 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradInit: Learning to Initialize Neural Networks for Stable and Efficient Training
Paper and Code
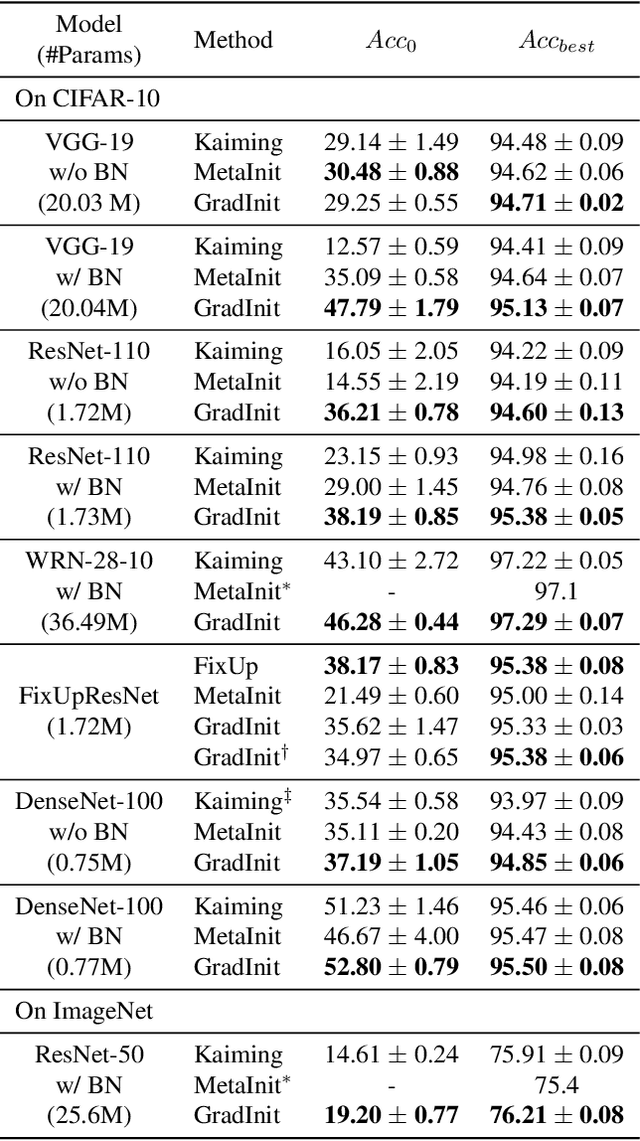
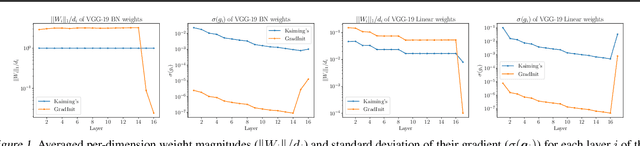
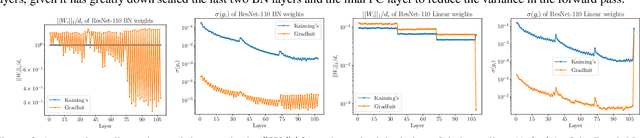
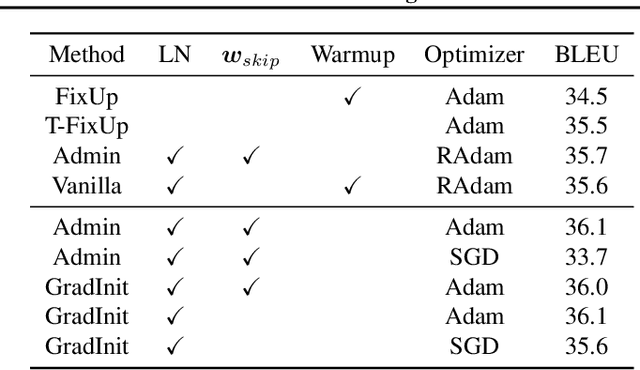
Changes in neural architectures have fostered significant breakthroughs in language modeling and computer vision. Unfortunately, novel architectures often require re-thinking the choice of hyperparameters (e.g., learning rate, warmup schedule, and momentum coefficients) to maintain stability of the optimizer. This optimizer instability is often the result of poor parameter initialization, and can be avoided by architecture-specific initialization schemes. In this paper, we present GradInit, an automated and architecture agnostic method for initializing neural networks. GradInit is based on a simple heuristic; the variance of each network layer is adjusted so that a single step of SGD or Adam results in the smallest possible loss value. This adjustment is done by introducing a scalar multiplier variable in front of each parameter block, and then optimizing these variables using a simple numerical scheme. GradInit accelerates the convergence and test performance of many convolutional architectures, both with or without skip connections, and even without normalization layers. It also enables training the original Post-LN Transformer for machine translation without learning rate warmup under a wide range of learning rates and momentum coefficients. Code is available at https://github.com/zhuchen03/gradinit.