 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGANE: Morphable Eyeglass and Avatar Network
Feb 09, 2023



Eyeglasses play an important role in the perception of identity. Authentic virtual representations of faces can benefit greatly from their inclusion. However, modeling the geometric and appearance interactions of glasses and the face of virtual representations of humans is challenging. Glasses and faces affect each other's geometry at their contact points, and also induce appearance changes due to light transport. Most existing approaches do not capture these physical interactions since they model eyeglasses and faces independently. Others attempt to resolve interactions as a 2D image synthesis problem and suffer from view and temporal inconsistencies. In this work, we propose a 3D compositional morphable model of eyeglasses that accurately incorporates high-fidelity geometric and photometric interaction effects. To support the large variation in eyeglass topology efficiently, we employ a hybrid representation that combines surface geometry and a volumetric representation. Unlike volumetric approaches, our model naturally retains correspondences across glasses, and hence explicit modification of geometry, such as lens insertion and frame deformation, is greatly simplified. In addition, our model is relightable under point lights and natural illumination, supporting high-fidelity rendering of various frame materials, including translucent plastic and metal within a single morphable model. Importantly, our approach models global light transport effects, such as casting shadows between faces and glasses. Our morphable model for eyeglasses can also be fit to novel glasses via inverse rendering. We compare our approach to state-of-the-art methods and demonstrate significant quality improvements.
Multiface: A Dataset for Neural Face Rendering
Jul 22, 2022



Photorealistic avatars of human faces have come a long way in recent years, yet research along this area is limited by a lack of publicly available, high-quality datasets covering both, dense multi-view camera captures, and rich facial expressions of the captured subjects. In this work, we present Multiface, a new multi-view, high-resolution human face dataset collected from 13 identities at Reality Labs Research for neural face rendering. We introduce Mugsy, a large scale multi-camera apparatus to capture high-resolution synchronized videos of a facial performance. The goal of Multiface is to close the gap in accessibility to high quality data in the academic community and to enable research in VR telepresence. Along with the release of the dataset, we conduct ablation studies on the influence of different model architectures toward the model's interpolation capacity of novel viewpoint and expressions. With a conditional VAE model serving as our baseline, we found that adding spatial bias, texture warp field, and residual connections improves performance on novel view synthesis. Our code and data is available at: https://github.com/facebookresearch/multiface
Drivable Volumetric Avatars using Texel-Aligned Features
Jul 20, 2022
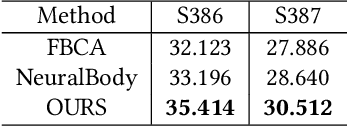
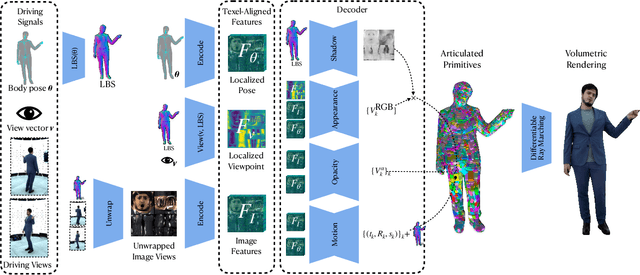
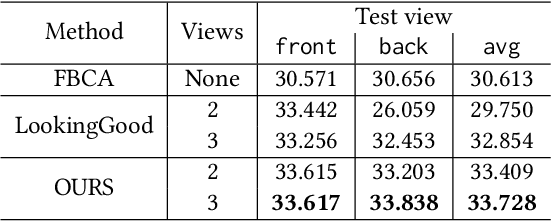
Photorealistic telepresence requires both high-fidelity body modeling and faithful driving to enable dynamically synthesized appearance that is indistinguishable from reality. In this work, we propose an end-to-end framework that addresses two core challenges in modeling and driving full-body avatars of real people. One challenge is driving an avatar while staying faithful to details and dynamics that cannot be captured by a global low-dimensional parameterization such as body pose. Our approach supports driving of clothed avatars with wrinkles and motion that a real driving performer exhibits beyond the training corpus. Unlike existing global state representations or non-parametric screen-space approaches, we introduce texel-aligned features -- a localised representation which can leverage both the structural prior of a skeleton-based parametric model and observed sparse image signals at the same time. Another challenge is modeling a temporally coherent clothed avatar, which typically requires precise surface tracking. To circumvent this, we propose a novel volumetric avatar representation by extending mixtures of volumetric primitives to articulated objects. By explicitly incorporating articulation, our approach naturally generalizes to unseen poses. We also introduce a localized viewpoint conditioning, which leads to a large improvement in generalization of view-dependent appearance. The proposed volumetric representation does not require high-quality mesh tracking as a prerequisite and brings significant quality improvements compared to mesh-based counterparts. In our experiments, we carefully examine our design choices and demonstrate the efficacy of our approach, outperforming the state-of-the-art methods on challenging driving scenarios.
Advances in Neural Rendering
Nov 10, 2021Synthesizing photo-realistic images and videos is at the heart of computer graphics and has been the focus of decades of research. Traditionally, synthetic images of a scene are generated using rendering algorithms such as rasterization or ray tracing, which take specifically defined representations of geometry and material properties as input. Collectively, these inputs define the actual scene and what is rendered, and are referred to as the scene representation (where a scene consists of one or more objects). Example scene representations are triangle meshes with accompanied textures (e.g., created by an artist), point clouds (e.g., from a depth sensor), volumetric grids (e.g., from a CT scan), or implicit surface functions (e.g., truncated signed distance fields). The reconstruction of such a scene representation from observations using differentiable rendering losses is known as inverse graphics or inverse rendering. Neural rendering is closely related, and combines ideas from classical computer graphics and machine learning to create algorithms for synthesizing images from real-world observations. Neural rendering is a leap forward towards the goal of synthesizing photo-realistic image and video content. In recent years, we have seen immense progress in this field through hundreds of publications that show different ways to inject learnable components into the rendering pipeline. This state-of-the-art report on advances in neural rendering focuses on methods that combine classical rendering principles with learned 3D scene representations, often now referred to as neural scene representations. A key advantage of these methods is that they are 3D-consistent by design, enabling applications such as novel viewpoint synthesis of a captured scene. In addition to methods that handle static scenes, we cover neural scene representations for modeling non-rigidly deforming objects...
Driving-Signal Aware Full-Body Avatars
May 21, 2021
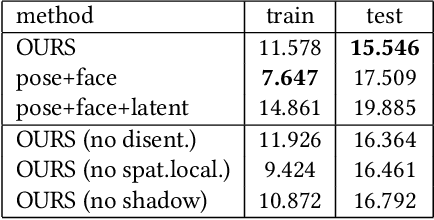
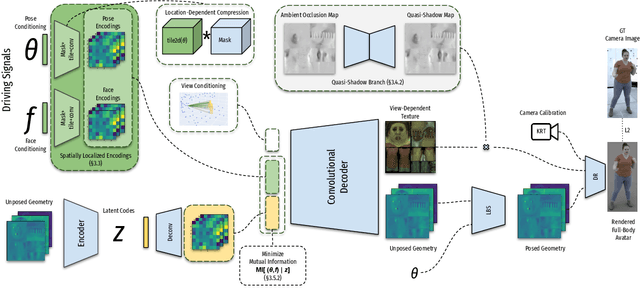
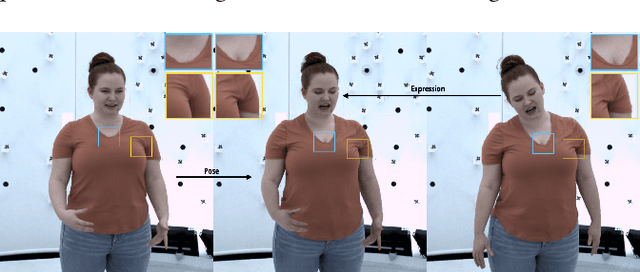
We present a learning-based method for building driving-signal aware full-body avatars. Our model is a conditional variational autoencoder that can be animated with incomplete driving signals, such as human pose and facial keypoints, and produces a high-quality representation of human geometry and view-dependent appearance. The core intuition behind our method is that better drivability and generalization can be achieved by disentangling the driving signals and remaining generative factors, which are not available during animation. To this end, we explicitly account for information deficiency in the driving signal by introducing a latent space that exclusively captures the remaining information, thus enabling the imputation of the missing factors required during full-body animation, while remaining faithful to the driving signal. We also propose a learnable localized compression for the driving signal which promotes better generalization, and helps minimize the influence of global chance-correlations often found in real datasets. For a given driving signal, the resulting variational model produces a compact space of uncertainty for missing factors that allows for an imputation strategy best suited to a particular application. We demonstrate the efficacy of our approach on the challenging problem of full-body animation for virtual telepresence with driving signals acquired from minimal sensors placed in the environment and mounted on a VR-headset.
Pixel Codec Avatars
Apr 09, 2021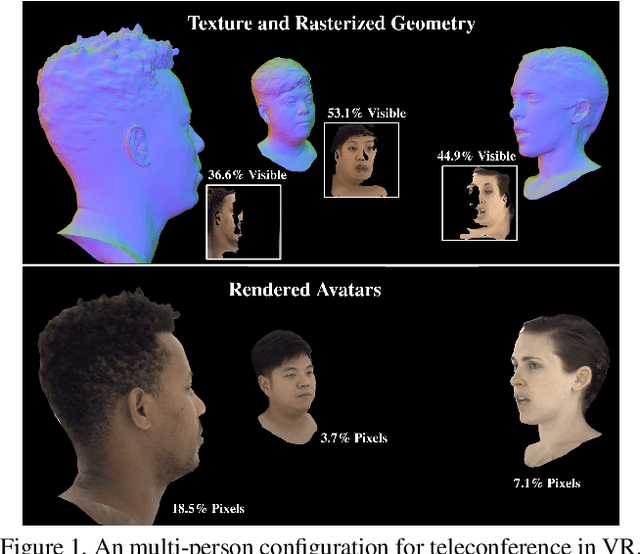
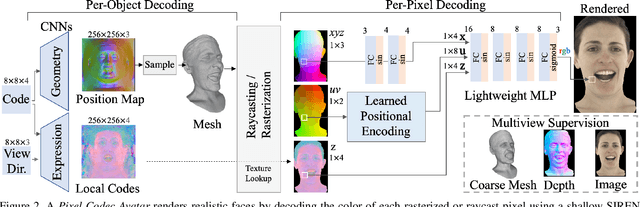
Telecommunication with photorealistic avatars in virtual or augmented reality is a promising path for achieving authentic face-to-face communication in 3D over remote physical distances. In this work, we present the Pixel Codec Avatars (PiCA): a deep generative model of 3D human faces that achieves state of the art reconstruction performance while being computationally efficient and adaptive to the rendering conditions during execution. Our model combines two core ideas: (1) a fully convolutional architecture for decoding spatially varying features, and (2) a rendering-adaptive per-pixel decoder. Both techniques are integrated via a dense surface representation that is learned in a weakly-supervised manner from low-topology mesh tracking over training images. We demonstrate that PiCA improves reconstruction over existing techniques across testing expressions and views on persons of different gender and skin tone. Importantly, we show that the PiCA model is much smaller than the state-of-art baseline model, and makes multi-person telecommunicaiton possible: on a single Oculus Quest 2 mobile VR headset, 5 avatars are rendered in realtime in the same scene.
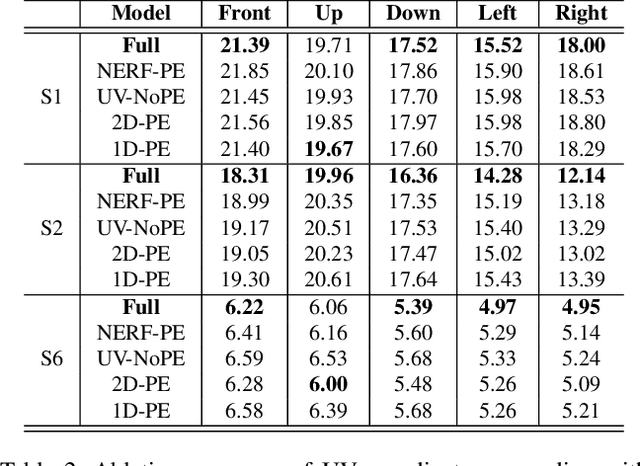
SimPoE: Simulated Character Control for 3D Human Pose Estimation
Apr 01, 2021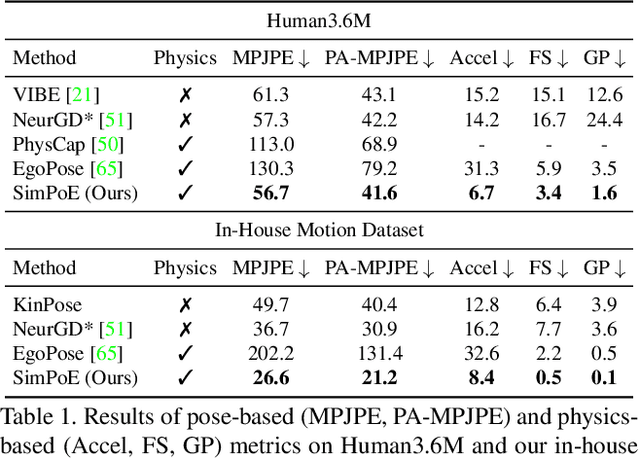
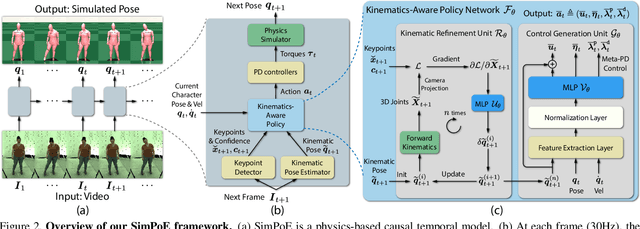
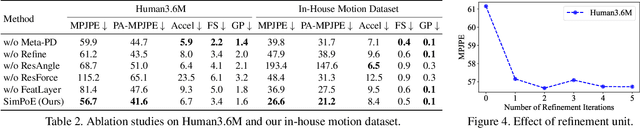
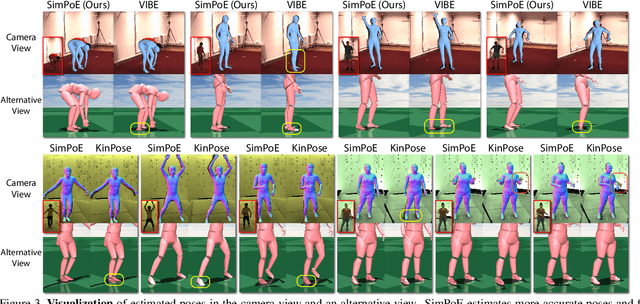
Accurate estimation of 3D human motion from monocular video requires modeling both kinematics (body motion without physical forces) and dynamics (motion with physical forces). To demonstrate this, we present SimPoE, a Simulation-based approach for 3D human Pose Estimation, which integrates image-based kinematic inference and physics-based dynamics modeling. SimPoE learns a policy that takes as input the current-frame pose estimate and the next image frame to control a physically-simulated character to output the next-frame pose estimate. The policy contains a learnable kinematic pose refinement unit that uses 2D keypoints to iteratively refine its kinematic pose estimate of the next frame. Based on this refined kinematic pose, the policy learns to compute dynamics-based control (e.g., joint torques) of the character to advance the current-frame pose estimate to the pose estimate of the next frame. This design couples the kinematic pose refinement unit with the dynamics-based control generation unit, which are learned jointly with reinforcement learning to achieve accurate and physically-plausible pose estimation. Furthermore, we propose a meta-control mechanism that dynamically adjusts the character's dynamics parameters based on the character state to attain more accurate pose estimates. Experiments on large-scale motion datasets demonstrate that our approach establishes the new state of the art in pose accuracy while ensuring physical plausibility.
Mixture of Volumetric Primitives for Efficient Neural Rendering
Mar 02, 2021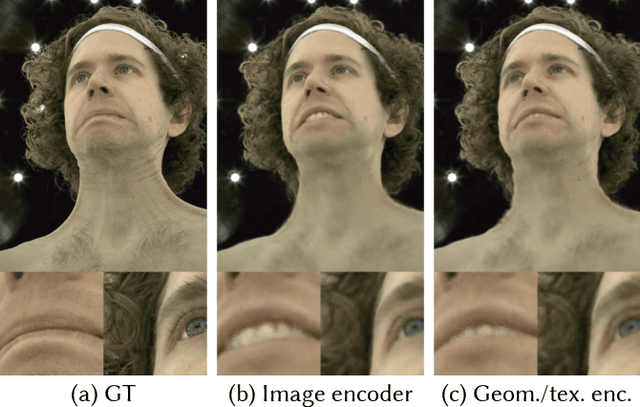
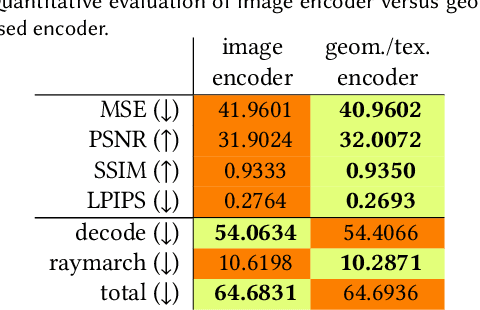
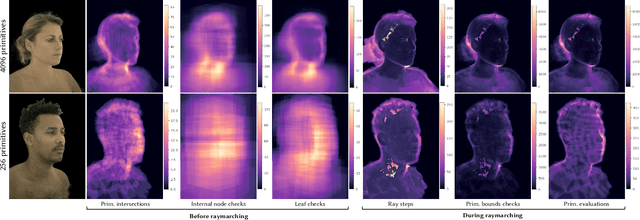
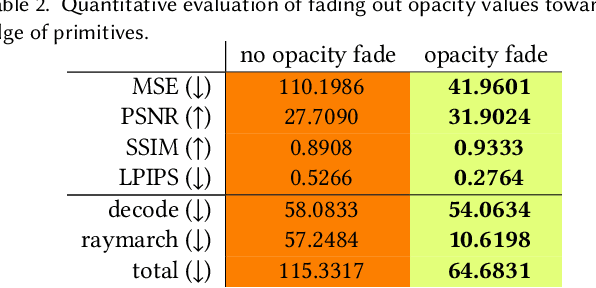
Real-time rendering and animation of humans is a core function in games, movies, and telepresence applications. Existing methods have a number of drawbacks we aim to address with our work. Triangle meshes have difficulty modeling thin structures like hair, volumetric representations like Neural Volumes are too low-resolution given a reasonable memory budget, and high-resolution implicit representations like Neural Radiance Fields are too slow for use in real-time applications. We present Mixture of Volumetric Primitives (MVP), a representation for rendering dynamic 3D content that combines the completeness of volumetric representations with the efficiency of primitive-based rendering, e.g., point-based or mesh-based methods. Our approach achieves this by leveraging spatially shared computation with a deconvolutional architecture and by minimizing computation in empty regions of space with volumetric primitives that can move to cover only occupied regions. Our parameterization supports the integration of correspondence and tracking constraints, while being robust to areas where classical tracking fails, such as around thin or translucent structures and areas with large topological variability. MVP is a hybrid that generalizes both volumetric and primitive-based representations. Through a series of extensive experiments we demonstrate that it inherits the strengths of each, while avoiding many of their limitations. We also compare our approach to several state-of-the-art methods and demonstrate that MVP produces superior results in terms of quality and runtime performance.
PVA: Pixel-aligned Volumetric Avatars
Jan 07, 2021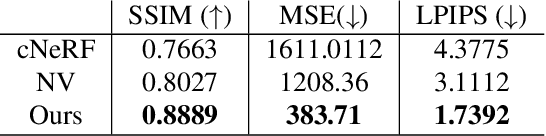
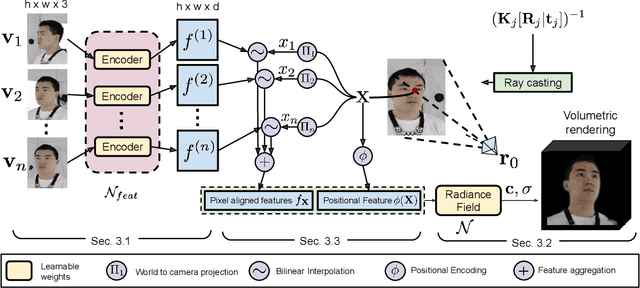


Acquisition and rendering of photo-realistic human heads is a highly challenging research problem of particular importance for virtual telepresence. Currently, the highest quality is achieved by volumetric approaches trained in a person specific manner on multi-view data. These models better represent fine structure, such as hair, compared to simpler mesh-based models. Volumetric models typically employ a global code to represent facial expressions, such that they can be driven by a small set of animation parameters. While such architectures achieve impressive rendering quality, they can not easily be extended to the multi-identity setting. In this paper, we devise a novel approach for predicting volumetric avatars of the human head given just a small number of inputs. We enable generalization across identities by a novel parameterization that combines neural radiance fields with local, pixel-aligned features extracted directly from the inputs, thus sidestepping the need for very deep or complex networks. Our approach is trained in an end-to-end manner solely based on a photometric re-rendering loss without requiring explicit 3D supervision.We demonstrate that our approach outperforms the existing state of the art in terms of quality and is able to generate faithful facial expressions in a multi-identity setting.
Learning Compositional Radiance Fields of Dynamic Human Heads
Dec 17, 2020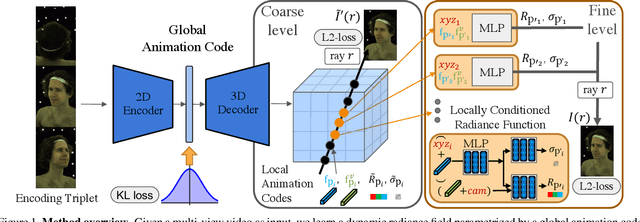



Photorealistic rendering of dynamic humans is an important ability for telepresence systems, virtual shopping, synthetic data generation, and more. Recently, neural rendering methods, which combine techniques from computer graphics and machine learning, have created high-fidelity models of humans and objects. Some of these methods do not produce results with high-enough fidelity for driveable human models (Neural Volumes) whereas others have extremely long rendering times (NeRF). We propose a novel compositional 3D representation that combines the best of previous methods to produce both higher-resolution and faster results. Our representation bridges the gap between discrete and continuous volumetric representations by combining a coarse 3D-structure-aware grid of animation codes with a continuous learned scene function that maps every position and its corresponding local animation code to its view-dependent emitted radiance and local volume density. Differentiable volume rendering is employed to compute photo-realistic novel views of the human head and upper body as well as to train our novel representation end-to-end using only 2D supervision. In addition, we show that the learned dynamic radiance field can be used to synthesize novel unseen expressions based on a global animation code. Our approach achieves state-of-the-art results for synthesizing novel views of dynamic human heads and the upper body.