 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTighter sparse variational Gaussian processes
Feb 07, 2025Sparse variational Gaussian process (GP) approximations based on inducing points have become the de facto standard for scaling GPs to large datasets, owing to their theoretical elegance, computational efficiency, and ease of implementation. This paper introduces a provably tighter variational approximation by relaxing the standard assumption that the conditional approximate posterior given the inducing points must match that in the prior. The key innovation is to modify the conditional posterior to have smaller variances than that of the prior at the training points. We derive the collapsed bound for the regression case, describe how to use the proposed approximation in large data settings, and discuss its application to handle orthogonally structured inducing points and GP latent variable models. Extensive experiments on regression benchmarks, classification, and latent variable models demonstrate that the proposed approximation consistently matches or outperforms standard sparse variational GPs while maintaining the same computational cost. An implementation will be made available in all popular GP packages.
A Meta-Learning Approach to Bayesian Causal Discovery
Dec 21, 2024



Discovering a unique causal structure is difficult due to both inherent identifiability issues, and the consequences of finite data. As such, uncertainty over causal structures, such as those obtained from a Bayesian posterior, are often necessary for downstream tasks. Finding an accurate approximation to this posterior is challenging, due to the large number of possible causal graphs, as well as the difficulty in the subproblem of finding posteriors over the functional relationships of the causal edges. Recent works have used meta-learning to view the problem of estimating the maximum a-posteriori causal graph as supervised learning. Yet, these methods are limited when estimating the full posterior as they fail to encode key properties of the posterior, such as correlation between edges and permutation equivariance with respect to nodes. Further, these methods also cannot reliably sample from the posterior over causal structures. To address these limitations, we propose a Bayesian meta learning model that allows for sampling causal structures from the posterior and encodes these key properties. We compare our meta-Bayesian causal discovery against existing Bayesian causal discovery methods, demonstrating the advantages of directly learning a posterior over causal structure.
Gridded Transformer Neural Processes for Large Unstructured Spatio-Temporal Data
Oct 10, 2024Many important problems require modelling large-scale spatio-temporal datasets, with one prevalent example being weather forecasting. Recently, transformer-based approaches have shown great promise in a range of weather forecasting problems. However, these have mostly focused on gridded data sources, neglecting the wealth of unstructured, off-the-grid data from observational measurements such as those at weather stations. A promising family of models suitable for such tasks are neural processes (NPs), notably the family of transformer neural processes (TNPs). Although TNPs have shown promise on small spatio-temporal datasets, they are unable to scale to the quantities of data used by state-of-the-art weather and climate models. This limitation stems from their lack of efficient attention mechanisms. We address this shortcoming through the introduction of gridded pseudo-token TNPs which employ specialised encoders and decoders to handle unstructured observations and utilise a processor containing gridded pseudo-tokens that leverage efficient attention mechanisms. Our method consistently outperforms a range of strong baselines on various synthetic and real-world regression tasks involving large-scale data, while maintaining competitive computational efficiency. The real-life experiments are performed on weather data, demonstrating the potential of our approach to bring performance and computational benefits when applied at scale in a weather modelling pipeline.
Approximately Equivariant Neural Processes
Jun 19, 2024



Equivariant deep learning architectures exploit symmetries in learning problems to improve the sample efficiency of neural-network-based models and their ability to generalise. However, when modelling real-world data, learning problems are often not exactly equivariant, but only approximately. For example, when estimating the global temperature field from weather station observations, local topographical features like mountains break translation equivariance. In these scenarios, it is desirable to construct architectures that can flexibly depart from exact equivariance in a data-driven way. In this paper, we develop a general approach to achieving this using existing equivariant architectures. Our approach is agnostic to both the choice of symmetry group and model architecture, making it widely applicable. We consider the use of approximately equivariant architectures in neural processes (NPs), a popular family of meta-learning models. We demonstrate the effectiveness of our approach on a number of synthetic and real-world regression experiments, demonstrating that approximately equivariant NP models can outperform both their non-equivariant and strictly equivariant counterparts.
In-Context In-Context Learning with Transformer Neural Processes
Jun 19, 2024



Neural processes (NPs) are a powerful family of meta-learning models that seek to approximate the posterior predictive map of the ground-truth stochastic process from which each dataset in a meta-dataset is sampled. There are many cases in which practitioners, besides having access to the dataset of interest, may also have access to other datasets that share similarities with it. In this case, integrating these datasets into the NP can improve predictions. We equip NPs with this functionality and describe this paradigm as in-context in-context learning. Standard NP architectures, such as the convolutional conditional NP (ConvCNP) or the family of transformer neural processes (TNPs), are not capable of in-context in-context learning, as they are only able to condition on a single dataset. We address this shortcoming by developing the in-context in-context learning pseudo-token TNP (ICICL-TNP). The ICICL-TNP builds on the family of PT-TNPs, which utilise pseudo-token-based transformer architectures to sidestep the quadratic computational complexity associated with regular transformer architectures. Importantly, the ICICL-TNP is capable of conditioning on both sets of datapoints and sets of datasets, enabling it to perform in-context in-context learning. We demonstrate the importance of in-context in-context learning and the effectiveness of the ICICL-TNP in a number of experiments.
Translation Equivariant Transformer Neural Processes
Jun 18, 2024



The effectiveness of neural processes (NPs) in modelling posterior prediction maps -- the mapping from data to posterior predictive distributions -- has significantly improved since their inception. This improvement can be attributed to two principal factors: (1) advancements in the architecture of permutation invariant set functions, which are intrinsic to all NPs; and (2) leveraging symmetries present in the true posterior predictive map, which are problem dependent. Transformers are a notable development in permutation invariant set functions, and their utility within NPs has been demonstrated through the family of models we refer to as TNPs. Despite significant interest in TNPs, little attention has been given to incorporating symmetries. Notably, the posterior prediction maps for data that are stationary -- a common assumption in spatio-temporal modelling -- exhibit translation equivariance. In this paper, we introduce of a new family of translation equivariant TNPs that incorporate translation equivariance. Through an extensive range of experiments on synthetic and real-world spatio-temporal data, we demonstrate the effectiveness of TE-TNPs relative to their non-translation-equivariant counterparts and other NP baselines.
Noise-Aware Differentially Private Regression via Meta-Learning
Jun 12, 2024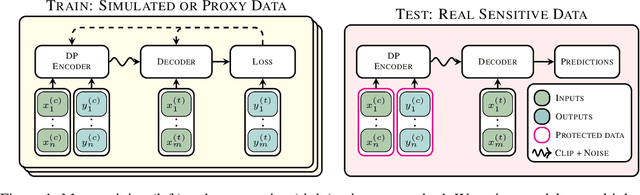
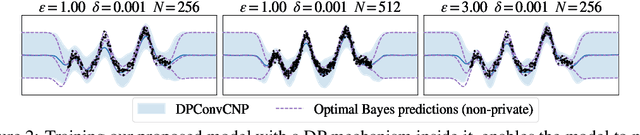

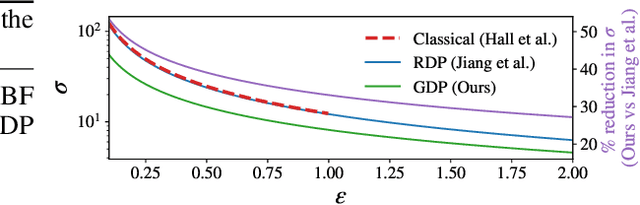
Many high-stakes applications require machine learning models that protect user privacy and provide well-calibrated, accurate predictions. While Differential Privacy (DP) is the gold standard for protecting user privacy, standard DP mechanisms typically significantly impair performance. One approach to mitigating this issue is pre-training models on simulated data before DP learning on the private data. In this work we go a step further, using simulated data to train a meta-learning model that combines the Convolutional Conditional Neural Process (ConvCNP) with an improved functional DP mechanism of Hall et al. [2013] yielding the DPConvCNP. DPConvCNP learns from simulated data how to map private data to a DP predictive model in one forward pass, and then provides accurate, well-calibrated predictions. We compare DPConvCNP with a DP Gaussian Process (GP) baseline with carefully tuned hyperparameters. The DPConvCNP outperforms the GP baseline, especially on non-Gaussian data, yet is much faster at test time and requires less tuning.
Amortised Inference in Neural Networks for Small-Scale Probabilistic Meta-Learning
Oct 24, 2023
The global inducing point variational approximation for BNNs is based on using a set of inducing inputs to construct a series of conditional distributions that accurately approximate the conditionals of the true posterior distribution. Our key insight is that these inducing inputs can be replaced by the actual data, such that the variational distribution consists of a set of approximate likelihoods for each datapoint. This structure lends itself to amortised inference, in which the parameters of each approximate likelihood are obtained by passing each datapoint through a meta-model known as the inference network. By training this inference network across related datasets, we can meta-learn Bayesian inference over task-specific BNNs.
Causal Reasoning in the Presence of Latent Confounders via Neural ADMG Learning
Mar 22, 2023Latent confounding has been a long-standing obstacle for causal reasoning from observational data. One popular approach is to model the data using acyclic directed mixed graphs (ADMGs), which describe ancestral relations between variables using directed and bidirected edges. However, existing methods using ADMGs are based on either linear functional assumptions or a discrete search that is complicated to use and lacks computational tractability for large datasets. In this work, we further extend the existing body of work and develop a novel gradient-based approach to learning an ADMG with non-linear functional relations from observational data. We first show that the presence of latent confounding is identifiable under the assumptions of bow-free ADMGs with non-linear additive noise models. With this insight, we propose a novel neural causal model based on autoregressive flows for ADMG learning. This not only enables us to determine complex causal structural relationships behind the data in the presence of latent confounding, but also estimate their functional relationships (hence treatment effects) simultaneously. We further validate our approach via experiments on both synthetic and real-world datasets, and demonstrate the competitive performance against relevant baselines.
Differentially private partitioned variational inference
Sep 23, 2022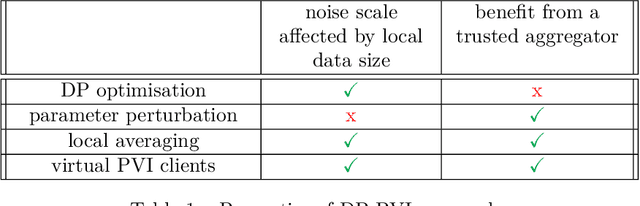
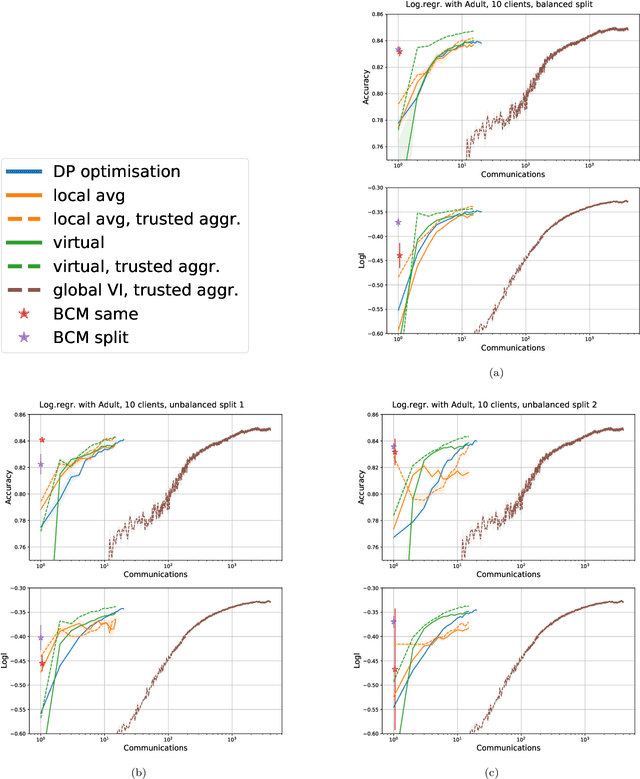
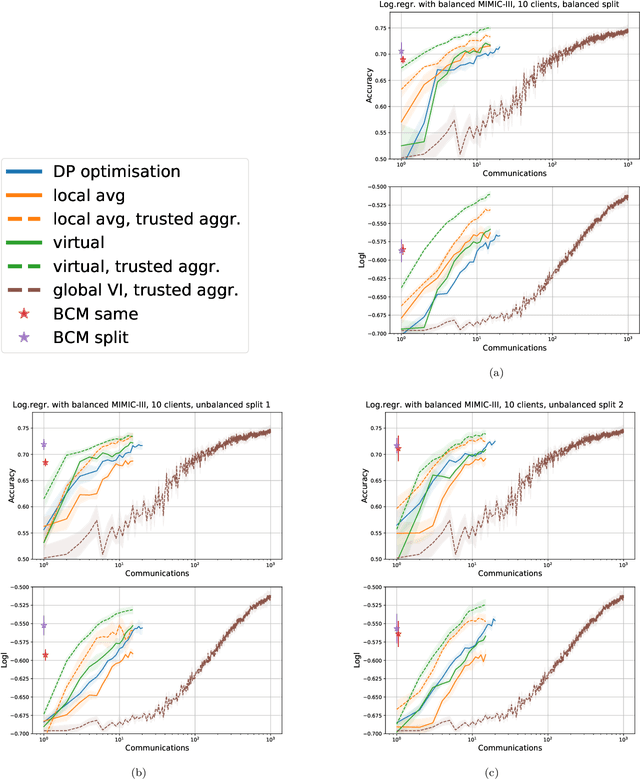

Learning a privacy-preserving model from distributed sensitive data is an increasingly important problem, often formulated in the federated learning context. Variational inference has recently been extended to the non-private federated learning setting via the partitioned variational inference algorithm. For privacy protection, the current gold standard is called differential privacy. Differential privacy guarantees privacy in a strong, mathematically clearly defined sense. In this paper, we present differentially private partitioned variational inference, the first general framework for learning a variational approximation to a Bayesian posterior distribution in the federated learning setting while minimising the number of communication rounds and providing differential privacy guarantees for data subjects. We propose three alternative implementations in the general framework, one based on perturbing local optimisation done by individual parties, and two based on perturbing global updates (one using a version of federated averaging, one adding virtual parties to the protocol), and compare their properties both theoretically and empirically. We show that perturbing the local optimisation works well with simple and complex models as long as each party has enough local data. However, the privacy is always guaranteed independently by each party. In contrast, perturbing the global updates works best with relatively simple models. Given access to suitable secure primitives, such as secure aggregation or secure shuffling, the performance can be improved by all parties guaranteeing privacy jointly.