 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashion130K: An E-commerce Fashion Dataset for Outfit Generation with Unified Multi-modal Condition
May 11, 2026Recent research work on fashion outfit generation focuses on promoting visual consistency of garments by leveraging key information from reference image and text prompt. However, the potential of outfit generation remains underexplored, requiring comprehensive e-commercial dataset and elaborative utilization of multi-modal condition. In this paper, we propose a brand-new e-commerce dataset, named Fashion130k, with various occasions, models, and garment types. For the consistent generation of garment, we design a framework with Unified Multi-modal Condition (UMC) to align and integrate the text and visual prompts into generation model. Specifically, we explore an embedding refiner to extract the unified embeddings of multi-modal prompts, within which a Fusion Transformer is proposed to align the multi-modal embeddings by adjusting the modality gap between text and image. Based on unified embeddings, the attention in generation model is redesigned to emphasis the correlations between prompts and noise image, inducing that the noise image can select the pivotal tokens of prompts for consistent outfit generation. Our dataset and proposed framework offer a general and nuanced exploration of multi-modal prompts for generation models. Extensive experiments on real-world applications and benchmark demonstrate the effectiveness of UMC in visual consistency, achieving promising result than that of SoTA methods.
UM-Text: A Unified Multimodal Model for Image Understanding
Jan 13, 2026With the rapid advancement of image generation, visual text editing using natural language instructions has received increasing attention. The main challenge of this task is to fully understand the instruction and reference image, and thus generate visual text that is style-consistent with the image. Previous methods often involve complex steps of specifying the text content and attributes, such as font size, color, and layout, without considering the stylistic consistency with the reference image. To address this, we propose UM-Text, a unified multimodal model for context understanding and visual text editing by natural language instructions. Specifically, we introduce a Visual Language Model (VLM) to process the instruction and reference image, so that the text content and layout can be elaborately designed according to the context information. To generate an accurate and harmonious visual text image, we further propose the UM-Encoder to combine the embeddings of various condition information, where the combination is automatically configured by VLM according to the input instruction. During training, we propose a regional consistency loss to offer more effective supervision for glyph generation on both latent and RGB space, and design a tailored three-stage training strategy to further enhance model performance. In addition, we contribute the UM-DATA-200K, a large-scale visual text image dataset on diverse scenes for model training. Extensive qualitative and quantitative results on multiple public benchmarks demonstrate that our method achieves state-of-the-art performance.
EdgeFlex-Transformer: Transformer Inference for Edge Devices
Dec 17, 2025Deploying large-scale transformer models on edge devices presents significant challenges due to strict constraints on memory, compute, and latency. In this work, we propose a lightweight yet effective multi-stage optimization pipeline designed to compress and accelerate Vision Transformers (ViTs) for deployment in resource-constrained environments. Our methodology combines activation profiling, memory-aware pruning, selective mixed-precision execution, and activation-aware quantization (AWQ) to reduce the model's memory footprint without requiring costly retraining or task-specific fine-tuning. Starting from a ViT-Huge backbone with 632 million parameters, we first identify low-importance channels using activation statistics collected via forward hooks, followed by structured pruning to shrink the MLP layers under a target memory budget. We further apply FP16 conversion to selected components and leverage AWQ to quantize the remaining model weights and activations to INT8 with minimal accuracy degradation. Our experiments on CIFAR-10 demonstrate that the fully optimized model achieves a 76% reduction in peak memory usage and over 6x lower latency, while retaining or even improving accuracy compared to the original FP32 baseline. This framework offers a practical path toward efficient transformer inference on edge platforms, and opens future avenues for integrating dynamic sparsity and Mixture-of-Experts (MoE) architectures to further scale performance across diverse tasks.
On-device Large Multi-modal Agent for Human Activity Recognition
Dec 17, 2025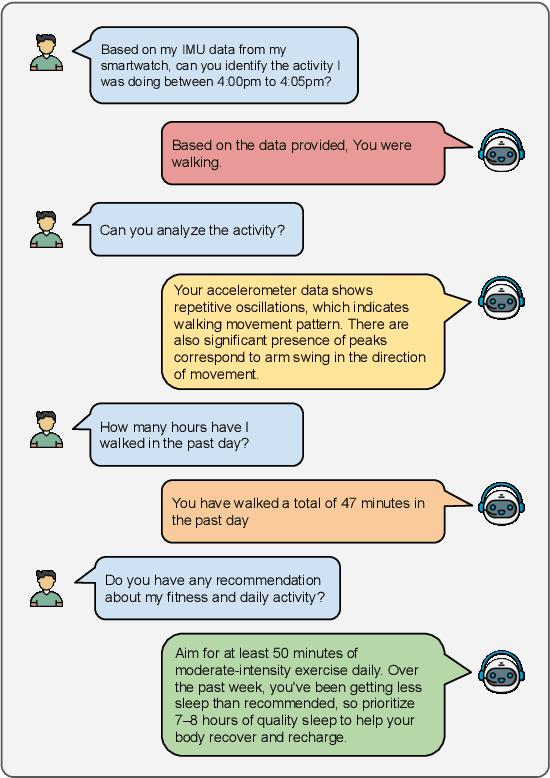
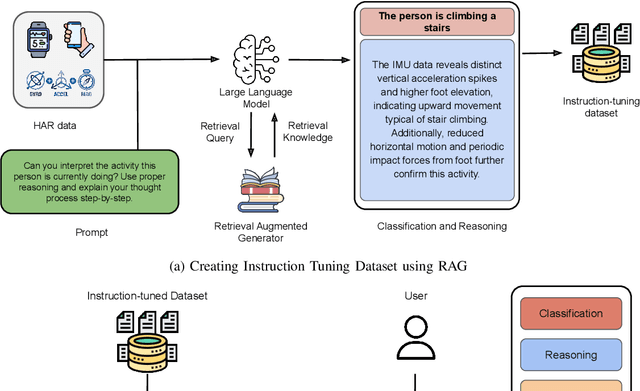
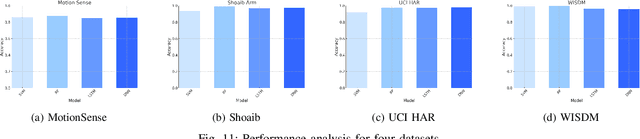
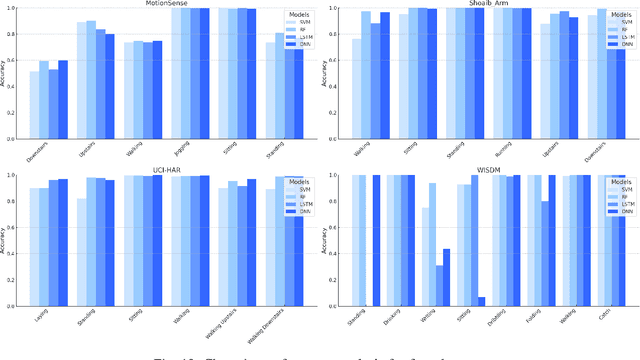
Human Activity Recognition (HAR) has been an active area of research, with applications ranging from healthcare to smart environments. The recent advancements in Large Language Models (LLMs) have opened new possibilities to leverage their capabilities in HAR, enabling not just activity classification but also interpretability and human-like interaction. In this paper, we present a Large Multi-Modal Agent designed for HAR, which integrates the power of LLMs to enhance both performance and user engagement. The proposed framework not only delivers activity classification but also bridges the gap between technical outputs and user-friendly insights through its reasoning and question-answering capabilities. We conduct extensive evaluations using widely adopted HAR datasets, including HHAR, Shoaib, Motionsense to assess the performance of our framework. The results demonstrate that our model achieves high classification accuracy comparable to state-of-the-art methods while significantly improving interpretability through its reasoning and Q&A capabilities.
Energy Efficient LoRaWAN in LEO Satellites
Dec 30, 2024



LPWAN service's inexpensive cost and long range capabilities make it a promising addition and countless satellite companies have started taking advantage of this technology to connect IoT users across the globe. However, LEO satellites have the unique challenge of using rechargeable batteries and green solar energy to power their components. LPWAN technology is not optimized to maximize battery lifespan of network nodes. By incorporating a MAC protocol that maximizes node the battery lifespan across the network, we can reduce battery waste and usage of scarce Earth resources to develop satellite batteries.
Mitigating Relative Over-Generalization in Multi-Agent Reinforcement Learning
Nov 17, 2024In decentralized multi-agent reinforcement learning, agents learning in isolation can lead to relative over-generalization (RO), where optimal joint actions are undervalued in favor of suboptimal ones. This hinders effective coordination in cooperative tasks, as agents tend to choose actions that are individually rational but collectively suboptimal. To address this issue, we introduce MaxMax Q-Learning (MMQ), which employs an iterative process of sampling and evaluating potential next states, selecting those with maximal Q-values for learning. This approach refines approximations of ideal state transitions, aligning more closely with the optimal joint policy of collaborating agents. We provide theoretical analysis supporting MMQ's potential and present empirical evaluations across various environments susceptible to RO. Our results demonstrate that MMQ frequently outperforms existing baselines, exhibiting enhanced convergence and sample efficiency.
Enhancing dysarthria speech feature representation with empirical mode decomposition and Walsh-Hadamard transform
Dec 30, 2023Dysarthria speech contains the pathological characteristics of vocal tract and vocal fold, but so far, they have not yet been included in traditional acoustic feature sets. Moreover, the nonlinearity and non-stationarity of speech have been ignored. In this paper, we propose a feature enhancement algorithm for dysarthria speech called WHFEMD. It combines empirical mode decomposition (EMD) and fast Walsh-Hadamard transform (FWHT) to enhance features. With the proposed algorithm, the fast Fourier transform of the dysarthria speech is first performed and then followed by EMD to get intrinsic mode functions (IMFs). After that, FWHT is used to output new coefficients and to extract statistical features based on IMFs, power spectral density, and enhanced gammatone frequency cepstral coefficients. To evaluate the proposed approach, we conducted experiments on two public pathological speech databases including UA Speech and TORGO. The results show that our algorithm performed better than traditional features in classification. We achieved improvements of 13.8% (UA Speech) and 3.84% (TORGO), respectively. Furthermore, the incorporation of an imbalanced classification algorithm to address data imbalance has resulted in a 12.18% increase in recognition accuracy. This algorithm effectively addresses the challenges of the imbalanced dataset and non-linearity in dysarthric speech and simultaneously provides a robust representation of the local pathological features of the vocal folds and tracts.
Data Classification With Multiprocessing
Dec 23, 2023Classification is one of the most important tasks in Machine Learning (ML) and with recent advancements in artificial intelligence (AI) it is important to find efficient ways to implement it. Generally, the choice of classification algorithm depends on the data it is dealing with, and accuracy of the algorithm depends on the hyperparameters it is tuned with. One way is to check the accuracy of the algorithms by executing it with different hyperparameters serially and then selecting the parameters that give the highest accuracy to predict the final output. This paper proposes another way where the algorithm is parallelly trained with different hyperparameters to reduce the execution time. In the end, results from all the trained variations of the algorithms are ensembled to exploit the parallelism and improve the accuracy of prediction. Python multiprocessing is used to test this hypothesis with different classification algorithms such as K-Nearest Neighbors (KNN), Support Vector Machines (SVM), random forest and decision tree and reviews factors affecting parallelism. Ensembled output considers the predictions from all processes and final class is the one predicted by maximum number of processes. Doing this increases the reliability of predictions. We conclude that ensembling improves accuracy and multiprocessing reduces execution time for selected algorithms.
Design, construction and evaluation of emotional multimodal pathological speech database
Dec 14, 2023



The lack of an available emotion pathology database is one of the key obstacles in studying the emotion expression status of patients with dysarthria. The first Chinese multimodal emotional pathological speech database containing multi-perspective information is constructed in this paper. It includes 29 controls and 39 patients with different degrees of motor dysarthria, expressing happy, sad, angry and neutral emotions. All emotional speech was labeled for intelligibility, types and discrete dimensional emotions by developed WeChat mini-program. The subjective analysis justifies from emotion discrimination accuracy, speech intelligibility, valence-arousal spatial distribution, and correlation between SCL-90 and disease severity. The automatic recognition tested on speech and glottal data, with average accuracy of 78% for controls and 60% for patients in audio, while 51% for controls and 38% for patients in glottal data, indicating an influence of the disease on emotional expression.
KG-BERTScore: Incorporating Knowledge Graph into BERTScore for Reference-Free Machine Translation Evaluation
Jan 30, 2023BERTScore is an effective and robust automatic metric for referencebased machine translation evaluation. In this paper, we incorporate multilingual knowledge graph into BERTScore and propose a metric named KG-BERTScore, which linearly combines the results of BERTScore and bilingual named entity matching for reference-free machine translation evaluation. From the experimental results on WMT19 QE as a metric without references shared tasks, our metric KG-BERTScore gets higher overall correlation with human judgements than the current state-of-the-art metrics for reference-free machine translation evaluation.1 Moreover, the pre-trained multilingual model used by KG-BERTScore and the parameter for linear combination are also studied in this paper.