 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Doesn't Kill You Makes You Robust: Adversarial Training against Poisons and Backdoors
Feb 26, 2021Data poisoning is a threat model in which a malicious actor tampers with training data to manipulate outcomes at inference time. A variety of defenses against this threat model have been proposed, but each suffers from at least one of the following flaws: they are easily overcome by adaptive attacks, they severely reduce testing performance, or they cannot generalize to diverse data poisoning threat models. Adversarial training, and its variants, is currently considered the only empirically strong defense against (inference-time) adversarial attacks. In this work, we extend the adversarial training framework to instead defend against (training-time) poisoning and backdoor attacks. Our method desensitizes networks to the effects of poisoning by creating poisons during training and injecting them into training batches. We show that this defense withstands adaptive attacks, generalizes to diverse threat models, and incurs a better performance trade-off than previous defenses.
Improving Robustness of Learning-based Autonomous Steering Using Adversarial Images
Feb 26, 2021
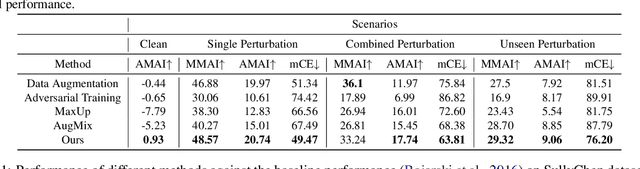
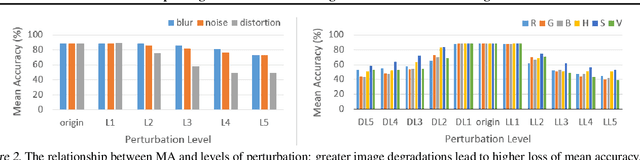
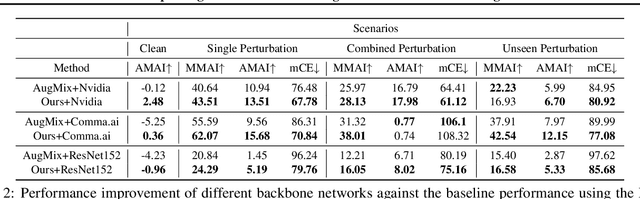
For safety of autonomous driving, vehicles need to be able to drive under various lighting, weather, and visibility conditions in different environments. These external and environmental factors, along with internal factors associated with sensors, can pose significant challenges to perceptual data processing, hence affecting the decision-making and control of the vehicle. In this work, we address this critical issue by introducing a framework for analyzing robustness of the learning algorithm w.r.t varying quality in the image input for autonomous driving. Using the results of sensitivity analysis, we further propose an algorithm to improve the overall performance of the task of "learning to steer". The results show that our approach is able to enhance the learning outcomes up to 48%. A comparative study drawn between our approach and other related techniques, such as data augmentation and adversarial training, confirms the effectiveness of our algorithm as a way to improve the robustness and generalization of neural network training for autonomous driving.
Center Smoothing for Certifiably Robust Vector-Valued Functions
Feb 19, 2021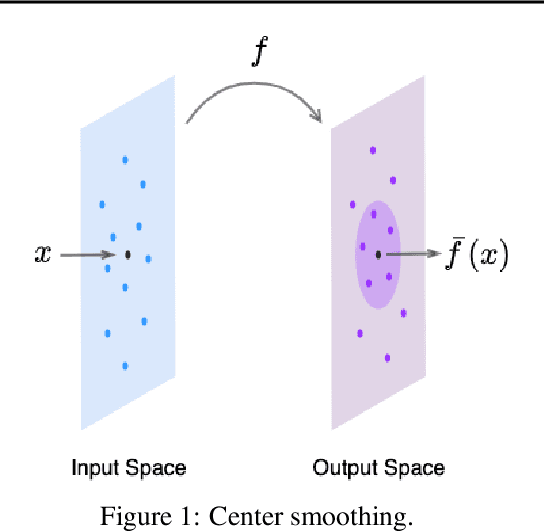
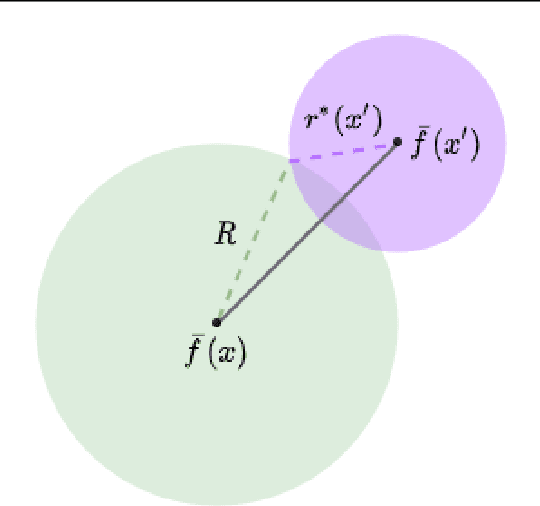
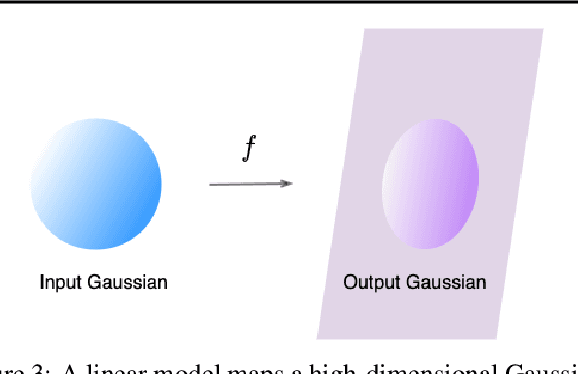

Randomized smoothing has been successfully applied in high-dimensional image classification tasks to obtain models that are provably robust against input perturbations of bounded size. We extend this technique to produce certifiable robustness for vector-valued functions, i.e., bound the change in output caused by a small change in input. These functions are used in many areas of machine learning, such as image reconstruction, dimensionality reduction, super-resolution, etc., but due to the enormous dimensionality of the output space in these problems, generating meaningful robustness guarantees is difficult. We design a smoothing procedure that can leverage the local, potentially low-dimensional, behaviour of the function around an input to obtain probabilistic robustness certificates. We demonstrate the effectiveness of our method on multiple learning tasks involving vector-valued functions with a wide range of input and output dimensionalities.
GradInit: Learning to Initialize Neural Networks for Stable and Efficient Training
Feb 16, 2021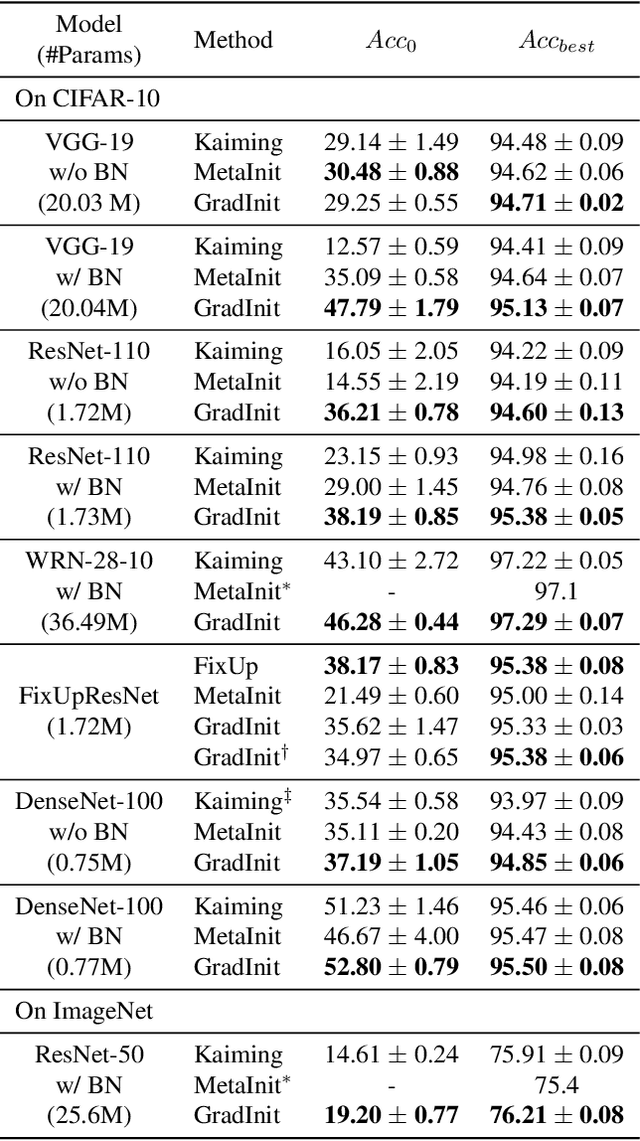
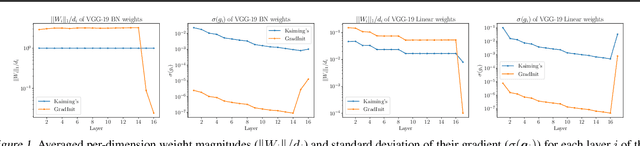
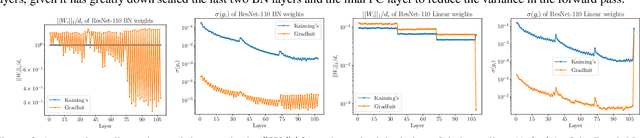
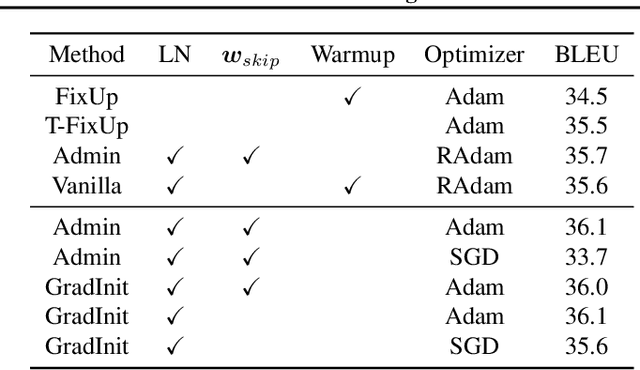
Changes in neural architectures have fostered significant breakthroughs in language modeling and computer vision. Unfortunately, novel architectures often require re-thinking the choice of hyperparameters (e.g., learning rate, warmup schedule, and momentum coefficients) to maintain stability of the optimizer. This optimizer instability is often the result of poor parameter initialization, and can be avoided by architecture-specific initialization schemes. In this paper, we present GradInit, an automated and architecture agnostic method for initializing neural networks. GradInit is based on a simple heuristic; the variance of each network layer is adjusted so that a single step of SGD or Adam results in the smallest possible loss value. This adjustment is done by introducing a scalar multiplier variable in front of each parameter block, and then optimizing these variables using a simple numerical scheme. GradInit accelerates the convergence and test performance of many convolutional architectures, both with or without skip connections, and even without normalization layers. It also enables training the original Post-LN Transformer for machine translation without learning rate warmup under a wide range of learning rates and momentum coefficients. Code is available at https://github.com/zhuchen03/gradinit.
Technical Challenges for Training Fair Neural Networks
Feb 12, 2021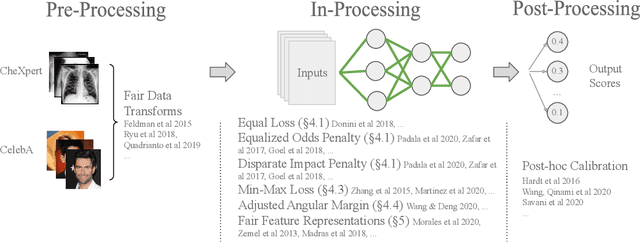
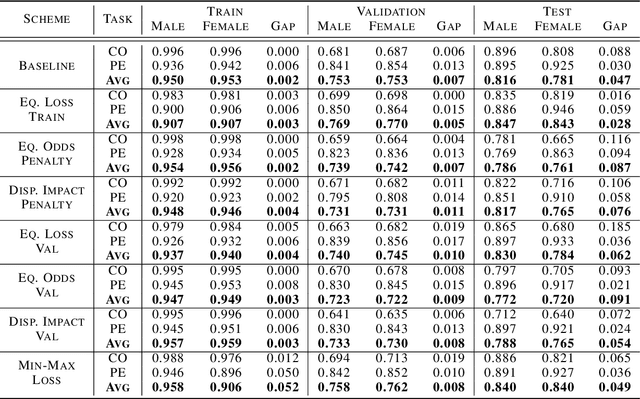

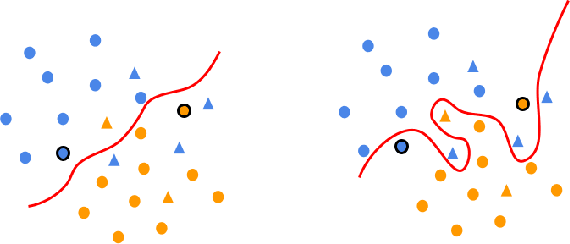
As machine learning algorithms have been widely deployed across applications, many concerns have been raised over the fairness of their predictions, especially in high stakes settings (such as facial recognition and medical imaging). To respond to these concerns, the community has proposed and formalized various notions of fairness as well as methods for rectifying unfair behavior. While fairness constraints have been studied extensively for classical models, the effectiveness of methods for imposing fairness on deep neural networks is unclear. In this paper, we observe that these large models overfit to fairness objectives, and produce a range of unintended and undesirable consequences. We conduct our experiments on both facial recognition and automated medical diagnosis datasets using state-of-the-art architectures.
LowKey: Leveraging Adversarial Attacks to Protect Social Media Users from Facial Recognition
Jan 25, 2021

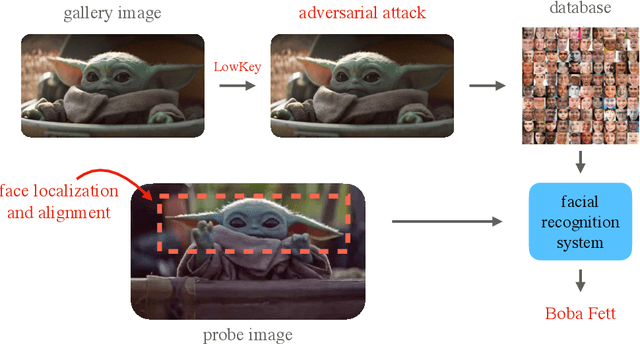
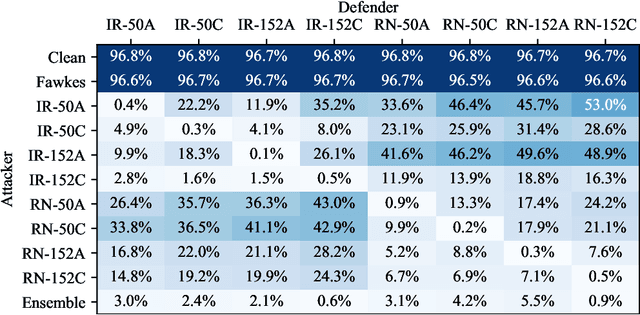
Facial recognition systems are increasingly deployed by private corporations, government agencies, and contractors for consumer services and mass surveillance programs alike. These systems are typically built by scraping social media profiles for user images. Adversarial perturbations have been proposed for bypassing facial recognition systems. However, existing methods fail on full-scale systems and commercial APIs. We develop our own adversarial filter that accounts for the entire image processing pipeline and is demonstrably effective against industrial-grade pipelines that include face detection and large scale databases. Additionally, we release an easy-to-use webtool that significantly degrades the accuracy of Amazon Rekognition and the Microsoft Azure Face Recognition API, reducing the accuracy of each to below 1%.
Dataset Security for Machine Learning: Data Poisoning, Backdoor Attacks, and Defenses
Dec 30, 2020
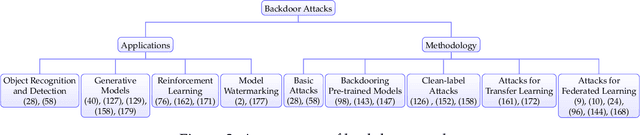


As machine learning systems grow in scale, so do their training data requirements, forcing practitioners to automate and outsource the curation of training data in order to achieve state-of-the-art performance. The absence of trustworthy human supervision over the data collection process exposes organizations to security vulnerabilities; training data can be manipulated to control and degrade the downstream behaviors of learned models. The goal of this work is to systematically categorize and discuss a wide range of dataset vulnerabilities and exploits, approaches for defending against these threats, and an array of open problems in this space. In addition to describing various poisoning and backdoor threat models and the relationships among them, we develop their unified taxonomy.
Analyzing the Machine Learning Conference Review Process
Nov 26, 2020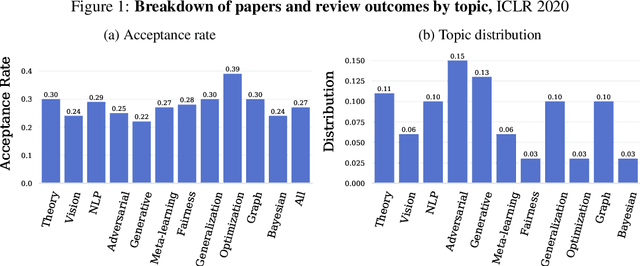
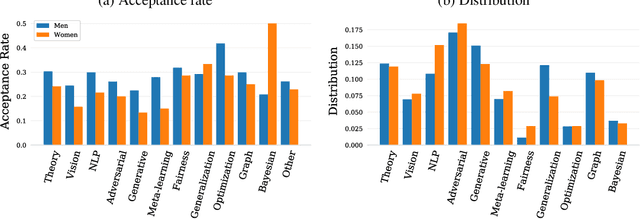
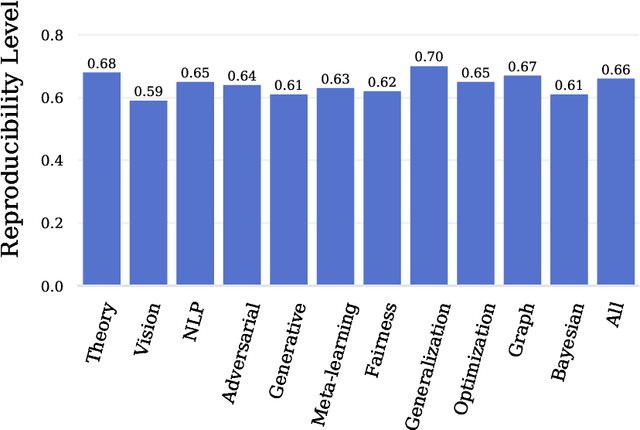
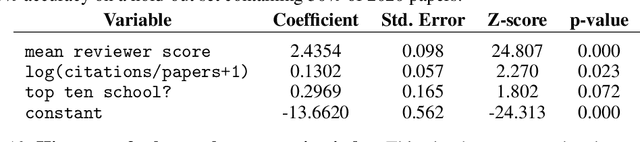
Mainstream machine learning conferences have seen a dramatic increase in the number of participants, along with a growing range of perspectives, in recent years. Members of the machine learning community are likely to overhear allegations ranging from randomness of acceptance decisions to institutional bias. In this work, we critically analyze the review process through a comprehensive study of papers submitted to ICLR between 2017 and 2020. We quantify reproducibility/randomness in review scores and acceptance decisions, and examine whether scores correlate with paper impact. Our findings suggest strong institutional bias in accept/reject decisions, even after controlling for paper quality. Furthermore, we find evidence for a gender gap, with female authors receiving lower scores, lower acceptance rates, and fewer citations per paper than their male counterparts. We conclude our work with recommendations for future conference organizers.
Strong Data Augmentation Sanitizes Poisoning and Backdoor Attacks Without an Accuracy Tradeoff
Nov 18, 2020


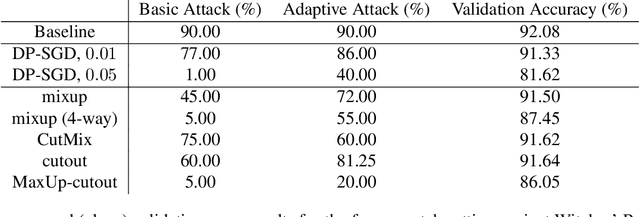
Data poisoning and backdoor attacks manipulate victim models by maliciously modifying training data. In light of this growing threat, a recent survey of industry professionals revealed heightened fear in the private sector regarding data poisoning. Many previous defenses against poisoning either fail in the face of increasingly strong attacks, or they significantly degrade performance. However, we find that strong data augmentations, such as mixup and CutMix, can significantly diminish the threat of poisoning and backdoor attacks without trading off performance. We further verify the effectiveness of this simple defense against adaptive poisoning methods, and we compare to baselines including the popular differentially private SGD (DP-SGD) defense. In the context of backdoors, CutMix greatly mitigates the attack while simultaneously increasing validation accuracy by 9%.
An Open Review of OpenReview: A Critical Analysis of the Machine Learning Conference Review Process
Oct 26, 2020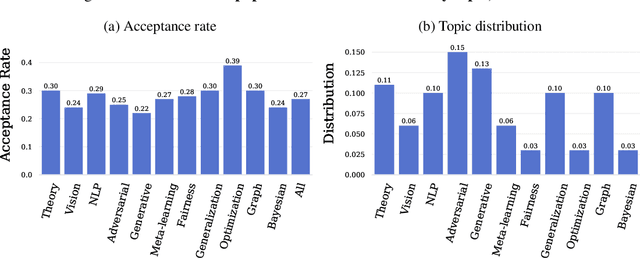

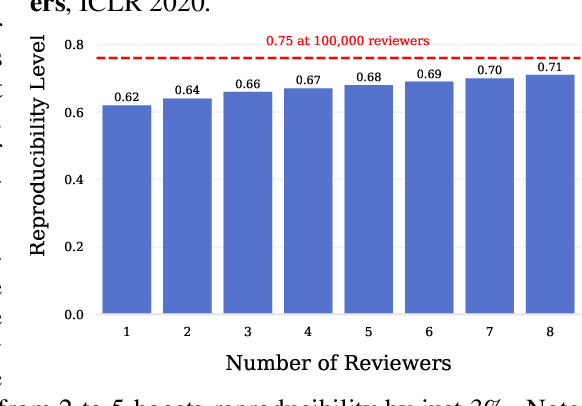

Mainstream machine learning conferences have seen a dramatic increase in the number of participants, along with a growing range of perspectives, in recent years. Members of the machine learning community are likely to overhear allegations ranging from randomness of acceptance decisions to institutional bias. In this work, we critically analyze the review process through a comprehensive study of papers submitted to ICLR between 2017 and 2020. We quantify reproducibility/randomness in review scores and acceptance decisions, and examine whether scores correlate with paper impact. Our findings suggest strong institutional bias in accept/reject decisions, even after controlling for paper quality. Furthermore, we find evidence for a gender gap, with female authors receiving lower scores, lower acceptance rates, and fewer citations per paper than their male counterparts. We conclude our work with recommendations for future conference organizers.