 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEMBA-MQM: Detecting Translation Quality Error Spans with GPT-4
Oct 21, 2023This paper introduces GEMBA-MQM, a GPT-based evaluation metric designed to detect translation quality errors, specifically for the quality estimation setting without the need for human reference translations. Based on the power of large language models (LLM), GEMBA-MQM employs a fixed three-shot prompting technique, querying the GPT-4 model to mark error quality spans. Compared to previous works, our method has language-agnostic prompts, thus avoiding the need for manual prompt preparation for new languages. While preliminary results indicate that GEMBA-MQM achieves state-of-the-art accuracy for system ranking, we advise caution when using it in academic works to demonstrate improvements over other methods due to its dependence on the proprietary, black-box GPT model.
SLIDE: Reference-free Evaluation for Machine Translation using a Sliding Document Window
Sep 16, 2023


Reference-based metrics that operate at the sentence level typically outperform quality estimation metrics, which have access only to the source and system output. This is unsurprising, since references resolve ambiguities that may be present in the source. We investigate whether additional source context can effectively substitute for a reference. We present a metric, SLIDE (SLiding Document Evaluator), which operates on blocks of sentences using a window that slides over each document in the test set, feeding each chunk into an unmodified, off-the-shelf quality estimation model. We find that SLIDE obtains significantly higher pairwise system accuracy than its sentence-level baseline, in some cases even eliminating the gap with reference-base metrics. This suggests that source context may provide the same information as a human reference.
Large Language Models Are State-of-the-Art Evaluators of Translation Quality
Feb 28, 2023



We describe GEMBA, a GPT-based metric for assessment of translation quality, which works both with a reference translation and without. In our evaluation, we focus on zero-shot prompting, comparing four prompt variants in two modes, based on the availability of the reference. We investigate seven versions of GPT models, including ChatGPT. We show that our method for translation quality assessment only works with GPT 3.5 and larger models. Comparing to results from WMT22's Metrics shared task, our method achieves state-of-the-art accuracy in both modes when compared to MQM-based human labels. Our results are valid on the system level for all three WMT22 Metrics shared task language pairs, namely English into German, English into Russian, and Chinese into English. This provides a first glimpse into the usefulness of pre-trained, generative large language models for quality assessment of translations. We publicly release all our code and prompt templates used for the experiments described in this work, as well as all corresponding scoring results, to allow for external validation and reproducibility.
Poor Man's Quality Estimation: Predicting Reference-Based MT Metrics Without the Reference
Jan 28, 2023



Machine translation quality estimation (QE) predicts human judgements of a translation hypothesis without seeing the reference. State-of-the-art QE systems based on pretrained language models have been achieving remarkable correlations with human judgements yet they are computationally heavy and require human annotations, which are slow and expensive to create. To address these limitations, we define the problem of metric estimation (ME) where one predicts the automated metric scores also without the reference. We show that even without access to the reference, our model can estimate automated metrics ($\rho$=60% for BLEU, $\rho$=51% for other metrics) at the sentence-level. Because automated metrics correlate with human judgements, we can leverage the ME task for pre-training a QE model. For the QE task, we find that pre-training on TER is better ($\rho$=23%) than training for scratch ($\rho$=20%).
The Reality of Multi-Lingual Machine Translation
Feb 25, 2022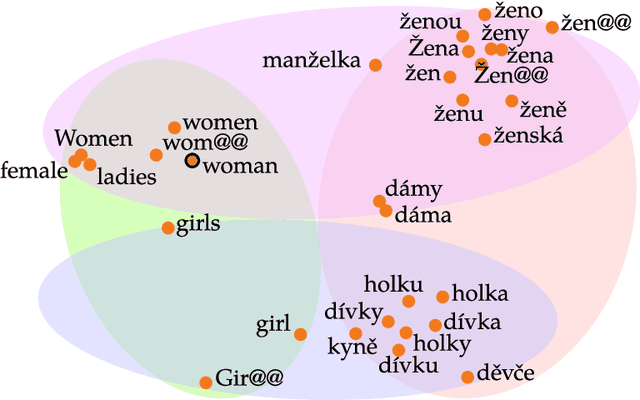
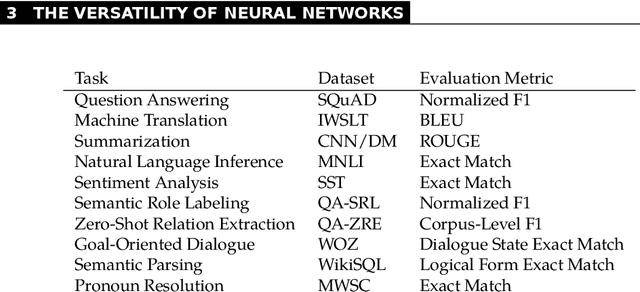
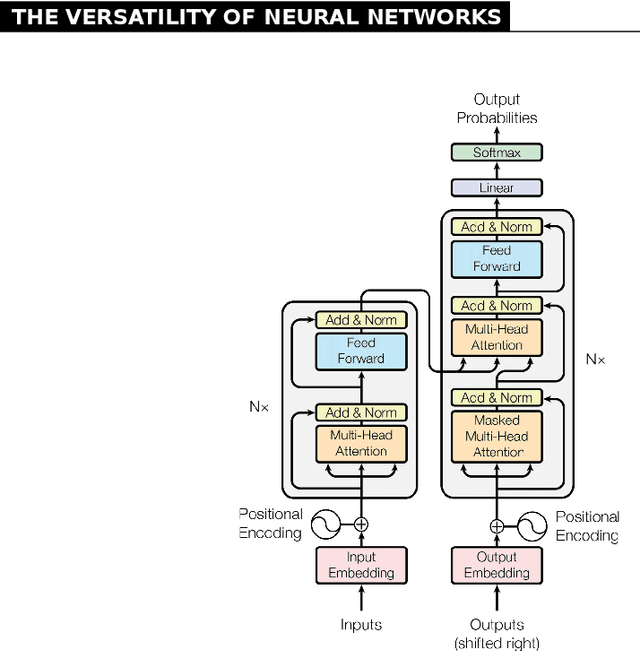

Our book "The Reality of Multi-Lingual Machine Translation" discusses the benefits and perils of using more than two languages in machine translation systems. While focused on the particular task of sequence-to-sequence processing and multi-task learning, the book targets somewhat beyond the area of natural language processing. Machine translation is for us a prime example of deep learning applications where human skills and learning capabilities are taken as a benchmark that many try to match and surpass. We document that some of the gains observed in multi-lingual translation may result from simpler effects than the assumed cross-lingual transfer of knowledge. In the first, rather general part, the book will lead you through the motivation for multi-linguality, the versatility of deep neural networks especially in sequence-to-sequence tasks to complications of this learning. We conclude the general part with warnings against too optimistic and unjustified explanations of the gains that neural networks demonstrate. In the second part, we fully delve into multi-lingual models, with a particularly careful examination of transfer learning as one of the more straightforward approaches utilizing additional languages. The recent multi-lingual techniques, including massive models, are surveyed and practical aspects of deploying systems for many languages are discussed. The conclusion highlights the open problem of machine understanding and reminds of two ethical aspects of building large-scale models: the inclusivity of research and its ecological trace.
To Ship or Not to Ship: An Extensive Evaluation of Automatic Metrics for Machine Translation
Jul 22, 2021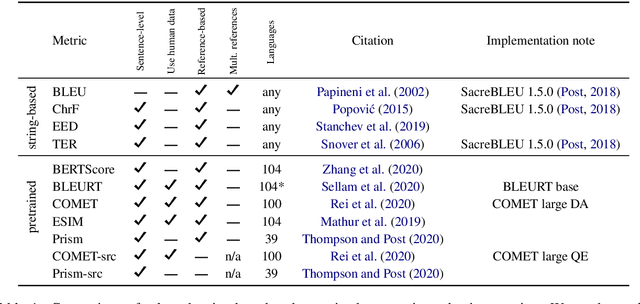

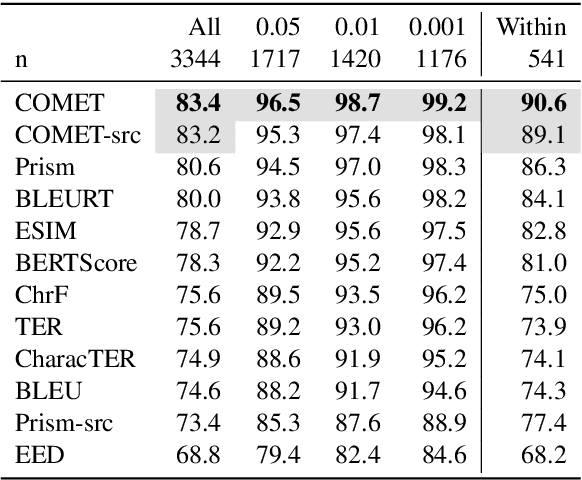

Automatic metrics are commonly used as the exclusive tool for declaring the superiority of one machine translation system's quality over another. The community choice of automatic metric guides research directions and industrial developments by deciding which models are deemed better. Evaluating metrics correlations has been limited to a small collection of human judgements. In this paper, we corroborate how reliable metrics are in contrast to human judgements on - to the best of our knowledge - the largest collection of human judgements. We investigate which metrics have the highest accuracy to make system-level quality rankings for pairs of systems, taking human judgement as a gold standard, which is the closest scenario to the real metric usage. Furthermore, we evaluate the performance of various metrics across different language pairs and domains. Lastly, we show that the sole use of BLEU negatively affected the past development of improved models. We release the collection of human judgements of 4380 systems, and 2.3 M annotated sentences for further analysis and replication of our work.
On User Interfaces for Large-Scale Document-Level Human Evaluation of Machine Translation Outputs
Apr 21, 2021
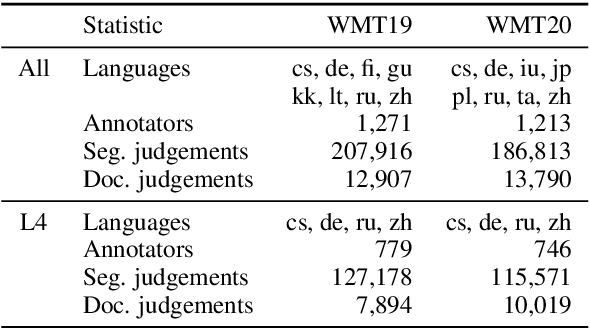
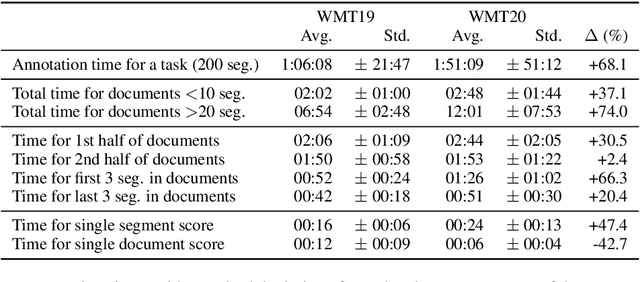

Recent studies emphasize the need of document context in human evaluation of machine translations, but little research has been done on the impact of user interfaces on annotator productivity and the reliability of assessments. In this work, we compare human assessment data from the last two WMT evaluation campaigns collected via two different methods for document-level evaluation. Our analysis shows that a document-centric approach to evaluation where the annotator is presented with the entire document context on a screen leads to higher quality segment and document level assessments. It improves the correlation between segment and document scores and increases inter-annotator agreement for document scores but is considerably more time consuming for annotators.
THEaiTRE 1.0: Interactive generation of theatre play scripts
Feb 17, 2021We present the first version of a system for interactive generation of theatre play scripts. The system is based on a vanilla GPT-2 model with several adjustments, targeting specific issues we encountered in practice. We also list other issues we encountered but plan to only solve in a future version of the system. The presented system was used to generate a theatre play script planned for premiere in February 2021.
CUNI Systems for the Unsupervised and Very Low Resource Translation Task in WMT20
Oct 22, 2020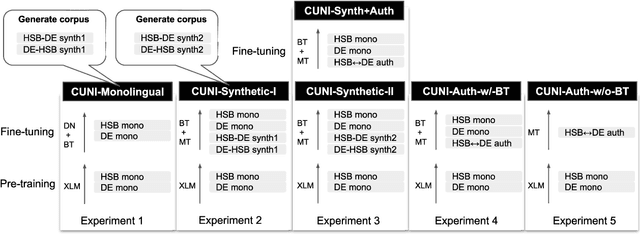
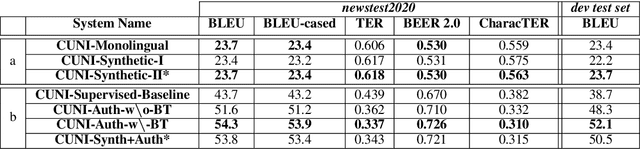
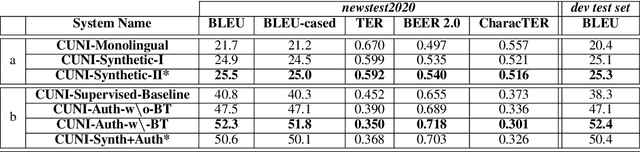
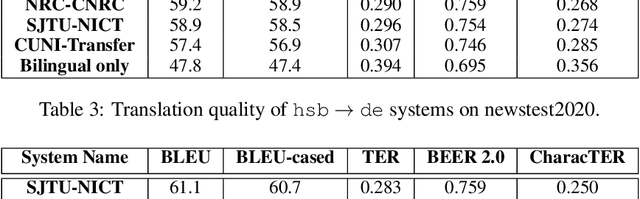
This paper presents a description of CUNI systems submitted to the WMT20 task on unsupervised and very low-resource supervised machine translation between German and Upper Sorbian. We experimented with training on synthetic data and pre-training on a related language pair. In the fully unsupervised scenario, we achieved 25.5 and 23.7 BLEU translating from and into Upper Sorbian, respectively. Our low-resource systems relied on transfer learning from German-Czech parallel data and achieved 57.4 BLEU and 56.1 BLEU, which is an improvement of 10 BLEU points over the baseline trained only on the available small German-Upper Sorbian parallel corpus.
Gender Coreference and Bias Evaluation at WMT 2020
Oct 12, 2020
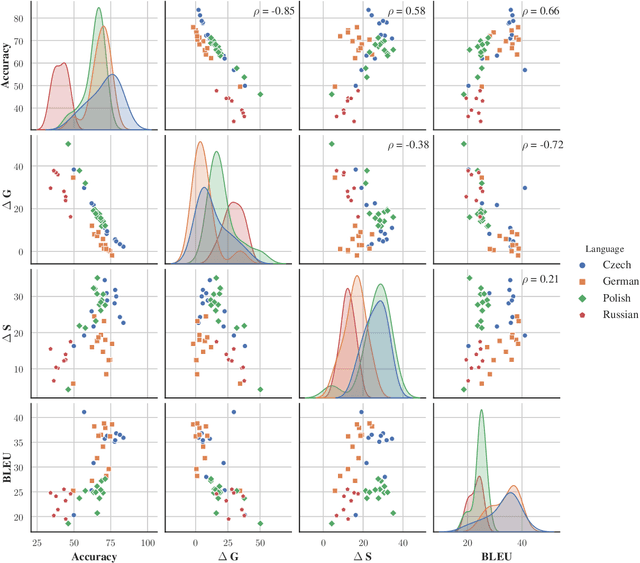

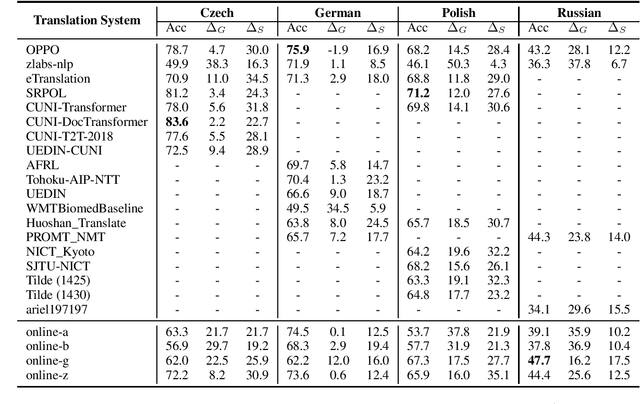
Gender bias in machine translation can manifest when choosing gender inflections based on spurious gender correlations. For example, always translating doctors as men and nurses as women. This can be particularly harmful as models become more popular and deployed within commercial systems. Our work presents the largest evidence for the phenomenon in more than 19 systems submitted to the WMT over four diverse target languages: Czech, German, Polish, and Russian. To achieve this, we use WinoMT, a recent automatic test suite which examines gender coreference and bias when translating from English to languages with grammatical gender. We extend WinoMT to handle two new languages tested in WMT: Polish and Czech. We find that all systems consistently use spurious correlations in the data rather than meaningful contextual information.