 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
A Family of LLMs Liberated from Static Vocabularies
Mar 16, 2026Tokenization is a central component of natural language processing in current large language models (LLMs), enabling models to convert raw text into processable units. Although learned tokenizers are widely adopted, they exhibit notable limitations, including their large, fixed vocabulary sizes and poor adaptability to new domains or languages. We present a family of models with up to 70 billion parameters based on the hierarchical autoregressive transformer (HAT) architecture. In HAT, an encoder transformer aggregates bytes into word embeddings and then feeds them to the backbone, a classical autoregressive transformer. The outputs of the backbone are then cross-attended by the decoder and converted back into bytes. We show that we can reuse available pre-trained models by converting the Llama 3.1 8B and 70B models into the HAT architecture: Llama-3.1-8B-TFree-HAT and Llama-3.1-70B-TFree-HAT are byte-level models whose encoder and decoder are trained from scratch, but where we adapt the pre-trained Llama backbone, i.e., the transformer blocks with the embedding matrix and head removed, to handle word embeddings instead of the original tokens. We also provide a 7B HAT model, Llama-TFree-HAT-Pretrained, trained entirely from scratch on nearly 4 trillion words. The HAT architecture improves text compression by reducing the number of required sequence positions and enhances robustness to intra-word variations, e.g., spelling differences. Through pre-training, as well as subsequent supervised fine-tuning and direct preference optimization in English and German, we show strong proficiency in both languages, improving on the original Llama 3.1 in most benchmarks. We release our models (including 200 pre-training checkpoints) on Hugging Face.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
The Impact of Inference Acceleration Strategies on Bias of LLMs
Oct 29, 2024



Last few years have seen unprecedented advances in capabilities of Large Language Models (LLMs). These advancements promise to deeply benefit a vast array of application domains. However, due to their immense size, performing inference with LLMs is both costly and slow. Consequently, a plethora of recent work has proposed strategies to enhance inference efficiency, e.g., quantization, pruning, and caching. These acceleration strategies reduce the inference cost and latency, often by several factors, while maintaining much of the predictive performance measured via common benchmarks. In this work, we explore another critical aspect of LLM performance: demographic bias in model generations due to inference acceleration optimizations. Using a wide range of metrics, we probe bias in model outputs from a number of angles. Analysis of outputs before and after inference acceleration shows significant change in bias. Worryingly, these bias effects are complex and unpredictable. A combination of an acceleration strategy and bias type may show little bias change in one model but may lead to a large effect in another. Our results highlight a need for in-depth and case-by-case evaluation of model bias after it has been modified to accelerate inference.
Understanding Memorisation in LLMs: Dynamics, Influencing Factors, and Implications
Jul 27, 2024

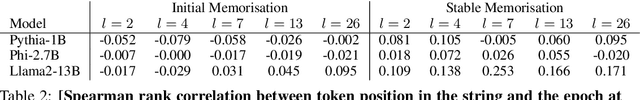

Understanding whether and to what extent large language models (LLMs) have memorised training data has important implications for the reliability of their output and the privacy of their training data. In order to cleanly measure and disentangle memorisation from other phenomena (e.g. in-context learning), we create an experimental framework that is based on repeatedly exposing LLMs to random strings. Our framework allows us to better understand the dynamics, i.e., the behaviour of the model, when repeatedly exposing it to random strings. Using our framework, we make several striking observations: (a) we find consistent phases of the dynamics across families of models (Pythia, Phi and Llama2), (b) we identify factors that make some strings easier to memorise than others, and (c) we identify the role of local prefixes and global context in memorisation. We also show that sequential exposition to different random strings has a significant effect on memorisation. Our results, often surprising, have significant downstream implications in the study and usage of LLMs.
Lawma: The Power of Specialization for Legal Tasks
Jul 23, 2024



Annotation and classification of legal text are central components of empirical legal research. Traditionally, these tasks are often delegated to trained research assistants. Motivated by the advances in language modeling, empirical legal scholars are increasingly turning to prompting commercial models, hoping that it will alleviate the significant cost of human annotation. Despite growing use, our understanding of how to best utilize large language models for legal tasks remains limited. We conduct a comprehensive study of 260 legal text classification tasks, nearly all new to the machine learning community. Starting from GPT-4 as a baseline, we show that it has non-trivial but highly varied zero-shot accuracy, often exhibiting performance that may be insufficient for legal work. We then demonstrate that a lightly fine-tuned Llama 3 model vastly outperforms GPT-4 on almost all tasks, typically by double-digit percentage points. We find that larger models respond better to fine-tuning than smaller models. A few tens to hundreds of examples suffice to achieve high classification accuracy. Notably, we can fine-tune a single model on all 260 tasks simultaneously at a small loss in accuracy relative to having a separate model for each task. Our work points to a viable alternative to the predominant practice of prompting commercial models. For concrete legal tasks with some available labeled data, researchers are better off using a fine-tuned open-source model.
Understanding the Role of Invariance in Transfer Learning
Jul 05, 2024Transfer learning is a powerful technique for knowledge-sharing between different tasks. Recent work has found that the representations of models with certain invariances, such as to adversarial input perturbations, achieve higher performance on downstream tasks. These findings suggest that invariance may be an important property in the context of transfer learning. However, the relationship of invariance with transfer performance is not fully understood yet and a number of questions remain. For instance, how important is invariance compared to other factors of the pretraining task? How transferable is learned invariance? In this work, we systematically investigate the importance of representational invariance for transfer learning, as well as how it interacts with other parameters during pretraining. To do so, we introduce a family of synthetic datasets that allow us to precisely control factors of variation both in training and test data. Using these datasets, we a) show that for learning representations with high transfer performance, invariance to the right transformations is as, or often more, important than most other factors such as the number of training samples, the model architecture and the identity of the pretraining classes, b) show conditions under which invariance can harm the ability to transfer representations and c) explore how transferable invariance is between tasks. The code is available at \url{https://github.com/tillspeicher/representation-invariance-transfer}.
Towards Reliable Latent Knowledge Estimation in LLMs: In-Context Learning vs. Prompting Based Factual Knowledge Extraction
Apr 19, 2024



We propose an approach for estimating the latent knowledge embedded inside large language models (LLMs). We leverage the in-context learning (ICL) abilities of LLMs to estimate the extent to which an LLM knows the facts stored in a knowledge base. Our knowledge estimator avoids reliability concerns with previous prompting-based methods, is both conceptually simpler and easier to apply, and we demonstrate that it can surface more of the latent knowledge embedded in LLMs. We also investigate how different design choices affect the performance of ICL-based knowledge estimation. Using the proposed estimator, we perform a large-scale evaluation of the factual knowledge of a variety of open source LLMs, like OPT, Pythia, Llama(2), Mistral, Gemma, etc. over a large set of relations and facts from the Wikidata knowledge base. We observe differences in the factual knowledge between different model families and models of different sizes, that some relations are consistently better known than others but that models differ in the precise facts they know, and differences in the knowledge of base models and their finetuned counterparts.
What Happens During Finetuning of Vision Transformers: An Invariance Based Investigation
Jul 12, 2023



The pretrain-finetune paradigm usually improves downstream performance over training a model from scratch on the same task, becoming commonplace across many areas of machine learning. While pretraining is empirically observed to be beneficial for a range of tasks, there is not a clear understanding yet of the reasons for this effect. In this work, we examine the relationship between pretrained vision transformers and the corresponding finetuned versions on several benchmark datasets and tasks. We present new metrics that specifically investigate the degree to which invariances learned by a pretrained model are retained or forgotten during finetuning. Using these metrics, we present a suite of empirical findings, including that pretraining induces transferable invariances in shallow layers and that invariances from deeper pretrained layers are compressed towards shallower layers during finetuning. Together, these findings contribute to understanding some of the reasons for the successes of pretrained models and the changes that a pretrained model undergoes when finetuned on a downstream task.
Diffused Redundancy in Pre-trained Representations
May 31, 2023



Representations learned by pre-training a neural network on a large dataset are increasingly used successfully to perform a variety of downstream tasks. In this work, we take a closer look at how features are encoded in such pre-trained representations. We find that learned representations in a given layer exhibit a degree of diffuse redundancy, i.e., any randomly chosen subset of neurons in the layer that is larger than a threshold size shares a large degree of similarity with the full layer and is able to perform similarly as the whole layer on a variety of downstream tasks. For example, a linear probe trained on $20\%$ of randomly picked neurons from a ResNet50 pre-trained on ImageNet1k achieves an accuracy within $5\%$ of a linear probe trained on the full layer of neurons for downstream CIFAR10 classification. We conduct experiments on different neural architectures (including CNNs and Transformers) pre-trained on both ImageNet1k and ImageNet21k and evaluate a variety of downstream tasks taken from the VTAB benchmark. We find that the loss & dataset used during pre-training largely govern the degree of diffuse redundancy and the "critical mass" of neurons needed often depends on the downstream task, suggesting that there is a task-inherent redundancy-performance Pareto frontier. Our findings shed light on the nature of representations learned by pre-trained deep neural networks and suggest that entire layers might not be necessary to perform many downstream tasks. We investigate the potential for exploiting this redundancy to achieve efficient generalization for downstream tasks and also draw caution to certain possible unintended consequences.