 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Domain Neural Machine Translation with Word-Level Adaptive Layer-wise Domain Mixing
Nov 07, 2019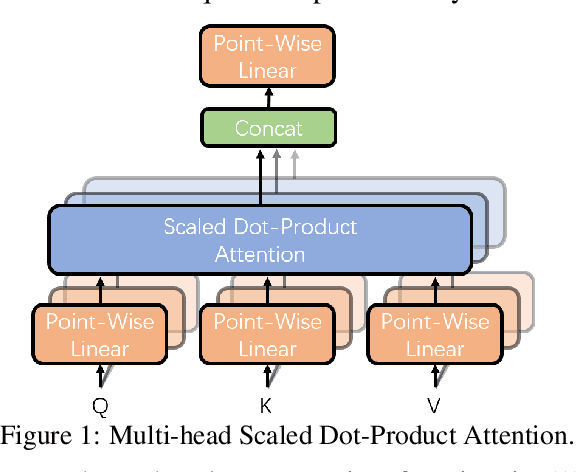
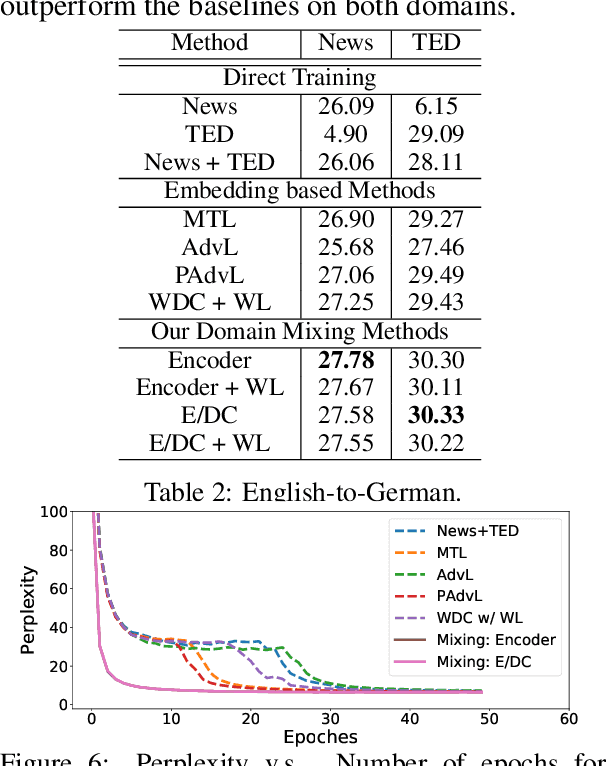
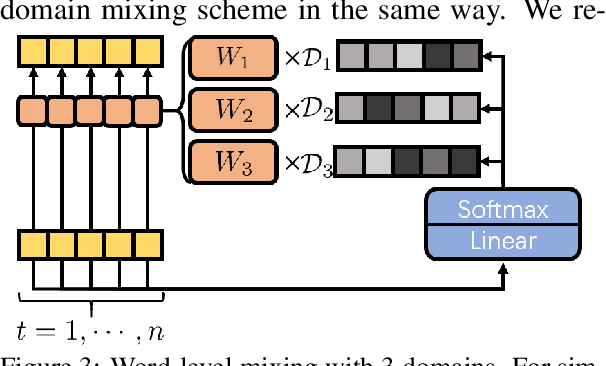
Many multi-domain neural machine translation (NMT) models achieve knowledge transfer by enforcing one encoder to learn shared embedding across domains. However, this design lacks adaptation to individual domains. To overcome this limitation, we propose a novel multi-domain NMT model using individual modules for each domain, on which we apply word-level, adaptive and layer-wise domain mixing. We first observe that words in a sentence are often related to multiple domains. Hence, we assume each word has a domain proportion, which indicates its domain preference. Then word representations are obtained by mixing their embedding in individual domains based on their domain proportions. We show this can be achieved by carefully designing multi-head dot-product attention modules for different domains, and eventually taking weighted averages of their parameters by word-level layer-wise domain proportions. Through this, we can achieve effective domain knowledge sharing, and capture fine-grained domain-specific knowledge as well. Our experiments show that our proposed model outperforms existing ones in several NMT tasks.
On Generalization Bounds of a Family of Recurrent Neural Networks
Nov 04, 2019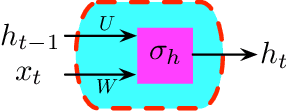
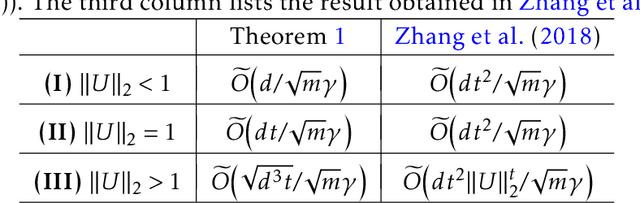
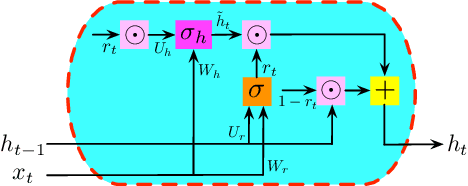
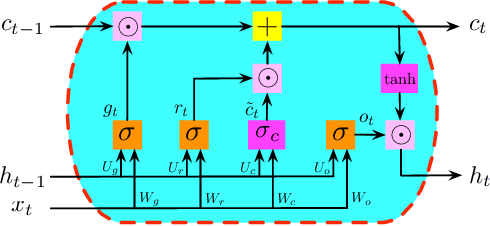
Recurrent Neural Networks (RNNs) have been widely applied to sequential data analysis. Due to their complicated modeling structures, however, the theory behind is still largely missing. To connect theory and practice, we study the generalization properties of vanilla RNNs as well as their variants, including Minimal Gated Unit (MGU), Long Short Term Memory (LSTM), and Convolutional (Conv) RNNs. Specifically, our theory is established under the PAC-Learning framework. The generalization bound is presented in terms of the spectral norms of the weight matrices and the total number of parameters. We also establish refined generalization bounds with additional norm assumptions, and draw a comparison among these bounds. We remark: (1) Our generalization bound for vanilla RNNs is significantly tighter than the best of existing results; (2) We are not aware of any other generalization bounds for MGU, LSTM, and Conv RNNs in the exiting literature; (3) We demonstrate the advantages of these variants in generalization.
Towards Understanding the Importance of Shortcut Connections in Residual Networks
Sep 11, 2019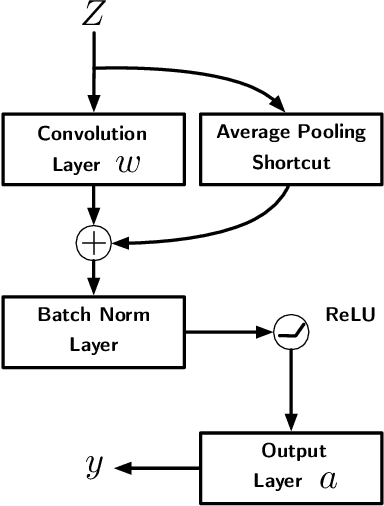

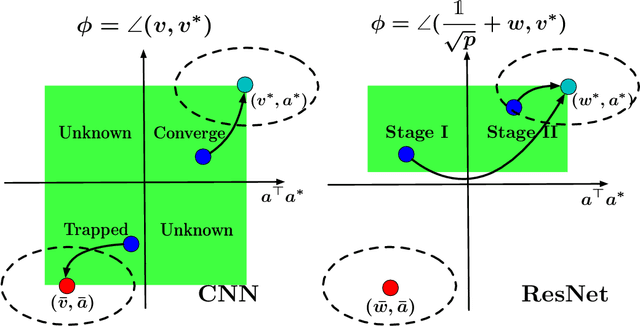
Residual Network (ResNet) is undoubtedly a milestone in deep learning. ResNet is equipped with shortcut connections between layers, and exhibits efficient training using simple first order algorithms. Despite of the great empirical success, the reason behind is far from being well understood. In this paper, we study a two-layer non-overlapping convolutional ResNet. Training such a network requires solving a non-convex optimization problem with a spurious local optimum. We show, however, that gradient descent combined with proper normalization, avoids being trapped by the spurious local optimum, and converges to a global optimum in polynomial time, when the weight of the first layer is initialized at 0, and that of the second layer is initialized arbitrarily in a ball. Numerical experiments are provided to support our theory.
Towards Understanding the Importance of Noise in Training Neural Networks
Sep 07, 2019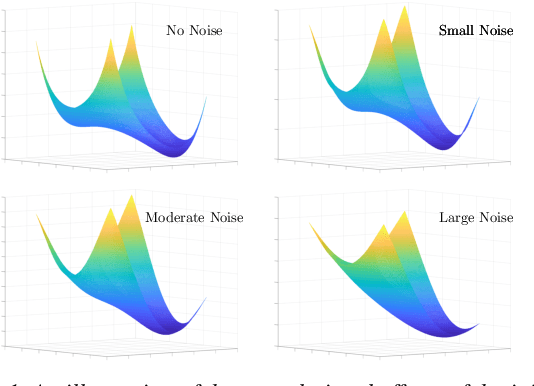
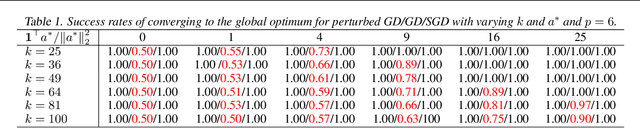
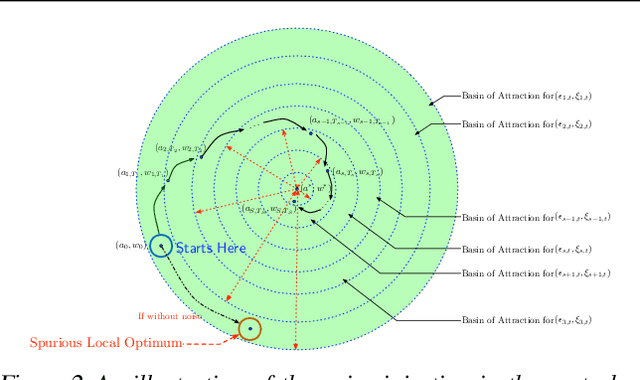
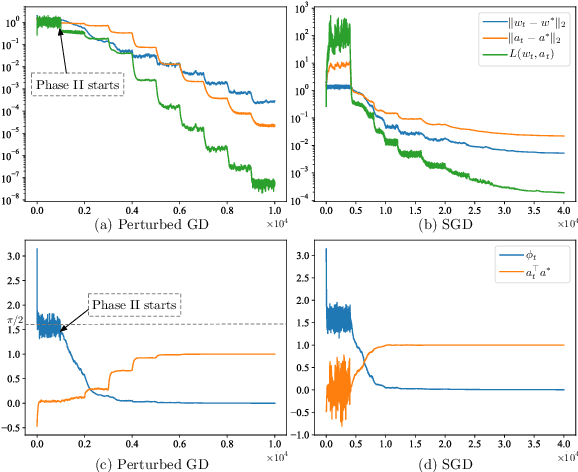
Numerous empirical evidence has corroborated that the noise plays a crucial rule in effective and efficient training of neural networks. The theory behind, however, is still largely unknown. This paper studies this fundamental problem through training a simple two-layer convolutional neural network model. Although training such a network requires solving a nonconvex optimization problem with a spurious local optimum and a global optimum, we prove that perturbed gradient descent and perturbed mini-batch stochastic gradient algorithms in conjunction with noise annealing is guaranteed to converge to a global optimum in polynomial time with arbitrary initialization. This implies that the noise enables the algorithm to efficiently escape from the spurious local optimum. Numerical experiments are provided to support our theory.
Meta Learning with Relational Information for Short Sequences
Sep 04, 2019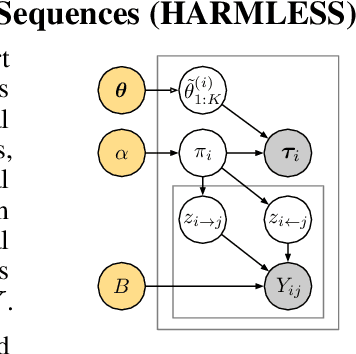
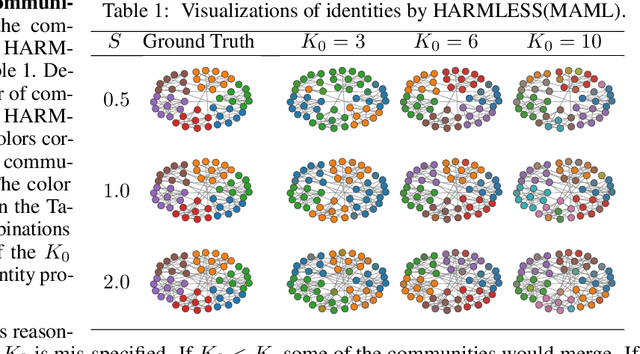
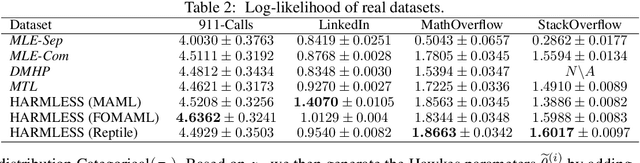
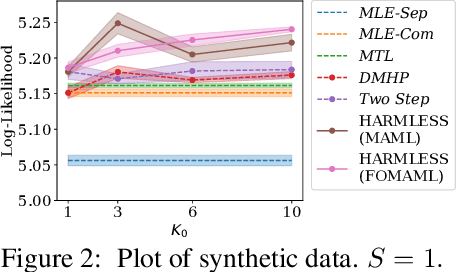
This paper proposes a new meta-learning method -- named HARMLESS (HAwkes Relational Meta LEarning method for Short Sequences) for learning heterogeneous point process models from short event sequence data along with a relational network. Specifically, we propose a hierarchical Bayesian mixture Hawkes process model, which naturally incorporates the relational information among sequences into point process modeling. Compared with existing methods, our model can capture the underlying mixed-community patterns of the relational network, which simultaneously encourages knowledge sharing among sequences and facilitates adaptive learning for each individual sequence. We further propose an efficient stochastic variational meta expectation maximization algorithm that can scale to large problems. Numerical experiments on both synthetic and real data show that HARMLESS outperforms existing methods in terms of predicting the future events.
Efficient Approximation of Deep ReLU Networks for Functions on Low Dimensional Manifolds
Aug 05, 2019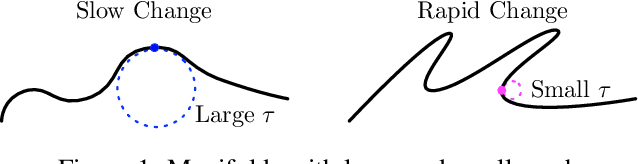
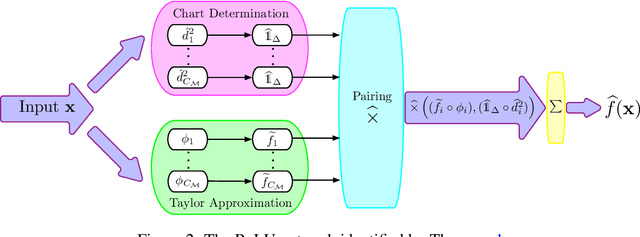
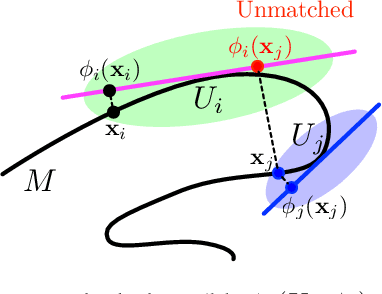
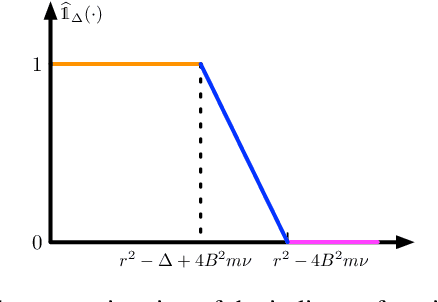
Deep neural networks have revolutionized many real world applications, due to their flexibility in data fitting and accurate predictions for unseen data. A line of research reveals that neural networks can approximate certain classes of functions with an arbitrary accuracy, while the size of the network scales exponentially with respect to the data dimension. Empirical results, however, suggest that networks of moderate size already yield appealing performance. To explain such a gap, a common belief is that many data sets exhibit low dimensional structures, and can be modeled as samples near a low dimensional manifold. In this paper, we prove that neural networks can efficiently approximate functions supported on low dimensional manifolds. The network size scales exponentially in the approximation error, with an exponent depending on the intrinsic dimension of the data and the smoothness of the function. Our result shows that exploiting low dimensional data structures can greatly enhance the efficiency in function approximation by neural networks. We also implement a sub-network that assigns input data to their corresponding local neighborhoods, which may be of independent interest.
Inductive Bias of Gradient Descent based Adversarial Training on Separable Data
Jun 10, 2019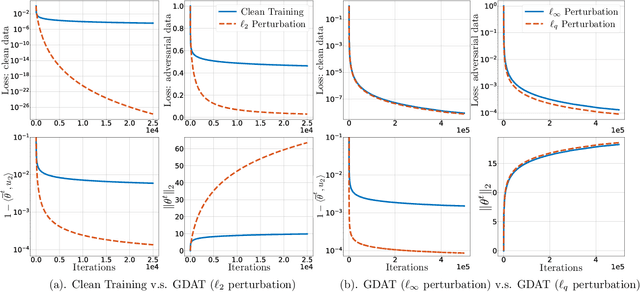
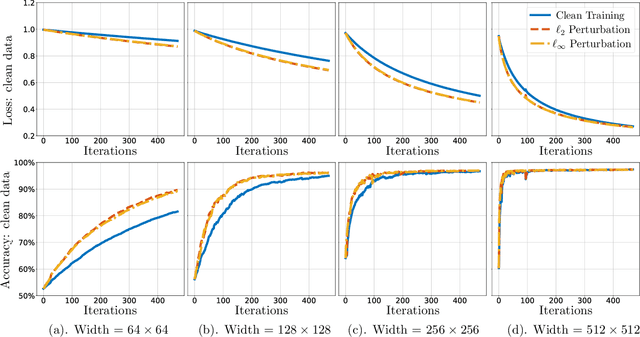
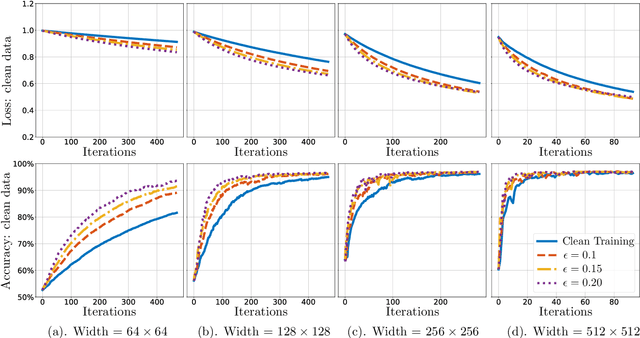
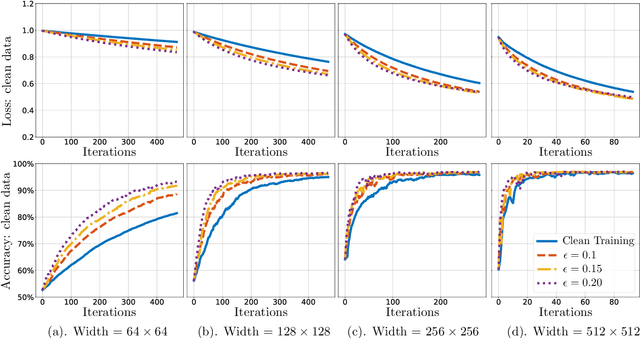
Adversarial training is a principled approach for training robust neural networks. Despite of tremendous successes in practice, its theoretical properties still remain largely unexplored. In this paper, we provide new theoretical insights of gradient descent based adversarial training by studying its computational properties, specifically on its inductive bias. We take the binary classification task on linearly separable data as an illustrative example, where the loss asymptotically attains its infimum as the parameter diverges to infinity along certain directions. Specifically, we show that when the adversarial perturbation during training has bounded $\ell_2$-norm, the classifier learned by gradient descent based adversarial training converges in direction to the maximum $\ell_2$-norm margin classifier at the rate of $\tilde{\mathcal{O}}(1/\sqrt{T})$, significantly faster than the rate $\mathcal{O}(1/\log T)$ of training with clean data. In addition, when the adversarial perturbation during training has bounded $\ell_q$-norm for some $q\ge 1$, the resulting classifier converges in direction to a maximum mixed-norm margin classifier, which has a natural interpretation of robustness, as being the maximum $\ell_2$-norm margin classifier under worst-case $\ell_q$-norm perturbation to the data. Our findings provide theoretical backups for adversarial training that it indeed promotes robustness against adversarial perturbation.
On Scalable and Efficient Computation of Large Scale Optimal Transport
May 14, 2019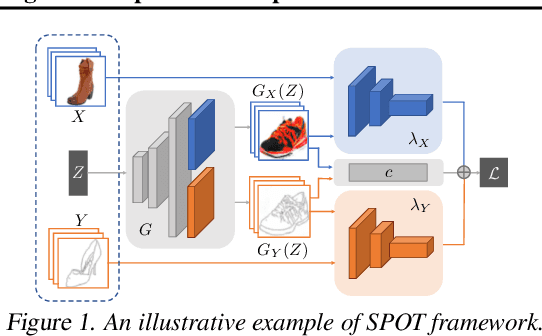
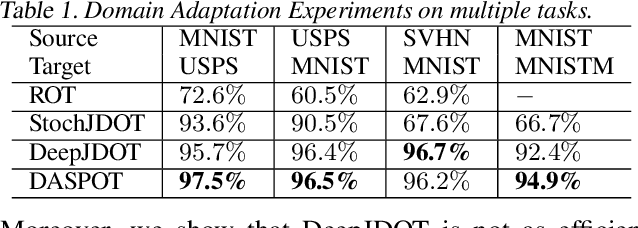
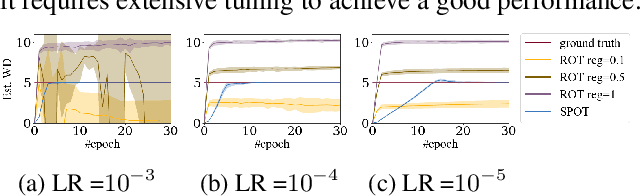
Optimal Transport (OT) naturally arises in many machine learning applications, yet the heavy computational burden limits its wide-spread uses. To address the scalability issue, we propose an implicit generative learning-based framework called SPOT (Scalable Push-forward of Optimal Transport). Specifically, we approximate the optimal transport plan by a pushforward of a reference distribution, and cast the optimal transport problem into a minimax problem. We then can solve OT problems efficiently using primal dual stochastic gradient-type algorithms. We also show that we can recover the density of the optimal transport plan using neural ordinary differential equations. Numerical experiments on both synthetic and real datasets illustrate that SPOT is robust and has favorable convergence behavior. SPOT also allows us to efficiently sample from the optimal transport plan, which benefits downstream applications such as domain adaptation.
On Computation and Generalization of GANs with Spectrum Control
Dec 28, 2018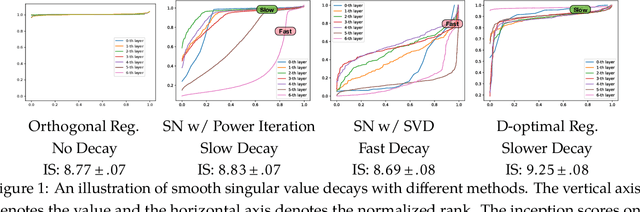
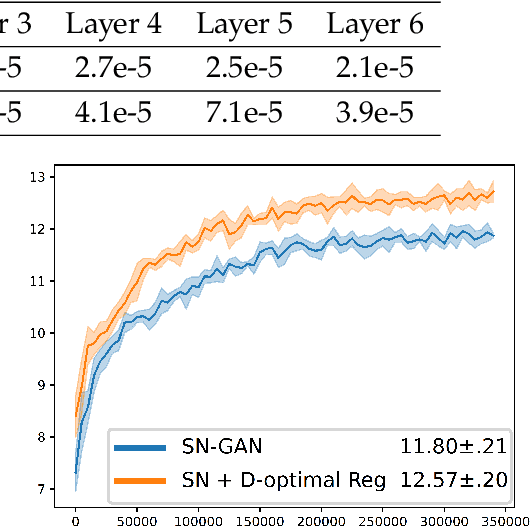
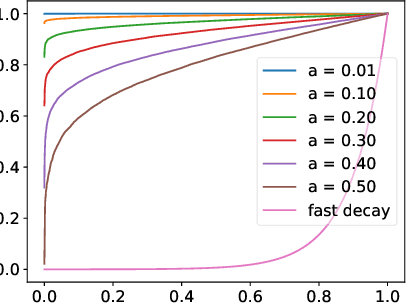
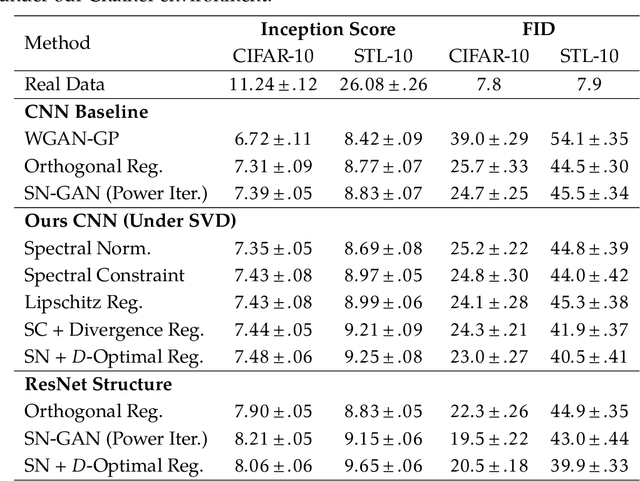
Generative Adversarial Networks (GANs), though powerful, is hard to train. Several recent works (brock2016neural,miyato2018spectral) suggest that controlling the spectra of weight matrices in the discriminator can significantly improve the training of GANs. Motivated by their discovery, we propose a new framework for training GANs, which allows more flexible spectrum control (e.g., making the weight matrices of the discriminator have slow singular value decays). Specifically, we propose a new reparameterization approach for the weight matrices of the discriminator in GANs, which allows us to directly manipulate the spectra of the weight matrices through various regularizers and constraints, without intensively computing singular value decompositions. Theoretically, we further show that the spectrum control improves the generalization ability of GANs. Our experiments on CIFAR-10, STL-10, and ImageNet datasets confirm that compared to other methods, our proposed method is capable of generating images with competitive quality by utilizing spectral normalization and encouraging the slow singular value decay.
Learning to Defense by Learning to Attack
Nov 03, 2018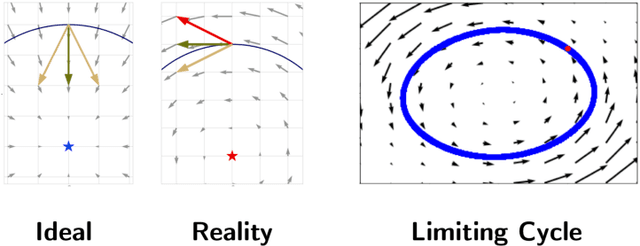
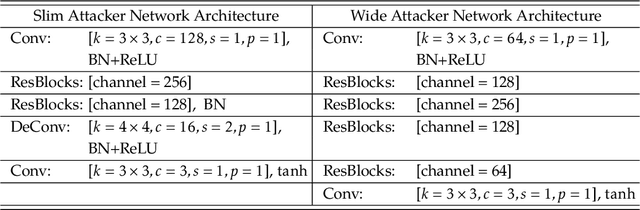
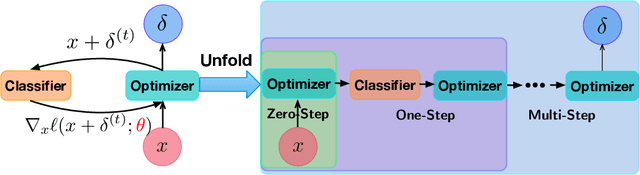
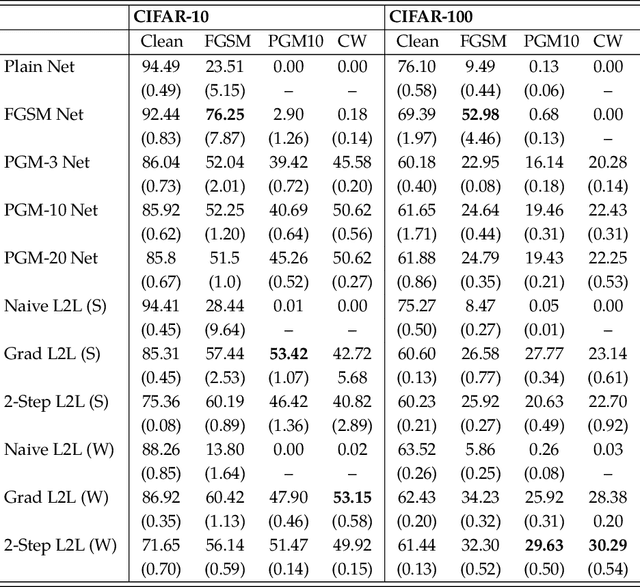
Adversarial training provides a principled approach for training robust neural networks. From an optimization perspective, the adversarial training is essentially solving a minmax robust optimization problem. The outer minimization is trying to learn a robust classifier, while the inner maximization is trying to generate adversarial samples. Unfortunately, such a minmax problem is very difficult to solve due to the lack of convex-concave structure. This work proposes a new adversarial training method based on a general learning-to-learn framework. Specifically, instead of applying the existing hand-design algorithms for the inner problem, we learn an optimizer, which is parametrized as a convolutional neural network. At the same time, a robust classifier is learned to defense the adversarial attack generated by the learned optimizer. Our experiments demonstrate that our proposed method significantly outperforms existing adversarial training methods on CIFAR-10 and CIFAR-100 datasets.