 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025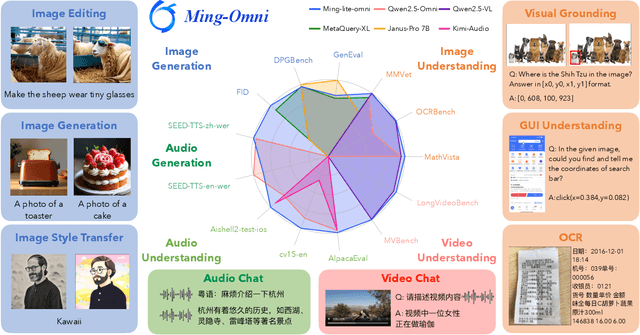
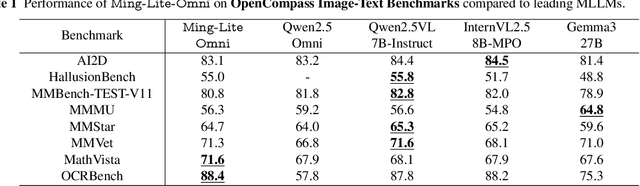
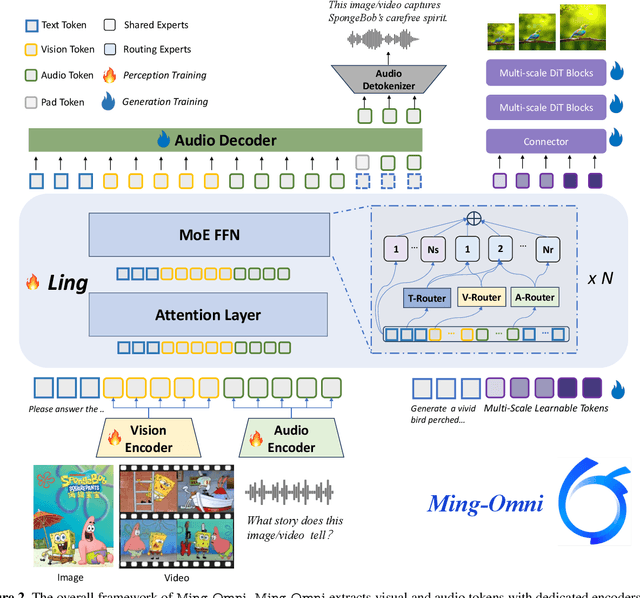
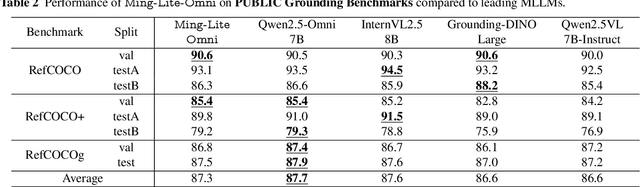
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
FAB: A Robust Facial Landmark Detection Framework for Motion-Blurred Videos
Oct 26, 2019
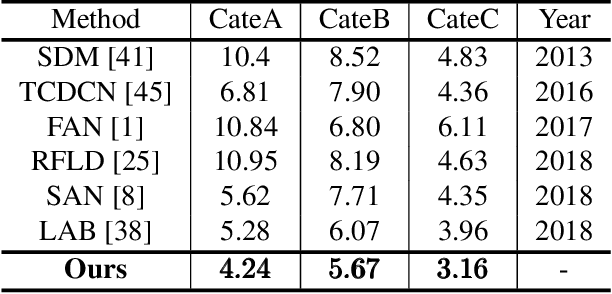
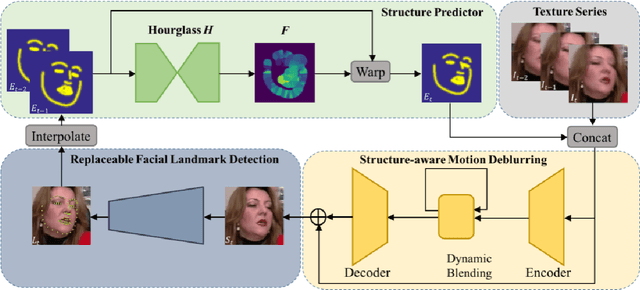
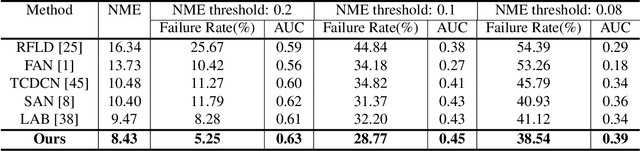
Recently, facial landmark detection algorithms have achieved remarkable performance on static images. However, these algorithms are neither accurate nor stable in motion-blurred videos. The missing of structure information makes it difficult for state-of-the-art facial landmark detection algorithms to yield good results. In this paper, we propose a framework named FAB that takes advantage of structure consistency in the temporal dimension for facial landmark detection in motion-blurred videos. A structure predictor is proposed to predict the missing face structural information temporally, which serves as a geometry prior. This allows our framework to work as a virtuous circle. On one hand, the geometry prior helps our structure-aware deblurring network generates high quality deblurred images which lead to better landmark detection results. On the other hand, better landmark detection results help structure predictor generate better geometry prior for the next frame. Moreover, it is a flexible video-based framework that can incorporate any static image-based methods to provide a performance boost on video datasets. Extensive experiments on Blurred-300VW, the proposed Real-world Motion Blur (RWMB) datasets and 300VW demonstrate the superior performance to the state-of-the-art methods. Datasets and models will be publicly available at https://keqiangsun.github.io/projects/FAB/FAB.html.