 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Concept Models: Permitting Stakeholder Customisation at Test-Time
Jun 14, 2023Concept-based models perform prediction using a set of concepts that are interpretable to stakeholders. However, such models often involve a fixed, large number of concepts, which may place a substantial cognitive load on stakeholders. We propose Selective COncept Models (SCOMs) which make predictions using only a subset of concepts and can be customised by stakeholders at test-time according to their preferences. We show that SCOMs only require a fraction of the total concepts to achieve optimal accuracy on multiple real-world datasets. Further, we collect and release a new dataset, CUB-Sel, consisting of human concept set selections for 900 bird images from the popular CUB dataset. Using CUB-Sel, we show that humans have unique individual preferences for the choice of concepts they prefer to reason about, and struggle to identify the most theoretically informative concepts. The customisation and concept selection provided by SCOM improves the efficiency of interpretation and intervention for stakeholders.
Evaluating Language Models for Mathematics through Interactions
Jun 02, 2023The standard methodology of evaluating large language models (LLMs) based on static pairs of inputs and outputs is insufficient for developing assistants: this kind of assessments fails to take into account the essential interactive element in their deployment, and therefore limits how we understand language model capabilities. We introduce CheckMate, an adaptable prototype platform for humans to interact with and evaluate LLMs. We conduct a study with CheckMate to evaluate three language models~(InstructGPT, ChatGPT, and GPT-4) as assistants in proving undergraduate-level mathematics, with a mixed cohort of participants from undergraduate students to professors of mathematics. We release the resulting interaction and rating dataset, MathConverse. By analysing MathConverse, we derive a preliminary taxonomy of human behaviours and uncover that despite a generally positive correlation, there are notable instances of divergence between correctness and perceived helpfulness in LLM generations, amongst other findings. Further, we identify useful scenarios and existing issues of GPT-4 in mathematical reasoning through a series of case studies contributed by expert mathematicians. We conclude with actionable takeaways for ML practitioners and mathematicians: models which communicate uncertainty, respond well to user corrections, are more interpretable and concise may constitute better assistants; interactive evaluation is a promising way to continually navigate the capability of these models; humans should be aware of language models' algebraic fallibility, and for that reason discern where they should be used.
Learning Personalized Decision Support Policies
Apr 13, 2023



Individual human decision-makers may benefit from different forms of support to improve decision outcomes. However, a key question is which form of support will lead to accurate decisions at a low cost. In this work, we propose learning a decision support policy that, for a given input, chooses which form of support, if any, to provide. We consider decision-makers for whom we have no prior information and formalize learning their respective policies as a multi-objective optimization problem that trades off accuracy and cost. Using techniques from stochastic contextual bandits, we propose $\texttt{THREAD}$, an online algorithm to personalize a decision support policy for each decision-maker, and devise a hyper-parameter tuning strategy to identify a cost-performance trade-off using simulated human behavior. We provide computational experiments to demonstrate the benefits of $\texttt{THREAD}$ compared to offline baselines. We then introduce $\texttt{Modiste}$, an interactive tool that provides $\texttt{THREAD}$ with an interface. We conduct human subject experiments to show how $\texttt{Modiste}$ learns policies personalized to each decision-maker and discuss the nuances of learning decision support policies online for real users.
Human Uncertainty in Concept-Based AI Systems
Mar 22, 2023Placing a human in the loop may abate the risks of deploying AI systems in safety-critical settings (e.g., a clinician working with a medical AI system). However, mitigating risks arising from human error and uncertainty within such human-AI interactions is an important and understudied issue. In this work, we study human uncertainty in the context of concept-based models, a family of AI systems that enable human feedback via concept interventions where an expert intervenes on human-interpretable concepts relevant to the task. Prior work in this space often assumes that humans are oracles who are always certain and correct. Yet, real-world decision-making by humans is prone to occasional mistakes and uncertainty. We study how existing concept-based models deal with uncertain interventions from humans using two novel datasets: UMNIST, a visual dataset with controlled simulated uncertainty based on the MNIST dataset, and CUB-S, a relabeling of the popular CUB concept dataset with rich, densely-annotated soft labels from humans. We show that training with uncertain concept labels may help mitigate weaknesses of concept-based systems when handling uncertain interventions. These results allow us to identify several open challenges, which we argue can be tackled through future multidisciplinary research on building interactive uncertainty-aware systems. To facilitate further research, we release a new elicitation platform, UElic, to collect uncertain feedback from humans in collaborative prediction tasks.
Towards Robust Metrics for Concept Representation Evaluation
Jan 25, 2023



Recent work on interpretability has focused on concept-based explanations, where deep learning models are explained in terms of high-level units of information, referred to as concepts. Concept learning models, however, have been shown to be prone to encoding impurities in their representations, failing to fully capture meaningful features of their inputs. While concept learning lacks metrics to measure such phenomena, the field of disentanglement learning has explored the related notion of underlying factors of variation in the data, with plenty of metrics to measure the purity of such factors. In this paper, we show that such metrics are not appropriate for concept learning and propose novel metrics for evaluating the purity of concept representations in both approaches. We show the advantage of these metrics over existing ones and demonstrate their utility in evaluating the robustness of concept representations and interventions performed on them. In addition, we show their utility for benchmarking state-of-the-art methods from both families and find that, contrary to common assumptions, supervision alone may not be sufficient for pure concept representations.
Web-based Elicitation of Human Perception on mixup Data
Nov 02, 2022



Synthetic data is proliferating on the web and powering many advances in machine learning. However, it is not always clear if synthetic labels are perceptually sensible to humans. The web provides us with a platform to take a step towards addressing this question through online elicitation. We design a series of elicitation interfaces, which we release as \texttt{HILL MixE Suite}, and recruit 159 participants, to provide perceptual judgments over the kinds of synthetic data constructed during \textit{mixup} training: a powerful regularizer shown to improve model robustness, generalization, and calibration. We find that human perception does not consistently align with the labels traditionally used for synthetic points and begin to demonstrate the applicability of these findings to potentially increase the reliability of downstream models. We release all elicited judgments in a new data hub we call \texttt{H-Mix}.
Iterative Teaching by Data Hallucination
Oct 31, 2022



We consider the problem of iterative machine teaching, where a teacher sequentially provides examples based on the status of a learner under a discrete input space (i.e., a pool of finite samples), which greatly limits the teacher's capability. To address this issue, we study iterative teaching under a continuous input space where the input example (i.e., image) can be either generated by solving an optimization problem or drawn directly from a continuous distribution. Specifically, we propose data hallucination teaching (DHT) where the teacher can generate input data intelligently based on labels, the learner's status and the target concept. We study a number of challenging teaching setups (e.g., linear/neural learners in omniscient and black-box settings). Extensive empirical results verify the effectiveness of DHT.
Uncertainty Quantification with Pre-trained Language Models: A Large-Scale Empirical Analysis
Oct 10, 2022
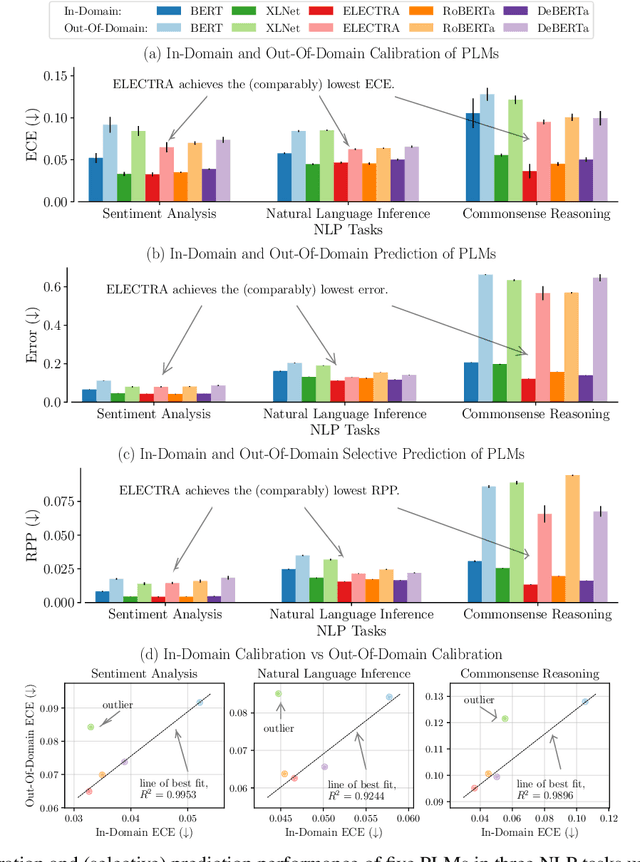
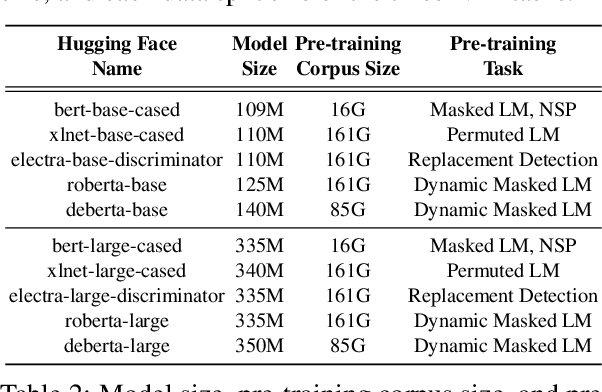
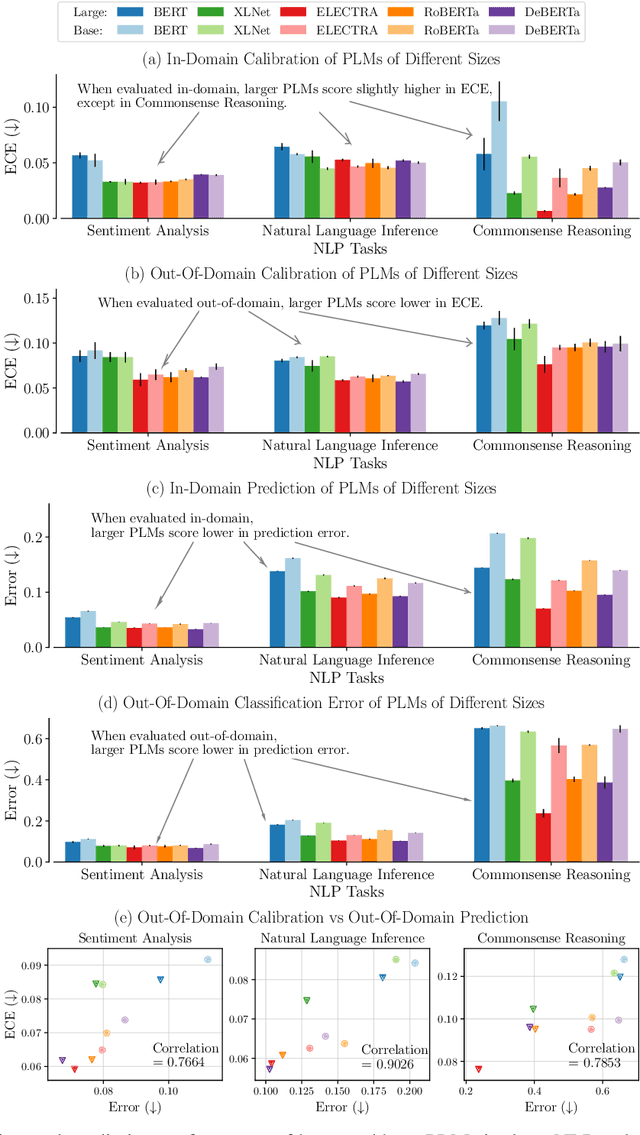
Pre-trained language models (PLMs) have gained increasing popularity due to their compelling prediction performance in diverse natural language processing (NLP) tasks. When formulating a PLM-based prediction pipeline for NLP tasks, it is also crucial for the pipeline to minimize the calibration error, especially in safety-critical applications. That is, the pipeline should reliably indicate when we can trust its predictions. In particular, there are various considerations behind the pipeline: (1) the choice and (2) the size of PLM, (3) the choice of uncertainty quantifier, (4) the choice of fine-tuning loss, and many more. Although prior work has looked into some of these considerations, they usually draw conclusions based on a limited scope of empirical studies. There still lacks a holistic analysis on how to compose a well-calibrated PLM-based prediction pipeline. To fill this void, we compare a wide range of popular options for each consideration based on three prevalent NLP classification tasks and the setting of domain shift. In response, we recommend the following: (1) use ELECTRA for PLM encoding, (2) use larger PLMs if possible, (3) use Temp Scaling as the uncertainty quantifier, and (4) use Focal Loss for fine-tuning.
Towards the Use of Saliency Maps for Explaining Low-Quality Electrocardiograms to End Users
Jul 06, 2022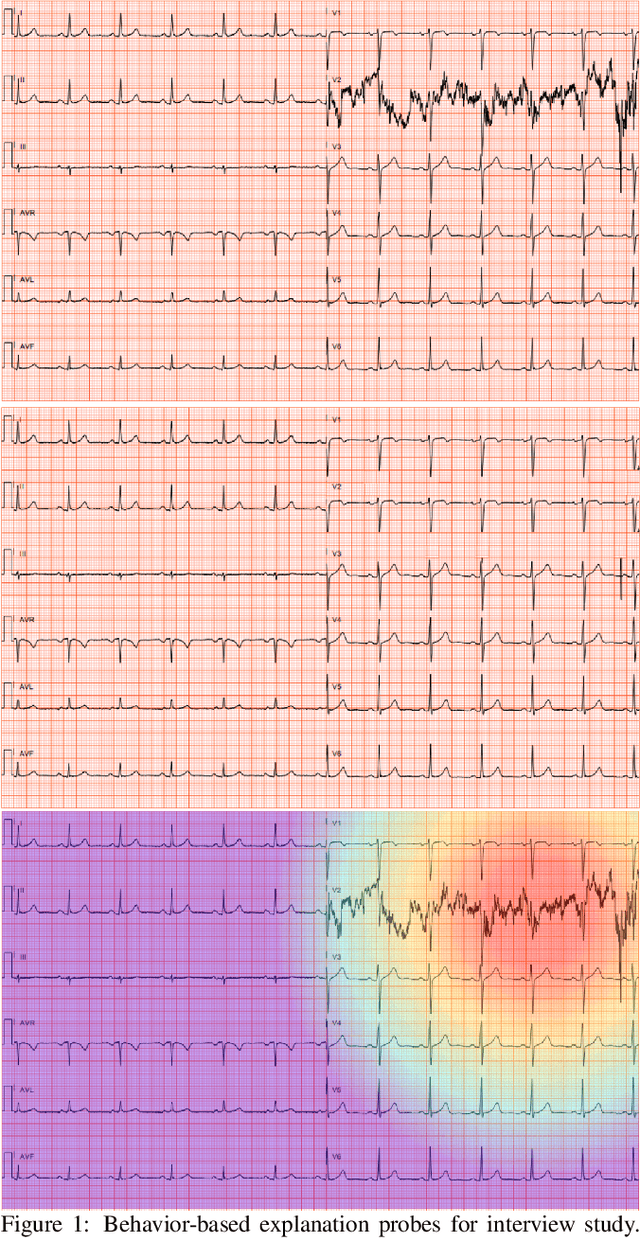

When using medical images for diagnosis, either by clinicians or artificial intelligence (AI) systems, it is important that the images are of high quality. When an image is of low quality, the medical exam that produced the image often needs to be redone. In telemedicine, a common problem is that the quality issue is only flagged once the patient has left the clinic, meaning they must return in order to have the exam redone. This can be especially difficult for people living in remote regions, who make up a substantial portion of the patients at Portal Telemedicina, a digital healthcare organization based in Brazil. In this paper, we report on ongoing work regarding (i) the development of an AI system for flagging and explaining low-quality medical images in real-time, (ii) an interview study to understand the explanation needs of stakeholders using the AI system at OurCompany, and, (iii) a longitudinal user study design to examine the effect of including explanations on the workflow of the technicians in our clinics. To the best of our knowledge, this would be the first longitudinal study on evaluating the effects of XAI methods on end-users -- stakeholders that use AI systems but do not have AI-specific expertise. We welcome feedback and suggestions on our experimental setup.
Eliciting and Learning with Soft Labels from Every Annotator
Jul 02, 2022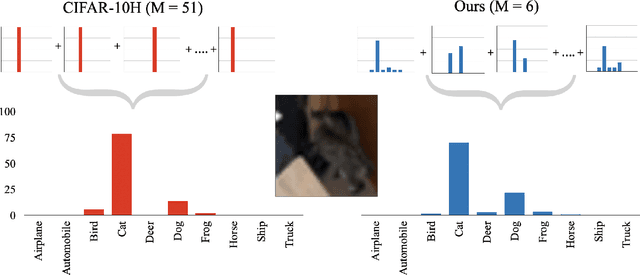

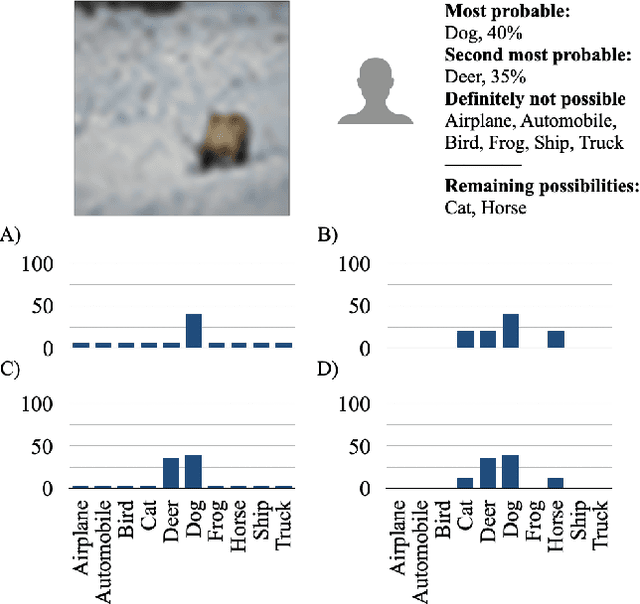

The labels used to train machine learning (ML) models are of paramount importance. Typically for ML classification tasks, datasets contain hard labels, yet learning using soft labels has been shown to yield benefits for model generalization, robustness, and calibration. Earlier work found success in forming soft labels from multiple annotators' hard labels; however, this approach may not converge to the best labels and necessitates many annotators, which can be expensive and inefficient. We focus on efficiently eliciting soft labels from individual annotators. We collect and release a dataset of soft labels for CIFAR-10 via a crowdsourcing study ($N=242$). We demonstrate that learning with our labels achieves comparable model performance to prior approaches while requiring far fewer annotators. Our elicitation methodology therefore shows promise towards enabling practitioners to enjoy the benefits of improved model performance and reliability with fewer annotators, and serves as a guide for future dataset curators on the benefits of leveraging richer information, such as categorical uncertainty, from individual annotators.