 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAG-MM: Multi-modal Multi-turn Comprehensive RAG Benchmark
Oct 30, 2025



Wearable devices such as smart glasses are transforming the way people interact with their surroundings, enabling users to seek information regarding entities in their view. Multi-Modal Retrieval-Augmented Generation (MM-RAG) plays a key role in supporting such questions, yet there is still no comprehensive benchmark for this task, especially regarding wearables scenarios. To fill this gap, we present CRAG-MM -- a Comprehensive RAG benchmark for Multi-modal Multi-turn conversations. CRAG-MM contains a diverse set of 6.5K (image, question, answer) triplets and 2K visual-based multi-turn conversations across 13 domains, including 6.2K egocentric images designed to mimic captures from wearable devices. We carefully constructed the questions to reflect real-world scenarios and challenges, including five types of image-quality issues, six question types, varying entity popularity, differing information dynamism, and different conversation turns. We design three tasks: single-source augmentation, multi-source augmentation, and multi-turn conversations -- each paired with an associated retrieval corpus and APIs for both image-KG retrieval and webpage retrieval. Our evaluation shows that straightforward RAG approaches achieve only 32% and 43% truthfulness on CRAG-MM single- and multi-turn QA, respectively, whereas state-of-the-art industry solutions have similar quality (32%/45%), underscoring ample room for improvement. The benchmark has hosted KDD Cup 2025, attracting about 1K participants and 5K submissions, with winning solutions improving baseline performance by 28%, highlighting its early impact on advancing the field.
Analyzing the Machine Learning Conference Review Process
Nov 26, 2020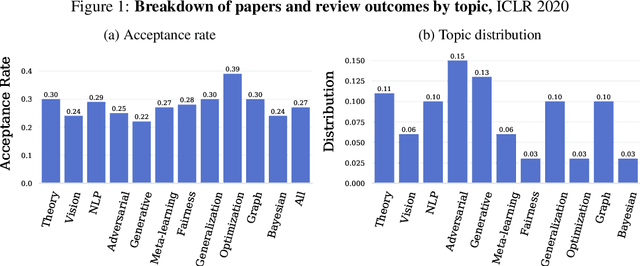
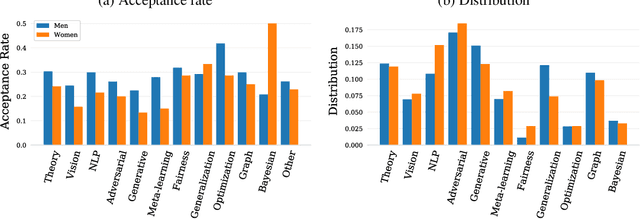
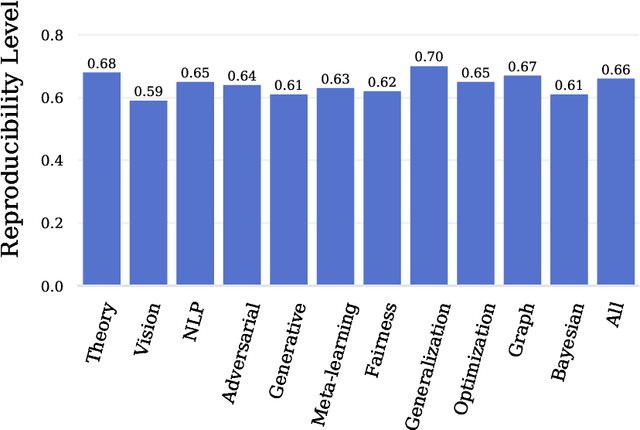
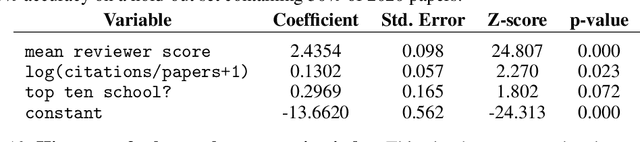
Mainstream machine learning conferences have seen a dramatic increase in the number of participants, along with a growing range of perspectives, in recent years. Members of the machine learning community are likely to overhear allegations ranging from randomness of acceptance decisions to institutional bias. In this work, we critically analyze the review process through a comprehensive study of papers submitted to ICLR between 2017 and 2020. We quantify reproducibility/randomness in review scores and acceptance decisions, and examine whether scores correlate with paper impact. Our findings suggest strong institutional bias in accept/reject decisions, even after controlling for paper quality. Furthermore, we find evidence for a gender gap, with female authors receiving lower scores, lower acceptance rates, and fewer citations per paper than their male counterparts. We conclude our work with recommendations for future conference organizers.
An Open Review of OpenReview: A Critical Analysis of the Machine Learning Conference Review Process
Oct 26, 2020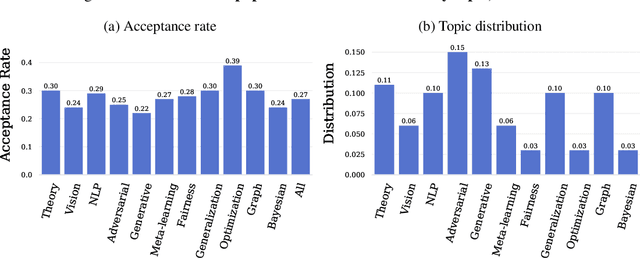

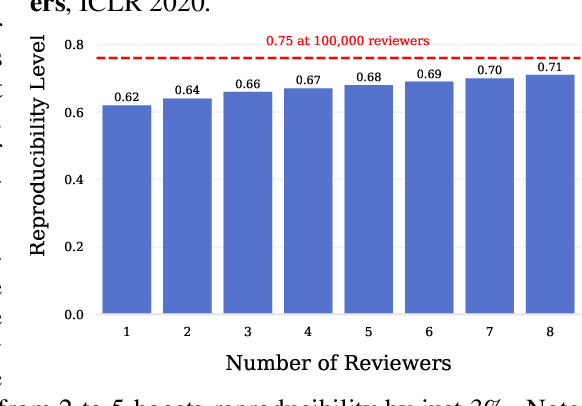

Mainstream machine learning conferences have seen a dramatic increase in the number of participants, along with a growing range of perspectives, in recent years. Members of the machine learning community are likely to overhear allegations ranging from randomness of acceptance decisions to institutional bias. In this work, we critically analyze the review process through a comprehensive study of papers submitted to ICLR between 2017 and 2020. We quantify reproducibility/randomness in review scores and acceptance decisions, and examine whether scores correlate with paper impact. Our findings suggest strong institutional bias in accept/reject decisions, even after controlling for paper quality. Furthermore, we find evidence for a gender gap, with female authors receiving lower scores, lower acceptance rates, and fewer citations per paper than their male counterparts. We conclude our work with recommendations for future conference organizers.