 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Agnostic Debiasing for Single Domain Generalization
Mar 13, 2023



Deep neural networks (DNNs) usually fail to generalize well to outside of distribution (OOD) data, especially in the extreme case of single domain generalization (single-DG) that transfers DNNs from single domain to multiple unseen domains. Existing single-DG techniques commonly devise various data-augmentation algorithms, and remould the multi-source domain generalization methodology to learn domain-generalized (semantic) features. Nevertheless, these methods are typically modality-specific, thereby being only applicable to one single modality (e.g., image). In contrast, we target a versatile Modality-Agnostic Debiasing (MAD) framework for single-DG, that enables generalization for different modalities. Technically, MAD introduces a novel two-branch classifier: a biased-branch encourages the classifier to identify the domain-specific (superficial) features, and a general-branch captures domain-generalized features based on the knowledge from biased-branch. Our MAD is appealing in view that it is pluggable to most single-DG models. We validate the superiority of our MAD in a variety of single-DG scenarios with different modalities, including recognition on 1D texts, 2D images, 3D point clouds, and semantic segmentation on 2D images. More remarkably, for recognition on 3D point clouds and semantic segmentation on 2D images, MAD improves DSU by 2.82\% and 1.5\% in accuracy and mIOU.
Semantic-Conditional Diffusion Networks for Image Captioning
Dec 06, 2022Recent advances on text-to-image generation have witnessed the rise of diffusion models which act as powerful generative models. Nevertheless, it is not trivial to exploit such latent variable models to capture the dependency among discrete words and meanwhile pursue complex visual-language alignment in image captioning. In this paper, we break the deeply rooted conventions in learning Transformer-based encoder-decoder, and propose a new diffusion model based paradigm tailored for image captioning, namely Semantic-Conditional Diffusion Networks (SCD-Net). Technically, for each input image, we first search the semantically relevant sentences via cross-modal retrieval model to convey the comprehensive semantic information. The rich semantics are further regarded as semantic prior to trigger the learning of Diffusion Transformer, which produces the output sentence in a diffusion process. In SCD-Net, multiple Diffusion Transformer structures are stacked to progressively strengthen the output sentence with better visional-language alignment and linguistical coherence in a cascaded manner. Furthermore, to stabilize the diffusion process, a new self-critical sequence training strategy is designed to guide the learning of SCD-Net with the knowledge of a standard autoregressive Transformer model. Extensive experiments on COCO dataset demonstrate the promising potential of using diffusion models in the challenging image captioning task. Source code is available at \url{https://github.com/YehLi/xmodaler/tree/master/configs/image_caption/scdnet}.
3D Cascade RCNN: High Quality Object Detection in Point Clouds
Nov 15, 2022



Recent progress on 2D object detection has featured Cascade RCNN, which capitalizes on a sequence of cascade detectors to progressively improve proposal quality, towards high-quality object detection. However, there has not been evidence in support of building such cascade structures for 3D object detection, a challenging detection scenario with highly sparse LiDAR point clouds. In this work, we present a simple yet effective cascade architecture, named 3D Cascade RCNN, that allocates multiple detectors based on the voxelized point clouds in a cascade paradigm, pursuing higher quality 3D object detector progressively. Furthermore, we quantitatively define the sparsity level of the points within 3D bounding box of each object as the point completeness score, which is exploited as the task weight for each proposal to guide the learning of each stage detector. The spirit behind is to assign higher weights for high-quality proposals with relatively complete point distribution, while down-weight the proposals with extremely sparse points that often incur noise during training. This design of completeness-aware re-weighting elegantly upgrades the cascade paradigm to be better applicable for the sparse input data, without increasing any FLOP budgets. Through extensive experiments on both the KITTI dataset and Waymo Open Dataset, we validate the superiority of our proposed 3D Cascade RCNN, when comparing to state-of-the-art 3D object detection techniques. The source code is publicly available at \url{https://github.com/caiqi/Cascasde-3D}.
SPE-Net: Boosting Point Cloud Analysis via Rotation Robustness Enhancement
Nov 15, 2022In this paper, we propose a novel deep architecture tailored for 3D point cloud applications, named as SPE-Net. The embedded ``Selective Position Encoding (SPE)'' procedure relies on an attention mechanism that can effectively attend to the underlying rotation condition of the input. Such encoded rotation condition then determines which part of the network parameters to be focused on, and is shown to efficiently help reduce the degree of freedom of the optimization during training. This mechanism henceforth can better leverage the rotation augmentations through reduced training difficulties, making SPE-Net robust against rotated data both during training and testing. The new findings in our paper also urge us to rethink the relationship between the extracted rotation information and the actual test accuracy. Intriguingly, we reveal evidences that by locally encoding the rotation information through SPE-Net, the rotation-invariant features are still of critical importance in benefiting the test samples without any actual global rotation. We empirically demonstrate the merits of the SPE-Net and the associated hypothesis on four benchmarks, showing evident improvements on both rotated and unrotated test data over SOTA methods. Source code is available at https://github.com/ZhaofanQiu/SPE-Net.
Explaining Cross-Domain Recognition with Interpretable Deep Classifier
Nov 15, 2022The recent advances in deep learning predominantly construct models in their internal representations, and it is opaque to explain the rationale behind and decisions to human users. Such explainability is especially essential for domain adaptation, whose challenges require developing more adaptive models across different domains. In this paper, we ask the question: how much each sample in source domain contributes to the network's prediction on the samples from target domain. To address this, we devise a novel Interpretable Deep Classifier (IDC) that learns the nearest source samples of a target sample as evidence upon which the classifier makes the decision. Technically, IDC maintains a differentiable memory bank for each category and the memory slot derives a form of key-value pair. The key records the features of discriminative source samples and the value stores the corresponding properties, e.g., representative scores of the features for describing the category. IDC computes the loss between the output of IDC and the labels of source samples to back-propagate to adjust the representative scores and update the memory banks. Extensive experiments on Office-Home and VisDA-2017 datasets demonstrate that our IDC leads to a more explainable model with almost no accuracy degradation and effectively calibrates classification for optimum reject options. More remarkably, when taking IDC as a prior interpreter, capitalizing on 0.1% source training data selected by IDC still yields superior results than that uses full training set on VisDA-2017 for unsupervised domain adaptation.
Dynamic Temporal Filtering in Video Models
Nov 15, 2022Video temporal dynamics is conventionally modeled with 3D spatial-temporal kernel or its factorized version comprised of 2D spatial kernel and 1D temporal kernel. The modeling power, nevertheless, is limited by the fixed window size and static weights of a kernel along the temporal dimension. The pre-determined kernel size severely limits the temporal receptive fields and the fixed weights treat each spatial location across frames equally, resulting in sub-optimal solution for long-range temporal modeling in natural scenes. In this paper, we present a new recipe of temporal feature learning, namely Dynamic Temporal Filter (DTF), that novelly performs spatial-aware temporal modeling in frequency domain with large temporal receptive field. Specifically, DTF dynamically learns a specialized frequency filter for every spatial location to model its long-range temporal dynamics. Meanwhile, the temporal feature of each spatial location is also transformed into frequency feature spectrum via 1D Fast Fourier Transform (FFT). The spectrum is modulated by the learnt frequency filter, and then transformed back to temporal domain with inverse FFT. In addition, to facilitate the learning of frequency filter in DTF, we perform frame-wise aggregation to enhance the primary temporal feature with its temporal neighbors by inter-frame correlation. It is feasible to plug DTF block into ConvNets and Transformer, yielding DTF-Net and DTF-Transformer. Extensive experiments conducted on three datasets demonstrate the superiority of our proposals. More remarkably, DTF-Transformer achieves an accuracy of 83.5% on Kinetics-400 dataset. Source code is available at \url{https://github.com/FuchenUSTC/DTF}.
Out-of-Distribution Detection with Hilbert-Schmidt Independence Optimization
Sep 26, 2022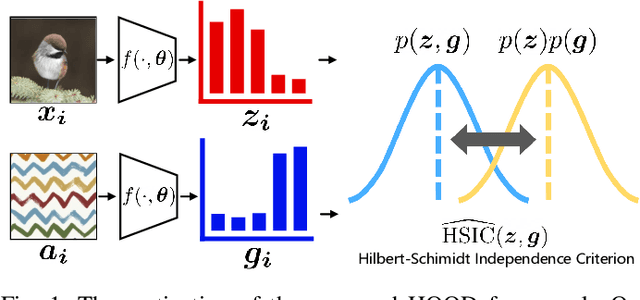
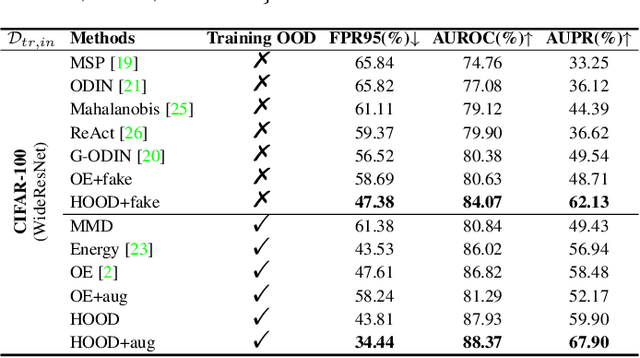
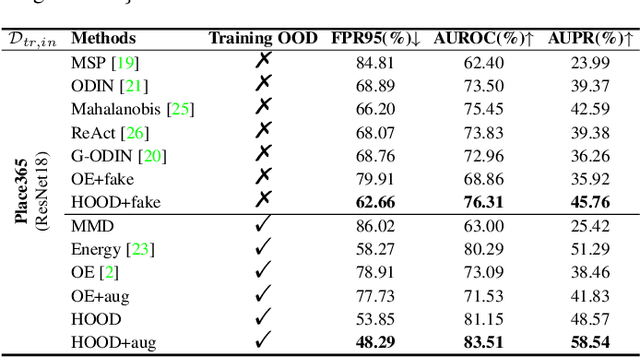
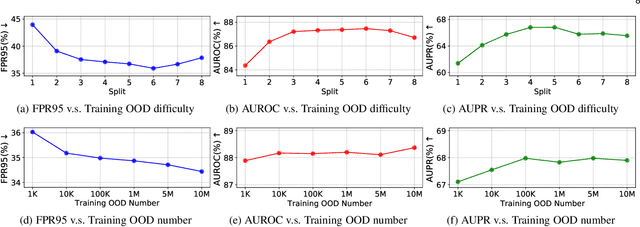
Outlier detection tasks have been playing a critical role in AI safety. There has been a great challenge to deal with this task. Observations show that deep neural network classifiers usually tend to incorrectly classify out-of-distribution (OOD) inputs into in-distribution classes with high confidence. Existing works attempt to solve the problem by explicitly imposing uncertainty on classifiers when OOD inputs are exposed to the classifier during training. In this paper, we propose an alternative probabilistic paradigm that is both practically useful and theoretically viable for the OOD detection tasks. Particularly, we impose statistical independence between inlier and outlier data during training, in order to ensure that inlier data reveals little information about OOD data to the deep estimator during training. Specifically, we estimate the statistical dependence between inlier and outlier data through the Hilbert-Schmidt Independence Criterion (HSIC), and we penalize such metric during training. We also associate our approach with a novel statistical test during the inference time coupled with our principled motivation. Empirical results show that our method is effective and robust for OOD detection on various benchmarks. In comparison to SOTA models, our approach achieves significant improvement regarding FPR95, AUROC, and AUPR metrics. Code is available: \url{https://github.com/jylins/hood}.
Scale Attention for Learning Deep Face Representation: A Study Against Visual Scale Variation
Sep 19, 2022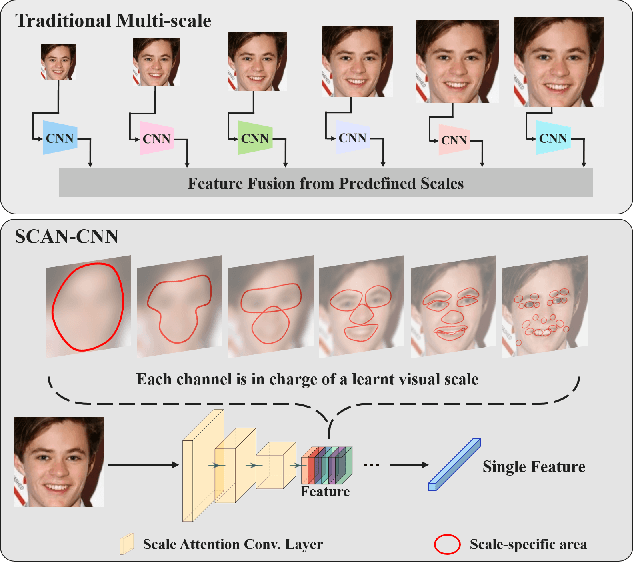
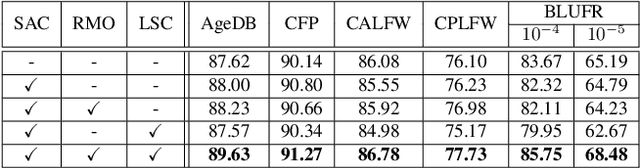
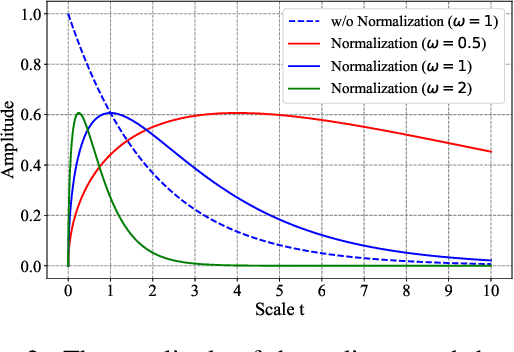
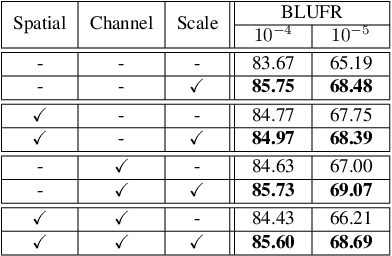
Human face images usually appear with wide range of visual scales. The existing face representations pursue the bandwidth of handling scale variation via multi-scale scheme that assembles a finite series of predefined scales. Such multi-shot scheme brings inference burden, and the predefined scales inevitably have gap from real data. Instead, learning scale parameters from data, and using them for one-shot feature inference, is a decent solution. To this end, we reform the conv layer by resorting to the scale-space theory, and achieve two-fold facilities: 1) the conv layer learns a set of scales from real data distribution, each of which is fulfilled by a conv kernel; 2) the layer automatically highlights the feature at the proper channel and location corresponding to the input pattern scale and its presence. Then, we accomplish the hierarchical scale attention by stacking the reformed layers, building a novel style named SCale AttentioN Conv Neural Network (\textbf{SCAN-CNN}). We apply SCAN-CNN to the face recognition task and push the frontier of SOTA performance. The accuracy gain is more evident when the face images are blurry. Meanwhile, as a single-shot scheme, the inference is more efficient than multi-shot fusion. A set of tools are made to ensure the fast training of SCAN-CNN and zero increase of inference cost compared with the plain CNN.
Generalized One-shot Domain Adaption of Generative Adversarial Networks
Sep 08, 2022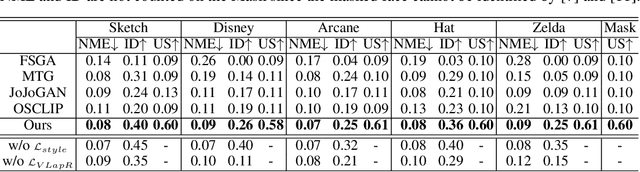
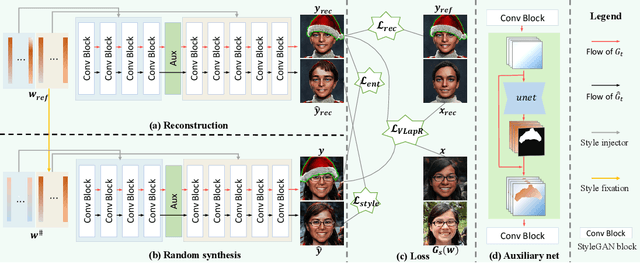

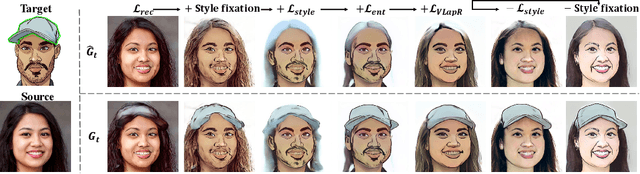
The adaption of Generative Adversarial Network (GAN) aims to transfer a pre-trained GAN to a given domain with limited training data. In this paper, we focus on the one-shot case, which is more challenging and rarely explored in previous works. We consider that the adaptation from source domain to target domain can be decoupled into two parts: the transfer of global style like texture and color, and the emergence of new entities that do not belong to the source domain. While previous works mainly focus on the style transfer, we propose a novel and concise framework\footnote{\url{https://github.com/thevoidname/Generalized-One-shot-GAN-Adaption}} to address the \textit{generalized one-shot adaption} task for both style and entity transfer, in which a reference image and its binary entity mask are provided. Our core objective is to constrain the gap between the internal distributions of the reference and syntheses by sliced Wasserstein distance. To better achieve it, style fixation is used at first to roughly obtain the exemplary style, and an auxiliary network is introduced to the original generator to disentangle entity and style transfer. Besides, to realize cross-domain correspondence, we propose the variational Laplacian regularization to constrain the smoothness of the adapted generator. Both quantitative and qualitative experiments demonstrate the effectiveness of our method in various scenarios.
DPTDR: Deep Prompt Tuning for Dense Passage Retrieval
Aug 24, 2022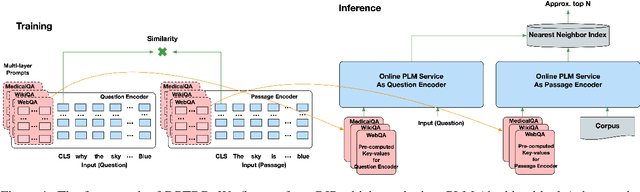

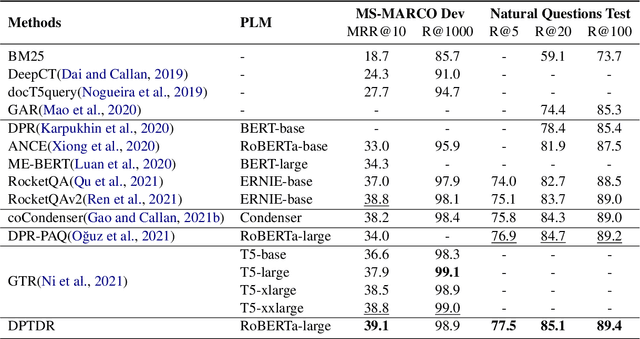
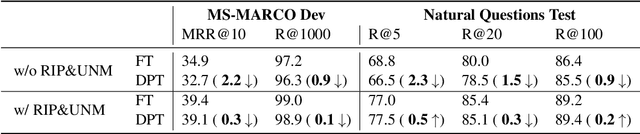
Deep prompt tuning (DPT) has gained great success in most natural language processing~(NLP) tasks. However, it is not well-investigated in dense retrieval where fine-tuning~(FT) still dominates. When deploying multiple retrieval tasks using the same backbone model~(e.g., RoBERTa), FT-based methods are unfriendly in terms of deployment cost: each new retrieval model needs to repeatedly deploy the backbone model without reuse. To reduce the deployment cost in such a scenario, this work investigates applying DPT in dense retrieval. The challenge is that directly applying DPT in dense retrieval largely underperforms FT methods. To compensate for the performance drop, we propose two model-agnostic and task-agnostic strategies for DPT-based retrievers, namely retrieval-oriented intermediate pretraining and unified negative mining, as a general approach that could be compatible with any pre-trained language model and retrieval task. The experimental results show that the proposed method (called DPTDR) outperforms previous state-of-the-art models on both MS-MARCO and Natural Questions. We also conduct ablation studies to examine the effectiveness of each strategy in DPTDR. We believe this work facilitates the industry, as it saves enormous efforts and costs of deployment and increases the utility of computing resources. Our code is available at https://github.com/tangzhy/DPTDR.