 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentionCap: Transformer Based Capacitance Matrix Learning Toward Full-Chip Extraction
Jun 06, 2026As capacitance extraction accuracy of rule-based pattern matching becomes difficult to sustain at advanced nodes, a growing trend emerges to develop deep-learning-based 2D capacitance models. However, existing MLP- and CNN-based methods constrain their input to fixed metal-layer combinations in a specific process node, limiting their usability in practice. Recognizing the inherent similarity between capacitance matrix and the prevailing attention mechanism, we propose AttentionCap, a customized Transformer for capacitance matrix learning, with a Gram representation framework, a physics-aligned symmetric-attention output layer, and a novel normalized Laplacian loss. We also introduce a process-node embedding to enable multi-node learning. Trained on synthetic data, AttentionCap attains 0.67\%/3.99\% self/coupling-capacitance error on unseen real designs under a multi-layer and multi-node setting, surpassing the CNN-Cap baseline with 4.6$\times$/5.7$\times$ lower self/coupling error and 192$\times$ faster inference speed. A pretrained AttentionCap accurately transfers to an unseen node with only 5K samples and 4K finetuning steps. With sufficient accuracy on unseen real designs and strong transferability to new process nodes, AttentionCap offers highly practical value for modern EDA workflows. Code and data are available at https://github.com/THU-numbda/AttentionCap.
FAB: A Robust Facial Landmark Detection Framework for Motion-Blurred Videos
Oct 26, 2019
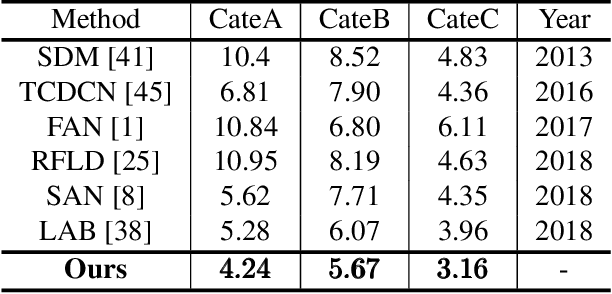
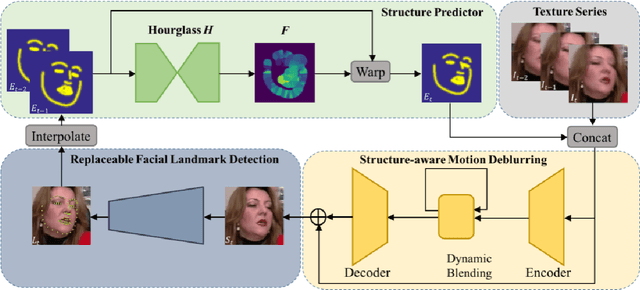
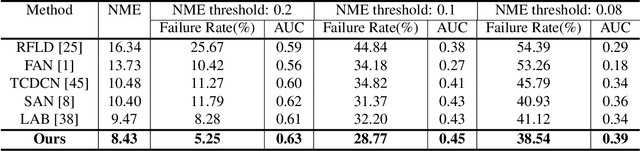
Recently, facial landmark detection algorithms have achieved remarkable performance on static images. However, these algorithms are neither accurate nor stable in motion-blurred videos. The missing of structure information makes it difficult for state-of-the-art facial landmark detection algorithms to yield good results. In this paper, we propose a framework named FAB that takes advantage of structure consistency in the temporal dimension for facial landmark detection in motion-blurred videos. A structure predictor is proposed to predict the missing face structural information temporally, which serves as a geometry prior. This allows our framework to work as a virtuous circle. On one hand, the geometry prior helps our structure-aware deblurring network generates high quality deblurred images which lead to better landmark detection results. On the other hand, better landmark detection results help structure predictor generate better geometry prior for the next frame. Moreover, it is a flexible video-based framework that can incorporate any static image-based methods to provide a performance boost on video datasets. Extensive experiments on Blurred-300VW, the proposed Real-world Motion Blur (RWMB) datasets and 300VW demonstrate the superior performance to the state-of-the-art methods. Datasets and models will be publicly available at https://keqiangsun.github.io/projects/FAB/FAB.html.
Detecting Adversarial Perturbations with Saliency
Mar 23, 2018
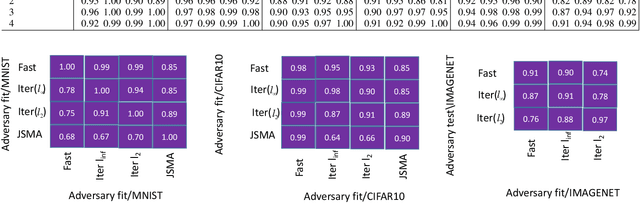

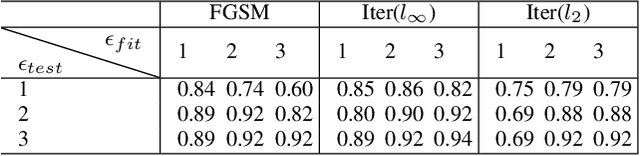
In this paper we propose a novel method for detecting adversarial examples by training a binary classifier with both origin data and saliency data. In the case of image classification model, saliency simply explain how the model make decisions by identifying significant pixels for prediction. A model shows wrong classification output always learns wrong features and shows wrong saliency as well. Our approach shows good performance on detecting adversarial perturbations. We quantitatively evaluate generalization ability of the detector, showing that detectors trained with strong adversaries perform well on weak adversaries.