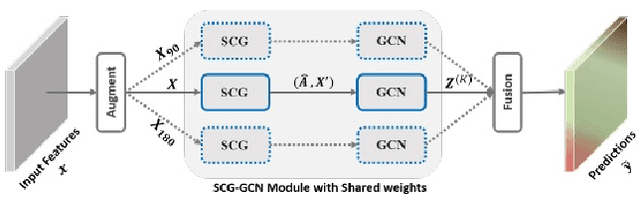
The first Agriculture-Vision Challenge aims to encourage research in developing novel and effective algorithms for agricultural pattern recognition from aerial images, especially for the semantic segmentation task associated with our challenge dataset. Around 57 participating teams from various countries compete to achieve state-of-the-art in aerial agriculture semantic segmentation. The Agriculture-Vision Challenge Dataset was employed, which comprises of 21,061 aerial and multi-spectral farmland images. This paper provides a summary of notable methods and results in the challenge. Our submission server and leaderboard will continue to open for researchers that are interested in this challenge dataset and task; the link can be found here.
Eye Semantic Segmentation with a Lightweight Model
Nov 04, 2019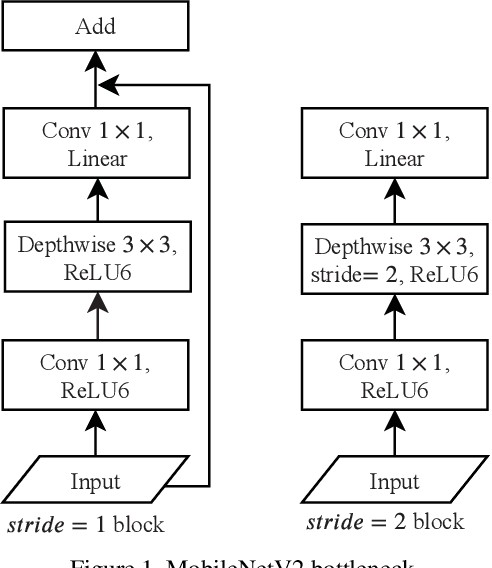
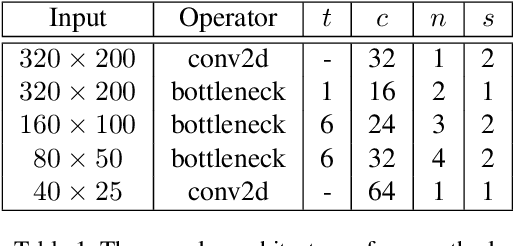
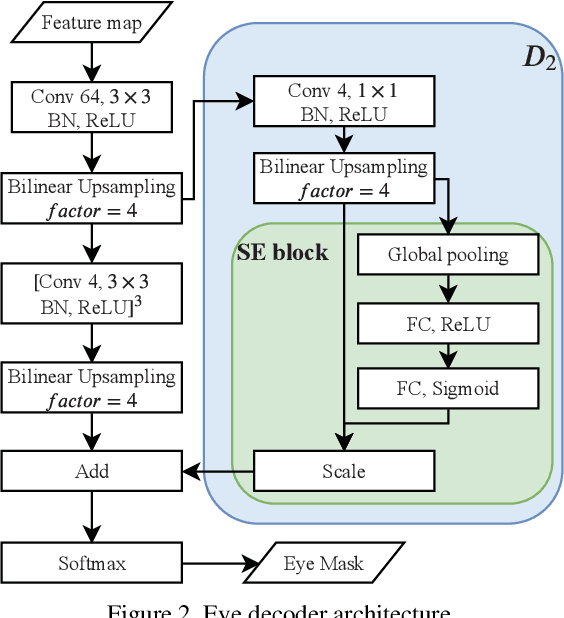
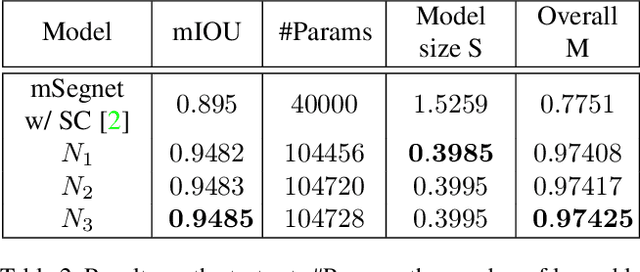
In this paper, we present a multi-class eye segmentation method that can run the hardware limitations for real-time inference. Our approach includes three major stages: get a grayscale image from the input, segment three distinct eye region with a deep network, and remove incorrect areas with heuristic filters. Our model based on the encoder decoder structure with the key is the depthwise convolution operation to reduce the computation cost. We experiment on OpenEDS, a large scale dataset of eye images captured by a head-mounted display with two synchronized eye facing cameras. We achieved the mean intersection over union (mIoU) of 94.85% with a model of size 0.4 megabytes. The source code are available https://github.com/th2l/Eye_VR_Segmentation