 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertifying Model Accuracy under Distribution Shifts
Jan 28, 2022
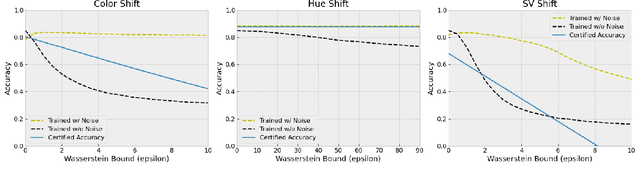

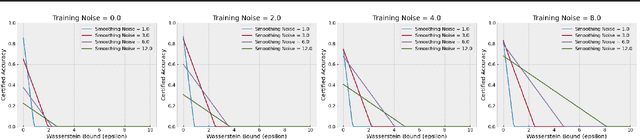
Certified robustness in machine learning has primarily focused on adversarial perturbations of the input with a fixed attack budget for each point in the data distribution. In this work, we present provable robustness guarantees on the accuracy of a model under bounded Wasserstein shifts of the data distribution. We show that a simple procedure that randomizes the input of the model within a transformation space is provably robust to distributional shifts under the transformation. Our framework allows the datum-specific perturbation size to vary across different points in the input distribution and is general enough to include fixed-sized perturbations as well. Our certificates produce guaranteed lower bounds on the performance of the model for any (natural or adversarial) shift of the input distribution within a Wasserstein ball around the original distribution. We apply our technique to: (i) certify robustness against natural (non-adversarial) transformations of images such as color shifts, hue shifts and changes in brightness and saturation, (ii) certify robustness against adversarial shifts of the input distribution, and (iii) show provable lower bounds (hardness results) on the performance of models trained on so-called "unlearnable" datasets that have been poisoned to interfere with model training.
Are Commercial Face Detection Models as Biased as Academic Models?
Jan 25, 2022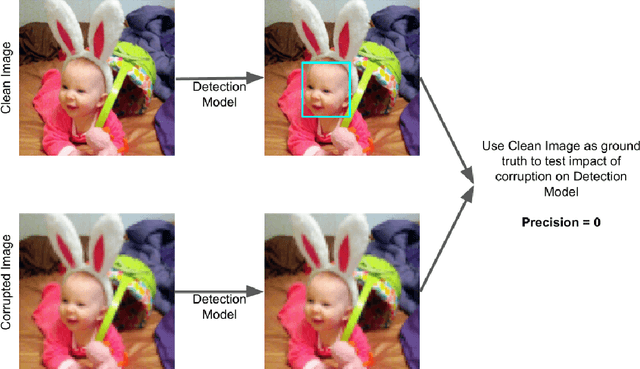
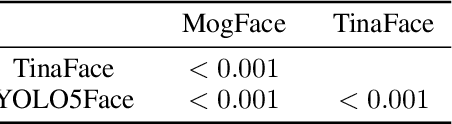
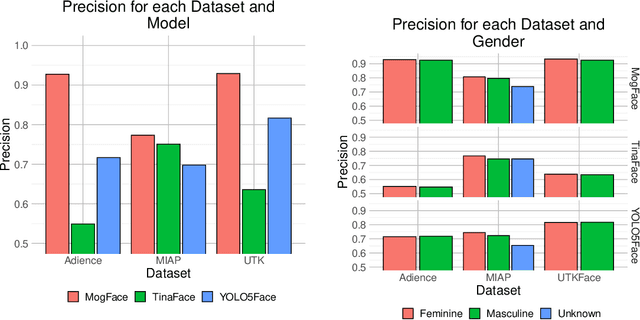
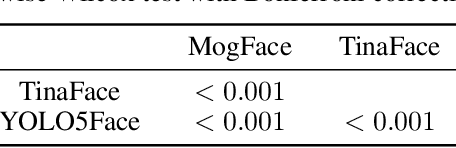
As facial recognition systems are deployed more widely, scholars and activists have studied their biases and harms. Audits are commonly used to accomplish this and compare the algorithmic facial recognition systems' performance against datasets with various metadata labels about the subjects of the images. Seminal works have found discrepancies in performance by gender expression, age, perceived race, skin type, etc. These studies and audits often examine algorithms which fall into two categories: academic models or commercial models. We present a detailed comparison between academic and commercial face detection systems, specifically examining robustness to noise. We find that state-of-the-art academic face detection models exhibit demographic disparities in their noise robustness, specifically by having statistically significant decreased performance on older individuals and those who present their gender in a masculine manner. When we compare the size of these disparities to that of commercial models, we conclude that commercial models - in contrast to their relatively larger development budget and industry-level fairness commitments - are always as biased or more biased than an academic model.
Execute Order 66: Targeted Data Poisoning for Reinforcement Learning
Jan 03, 2022
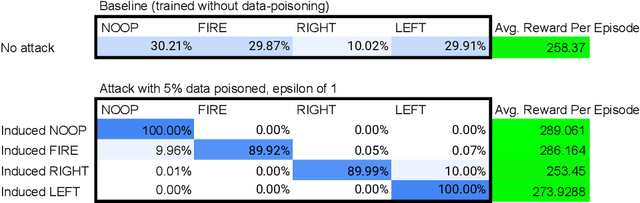

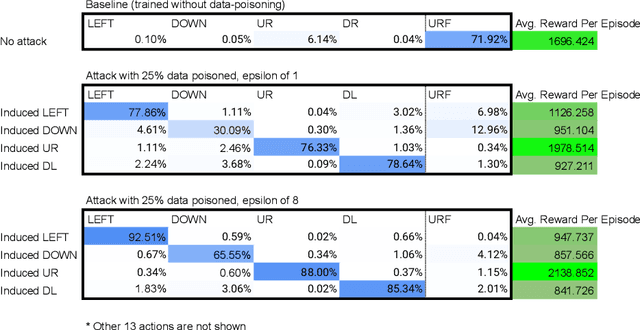
Data poisoning for reinforcement learning has historically focused on general performance degradation, and targeted attacks have been successful via perturbations that involve control of the victim's policy and rewards. We introduce an insidious poisoning attack for reinforcement learning which causes agent misbehavior only at specific target states - all while minimally modifying a small fraction of training observations without assuming any control over policy or reward. We accomplish this by adapting a recent technique, gradient alignment, to reinforcement learning. We test our method and demonstrate success in two Atari games of varying difficulty.
Hybrid Jammer Mitigation for All-Digital mmWave Massive MU-MIMO
Nov 25, 2021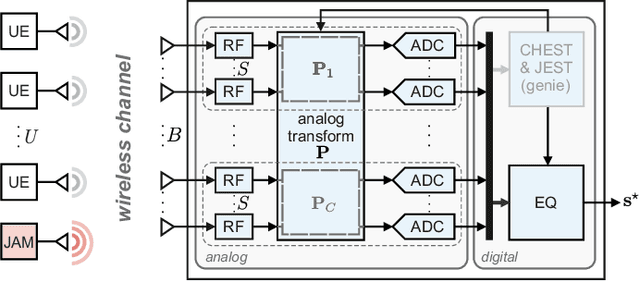
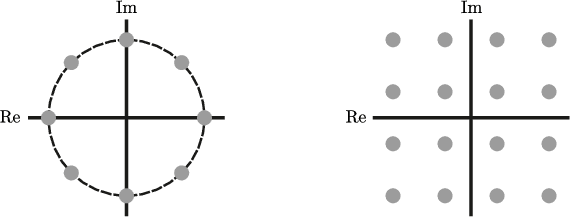
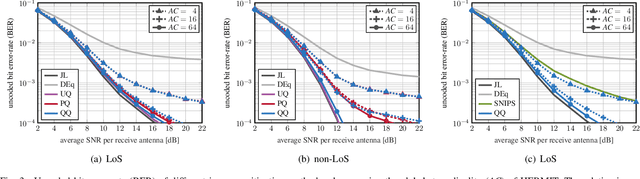
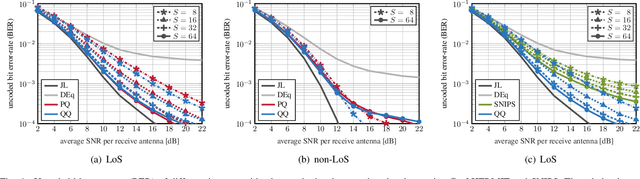
Low-resolution analog-to-digital converters (ADCs) simplify the design of millimeter-wave (mmWave) massive multi-user multiple-input multiple-output (MU-MIMO) basestations, but increase vulnerability to jamming attacks. As a remedy, we propose HERMIT (short for Hybrid jammER MITigation), a method that combines a hardware-friendly adaptive analog transform with a corresponding digital equalizer: The analog transform removes most of the jammer's energy prior to data conversion; the digital equalizer suppresses jammer residues while detecting the legitimate transmit data. We provide theoretical results that establish the optimal analog transform as a function of the user equipments' and the jammer's channels. Using simulations with mmWave channel models, we demonstrate the superiority of HERMIT compared both to purely digital jammer mitigation as well as to a recent hybrid method that mitigates jammer interference with a nonadaptive analog transform.
Active Learning at the ImageNet Scale
Nov 25, 2021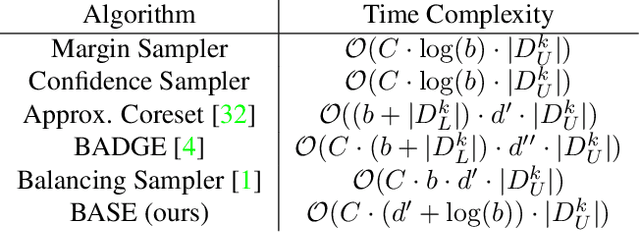
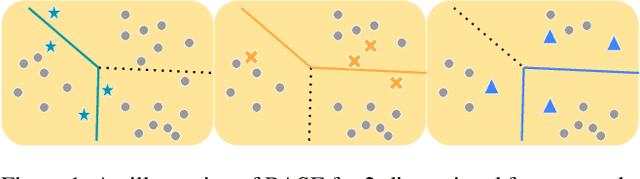

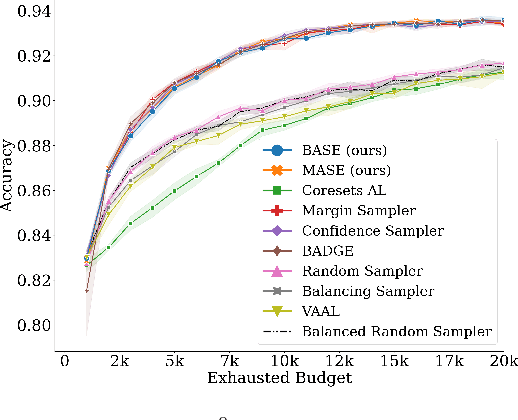
Active learning (AL) algorithms aim to identify an optimal subset of data for annotation, such that deep neural networks (DNN) can achieve better performance when trained on this labeled subset. AL is especially impactful in industrial scale settings where data labeling costs are high and practitioners use every tool at their disposal to improve model performance. The recent success of self-supervised pretraining (SSP) highlights the importance of harnessing abundant unlabeled data to boost model performance. By combining AL with SSP, we can make use of unlabeled data while simultaneously labeling and training on particularly informative samples. In this work, we study a combination of AL and SSP on ImageNet. We find that performance on small toy datasets -- the typical benchmark setting in the literature -- is not representative of performance on ImageNet due to the class imbalanced samples selected by an active learner. Among the existing baselines we test, popular AL algorithms across a variety of small and large scale settings fail to outperform random sampling. To remedy the class-imbalance problem, we propose Balanced Selection (BASE), a simple, scalable AL algorithm that outperforms random sampling consistently by selecting more balanced samples for annotation than existing methods. Our code is available at: https://github.com/zeyademam/active_learning .
Joint Channel Estimation and Data Detection in Cell-Free Massive MU-MIMO Systems
Oct 29, 2021
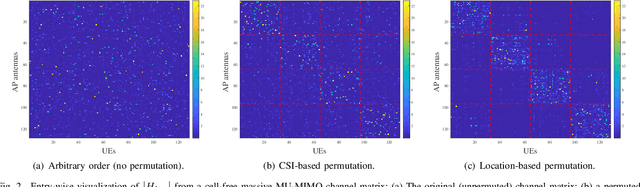
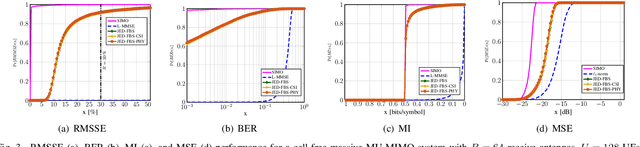
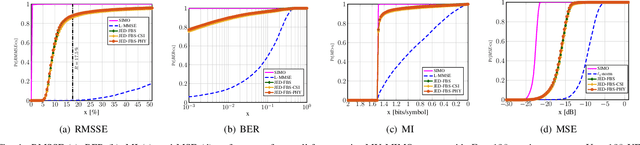
We propose a joint channel estimation and data detection (JED) algorithm for densely-populated cell-free massive multiuser (MU) multiple-input multiple-output (MIMO) systems, which reduces the channel training overhead caused by the presence of hundreds of simultaneously transmitting user equipments (UEs). Our algorithm iteratively solves a relaxed version of a maximum a-posteriori JED problem and simultaneously exploits the sparsity of cell-free massive MU-MIMO channels as well as the boundedness of QAM constellations. In order to improve the performance and convergence of the algorithm, we propose methods that permute the access point and UE indices to form so-called virtual cells, which leads to better initial solutions. We assess the performance of our algorithm in terms of root-mean-squared-symbol error, bit error rate, and mutual information, and we demonstrate that JED significantly reduces the pilot overhead compared to orthogonal training, which enables reliable communication with short packets to a large number of UEs.
VQ-GNN: A Universal Framework to Scale up Graph Neural Networks using Vector Quantization
Oct 27, 2021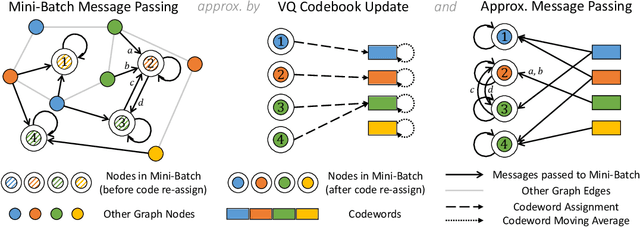
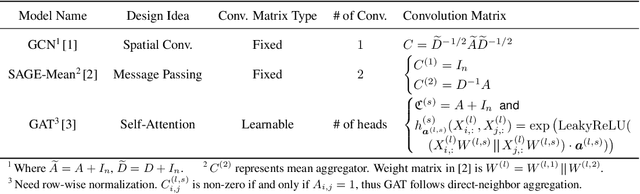
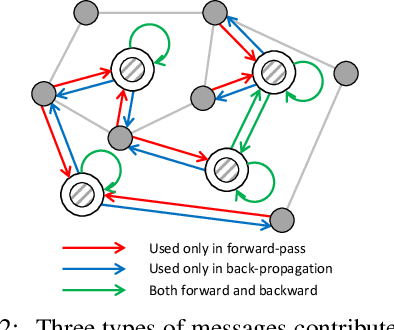

Most state-of-the-art Graph Neural Networks (GNNs) can be defined as a form of graph convolution which can be realized by message passing between direct neighbors or beyond. To scale such GNNs to large graphs, various neighbor-, layer-, or subgraph-sampling techniques are proposed to alleviate the "neighbor explosion" problem by considering only a small subset of messages passed to the nodes in a mini-batch. However, sampling-based methods are difficult to apply to GNNs that utilize many-hops-away or global context each layer, show unstable performance for different tasks and datasets, and do not speed up model inference. We propose a principled and fundamentally different approach, VQ-GNN, a universal framework to scale up any convolution-based GNNs using Vector Quantization (VQ) without compromising the performance. In contrast to sampling-based techniques, our approach can effectively preserve all the messages passed to a mini-batch of nodes by learning and updating a small number of quantized reference vectors of global node representations, using VQ within each GNN layer. Our framework avoids the "neighbor explosion" problem of GNNs using quantized representations combined with a low-rank version of the graph convolution matrix. We show that such a compact low-rank version of the gigantic convolution matrix is sufficient both theoretically and experimentally. In company with VQ, we design a novel approximated message passing algorithm and a nontrivial back-propagation rule for our framework. Experiments on various types of GNN backbones demonstrate the scalability and competitive performance of our framework on large-graph node classification and link prediction benchmarks.
A Frequency Perspective of Adversarial Robustness
Oct 26, 2021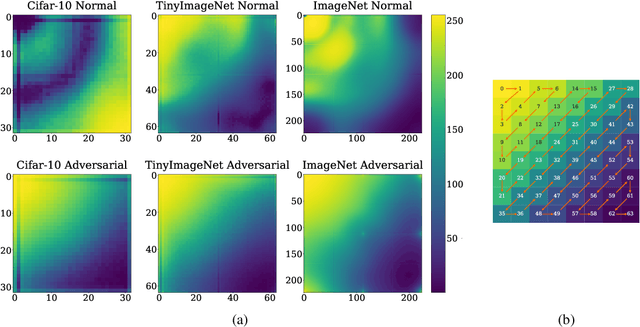
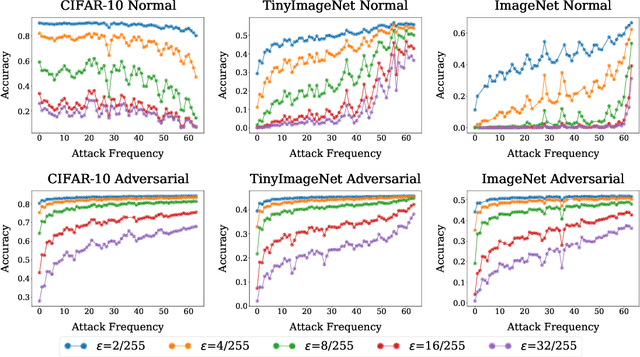
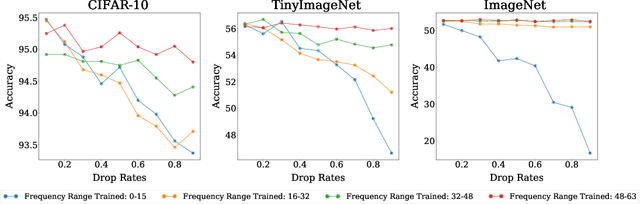
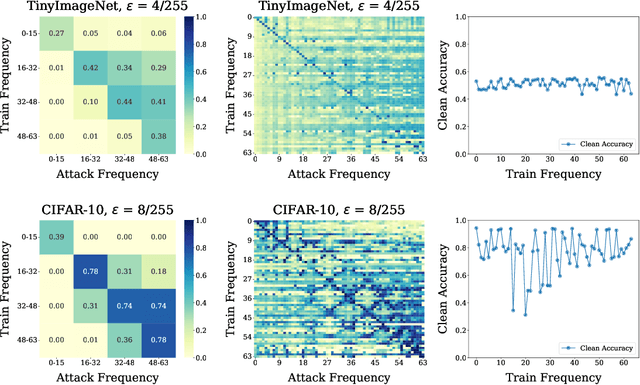
Adversarial examples pose a unique challenge for deep learning systems. Despite recent advances in both attacks and defenses, there is still a lack of clarity and consensus in the community about the true nature and underlying properties of adversarial examples. A deep understanding of these examples can provide new insights towards the development of more effective attacks and defenses. Driven by the common misconception that adversarial examples are high-frequency noise, we present a frequency-based understanding of adversarial examples, supported by theoretical and empirical findings. Our analysis shows that adversarial examples are neither in high-frequency nor in low-frequency components, but are simply dataset dependent. Particularly, we highlight the glaring disparities between models trained on CIFAR-10 and ImageNet-derived datasets. Utilizing this framework, we analyze many intriguing properties of training robust models with frequency constraints, and propose a frequency-based explanation for the commonly observed accuracy vs. robustness trade-off.
Convergent Boosted Smoothing for Modeling Graph Data with Tabular Node Features
Oct 26, 2021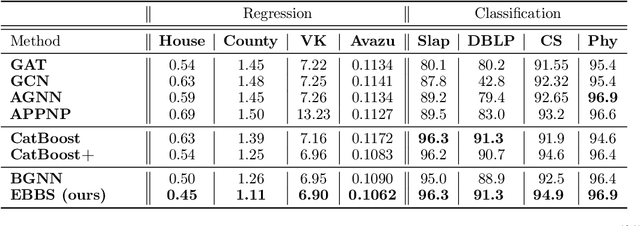
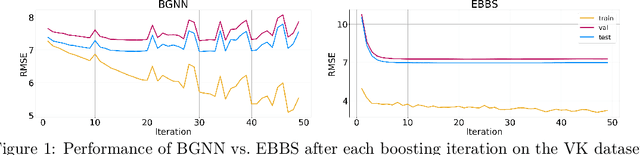

For supervised learning with tabular data, decision tree ensembles produced via boosting techniques generally dominate real-world applications involving iid training/test sets. However for graph data where the iid assumption is violated due to structured relations between samples, it remains unclear how to best incorporate this structure within existing boosting pipelines. To this end, we propose a generalized framework for iterating boosting with graph propagation steps that share node/sample information across edges connecting related samples. Unlike previous efforts to integrate graph-based models with boosting, our approach is anchored in a principled meta loss function such that provable convergence can be guaranteed under relatively mild assumptions. Across a variety of non-iid graph datasets with tabular node features, our method achieves comparable or superior performance than both tabular and graph neural network models, as well as existing hybrid strategies that combine the two. Beyond producing better predictive performance than recently proposed graph models, our proposed techniques are easy to implement, computationally more efficient, and enjoy stronger theoretical guarantees (which make our results more reproducible).
Robbing the Fed: Directly Obtaining Private Data in Federated Learning with Modified Models
Oct 25, 2021
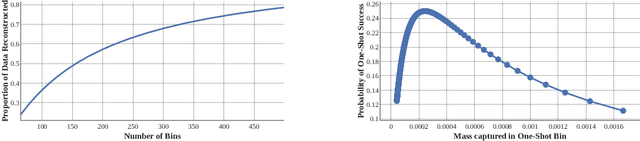


Federated learning has quickly gained popularity with its promises of increased user privacy and efficiency. Previous works have shown that federated gradient updates contain information that can be used to approximately recover user data in some situations. These previous attacks on user privacy have been limited in scope and do not scale to gradient updates aggregated over even a handful of data points, leaving some to conclude that data privacy is still intact for realistic training regimes. In this work, we introduce a new threat model based on minimal but malicious modifications of the shared model architecture which enable the server to directly obtain a verbatim copy of user data from gradient updates without solving difficult inverse problems. Even user data aggregated over large batches -- where previous methods fail to extract meaningful content -- can be reconstructed by these minimally modified models.