 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly Horizon-Free Offline Reinforcement Learning
Mar 25, 2021
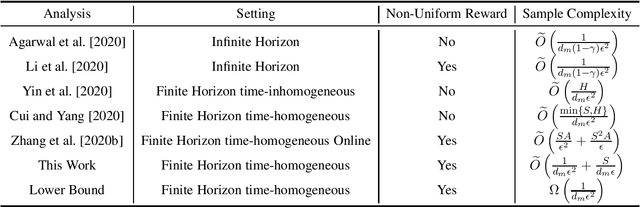
We revisit offline reinforcement learning on episodic time-homogeneous tabular Markov Decision Processes with $S$ states, $A$ actions and planning horizon $H$. Given the collected $N$ episodes data with minimum cumulative reaching probability $d_m$, we obtain the first set of nearly $H$-free sample complexity bounds for evaluation and planning using the empirical MDPs: 1.For the offline evaluation, we obtain an $\tilde{O}\left(\sqrt{\frac{1}{Nd_m}} \right)$ error rate, which matches the lower bound and does not have additional dependency on $\poly\left(S,A\right)$ in higher-order term, that is different from previous works~\citep{yin2020near,yin2020asymptotically}. 2.For the offline policy optimization, we obtain an $\tilde{O}\left(\sqrt{\frac{1}{Nd_m}} + \frac{S}{Nd_m}\right)$ error rate, improving upon the best known result by \cite{cui2020plug}, which has additional $H$ and $S$ factors in the main term. Furthermore, this bound approaches the $\Omega\left(\sqrt{\frac{1}{Nd_m}}\right)$ lower bound up to logarithmic factors and a high-order term. To the best of our knowledge, these are the first set of nearly horizon-free bounds in offline reinforcement learning.
Combinatorial Bandits without Total Order for Arms
Mar 03, 2021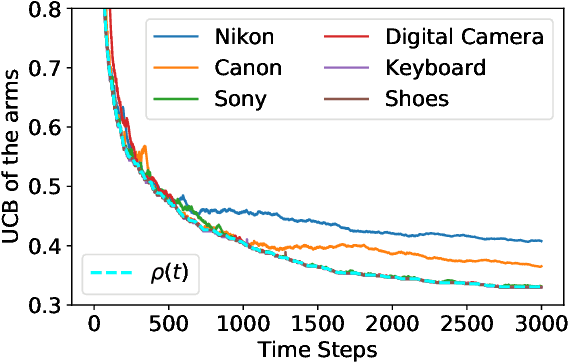
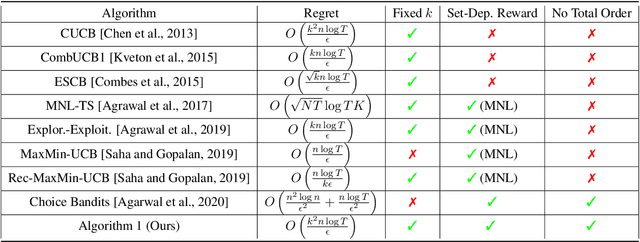
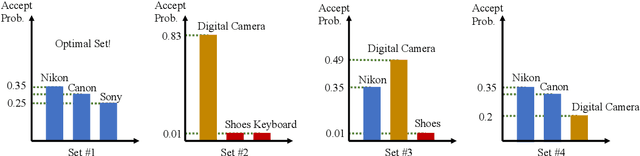
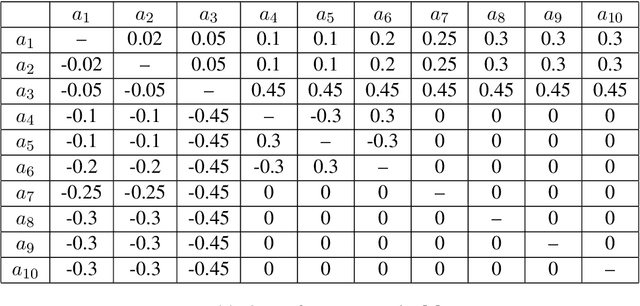
We consider the combinatorial bandits problem, where at each time step, the online learner selects a size-$k$ subset $s$ from the arms set $\mathcal{A}$, where $\left|\mathcal{A}\right| = n$, and observes a stochastic reward of each arm in the selected set $s$. The goal of the online learner is to minimize the regret, induced by not selecting $s^*$ which maximizes the expected total reward. Specifically, we focus on a challenging setting where 1) the reward distribution of an arm depends on the set $s$ it is part of, and crucially 2) there is \textit{no total order} for the arms in $\mathcal{A}$. In this paper, we formally present a reward model that captures set-dependent reward distribution and assumes no total order for arms. Correspondingly, we propose an Upper Confidence Bound (UCB) algorithm that maintains UCB for each individual arm and selects the arms with top-$k$ UCB. We develop a novel regret analysis and show an $O\left(\frac{k^2 n \log T}{\epsilon}\right)$ gap-dependent regret bound as well as an $O\left(k^2\sqrt{n T \log T}\right)$ gap-independent regret bound. We also provide a lower bound for the proposed reward model, which shows our proposed algorithm is near-optimal for any constant $k$. Empirical results on various reward models demonstrate the broad applicability of our algorithm.
Linear Bandit Algorithms with Sublinear Time Complexity
Mar 03, 2021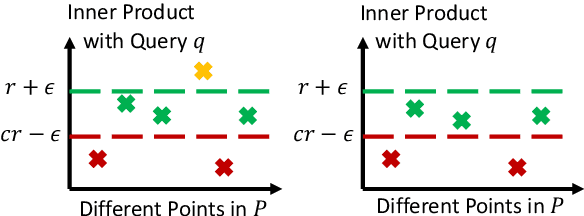
We propose to accelerate existing linear bandit algorithms to achieve per-step time complexity sublinear in the number of arms $K$. The key to sublinear complexity is the realization that the arm selection in many linear bandit algorithms reduces to the maximum inner product search (MIPS) problem. Correspondingly, we propose an algorithm that approximately solves the MIPS problem for a sequence of adaptive queries yielding near-linear preprocessing time complexity and sublinear query time complexity. Using the proposed MIPS solver as a sub-routine, we present two bandit algorithms (one based on UCB, and the other based on TS) that achieve sublinear time complexity. We explicitly characterize the tradeoff between the per-step time complexity and regret, and show that our proposed algorithms can achieve $O(K^{1-\alpha(T)})$ per-step complexity for some $\alpha(T) > 0$ and $\widetilde O(\sqrt{T})$ regret, where $T$ is the time horizon. Further, we present the theoretical limit of the tradeoff, which provides a lower bound for the per-step time complexity. We also discuss other choices of approximate MIPS algorithms and other applications to linear bandit problems.
Accountable Off-Policy Evaluation With Kernel Bellman Statistics
Aug 15, 2020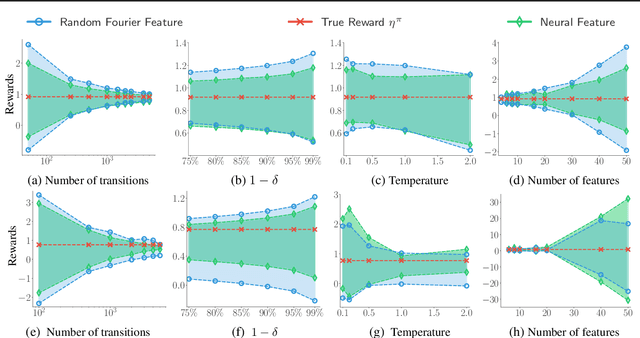
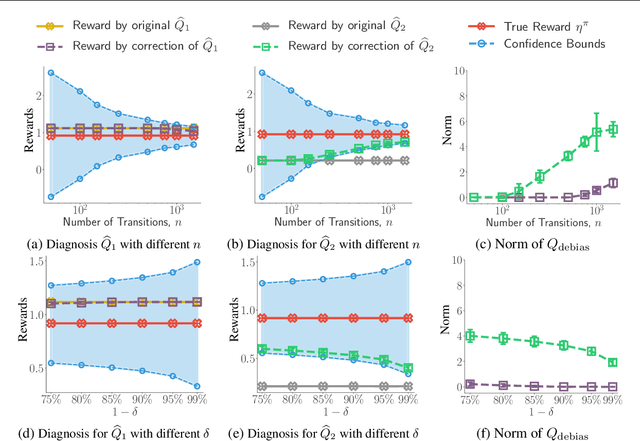
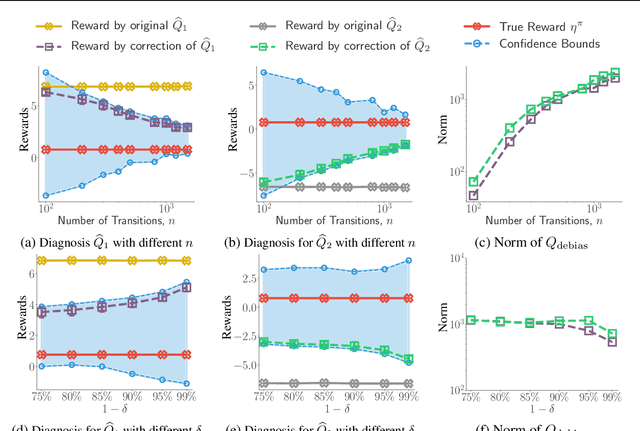
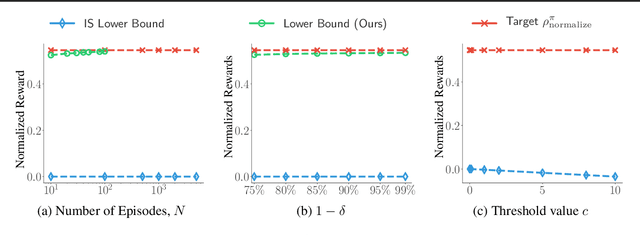
We consider off-policy evaluation (OPE), which evaluates the performance of a new policy from observed data collected from previous experiments, without requiring the execution of the new policy. This finds important applications in areas with high execution cost or safety concerns, such as medical diagnosis, recommendation systems and robotics. In practice, due to the limited information from off-policy data, it is highly desirable to construct rigorous confidence intervals, not just point estimation, for the policy performance. In this work, we propose a new variational framework which reduces the problem of calculating tight confidence bounds in OPE into an optimization problem on a feasible set that catches the true state-action value function with high probability. The feasible set is constructed by leveraging statistical properties of a recently proposed kernel Bellman loss (Feng et al., 2019). We design an efficient computational approach for calculating our bounds, and extend it to perform post-hoc diagnosis and correction for existing estimators. Empirical results show that our method yields tight confidence intervals in different settings.
Stein Self-Repulsive Dynamics: Benefits From Past Samples
Feb 21, 2020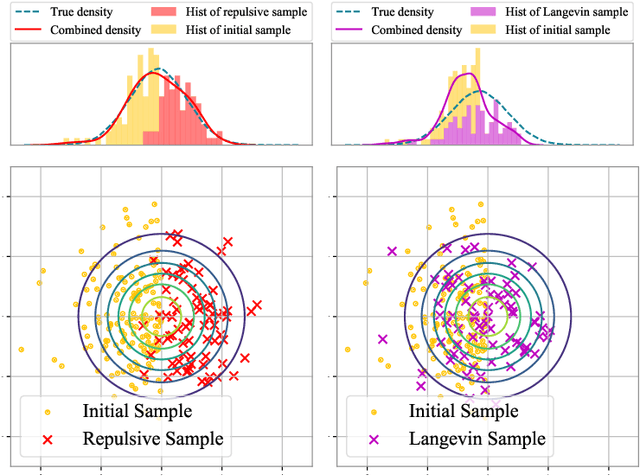
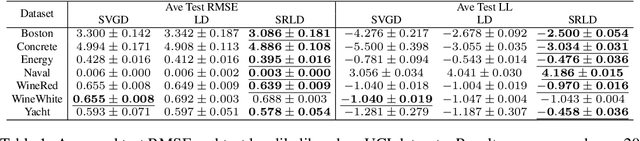


We propose a new Stein self-repulsive dynamics for obtaining diversified samples from intractable un-normalized distributions. Our idea is to introduce Stein variational gradient as a repulsive force to push the samples of Langevin dynamics away from the past trajectories. This simple idea allows us to significantly decrease the auto-correlation in Langevin dynamics and hence increase the effective sample size. Importantly, as we establish in our theoretical analysis, the asymptotic stationary distribution remains correct even with the addition of the repulsive force, thanks to the special properties of the Stein variational gradient. We perform extensive empirical studies of our new algorithm, showing that our method yields much higher sample efficiency and better uncertainty estimation than vanilla Langevin dynamics.
MaxUp: A Simple Way to Improve Generalization of Neural Network Training
Feb 20, 2020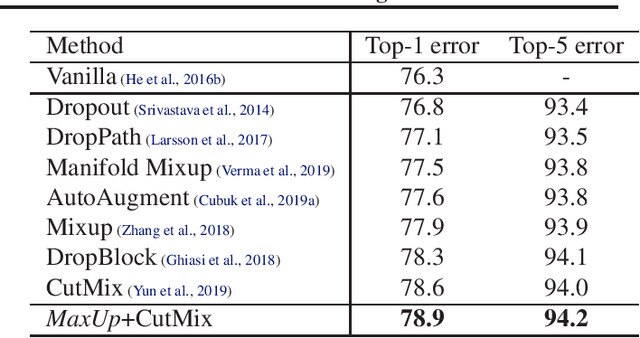
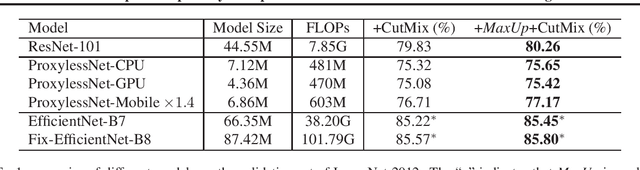
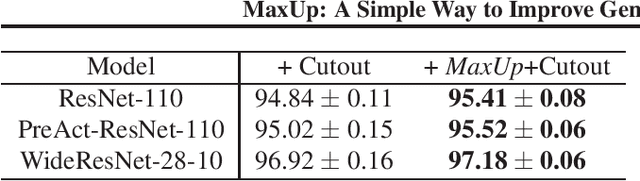

We propose \emph{MaxUp}, an embarrassingly simple, highly effective technique for improving the generalization performance of machine learning models, especially deep neural networks. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, we implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. For example, in the case of Gaussian perturbation, \emph{MaxUp} is asymptotically equivalent to using the gradient norm of the loss as a penalty to encourage smoothness. We test \emph{MaxUp} on a range of tasks, including image classification, language modeling, and adversarial certification, on which \emph{MaxUp} consistently outperforms the existing best baseline methods, without introducing substantial computational overhead. In particular, we improve ImageNet classification from the state-of-the-art top-1 accuracy $85.5\%$ without extra data to $85.8\%$. Code will be released soon.
Implicit Regularization of Normalization Methods
Nov 23, 2019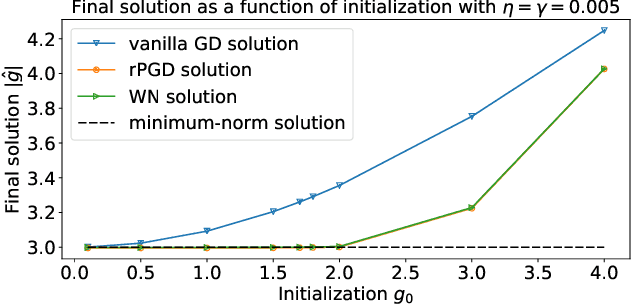
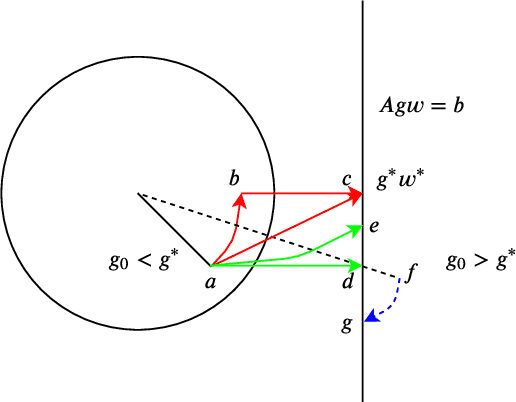
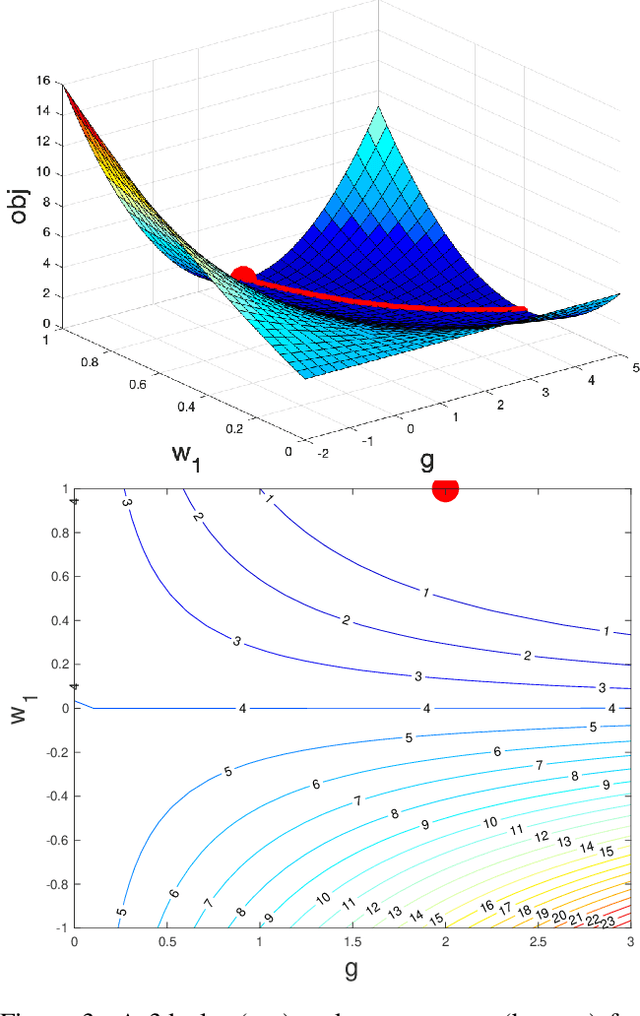
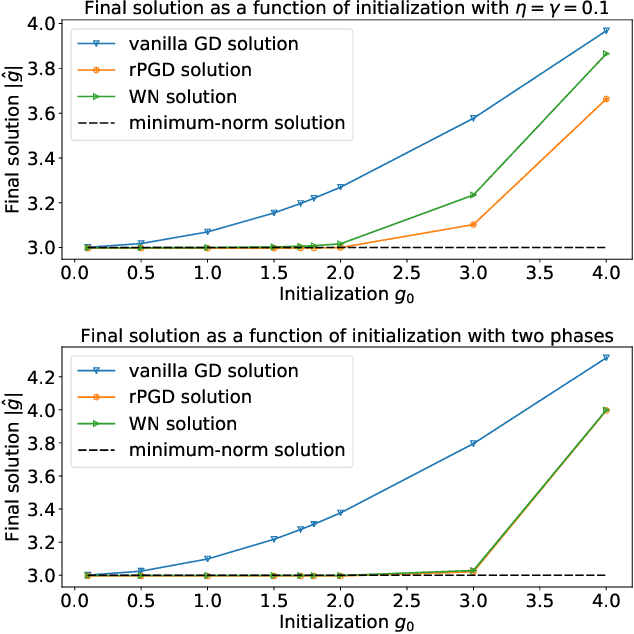
Normalization methods such as batch normalization are commonly used in overparametrized models like neural networks. Here, we study the weight normalization (WN) method (Salimans & Kingma, 2016) and a variant called reparametrized projected gradient descent (rPGD) for overparametrized least squares regression and some more general loss functions. WN and rPGD reparametrize the weights with a scale $g$ and a unit vector such that the objective function becomes \emph{non-convex}. We show that this non-convex formulation has beneficial regularization effects compared to gradient descent on the original objective. We show that these methods adaptively regularize the weights and \emph{converge with exponential rate} to the minimum $\ell_2$ norm solution (or close to it) even for initializations \emph{far from zero}. This is different from the behavior of gradient descent, which only converges to the min norm solution when started at zero, and is more sensitive to initialization. Some of our proof techniques are different from many related works; for instance we find explicit invariants along the gradient flow paths. We verify our results experimentally and suggest that there may be a similar phenomenon for nonlinear problems such as matrix sensing.
Function Space Particle Optimization for Bayesian Neural Networks
Feb 26, 2019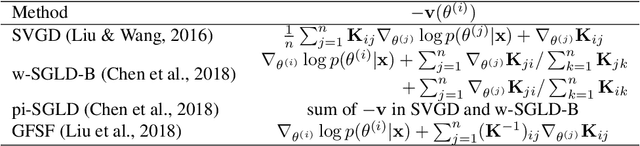
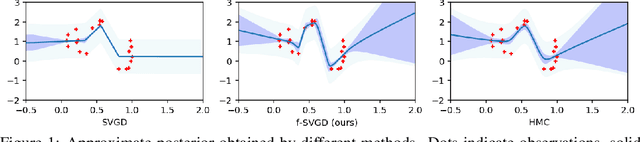
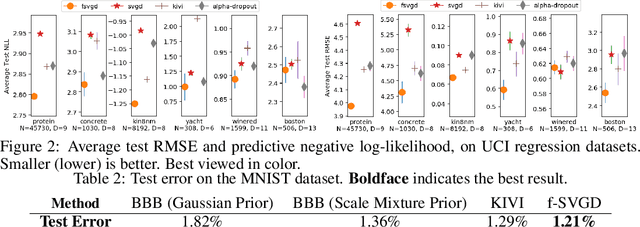
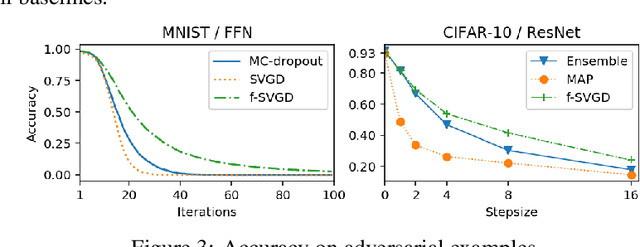
While Bayesian neural networks (BNNs) have drawn increasing attention, their posterior inference remains challenging, due to the high-dimensional and over-parameterized nature. To address this issue, several highly flexible and scalable variational inference procedures based on the idea of particle optimization have been proposed. These methods directly optimize a set of particles to approximate the target posterior. However, their application to BNNs often yields sub-optimal performance, as such methods have a particular failure mode on over-parameterized models. In this paper, we propose to solve this issue by performing particle optimization directly in the space of regression functions. We demonstrate through extensive experiments that our method successfully overcomes this issue, and outperforms strong baselines in a variety of tasks including prediction, defense against adversarial examples, and reinforcement learning.
Reward Shaping via Meta-Learning
Jan 27, 2019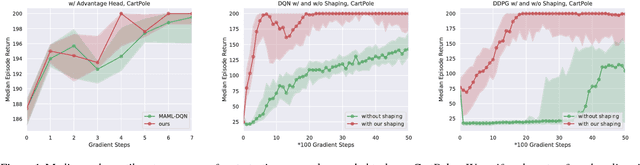
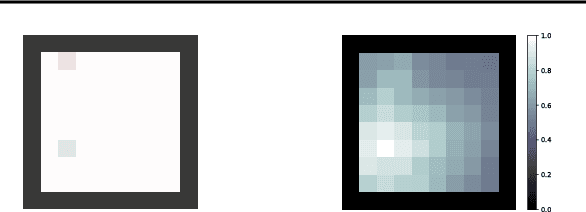
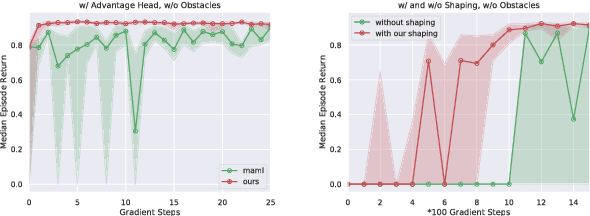

Reward shaping is one of the most effective methods to tackle the crucial yet challenging problem of credit assignment in Reinforcement Learning (RL). However, designing shaping functions usually requires much expert knowledge and hand-engineering, and the difficulties are further exacerbated given multiple similar tasks to solve. In this paper, we consider reward shaping on a distribution of tasks, and propose a general meta-learning framework to automatically learn the efficient reward shaping on newly sampled tasks, assuming only shared state space but not necessarily action space. We first derive the theoretically optimal reward shaping in terms of credit assignment in model-free RL. We then propose a value-based meta-learning algorithm to extract an effective prior over the optimal reward shaping. The prior can be applied directly to new tasks, or provably adapted to the task-posterior while solving the task within few gradient updates. We demonstrate the effectiveness of our shaping through significantly improved learning efficiency and interpretable visualizations across various settings, including notably a successful transfer from DQN to DDPG.
Lazy-CFR: a fast regret minimization algorithm for extensive games with imperfect information
Oct 10, 2018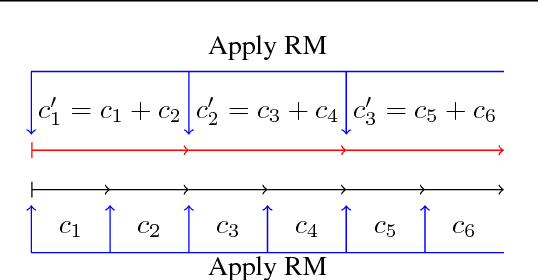
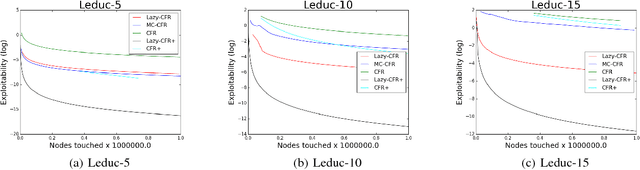
In this paper, we focus on solving two-player zero-sum extensive games with imperfect information. Counterfactual regret minimization (CFR) is the most popular algorithm on solving such games and achieves state-of-the-art performance in practice. However, the performance of CFR is not fully understood, since empirical results on the regret are much better than the upper bound proved in \cite{zinkevich2008regret}. Another issue of CFR is that CFR has to traverse the whole game tree in each round, which is not tolerable in large scale games. In this paper, we present a novel technique, lazy update, which can avoid traversing the whole game tree in CFR. Further, we present a novel analysis on the CFR with lazy update. Our analysis can also be applied to the vanilla CFR, which results in a much tighter regret bound than that proved in \cite{zinkevich2008regret}. Inspired by lazy update, we further present a novel CFR variant, named Lazy-CFR. Compared to traversing $O(|\mathcal{I}|)$ information sets in vanilla CFR, Lazy-CFR needs only to traverse $O(\sqrt{|\mathcal{I}|})$ information sets per round while the regret bound almost keep the same, where $\mathcal{I}$ is the class of all information sets. As a result, Lazy-CFR shows better convergence result compared with vanilla CFR. Experimental results consistently show that Lazy-CFR outperforms the vanilla CFR significantly.