 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing Text-to-Image Diffusion Prior for Zero-Shot Image Captioning
Dec 31, 2024Recently, zero-shot image captioning has gained increasing attention, where only text data is available for training. The remarkable progress in text-to-image diffusion model presents the potential to resolve this task by employing synthetic image-caption pairs generated by this pre-trained prior. Nonetheless, the defective details in the salient regions of the synthetic images introduce semantic misalignment between the synthetic image and text, leading to compromised results. To address this challenge, we propose a novel Patch-wise Cross-modal feature Mix-up (PCM) mechanism to adaptively mitigate the unfaithful contents in a fine-grained manner during training, which can be integrated into most of encoder-decoder frameworks, introducing our PCM-Net. Specifically, for each input image, salient visual concepts in the image are first detected considering the image-text similarity in CLIP space. Next, the patch-wise visual features of the input image are selectively fused with the textual features of the salient visual concepts, leading to a mixed-up feature map with less defective content. Finally, a visual-semantic encoder is exploited to refine the derived feature map, which is further incorporated into the sentence decoder for caption generation. Additionally, to facilitate the model training with synthetic data, a novel CLIP-weighted cross-entropy loss is devised to prioritize the high-quality image-text pairs over the low-quality counterparts. Extensive experiments on MSCOCO and Flickr30k datasets demonstrate the superiority of our PCM-Net compared with state-of-the-art VLMs-based approaches. It is noteworthy that our PCM-Net ranks first in both in-domain and cross-domain zero-shot image captioning. The synthetic dataset SynthImgCap and code are available at https://jianjieluo.github.io/SynthImgCap.
Semantic-Conditional Diffusion Networks for Image Captioning
Dec 06, 2022Recent advances on text-to-image generation have witnessed the rise of diffusion models which act as powerful generative models. Nevertheless, it is not trivial to exploit such latent variable models to capture the dependency among discrete words and meanwhile pursue complex visual-language alignment in image captioning. In this paper, we break the deeply rooted conventions in learning Transformer-based encoder-decoder, and propose a new diffusion model based paradigm tailored for image captioning, namely Semantic-Conditional Diffusion Networks (SCD-Net). Technically, for each input image, we first search the semantically relevant sentences via cross-modal retrieval model to convey the comprehensive semantic information. The rich semantics are further regarded as semantic prior to trigger the learning of Diffusion Transformer, which produces the output sentence in a diffusion process. In SCD-Net, multiple Diffusion Transformer structures are stacked to progressively strengthen the output sentence with better visional-language alignment and linguistical coherence in a cascaded manner. Furthermore, to stabilize the diffusion process, a new self-critical sequence training strategy is designed to guide the learning of SCD-Net with the knowledge of a standard autoregressive Transformer model. Extensive experiments on COCO dataset demonstrate the promising potential of using diffusion models in the challenging image captioning task. Source code is available at \url{https://github.com/YehLi/xmodaler/tree/master/configs/image_caption/scdnet}.
CoCo-BERT: Improving Video-Language Pre-training with Contrastive Cross-modal Matching and Denoising
Dec 14, 2021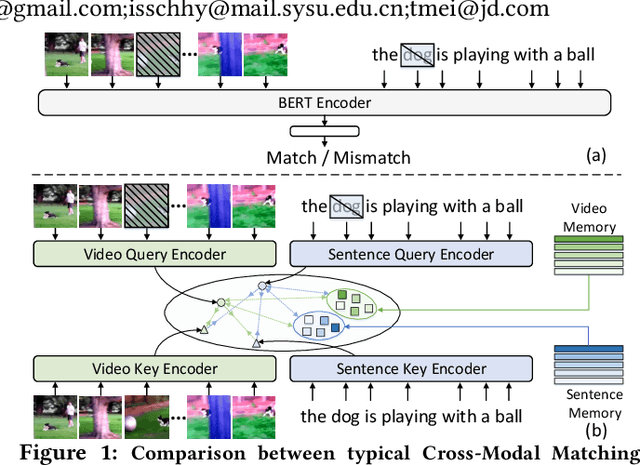
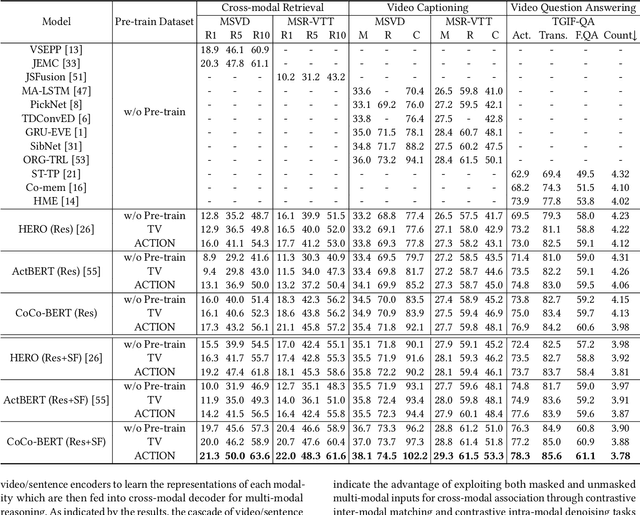
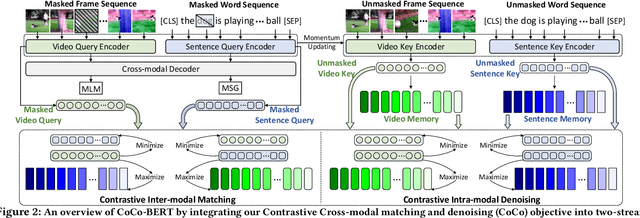
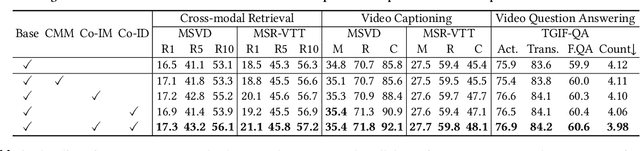
BERT-type structure has led to the revolution of vision-language pre-training and the achievement of state-of-the-art results on numerous vision-language downstream tasks. Existing solutions dominantly capitalize on the multi-modal inputs with mask tokens to trigger mask-based proxy pre-training tasks (e.g., masked language modeling and masked object/frame prediction). In this work, we argue that such masked inputs would inevitably introduce noise for cross-modal matching proxy task, and thus leave the inherent vision-language association under-explored. As an alternative, we derive a particular form of cross-modal proxy objective for video-language pre-training, i.e., Contrastive Cross-modal matching and denoising (CoCo). By viewing the masked frame/word sequences as the noisy augmentation of primary unmasked ones, CoCo strengthens video-language association by simultaneously pursuing inter-modal matching and intra-modal denoising between masked and unmasked inputs in a contrastive manner. Our CoCo proxy objective can be further integrated into any BERT-type encoder-decoder structure for video-language pre-training, named as Contrastive Cross-modal BERT (CoCo-BERT). We pre-train CoCo-BERT on TV dataset and a newly collected large-scale GIF video dataset (ACTION). Through extensive experiments over a wide range of downstream tasks (e.g., cross-modal retrieval, video question answering, and video captioning), we demonstrate the superiority of CoCo-BERT as a pre-trained structure.
Auto-captions on GIF: A Large-scale Video-sentence Dataset for Vision-language Pre-training
Jul 05, 2020
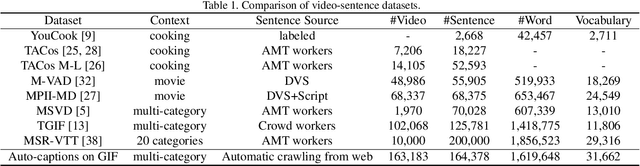
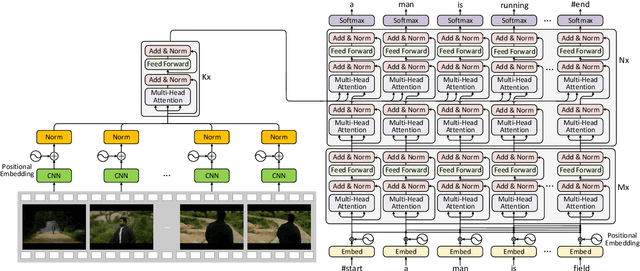
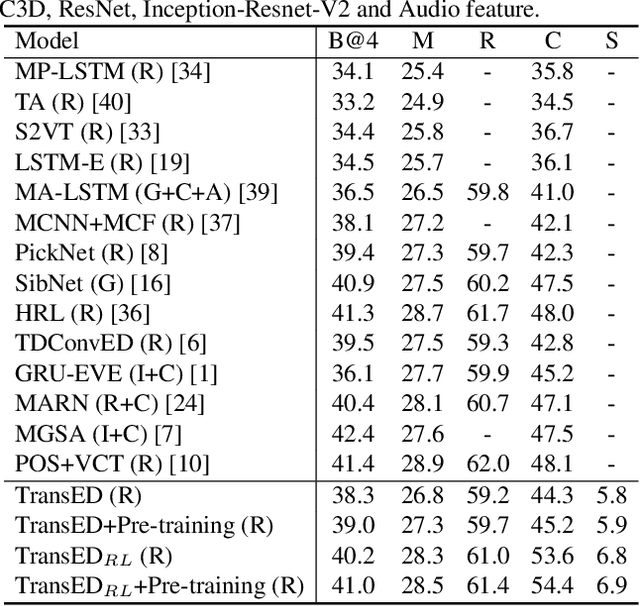
In this work, we present Auto-captions on GIF, which is a new large-scale pre-training dataset for generic video understanding. All video-sentence pairs are created by automatically extracting and filtering video caption annotations from billions of web pages. Auto-captions on GIF dataset can be utilized to pre-train the generic feature representation or encoder-decoder structure for video captioning, and other downstream tasks (e.g., sentence localization in videos, video question answering, etc.) as well. We present a detailed analysis of Auto-captions on GIF dataset in comparison to existing video-sentence datasets. We also provide an evaluation of a Transformer-based encoder-decoder structure for vision-language pre-training, which is further adapted to video captioning downstream task and yields the compelling generalizability on MSR-VTT. The dataset is available at \url{http://www.auto-video-captions.top/2020/dataset}.