 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChiQA: A Large Scale Image-based Real-World Question Answering Dataset for Multi-Modal Understanding
Aug 05, 2022
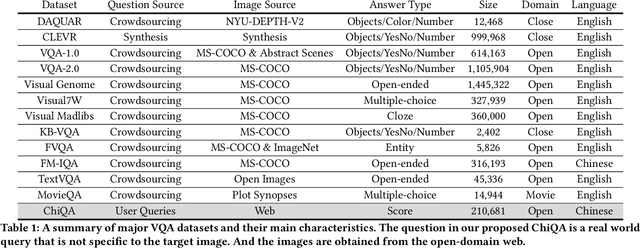

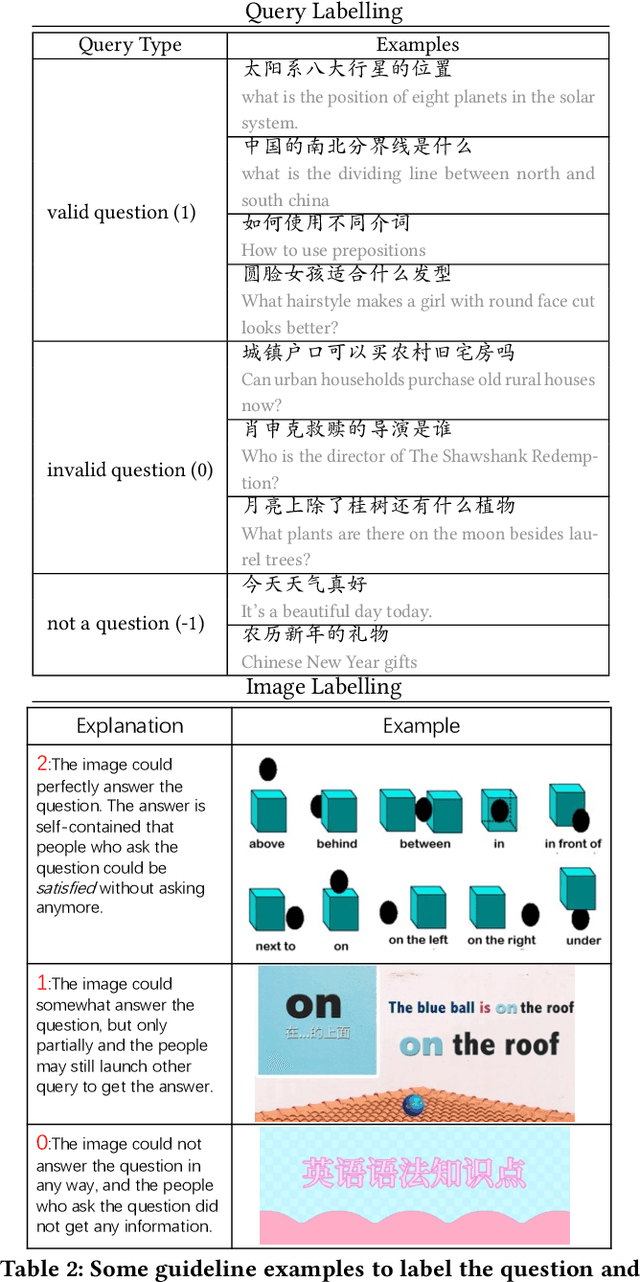
Visual question answering is an important task in both natural language and vision understanding. However, in most of the public visual question answering datasets such as VQA, CLEVR, the questions are human generated that specific to the given image, such as `What color are her eyes?'. The human generated crowdsourcing questions are relatively simple and sometimes have the bias toward certain entities or attributes. In this paper, we introduce a new question answering dataset based on image-ChiQA. It contains the real-world queries issued by internet users, combined with several related open-domain images. The system should determine whether the image could answer the question or not. Different from previous VQA datasets, the questions are real-world image-independent queries that are more various and unbiased. Compared with previous image-retrieval or image-caption datasets, the ChiQA not only measures the relatedness but also measures the answerability, which demands more fine-grained vision and language reasoning. ChiQA contains more than 40K questions and more than 200K question-images pairs. A three-level 2/1/0 label is assigned to each pair indicating perfect answer, partially answer and irrelevant. Data analysis shows ChiQA requires a deep understanding of both language and vision, including grounding, comparisons, and reading. We evaluate several state-of-the-art visual-language models such as ALBEF, demonstrating that there is still a large room for improvements on ChiQA.
Lightweight and Progressively-Scalable Networks for Semantic Segmentation
Jul 27, 2022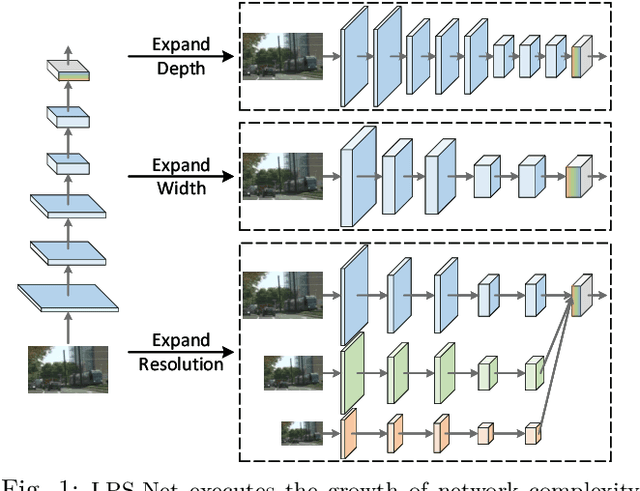

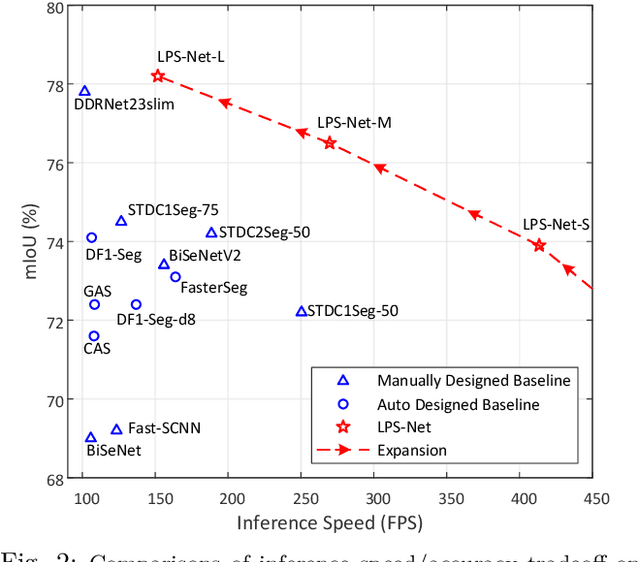
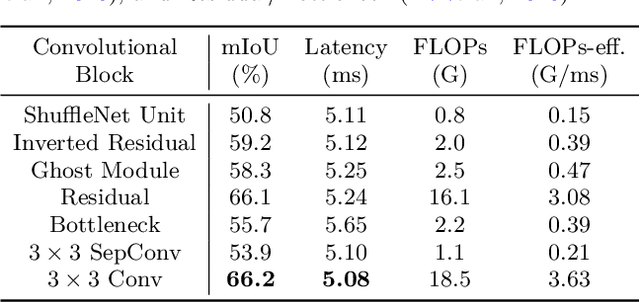
Multi-scale learning frameworks have been regarded as a capable class of models to boost semantic segmentation. The problem nevertheless is not trivial especially for the real-world deployments, which often demand high efficiency in inference latency. In this paper, we thoroughly analyze the design of convolutional blocks (the type of convolutions and the number of channels in convolutions), and the ways of interactions across multiple scales, all from lightweight standpoint for semantic segmentation. With such in-depth comparisons, we conclude three principles, and accordingly devise Lightweight and Progressively-Scalable Networks (LPS-Net) that novelly expands the network complexity in a greedy manner. Technically, LPS-Net first capitalizes on the principles to build a tiny network. Then, LPS-Net progressively scales the tiny network to larger ones by expanding a single dimension (the number of convolutional blocks, the number of channels, or the input resolution) at one time to meet the best speed/accuracy tradeoff. Extensive experiments conducted on three datasets consistently demonstrate the superiority of LPS-Net over several efficient semantic segmentation methods. More remarkably, our LPS-Net achieves 73.4% mIoU on Cityscapes test set, with the speed of 413.5FPS on an NVIDIA GTX 1080Ti, leading to a performance improvement by 1.5% and a 65% speed-up against the state-of-the-art STDC. Code is available at \url{https://github.com/YihengZhang-CV/LPS-Net}.
Dual Vision Transformer
Jul 12, 2022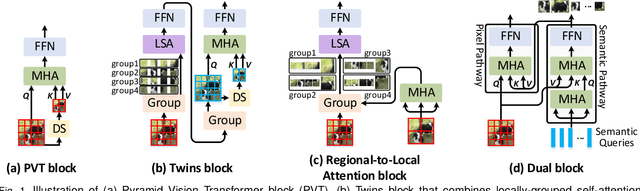
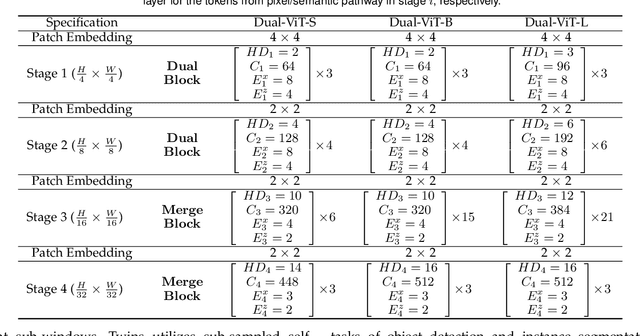
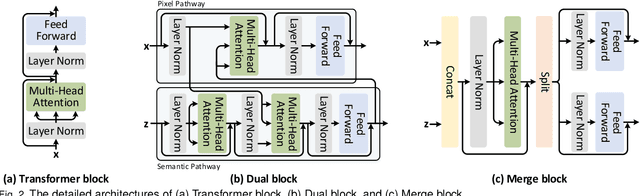
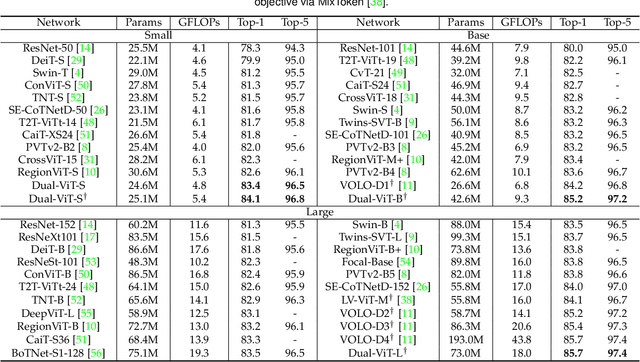
Prior works have proposed several strategies to reduce the computational cost of self-attention mechanism. Many of these works consider decomposing the self-attention procedure into regional and local feature extraction procedures that each incurs a much smaller computational complexity. However, regional information is typically only achieved at the expense of undesirable information lost owing to down-sampling. In this paper, we propose a novel Transformer architecture that aims to mitigate the cost issue, named Dual Vision Transformer (Dual-ViT). The new architecture incorporates a critical semantic pathway that can more efficiently compress token vectors into global semantics with reduced order of complexity. Such compressed global semantics then serve as useful prior information in learning finer pixel level details, through another constructed pixel pathway. The semantic pathway and pixel pathway are then integrated together and are jointly trained, spreading the enhanced self-attention information in parallel through both of the pathways. Dual-ViT is henceforth able to reduce the computational complexity without compromising much accuracy. We empirically demonstrate that Dual-ViT provides superior accuracy than SOTA Transformer architectures with reduced training complexity. Source code is available at \url{https://github.com/YehLi/ImageNetModel}.
Wave-ViT: Unifying Wavelet and Transformers for Visual Representation Learning
Jul 11, 2022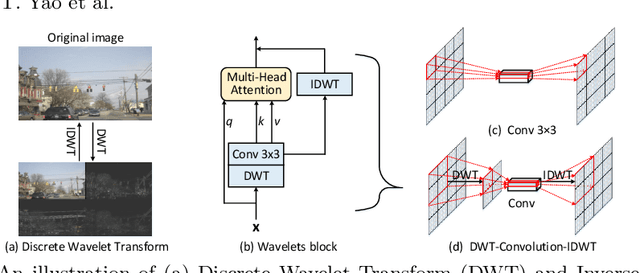
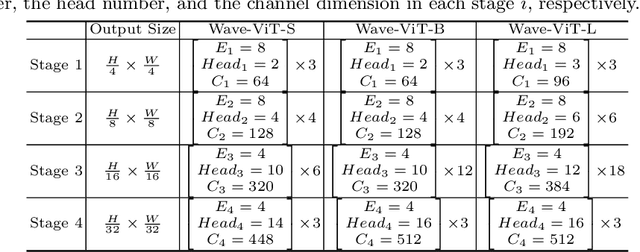
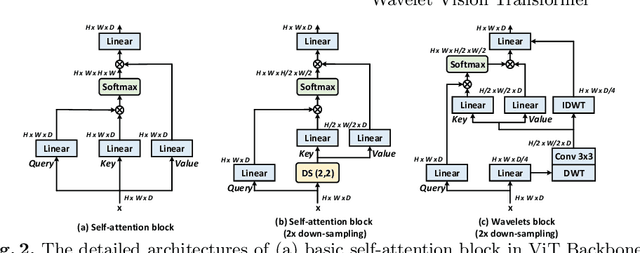
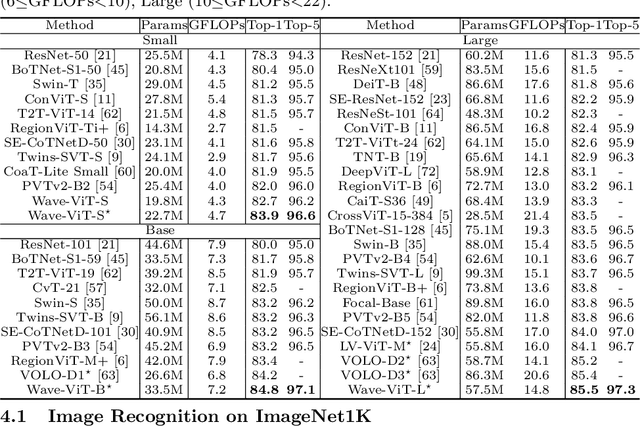
Multi-scale Vision Transformer (ViT) has emerged as a powerful backbone for computer vision tasks, while the self-attention computation in Transformer scales quadratically w.r.t. the input patch number. Thus, existing solutions commonly employ down-sampling operations (e.g., average pooling) over keys/values to dramatically reduce the computational cost. In this work, we argue that such over-aggressive down-sampling design is not invertible and inevitably causes information dropping especially for high-frequency components in objects (e.g., texture details). Motivated by the wavelet theory, we construct a new Wavelet Vision Transformer (\textbf{Wave-ViT}) that formulates the invertible down-sampling with wavelet transforms and self-attention learning in a unified way. This proposal enables self-attention learning with lossless down-sampling over keys/values, facilitating the pursuing of a better efficiency-vs-accuracy trade-off. Furthermore, inverse wavelet transforms are leveraged to strengthen self-attention outputs by aggregating local contexts with enlarged receptive field. We validate the superiority of Wave-ViT through extensive experiments over multiple vision tasks (e.g., image recognition, object detection and instance segmentation). Its performances surpass state-of-the-art ViT backbones with comparable FLOPs. Source code is available at \url{https://github.com/YehLi/ImageNetModel}.
Bi-Calibration Networks for Weakly-Supervised Video Representation Learning
Jun 21, 2022

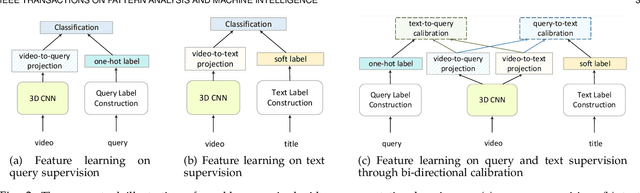
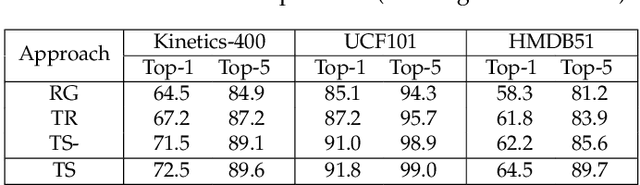
The leverage of large volumes of web videos paired with the searched queries or surrounding texts (e.g., title) offers an economic and extensible alternative to supervised video representation learning. Nevertheless, modeling such weakly visual-textual connection is not trivial due to query polysemy (i.e., many possible meanings for a query) and text isomorphism (i.e., same syntactic structure of different text). In this paper, we introduce a new design of mutual calibration between query and text to boost weakly-supervised video representation learning. Specifically, we present Bi-Calibration Networks (BCN) that novelly couples two calibrations to learn the amendment from text to query and vice versa. Technically, BCN executes clustering on all the titles of the videos searched by an identical query and takes the centroid of each cluster as a text prototype. The query vocabulary is built directly on query words. The video-to-text/video-to-query projections over text prototypes/query vocabulary then start the text-to-query or query-to-text calibration to estimate the amendment to query or text. We also devise a selection scheme to balance the two corrections. Two large-scale web video datasets paired with query and title for each video are newly collected for weakly-supervised video representation learning, which are named as YOVO-3M and YOVO-10M, respectively. The video features of BCN learnt on 3M web videos obtain superior results under linear model protocol on downstream tasks. More remarkably, BCN trained on the larger set of 10M web videos with further fine-tuning leads to 1.6%, and 1.8% gains in top-1 accuracy on Kinetics-400, and Something-Something V2 datasets over the state-of-the-art TDN, and ACTION-Net methods with ImageNet pre-training. Source code and datasets are available at \url{https://github.com/FuchenUSTC/BCN}.
Stand-Alone Inter-Frame Attention in Video Models
Jun 14, 2022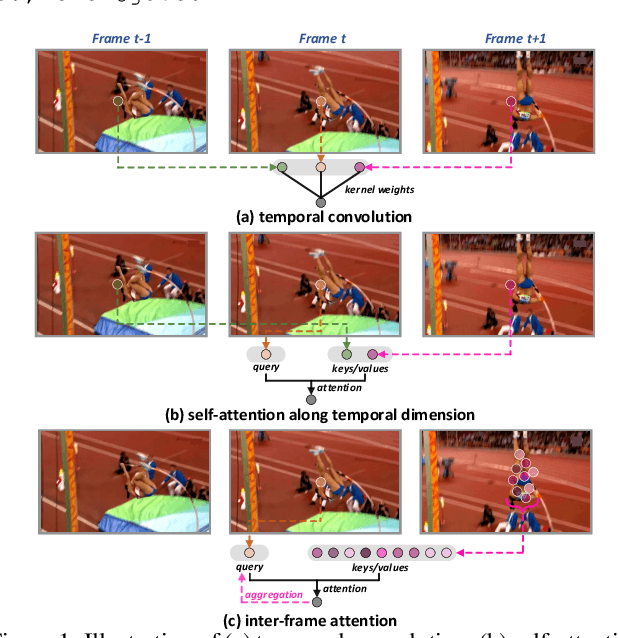
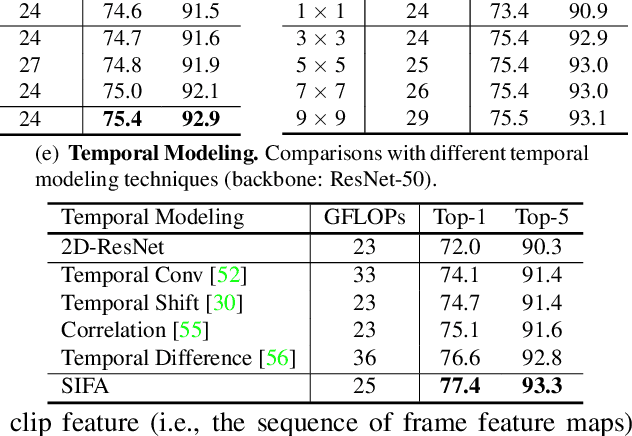
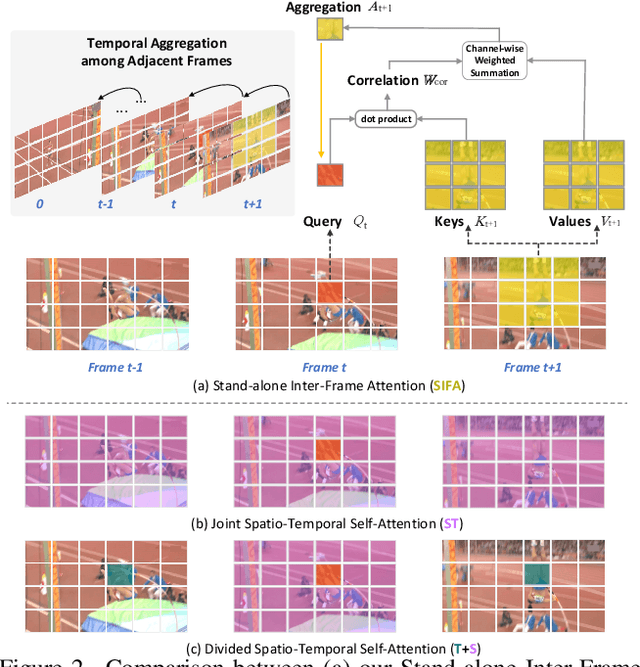
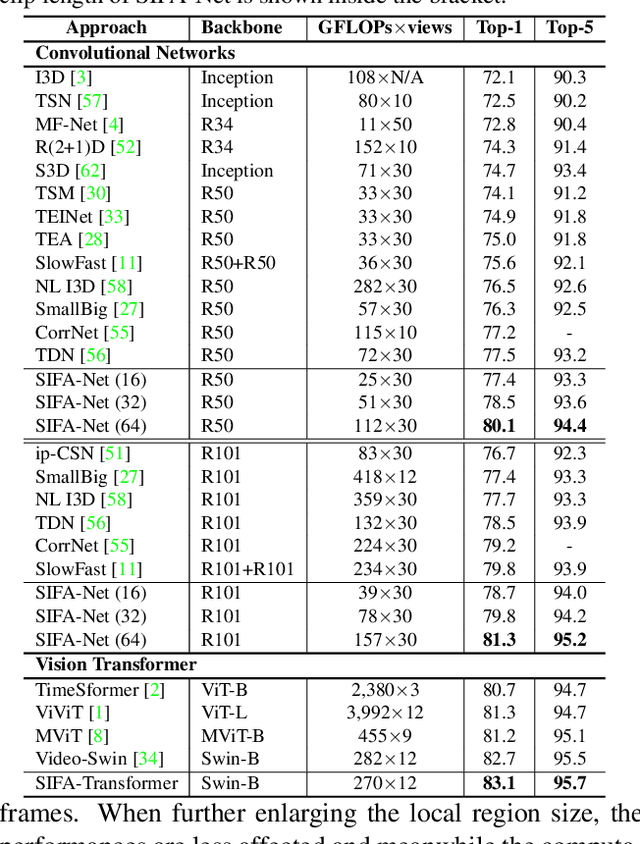
Motion, as the uniqueness of a video, has been critical to the development of video understanding models. Modern deep learning models leverage motion by either executing spatio-temporal 3D convolutions, factorizing 3D convolutions into spatial and temporal convolutions separately, or computing self-attention along temporal dimension. The implicit assumption behind such successes is that the feature maps across consecutive frames can be nicely aggregated. Nevertheless, the assumption may not always hold especially for the regions with large deformation. In this paper, we present a new recipe of inter-frame attention block, namely Stand-alone Inter-Frame Attention (SIFA), that novelly delves into the deformation across frames to estimate local self-attention on each spatial location. Technically, SIFA remoulds the deformable design via re-scaling the offset predictions by the difference between two frames. Taking each spatial location in the current frame as the query, the locally deformable neighbors in the next frame are regarded as the keys/values. Then, SIFA measures the similarity between query and keys as stand-alone attention to weighted average the values for temporal aggregation. We further plug SIFA block into ConvNets and Vision Transformer, respectively, to devise SIFA-Net and SIFA-Transformer. Extensive experiments conducted on four video datasets demonstrate the superiority of SIFA-Net and SIFA-Transformer as stronger backbones. More remarkably, SIFA-Transformer achieves an accuracy of 83.1% on Kinetics-400 dataset. Source code is available at \url{https://github.com/FuchenUSTC/SIFA}.
Comprehending and Ordering Semantics for Image Captioning
Jun 14, 2022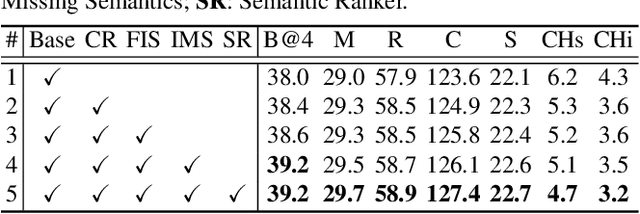
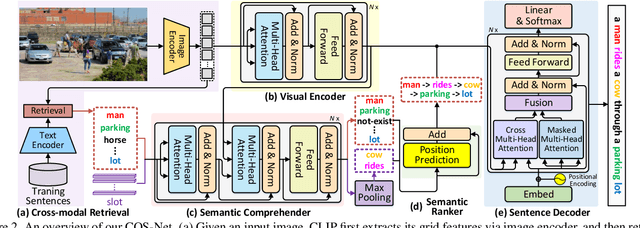
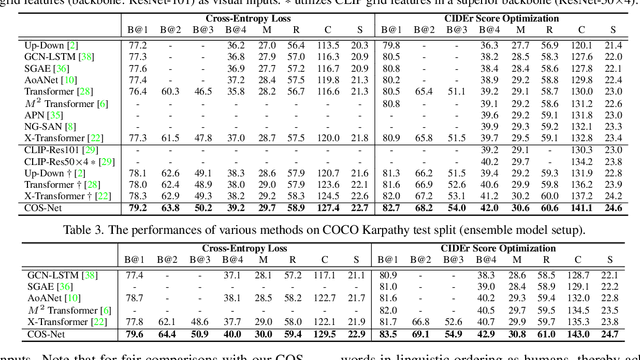
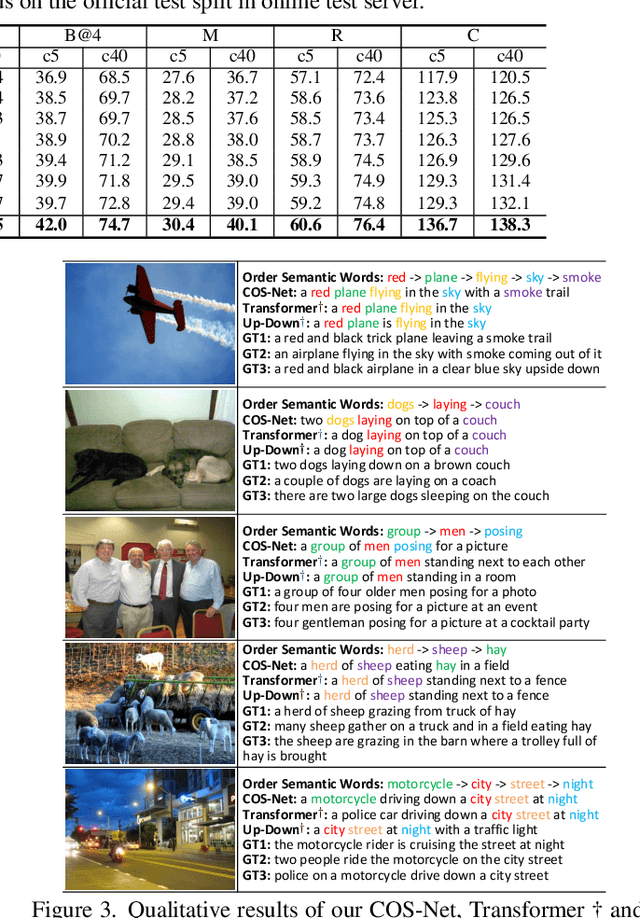
Comprehending the rich semantics in an image and ordering them in linguistic order are essential to compose a visually-grounded and linguistically coherent description for image captioning. Modern techniques commonly capitalize on a pre-trained object detector/classifier to mine the semantics in an image, while leaving the inherent linguistic ordering of semantics under-exploited. In this paper, we propose a new recipe of Transformer-style structure, namely Comprehending and Ordering Semantics Networks (COS-Net), that novelly unifies an enriched semantic comprehending and a learnable semantic ordering processes into a single architecture. Technically, we initially utilize a cross-modal retrieval model to search the relevant sentences of each image, and all words in the searched sentences are taken as primary semantic cues. Next, a novel semantic comprehender is devised to filter out the irrelevant semantic words in primary semantic cues, and meanwhile infer the missing relevant semantic words visually grounded in the image. After that, we feed all the screened and enriched semantic words into a semantic ranker, which learns to allocate all semantic words in linguistic order as humans. Such sequence of ordered semantic words are further integrated with visual tokens of images to trigger sentence generation. Empirical evidences show that COS-Net clearly surpasses the state-of-the-art approaches on COCO and achieves to-date the best CIDEr score of 141.1% on Karpathy test split. Source code is available at \url{https://github.com/YehLi/xmodaler/tree/master/configs/image_caption/cosnet}.
MLP-3D: A MLP-like 3D Architecture with Grouped Time Mixing
Jun 13, 2022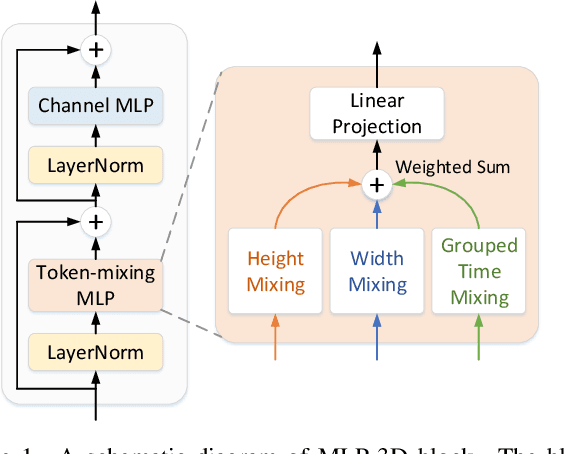
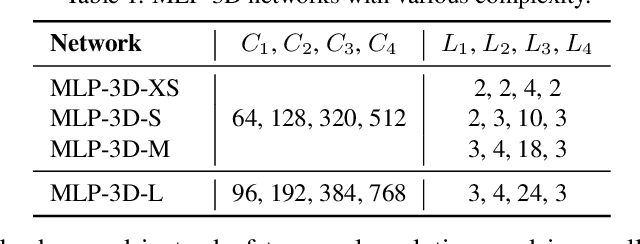

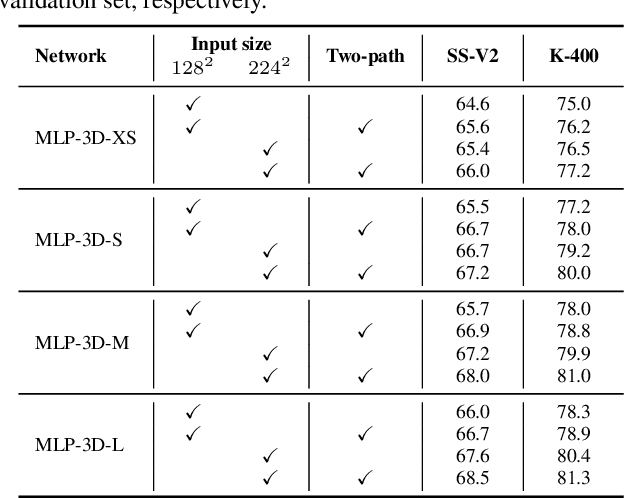
Convolutional Neural Networks (CNNs) have been regarded as the go-to models for visual recognition. More recently, convolution-free networks, based on multi-head self-attention (MSA) or multi-layer perceptrons (MLPs), become more and more popular. Nevertheless, it is not trivial when utilizing these newly-minted networks for video recognition due to the large variations and complexities in video data. In this paper, we present MLP-3D networks, a novel MLP-like 3D architecture for video recognition. Specifically, the architecture consists of MLP-3D blocks, where each block contains one MLP applied across tokens (i.e., token-mixing MLP) and one MLP applied independently to each token (i.e., channel MLP). By deriving the novel grouped time mixing (GTM) operations, we equip the basic token-mixing MLP with the ability of temporal modeling. GTM divides the input tokens into several temporal groups and linearly maps the tokens in each group with the shared projection matrix. Furthermore, we devise several variants of GTM with different grouping strategies, and compose each variant in different blocks of MLP-3D network by greedy architecture search. Without the dependence on convolutions or attention mechanisms, our MLP-3D networks achieves 68.5\%/81.4\% top-1 accuracy on Something-Something V2 and Kinetics-400 datasets, respectively. Despite with fewer computations, the results are comparable to state-of-the-art widely-used 3D CNNs and video transformers. Source code is available at https://github.com/ZhaofanQiu/MLP-3D.
Exploring Structure-aware Transformer over Interaction Proposals for Human-Object Interaction Detection
Jun 13, 2022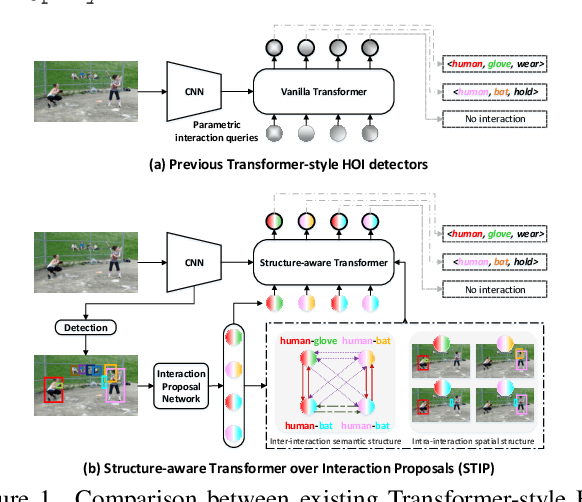
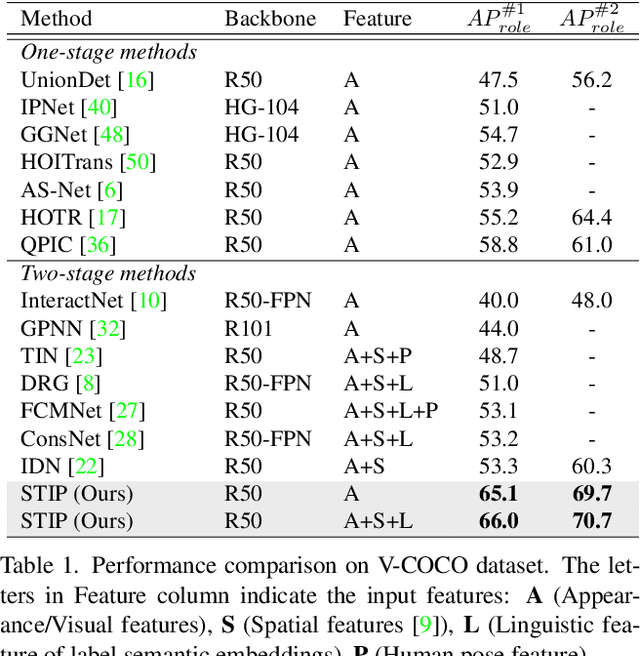
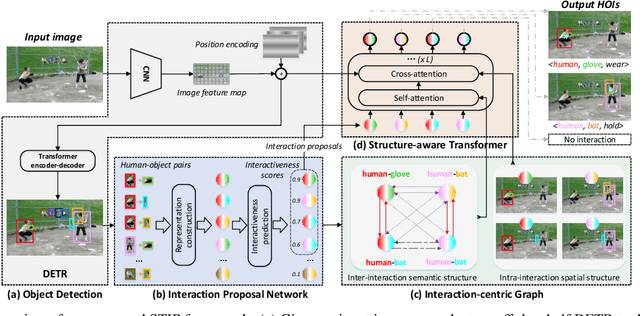
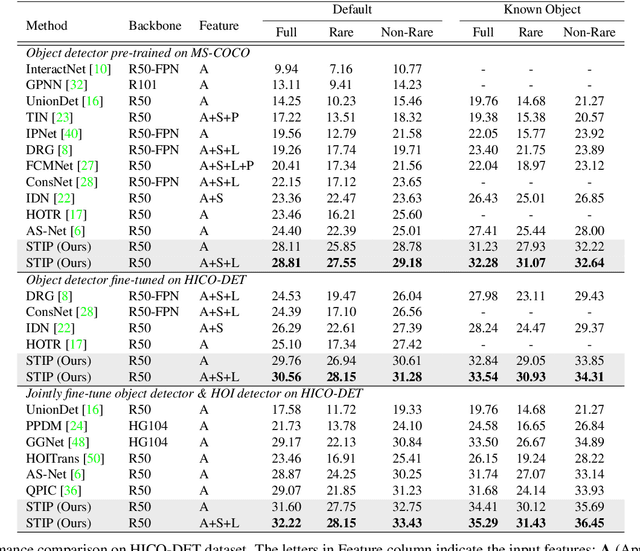
Recent high-performing Human-Object Interaction (HOI) detection techniques have been highly influenced by Transformer-based object detector (i.e., DETR). Nevertheless, most of them directly map parametric interaction queries into a set of HOI predictions through vanilla Transformer in a one-stage manner. This leaves rich inter- or intra-interaction structure under-exploited. In this work, we design a novel Transformer-style HOI detector, i.e., Structure-aware Transformer over Interaction Proposals (STIP), for HOI detection. Such design decomposes the process of HOI set prediction into two subsequent phases, i.e., an interaction proposal generation is first performed, and then followed by transforming the non-parametric interaction proposals into HOI predictions via a structure-aware Transformer. The structure-aware Transformer upgrades vanilla Transformer by encoding additionally the holistically semantic structure among interaction proposals as well as the locally spatial structure of human/object within each interaction proposal, so as to strengthen HOI predictions. Extensive experiments conducted on V-COCO and HICO-DET benchmarks have demonstrated the effectiveness of STIP, and superior results are reported when comparing with the state-of-the-art HOI detectors. Source code is available at \url{https://github.com/zyong812/STIP}.
Silver-Bullet-3D at ManiSkill 2021: Learning-from-Demonstrations and Heuristic Rule-based Methods for Object Manipulation
Jun 13, 2022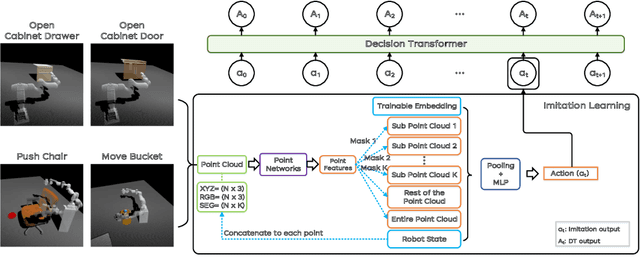



This paper presents an overview and comparative analysis of our systems designed for the following two tracks in SAPIEN ManiSkill Challenge 2021: No Interaction Track: The No Interaction track targets for learning policies from pre-collected demonstration trajectories. We investigate both imitation learning-based approach, i.e., imitating the observed behavior using classical supervised learning techniques, and offline reinforcement learning-based approaches, for this track. Moreover, the geometry and texture structures of objects and robotic arms are exploited via Transformer-based networks to facilitate imitation learning. No Restriction Track: In this track, we design a Heuristic Rule-based Method (HRM) to trigger high-quality object manipulation by decomposing the task into a series of sub-tasks. For each sub-task, the simple rule-based controlling strategies are adopted to predict actions that can be applied to robotic arms. To ease the implementations of our systems, all the source codes and pre-trained models are available at \url{https://github.com/caiqi/Silver-Bullet-3D/}.