 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior Knowledge-Guided Attention in Self-Supervised Vision Transformers
Sep 07, 2022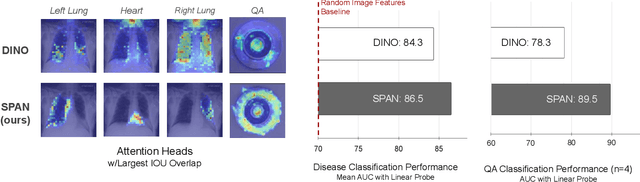
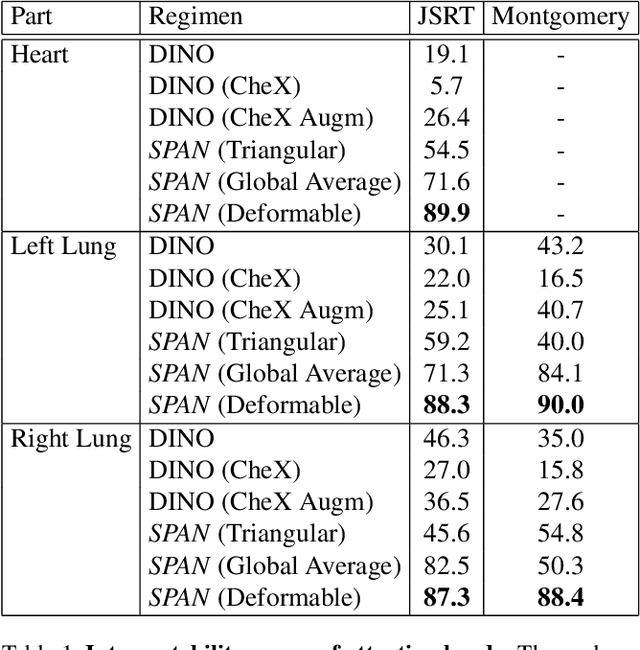
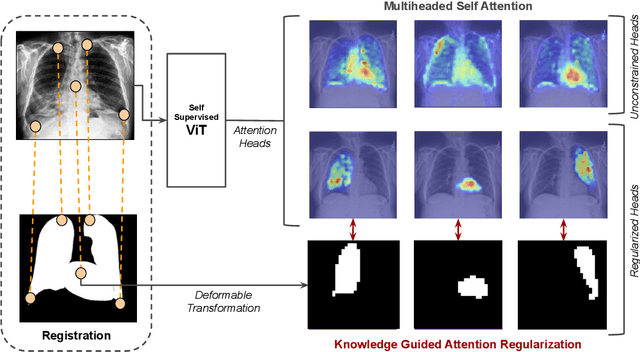

Recent trends in self-supervised representation learning have focused on removing inductive biases from training pipelines. However, inductive biases can be useful in settings when limited data are available or provide additional insight into the underlying data distribution. We present spatial prior attention (SPAN), a framework that takes advantage of consistent spatial and semantic structure in unlabeled image datasets to guide Vision Transformer attention. SPAN operates by regularizing attention masks from separate transformer heads to follow various priors over semantic regions. These priors can be derived from data statistics or a single labeled sample provided by a domain expert. We study SPAN through several detailed real-world scenarios, including medical image analysis and visual quality assurance. We find that the resulting attention masks are more interpretable than those derived from domain-agnostic pretraining. SPAN produces a 58.7 mAP improvement for lung and heart segmentation. We also find that our method yields a 2.2 mAUC improvement compared to domain-agnostic pretraining when transferring the pretrained model to a downstream chest disease classification task. Lastly, we show that SPAN pretraining leads to higher downstream classification performance in low-data regimes compared to domain-agnostic pretraining.
Visual Prompting via Image Inpainting
Sep 01, 2022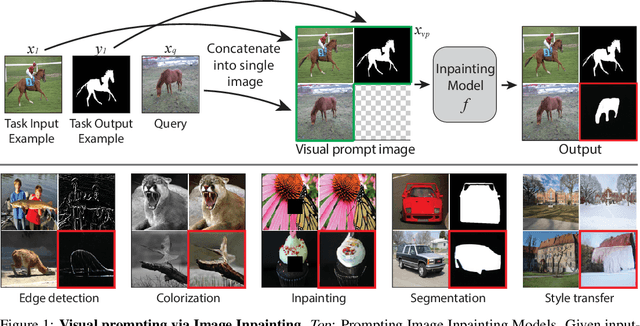
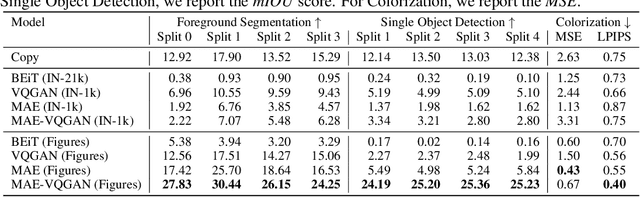
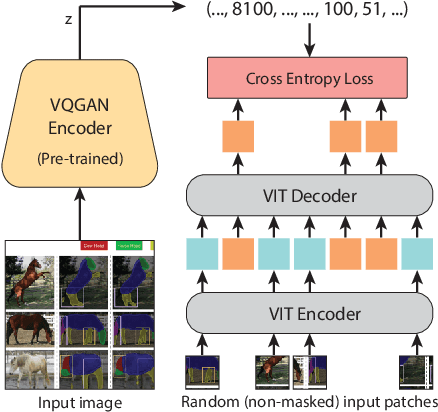
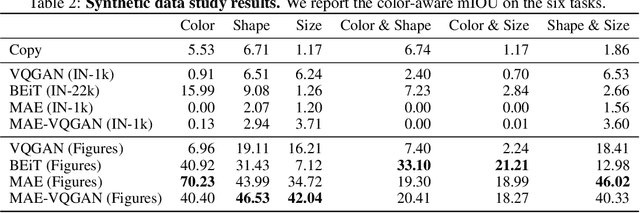
How does one adapt a pre-trained visual model to novel downstream tasks without task-specific finetuning or any model modification? Inspired by prompting in NLP, this paper investigates visual prompting: given input-output image example(s) of a new task at test time and a new input image, the goal is to automatically produce the output image, consistent with the given examples. We show that posing this problem as simple image inpainting - literally just filling in a hole in a concatenated visual prompt image - turns out to be surprisingly effective, provided that the inpainting algorithm has been trained on the right data. We train masked auto-encoders on a new dataset that we curated - 88k unlabeled figures from academic papers sources on Arxiv. We apply visual prompting to these pretrained models and demonstrate results on various downstream image-to-image tasks, including foreground segmentation, single object detection, colorization, edge detection, etc.
Refine and Represent: Region-to-Object Representation Learning
Aug 25, 2022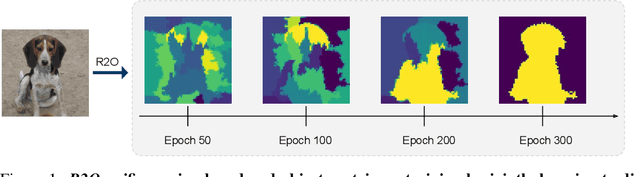
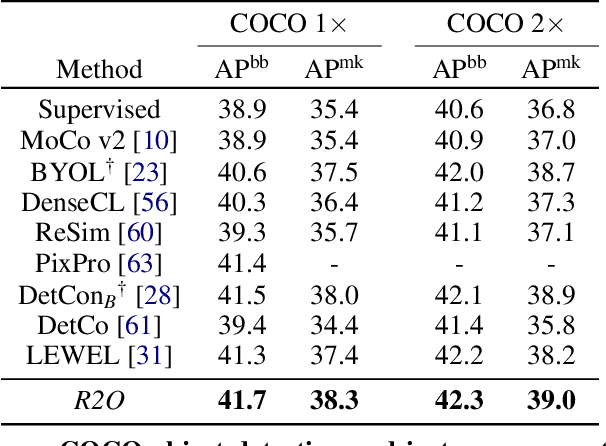
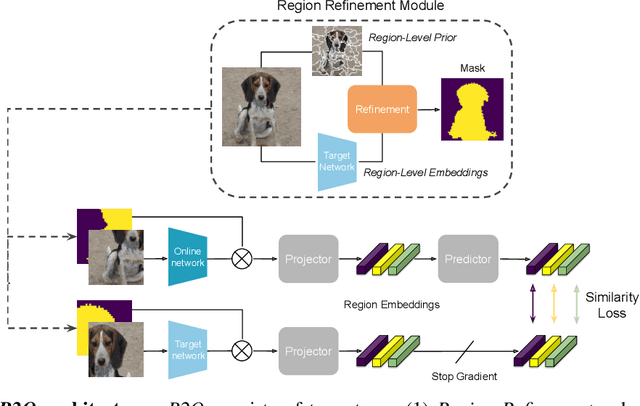
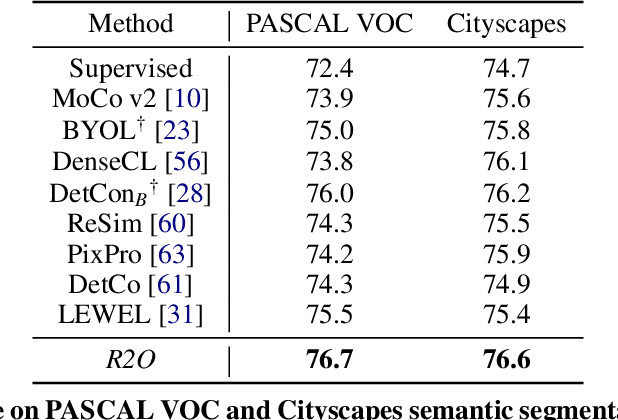
Recent works in self-supervised learning have demonstrated strong performance on scene-level dense prediction tasks by pretraining with object-centric or region-based correspondence objectives. In this paper, we present Region-to-Object Representation Learning (R2O) which unifies region-based and object-centric pretraining. R2O operates by training an encoder to dynamically refine region-based segments into object-centric masks and then jointly learns representations of the contents within the mask. R2O uses a "region refinement module" to group small image regions, generated using a region-level prior, into larger regions which tend to correspond to objects by clustering region-level features. As pretraining progresses, R2O follows a region-to-object curriculum which encourages learning region-level features early on and gradually progresses to train object-centric representations. Representations learned using R2O lead to state-of-the art performance in semantic segmentation for PASCAL VOC (+0.7 mIOU) and Cityscapes (+0.4 mIOU) and instance segmentation on MS COCO (+0.3 mask AP). Further, after pretraining on ImageNet, R2O pretrained models are able to surpass existing state-of-the-art in unsupervised object segmentation on the Caltech-UCSD Birds 200-2011 dataset (+2.9 mIoU) without any further training. We provide the code/models from this work at https://github.com/KKallidromitis/r2o.
TL;DW? Summarizing Instructional Videos with Task Relevance & Cross-Modal Saliency
Aug 14, 2022
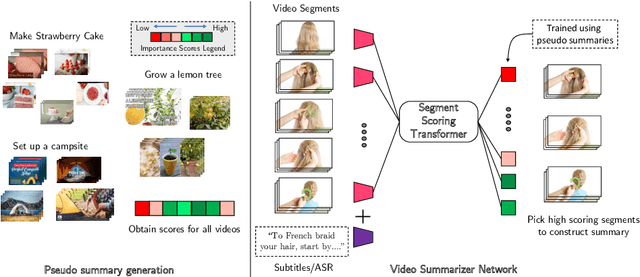
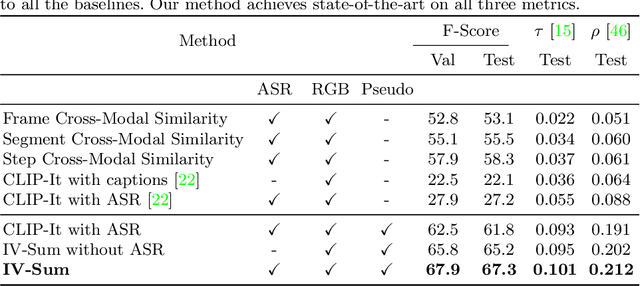
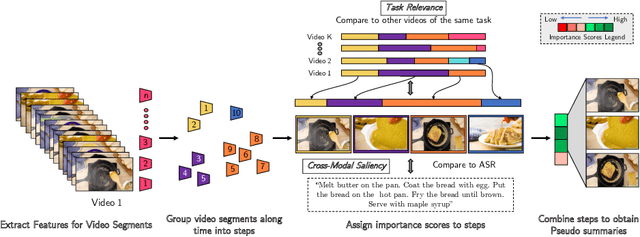
YouTube users looking for instructions for a specific task may spend a long time browsing content trying to find the right video that matches their needs. Creating a visual summary (abridged version of a video) provides viewers with a quick overview and massively reduces search time. In this work, we focus on summarizing instructional videos, an under-explored area of video summarization. In comparison to generic videos, instructional videos can be parsed into semantically meaningful segments that correspond to important steps of the demonstrated task. Existing video summarization datasets rely on manual frame-level annotations, making them subjective and limited in size. To overcome this, we first automatically generate pseudo summaries for a corpus of instructional videos by exploiting two key assumptions: (i) relevant steps are likely to appear in multiple videos of the same task (Task Relevance), and (ii) they are more likely to be described by the demonstrator verbally (Cross-Modal Saliency). We propose an instructional video summarization network that combines a context-aware temporal video encoder and a segment scoring transformer. Using pseudo summaries as weak supervision, our network constructs a visual summary for an instructional video given only video and transcribed speech. To evaluate our model, we collect a high-quality test set, WikiHow Summaries, by scraping WikiHow articles that contain video demonstrations and visual depictions of steps allowing us to obtain the ground-truth summaries. We outperform several baselines and a state-of-the-art video summarization model on this new benchmark.
Back to the Source: Diffusion-Driven Test-Time Adaptation
Jul 07, 2022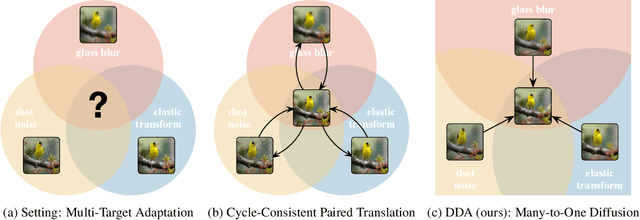

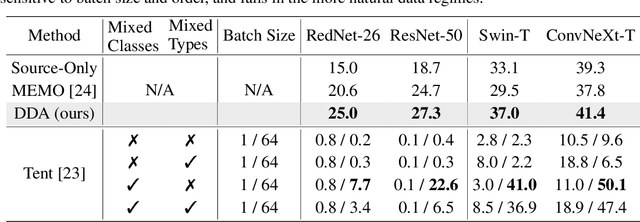
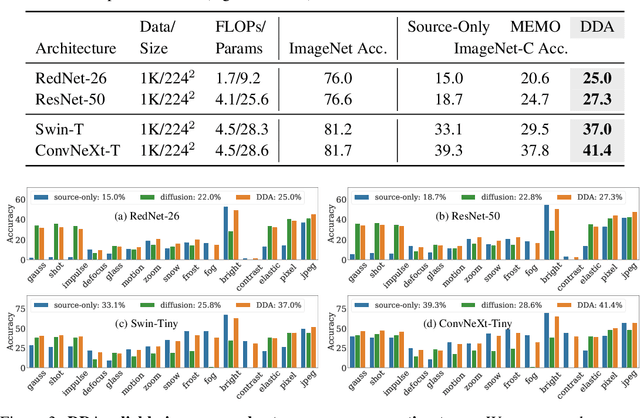
Test-time adaptation harnesses test inputs to improve the accuracy of a model trained on source data when tested on shifted target data. Existing methods update the source model by (re-)training on each target domain. While effective, re-training is sensitive to the amount and order of the data and the hyperparameters for optimization. We instead update the target data, by projecting all test inputs toward the source domain with a generative diffusion model. Our diffusion-driven adaptation method, DDA, shares its models for classification and generation across all domains. Both models are trained on the source domain, then fixed during testing. We augment diffusion with image guidance and self-ensembling to automatically decide how much to adapt. Input adaptation by DDA is more robust than prior model adaptation approaches across a variety of corruptions, architectures, and data regimes on the ImageNet-C benchmark. With its input-wise updates, DDA succeeds where model adaptation degrades on too little data in small batches, dependent data in non-uniform order, or mixed data with multiple corruptions.
Disentangled Action Recognition with Knowledge Bases
Jul 04, 2022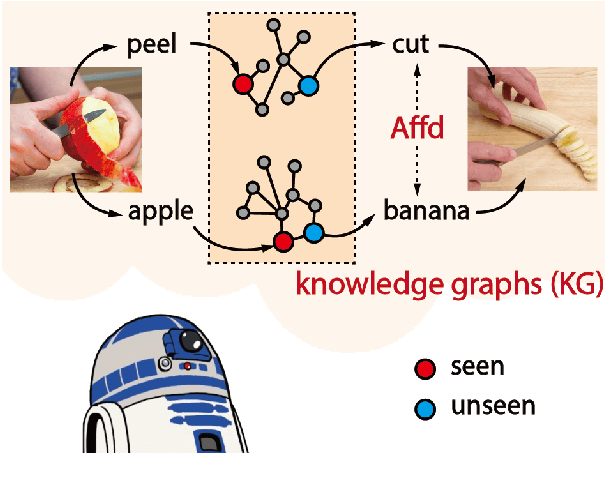
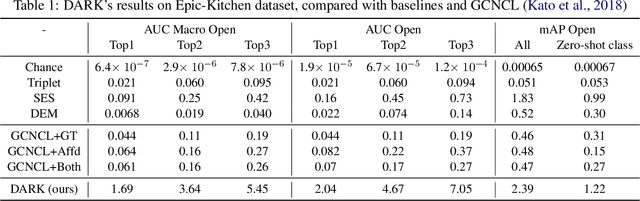
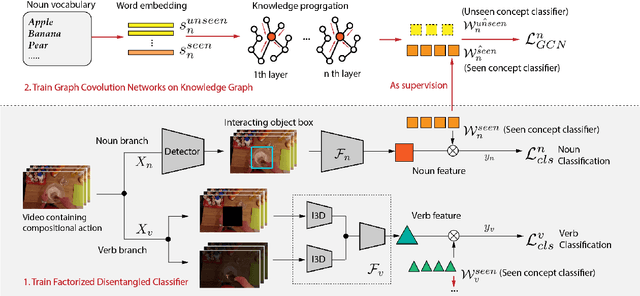
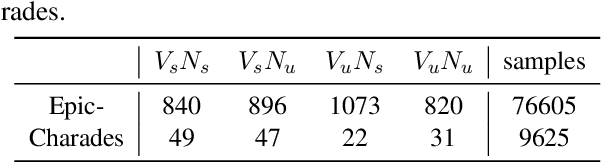
Action in video usually involves the interaction of human with objects. Action labels are typically composed of various combinations of verbs and nouns, but we may not have training data for all possible combinations. In this paper, we aim to improve the generalization ability of the compositional action recognition model to novel verbs or novel nouns that are unseen during training time, by leveraging the power of knowledge graphs. Previous work utilizes verb-noun compositional action nodes in the knowledge graph, making it inefficient to scale since the number of compositional action nodes grows quadratically with respect to the number of verbs and nouns. To address this issue, we propose our approach: Disentangled Action Recognition with Knowledge-bases (DARK), which leverages the inherent compositionality of actions. DARK trains a factorized model by first extracting disentangled feature representations for verbs and nouns, and then predicting classification weights using relations in external knowledge graphs. The type constraint between verb and noun is extracted from external knowledge bases and finally applied when composing actions. DARK has better scalability in the number of objects and verbs, and achieves state-of-the-art performance on the Charades dataset. We further propose a new benchmark split based on the Epic-kitchen dataset which is an order of magnitude bigger in the numbers of classes and samples, and benchmark various models on this benchmark.
Structured Video Tokens @ Ego4D PNR Temporal Localization Challenge 2022
Jun 15, 2022


This technical report describes the SViT approach for the Ego4D Point of No Return (PNR) Temporal Localization Challenge. We propose a learning framework StructureViT (SViT for short), which demonstrates how utilizing the structure of a small number of images only available during training can improve a video model. SViT relies on two key insights. First, as both images and videos contain structured information, we enrich a transformer model with a set of \emph{object tokens} that can be used across images and videos. Second, the scene representations of individual frames in video should "align" with those of still images. This is achieved via a "Frame-Clip Consistency" loss, which ensures the flow of structured information between images and videos. SViT obtains strong performance on the challenge test set with 0.656 absolute temporal localization error.
Bringing Image Scene Structure to Video via Frame-Clip Consistency of Object Tokens
Jun 15, 2022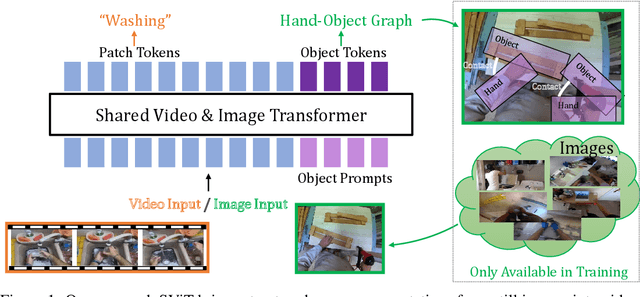
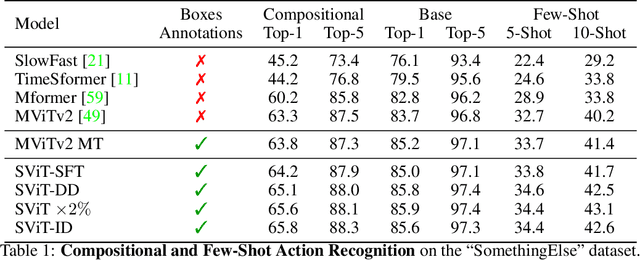
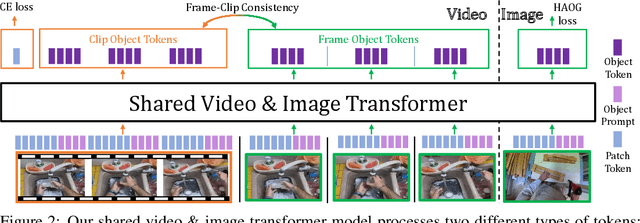
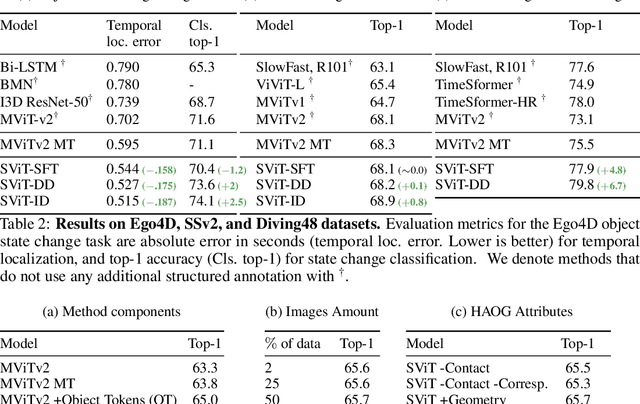
Recent action recognition models have achieved impressive results by integrating objects, their locations and interactions. However, obtaining dense structured annotations for each frame is tedious and time-consuming, making these methods expensive to train and less scalable. At the same time, if a small set of annotated images is available, either within or outside the domain of interest, how could we leverage these for a video downstream task? We propose a learning framework StructureViT (SViT for short), which demonstrates how utilizing the structure of a small number of images only available during training can improve a video model. SViT relies on two key insights. First, as both images and videos contain structured information, we enrich a transformer model with a set of \emph{object tokens} that can be used across images and videos. Second, the scene representations of individual frames in video should "align" with those of still images. This is achieved via a \emph{Frame-Clip Consistency} loss, which ensures the flow of structured information between images and videos. We explore a particular instantiation of scene structure, namely a \emph{Hand-Object Graph}, consisting of hands and objects with their locations as nodes, and physical relations of contact/no-contact as edges. SViT shows strong performance improvements on multiple video understanding tasks and datasets. Furthermore, it won in the Ego4D CVPR'22 Object State Localization challenge. For code and pretrained models, visit the project page at \url{https://eladb3.github.io/SViT/}
Voxel-informed Language Grounding
May 19, 2022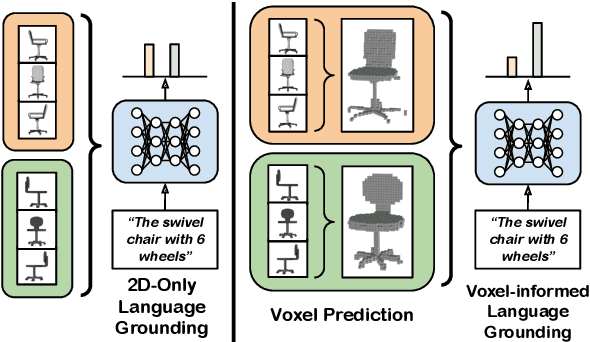
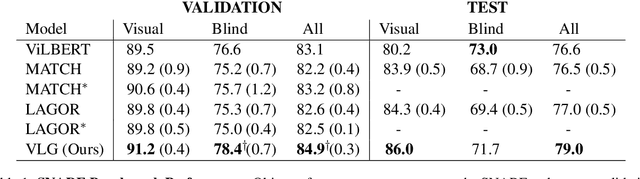
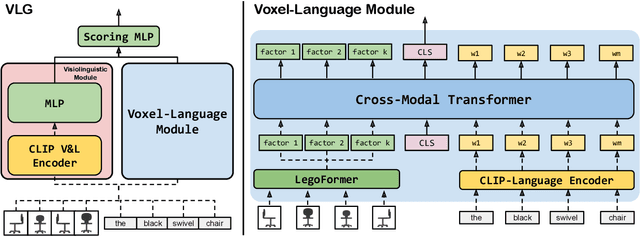
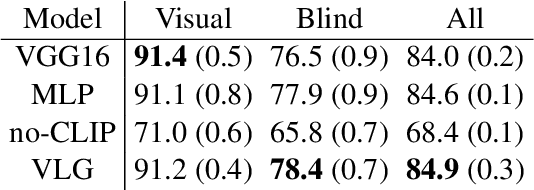
Natural language applied to natural 2D images describes a fundamentally 3D world. We present the Voxel-informed Language Grounder (VLG), a language grounding model that leverages 3D geometric information in the form of voxel maps derived from the visual input using a volumetric reconstruction model. We show that VLG significantly improves grounding accuracy on SNARE, an object reference game task. At the time of writing, VLG holds the top place on the SNARE leaderboard, achieving SOTA results with a 2.0% absolute improvement.
Reliable Visual Question Answering: Abstain Rather Than Answer Incorrectly
Apr 28, 2022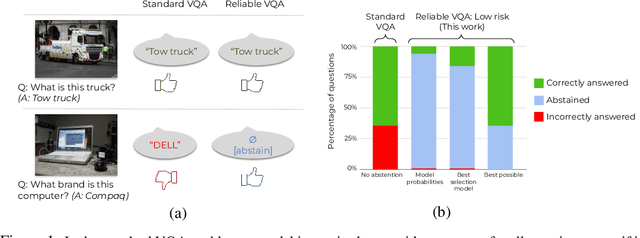
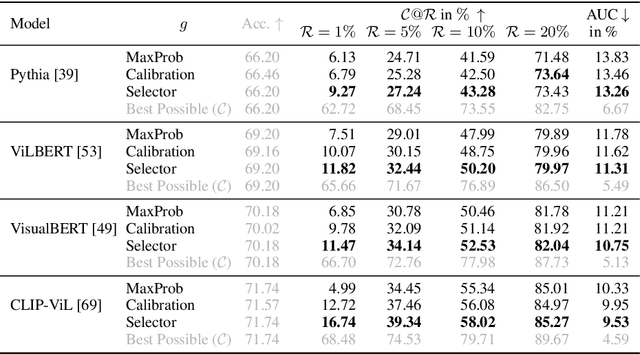


Machine learning has advanced dramatically, narrowing the accuracy gap to humans in multimodal tasks like visual question answering (VQA). However, while humans can say "I don't know" when they are uncertain (i.e., abstain from answering a question), such ability has been largely neglected in multimodal research, despite the importance of this problem to the usage of VQA in real settings. In this work, we promote a problem formulation for reliable VQA, where we prefer abstention over providing an incorrect answer. We first enable abstention capabilities for several VQA models, and analyze both their coverage, the portion of questions answered, and risk, the error on that portion. For that we explore several abstention approaches. We find that although the best performing models achieve over 71% accuracy on the VQA v2 dataset, introducing the option to abstain by directly using a model's softmax scores limits them to answering less than 8% of the questions to achieve a low risk of error (i.e., 1%). This motivates us to utilize a multimodal selection function to directly estimate the correctness of the predicted answers, which we show can triple the coverage from, for example, 5.0% to 16.7% at 1% risk. While it is important to analyze both coverage and risk, these metrics have a trade-off which makes comparing VQA models challenging. To address this, we also propose an Effective Reliability metric for VQA that places a larger cost on incorrect answers compared to abstentions. This new problem formulation, metric, and analysis for VQA provide the groundwork for building effective and reliable VQA models that have the self-awareness to abstain if and only if they don't know the answer.