 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
Jun 04, 2021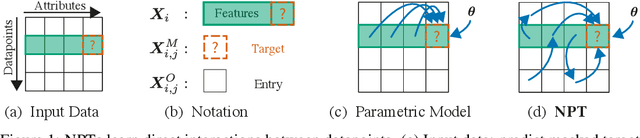
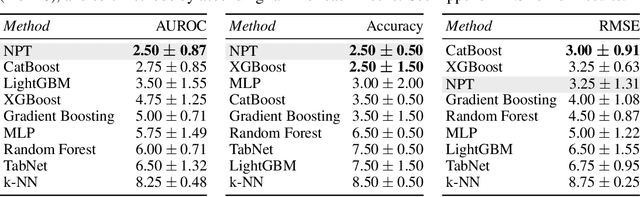
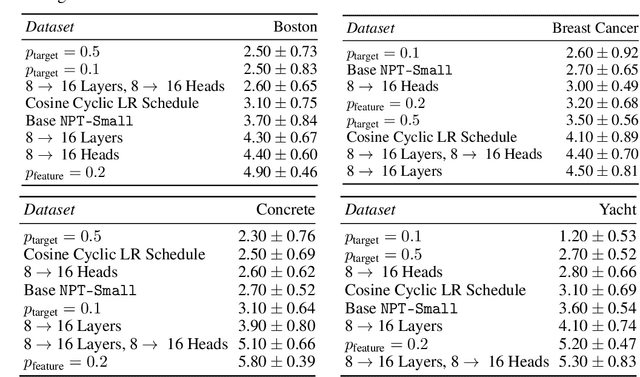
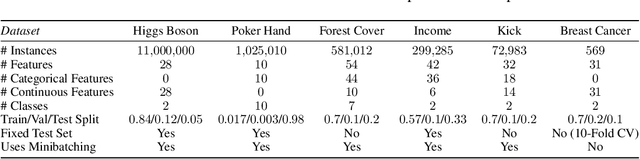
We challenge a common assumption underlying most supervised deep learning: that a model makes a prediction depending only on its parameters and the features of a single input. To this end, we introduce a general-purpose deep learning architecture that takes as input the entire dataset instead of processing one datapoint at a time. Our approach uses self-attention to reason about relationships between datapoints explicitly, which can be seen as realizing non-parametric models using parametric attention mechanisms. However, unlike conventional non-parametric models, we let the model learn end-to-end from the data how to make use of other datapoints for prediction. Empirically, our models solve cross-datapoint lookup and complex reasoning tasks unsolvable by traditional deep learning models. We show highly competitive results on tabular data, early results on CIFAR-10, and give insight into how the model makes use of the interactions between points.
Active Testing: Sample-Efficient Model Evaluation
Mar 09, 2021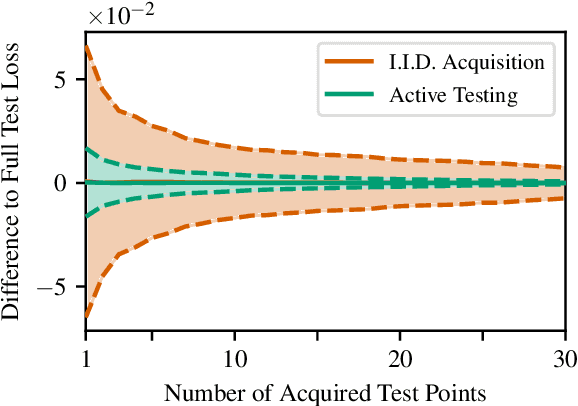
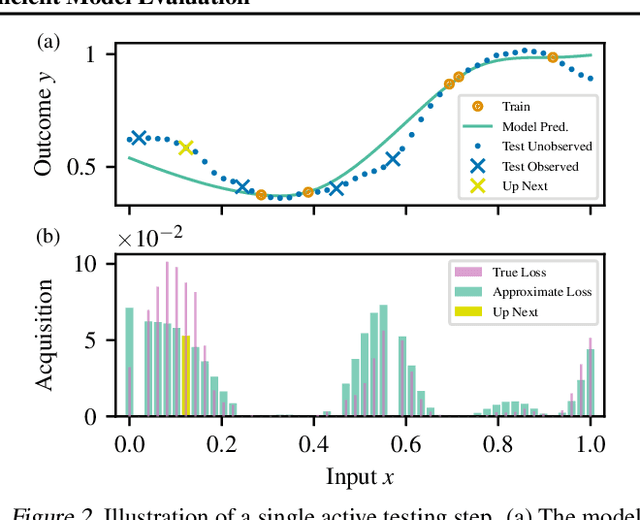
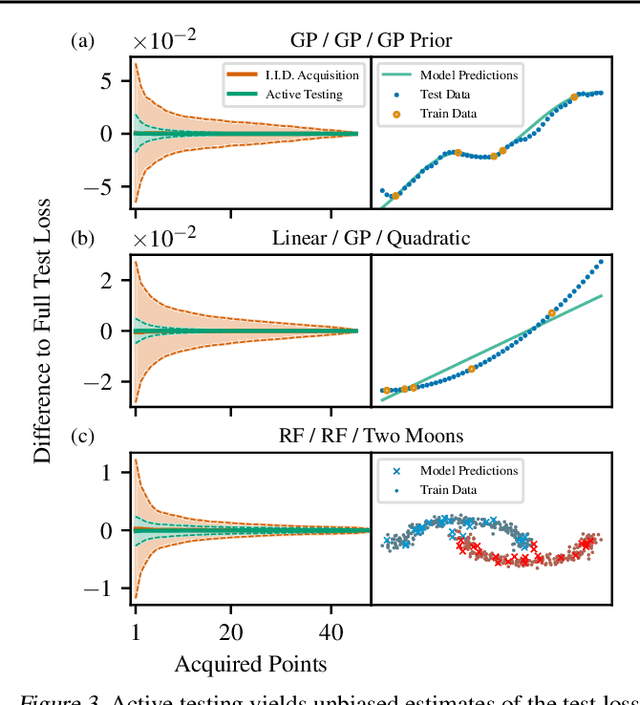
We introduce active testing: a new framework for sample-efficient model evaluation. While approaches like active learning reduce the number of labels needed for model training, existing literature largely ignores the cost of labeling test data, typically unrealistically assuming large test sets for model evaluation. This creates a disconnect to real applications where test labels are important and just as expensive, e.g. for optimizing hyperparameters. Active testing addresses this by carefully selecting the test points to label, ensuring model evaluation is sample-efficient. To this end, we derive theoretically-grounded and intuitive acquisition strategies that are specifically tailored to the goals of active testing, noting these are distinct to those of active learning. Actively selecting labels introduces a bias; we show how to remove that bias while reducing the variance of the estimator at the same time. Active testing is easy to implement, effective, and can be applied to any supervised machine learning method. We demonstrate this on models including WideResNet and Gaussian processes on datasets including CIFAR-100.
Deep Adaptive Design: Amortizing Sequential Bayesian Experimental Design
Mar 03, 2021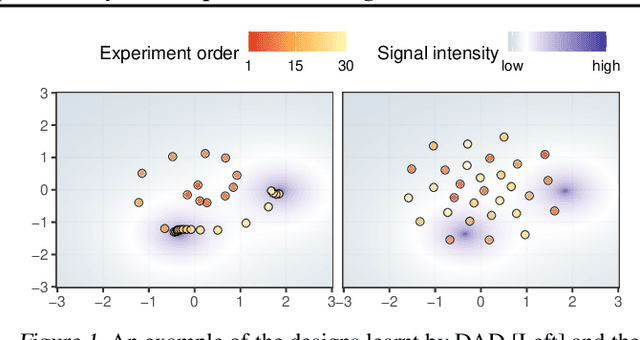

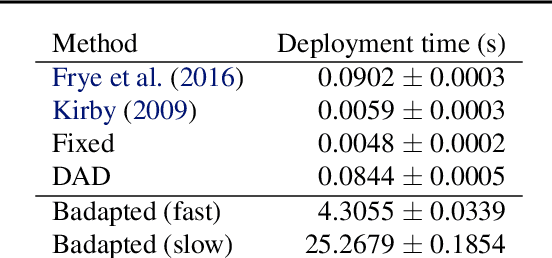
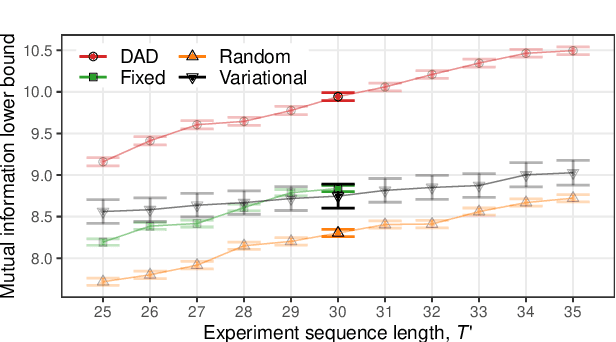
We introduce Deep Adaptive Design (DAD), a general method for amortizing the cost of performing sequential adaptive experiments using the framework of Bayesian optimal experimental design (BOED). Traditional sequential BOED approaches require substantial computational time at each stage of the experiment. This makes them unsuitable for most real-world applications, where decisions must typically be made quickly. DAD addresses this restriction by learning an amortized design network upfront and then using this to rapidly run (multiple) adaptive experiments at deployment time. This network takes as input the data from previous steps, and outputs the next design using a single forward pass; these design decisions can be made in milliseconds during the live experiment. To train the network, we introduce contrastive information bounds that are suitable objectives for the sequential setting, and propose a customized network architecture that exploits key symmetries. We demonstrate that DAD successfully amortizes the process of experimental design, outperforming alternative strategies on a number of problems.
Certifiably Robust Variational Autoencoders
Feb 15, 2021
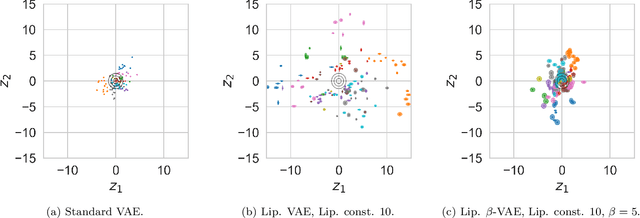
We introduce an approach for training Variational Autoencoders (VAEs) that are certifiably robust to adversarial attack. Specifically, we first derive actionable bounds on the minimal size of an input perturbation required to change a VAE's reconstruction by more than an allowed amount, with these bounds depending on certain key parameters such as the Lipschitz constants of the encoder and decoder. We then show how these parameters can be controlled, thereby providing a mechanism to ensure a priori that a VAE will attain a desired level of robustness. Moreover, we extend this to a complete practical approach for training such VAEs to ensure our criteria are met. Critically, our method allows one to specify a desired level of robustness upfront and then train a VAE that is guaranteed to achieve this robustness. We further demonstrate that these Lipschitz--constrained VAEs are more robust to attack than standard VAEs in practice.
On Statistical Bias In Active Learning: How and When To Fix It
Jan 27, 2021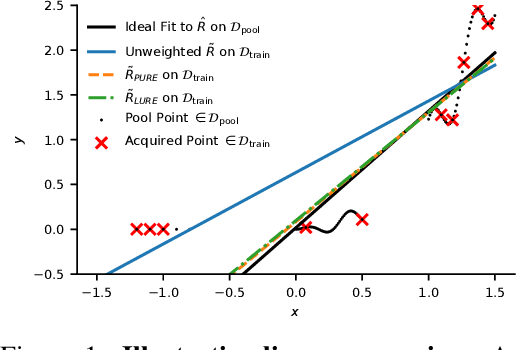

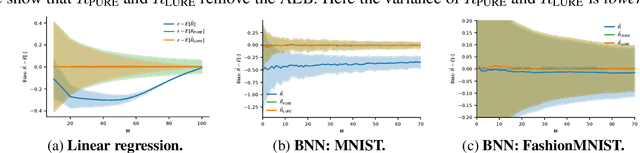

Active learning is a powerful tool when labelling data is expensive, but it introduces a bias because the training data no longer follows the population distribution. We formalize this bias and investigate the situations in which it can be harmful and sometimes even helpful. We further introduce novel corrective weights to remove bias when doing so is beneficial. Through this, our work not only provides a useful mechanism that can improve the active learning approach, but also an explanation of the empirical successes of various existing approaches which ignore this bias. In particular, we show that this bias can be actively helpful when training overparameterized models -- like neural networks -- with relatively little data.
On Signal-to-Noise Ratio Issues in Variational Inference for Deep Gaussian Processes
Nov 01, 2020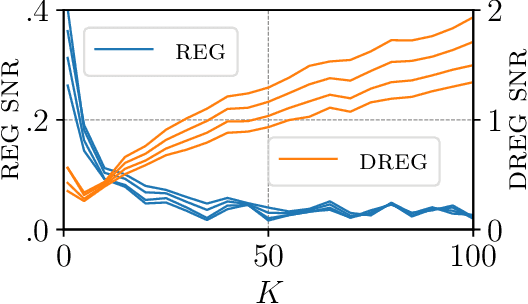
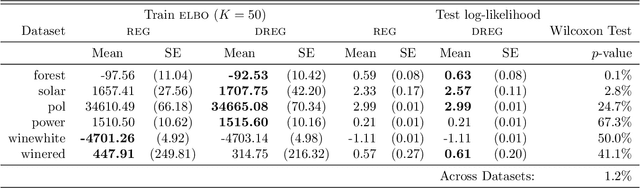
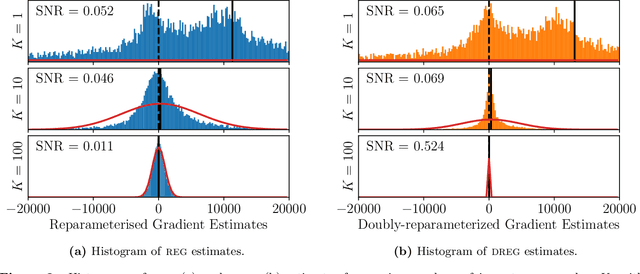
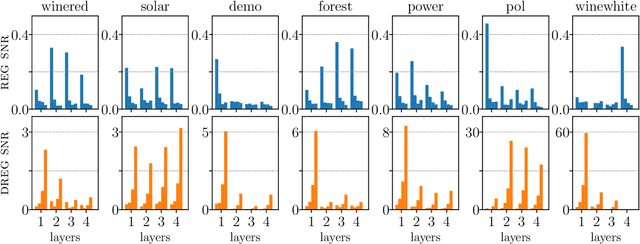
We show that the gradient estimates used in training Deep Gaussian Processes (DGPs) with importance-weighted variational inference are susceptible to signal-to-noise ratio (SNR) issues. Specifically, we show both theoretically and empirically that the SNR of the gradient estimates for the latent variable's variational parameters decreases as the number of importance samples increases. As a result, these gradient estimates degrade to pure noise if the number of importance samples is too large. To address this pathology, we show how doubly-reparameterized gradient estimators, originally proposed for training variational autoencoders, can be adapted to the DGP setting and that the resultant estimators completely remedy the SNR issue, thereby providing more reliable training. Finally, we demonstrate that our fix can lead to improvements in the predictive performance of the model's predictive posterior.
Improving Transformation Invariance in Contrastive Representation Learning
Oct 19, 2020
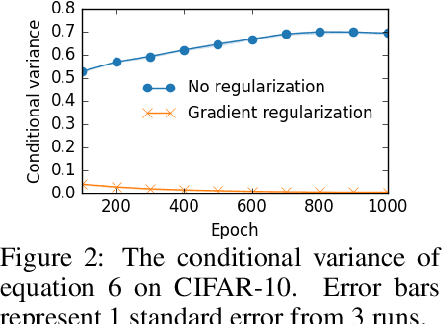
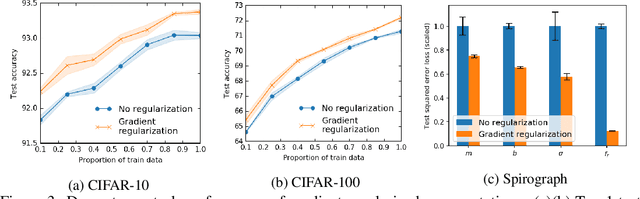

We propose methods to strengthen the invariance properties of representations obtained by contrastive learning. While existing approaches implicitly induce a degree of invariance as representations are learned, we look to more directly enforce invariance in the encoding process. To this end, we first introduce a training objective for contrastive learning that uses a novel regularizer to control how the representation changes under transformation. We show that representations trained with this objective perform better on downstream tasks and are more robust to the introduction of nuisance transformations at test time. Second, we propose a change to how test time representations are generated by introducing a feature averaging approach that combines encodings from multiple transformations of the original input, finding that this leads to across the board performance gains. Finally, we introduce the novel Spirograph dataset to explore our ideas in the context of a differentiable generative process with multiple downstream tasks, showing that our techniques for learning invariance are highly beneficial.
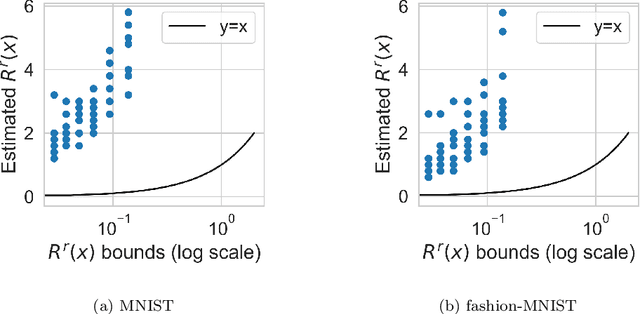
Towards a Theoretical Understanding of the Robustness of Variational Autoencoders
Jul 14, 2020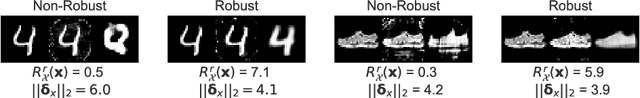

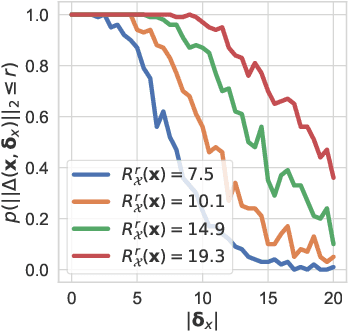
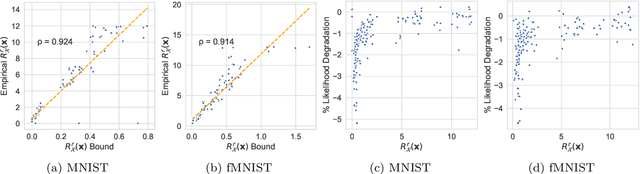
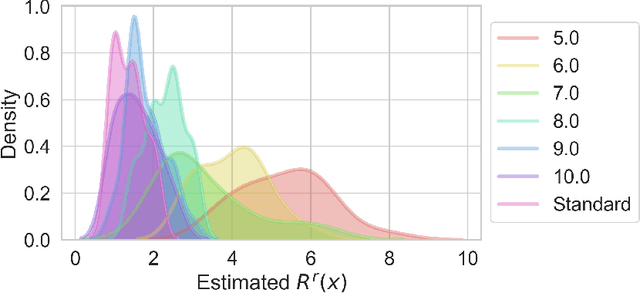
We make inroads into understanding the robustness of Variational Autoencoders (VAEs) to adversarial attacks and other input perturbations. While previous work has developed algorithmic approaches to attacking and defending VAEs, there remains a lack of formalization for what it means for a VAE to be robust. To address this, we develop a novel criterion for robustness in probabilistic models: $r$-robustness. We then use this to construct the first theoretical results for the robustness of VAEs, deriving margins in the input space for which we can provide guarantees about the resulting reconstruction. Informally, we are able to define a region within which any perturbation will produce a reconstruction that is similar to the original reconstruction. To support our analysis, we show that VAEs trained using disentangling methods not only score well under our robustness metrics, but that the reasons for this can be interpreted through our theoretical results.
Rethinking Semi-Supervised Learning in VAEs
Jun 17, 2020
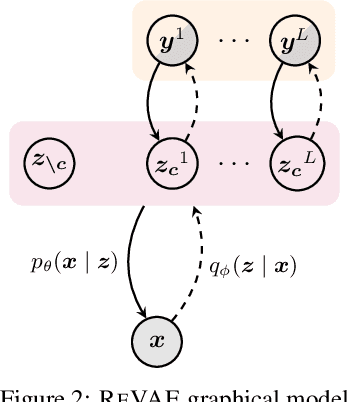

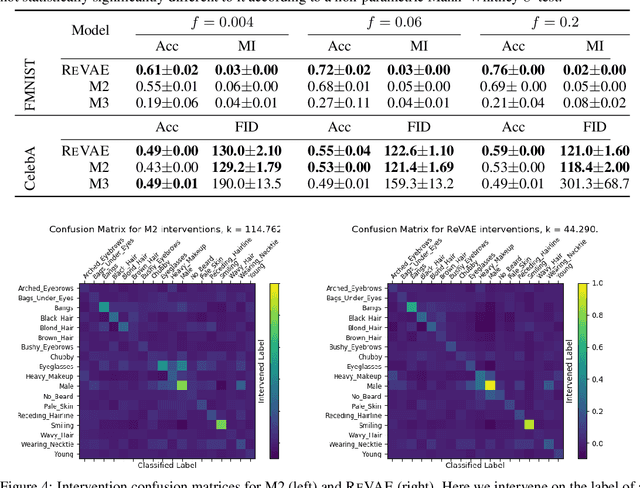
We present an alternative approach to semi-supervision in variational autoencoders(VAEs) that incorporates labels through auxiliary variables rather than directly through the latent variables. Prior work has generally conflated the meaning of labels, i.e. the associated characteristics of interest, with the actual label values themselves-learning latent variables that directly correspond to the label values. We argue that to learn meaningful representations, semi-supervision should instead try to capture these richer characteristics and that the construction of latent variables as label values is not just unnecessary, but actively harmful. To this end, we develop a novel VAE model, the reparameterized VAE (ReVAE), which "reparameterizes" supervision through auxiliary variables and a concomitant variational objective. Through judicious structuring of mappings between latent and auxiliary variables, we show that the ReVAE can effectively learn meaningful representations of data. In particular, we demonstrate that the ReVAE is able to match, and even improve on the classification accuracy of previous approaches, but more importantly, it also allows for more effective and more general interventions to be performed. We include a demo of ReVAE at https://github.com/thwjoy/revae-demo.
Statistically Robust Neural Network Classification
Dec 11, 2019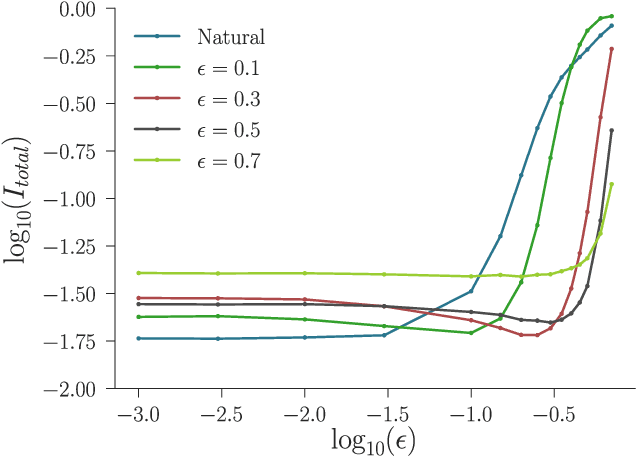
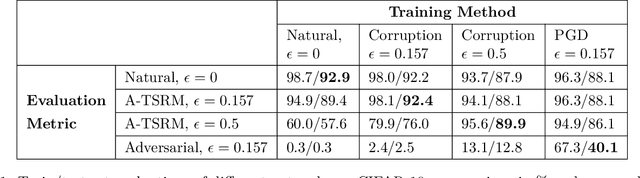
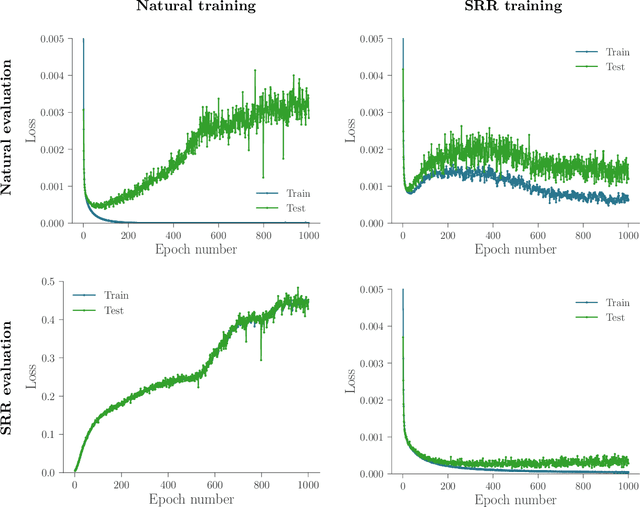
Recently there has been much interest in quantifying the robustness of neural network classifiers through adversarial risk metrics. However, for problems where test-time corruptions occur in a probabilistic manner, rather than being generated by an explicit adversary, adversarial metrics typically do not provide an accurate or reliable indicator of robustness. To address this, we introduce a statistically robust risk (SRR) framework which measures robustness in expectation over both network inputs and a corruption distribution. Unlike many adversarial risk metrics, which typically require separate applications on a point-by-point basis, the SRR can easily be directly estimated for an entire network and used as a training objective in a stochastic gradient scheme. Furthermore, we show both theoretically and empirically that it can scale to higher-dimensional networks by providing superior generalization performance compared with comparable adversarial risks.