 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTMSTC*: A Turn-minimizing Algorithm For Multi-robot Coverage Path Planning
Dec 05, 2022



Coverage path planning is a major application for mobile robots, which requires robots to move along a planned path to cover the entire map. For large-scale tasks, coverage path planning benefits greatly from multiple robots. In this paper, we describe Turn-minimizing Multirobot Spanning Tree Coverage Star(TMSTC*), an improved multirobot coverage path planning (mCPP) algorithm based on the MSTC*. Our algorithm partitions the map into minimum bricks as tree's branches and thereby transforms the problem into finding the maximum independent set of bipartite graph. We then connect bricks with greedy strategy to form a tree, aiming to reduce the number of turns of corresponding circumnavigating coverage path. Our experimental results show that our approach enables multiple robots to make fewer turns and thus complete terrain coverage tasks faster than other popular algorithms.
MultiRoboLearn: An open-source Framework for Multi-robot Deep Reinforcement Learning
Sep 28, 2022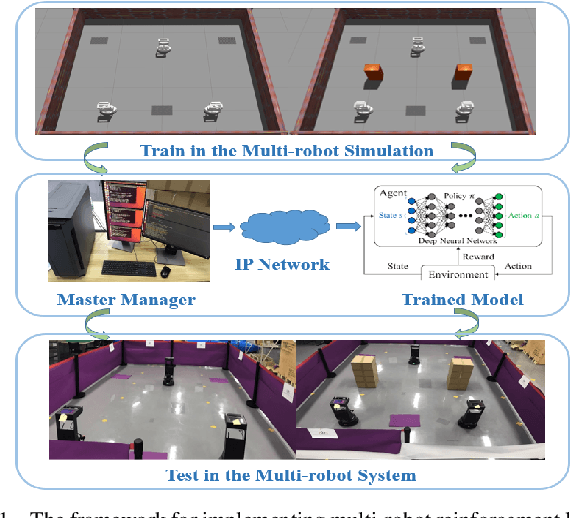
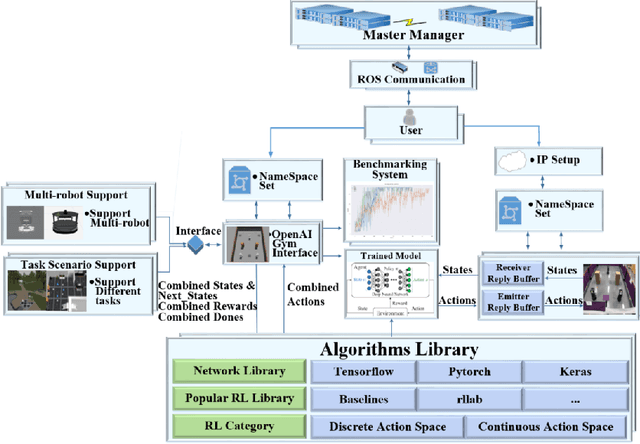
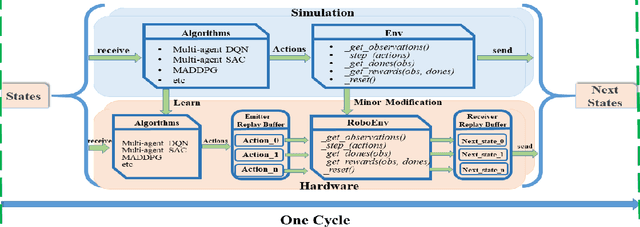
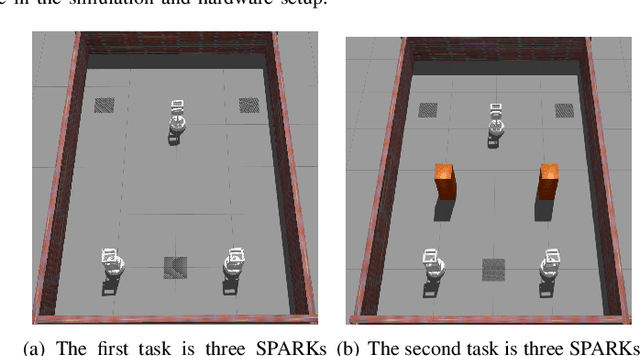
It is well known that it is difficult to have a reliable and robust framework to link multi-agent deep reinforcement learning algorithms with practical multi-robot applications. To fill this gap, we propose and build an open-source framework for multi-robot systems called MultiRoboLearn1. This framework builds a unified setup of simulation and real-world applications. It aims to provide standard, easy-to-use simulated scenarios that can also be easily deployed to real-world multi-robot environments. Also, the framework provides researchers with a benchmark system for comparing the performance of different reinforcement learning algorithms. We demonstrate the generality, scalability, and capability of the framework with two real-world scenarios2 using different types of multi-agent deep reinforcement learning algorithms in discrete and continuous action spaces.
Progressive Self-Distillation for Ground-to-Aerial Perception Knowledge Transfer
Aug 29, 2022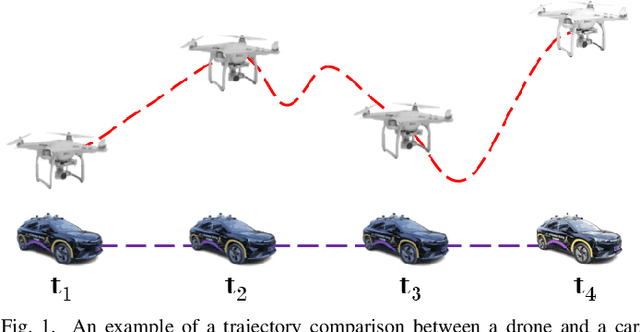
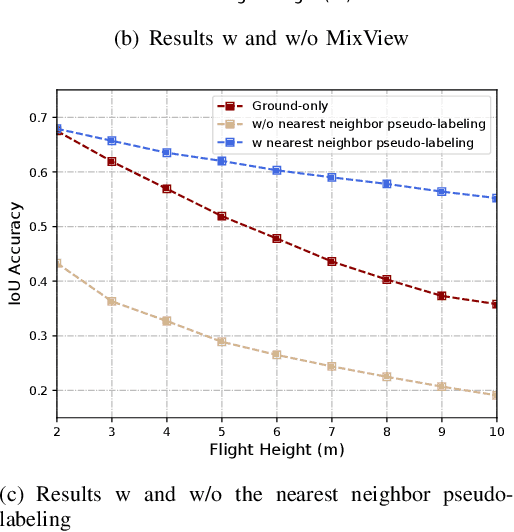
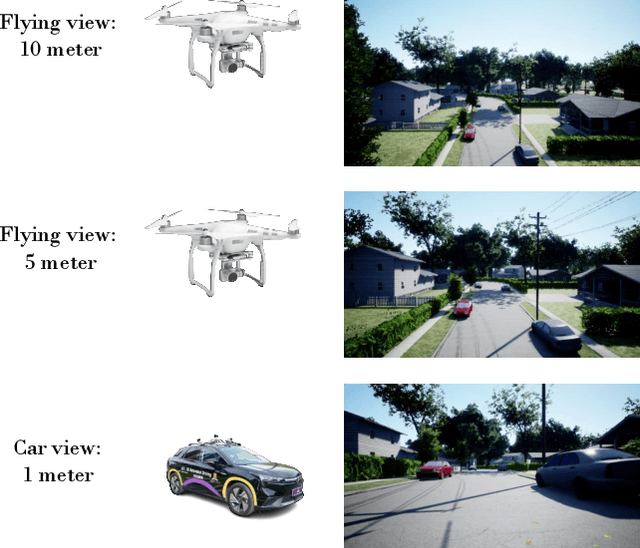
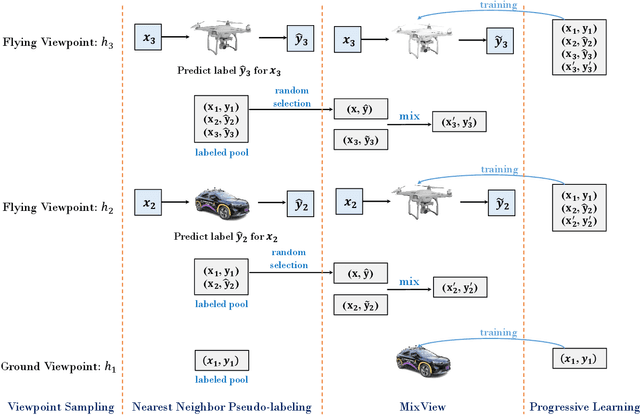
We study a practical yet hasn't been explored problem: how a drone can perceive in an environment from viewpoints of different flight heights. Unlike autonomous driving where the perception is always conducted from a ground viewpoint, a flying drone may flexibly change its flight height due to specific tasks, requiring capability for viewpoint invariant perception. To reduce the effort of annotation of flight data, we consider a ground-to-aerial knowledge distillation method while using only labeled data of ground viewpoint and unlabeled data of flying viewpoints. To this end, we propose a progressive semi-supervised learning framework which has four core components: a dense viewpoint sampling strategy that splits the range of vertical flight height into a set of small pieces with evenly-distributed intervals, and at each height we sample data from that viewpoint; the nearest neighbor pseudo-labeling that infers labels of the nearest neighbor viewpoint with a model learned on the preceding viewpoint; MixView that generates augmented images among different viewpoints to alleviate viewpoint difference; and a progressive distillation strategy to gradually learn until reaching the maximum flying height. We collect a synthesized dataset and a real-world dataset, and we perform extensive experiments to show that our method yields promising results for different flight heights.
Data-free Dense Depth Distillation
Aug 26, 2022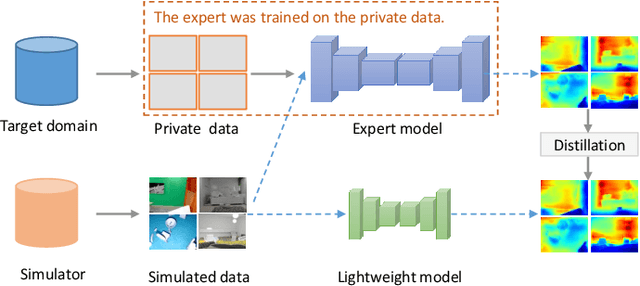
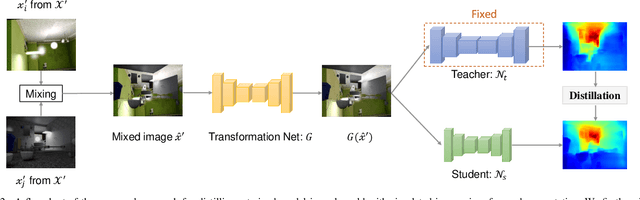

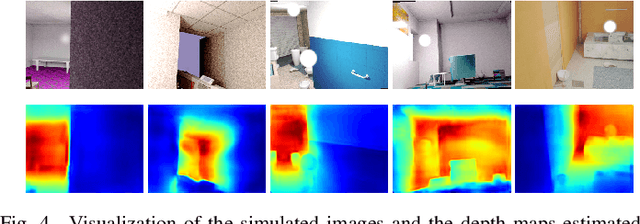
We study data-free knowledge distillation (KD) for monocular depth estimation (MDE), which learns a lightweight network for real-world depth perception by compressing from a trained expert model under the teacher-student framework while lacking training data in the target domain. Owing to the essential difference between dense regression and image recognition, previous methods of data-free KD are not applicable to MDE. To strengthen the applicability in the real world, in this paper, we seek to apply KD with out-of-distribution simulated images. The major challenges are i) lacking prior information about object distribution of the original training data; ii) the domain shift between the real world and the simulation. To cope with the first difficulty, we apply object-wise image mixing to generate new training samples for maximally covering distributed patterns of objects in the target domain. To tackle the second difficulty, we propose to utilize a transformation network that efficiently learns to fit the simulated data to the feature distribution of the teacher model. We evaluate the proposed approach for various depth estimation models and two different datasets. As a result, our method outperforms the baseline KD by a good margin and even achieves slightly better performance with as few as $1/6$ images, demonstrating a clear superiority.
Context-aware Mixture-of-Experts for Unbiased Scene Graph Generation
Aug 21, 2022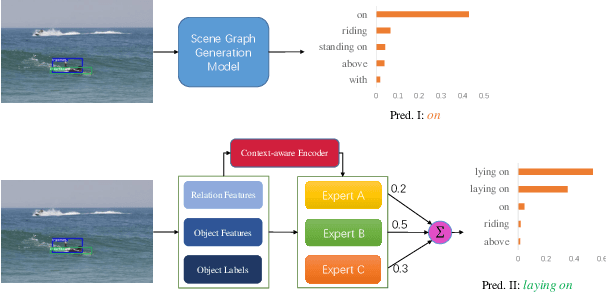
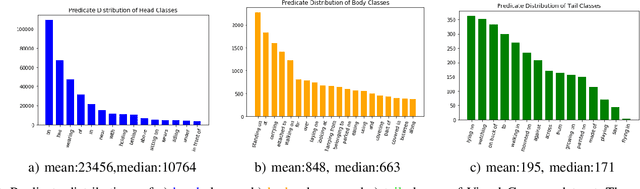
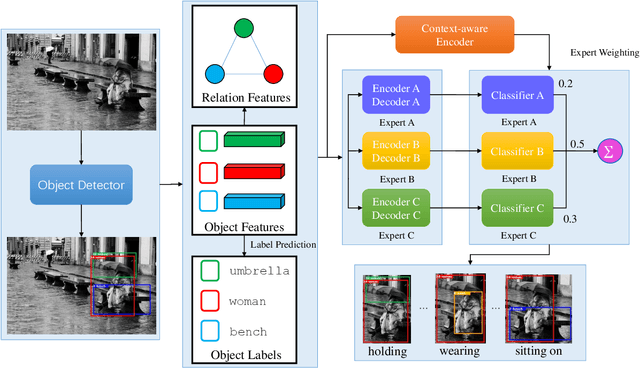
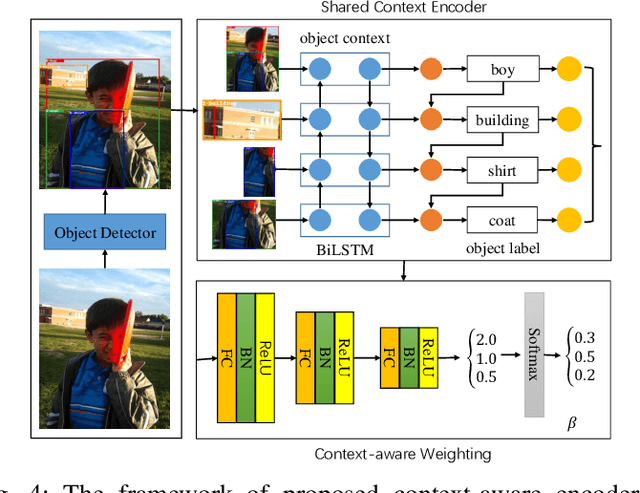
The scene graph generation has gained tremendous progress in recent years. However, its intrinsic long-tailed distribution of predicate classes is a challenging problem. Almost all existing scene graph generation (SGG) methods follow the same framework where they use a similar backbone network for object detection and a customized network for scene graph generation. These methods often design the sophisticated context-encoder to extract the inherent relevance of scene context w.r.t the intrinsic predicates and complicated networks to improve the learning capabilities of the network model for highly imbalanced data distributions. To address the unbiased SGG problem, we present a simple yet effective method called Context-Aware Mixture-of-Experts (CAME) to improve the model diversity and alleviate the biased SGG without a sophisticated design. Specifically, we propose to use the mixture of experts to remedy the heavily long-tailed distributions of predicate classes, which is suitable for most unbiased scene graph generators. With a mixture of relation experts, the long-tailed distribution of predicates is addressed in a divide and ensemble manner. As a result, the biased SGG is mitigated and the model tends to make more balanced predicates predictions. However, experts with the same weight are not sufficiently diverse to discriminate the different levels of predicates distributions. Hence, we simply use the build-in context-aware encoder, to help the network dynamically leverage the rich scene characteristics to further increase the diversity of the model. By utilizing the context information of the image, the importance of each expert w.r.t the scene context is dynamically assigned. We have conducted extensive experiments on three tasks on the Visual Genome dataset to show that came achieved superior performance over previous methods.
Learning to Coordinate for a Worker-Station Multi-robot System in Planar Coverage Tasks
Aug 05, 2022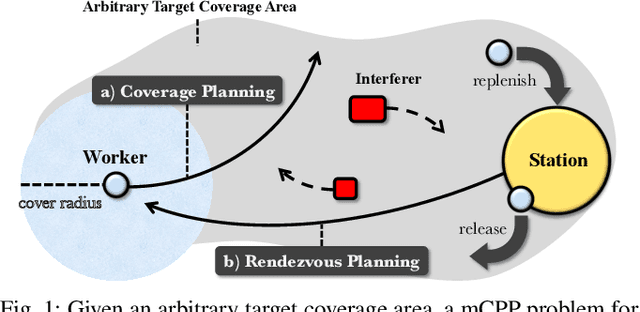
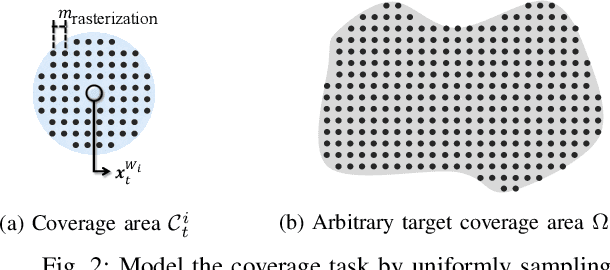
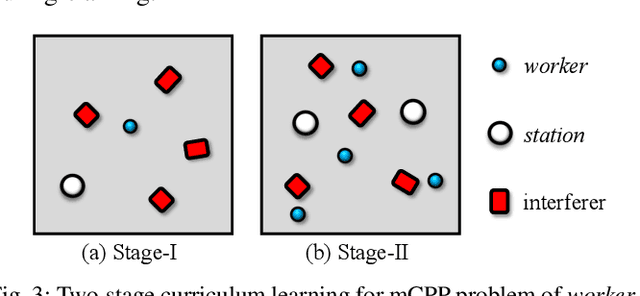
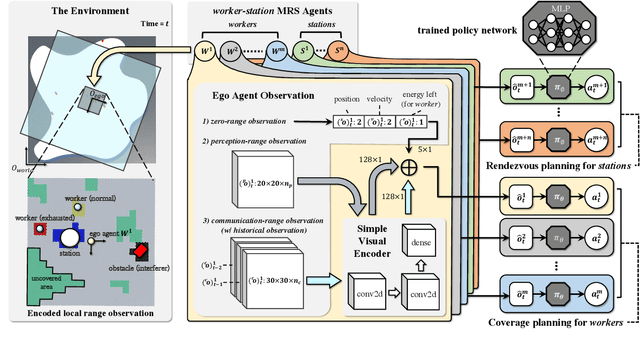
For massive large-scale tasks, a multi-robot system (MRS) can effectively improve efficiency by utilizing each robot's different capabilities, mobility, and functionality. In this paper, we focus on the multi-robot coverage path planning (mCPP) problem in large-scale planar areas with random dynamic interferers in the environment, where the robots have limited resources. We introduce a worker-station MRS consisting of multiple workers with limited resources for actual work, and one station with enough resources for resource replenishment. We aim to solve the mCPP problem for the worker-station MRS by formulating it as a fully cooperative multi-agent reinforcement learning problem. Then we propose an end-to-end decentralized online planning method, which simultaneously solves coverage planning for workers and rendezvous planning for station. Our method manages to reduce the influence of random dynamic interferers on planning, while the robots can avoid collisions with them. We conduct simulation and real robot experiments, and the comparison results show that our method has competitive performance in solving the mCPP problem for worker-station MRS in metric of task finish time.
Feature Pyramid Attention based Residual Neural Network for Environmental Sound Classification
May 28, 2022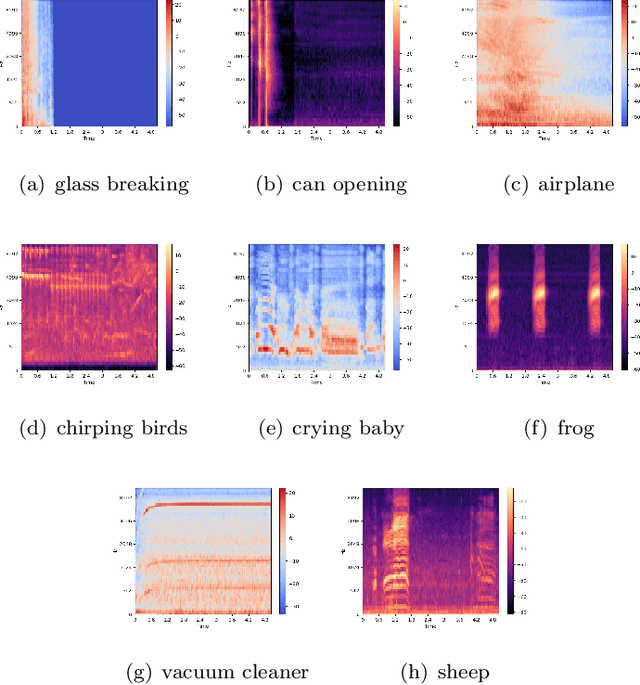
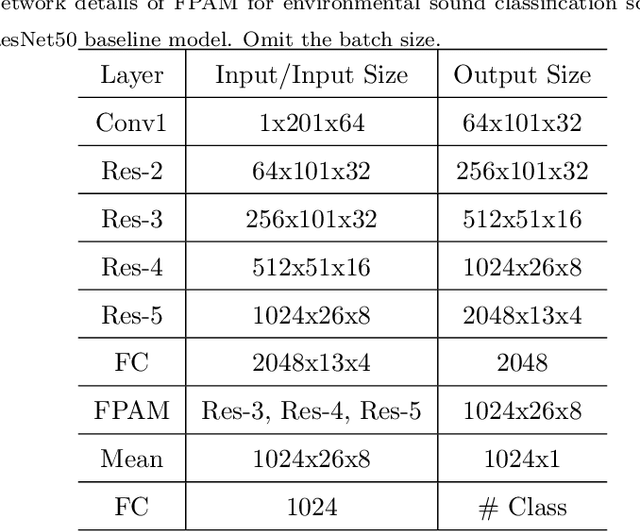
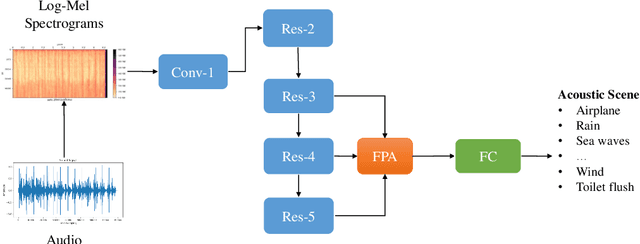
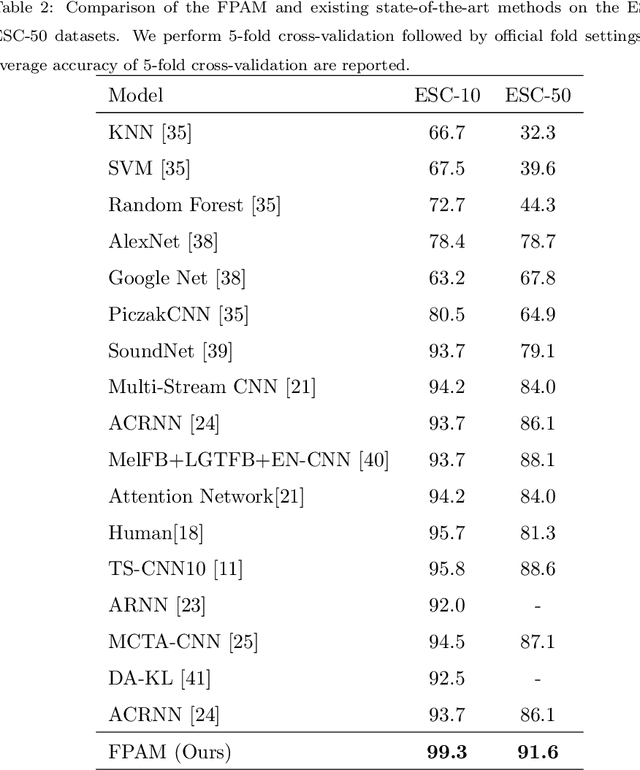
Environmental sound classification (ESC) is a challenging problem due to the unstructured spatial-temporal relations that exist in the sound signals. Recently, many studies have focused on abstracting features from convolutional neural networks while the learning of semantically relevant frames of sound signals has been overlooked. To this end, we present an end-to-end framework, namely feature pyramid attention network (FPAM), focusing on abstracting the semantically relevant features for ESC. We first extract the feature maps of the preprocessed spectrogram of the sound waveform by a backbone network. Then, to build multi-scale hierarchical features of sound spectrograms, we construct a feature pyramid representation of the sound spectrograms by aggregating the feature maps from multi-scale layers, where the temporal frames and spatial locations of semantically relevant frames are localized by FPAM. Specifically, the multiple features are first processed by a dimension alignment module. Afterward, the pyramid spatial attention module (PSA) is attached to localize the important frequency regions spatially with a spatial attention module (SAM). Last, the processed feature maps are refined by a pyramid channel attention (PCA) to localize the important temporal frames. To justify the effectiveness of the proposed FPAM, visualization of attention maps on the spectrograms has been presented. The visualization results show that FPAM can focus more on the semantic relevant regions while neglecting the noises. The effectiveness of the proposed methods is validated on two widely used ESC datasets: the ESC-50 and ESC-10 datasets. The experimental results show that the FPAM yields comparable performance to state-of-the-art methods. A substantial performance increase has been achieved by FPAM compared with the baseline methods.
Deep Depth Completion: A Survey
May 17, 2022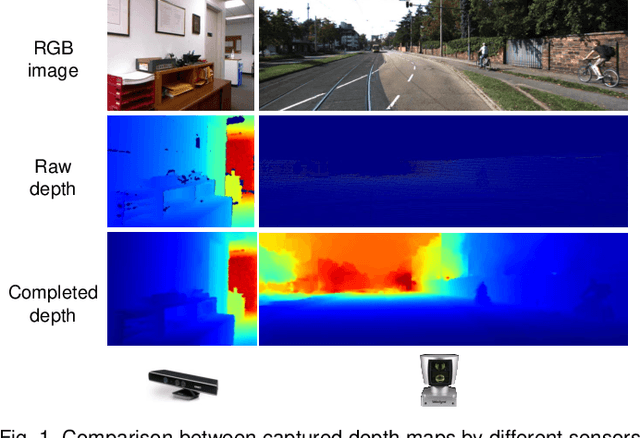
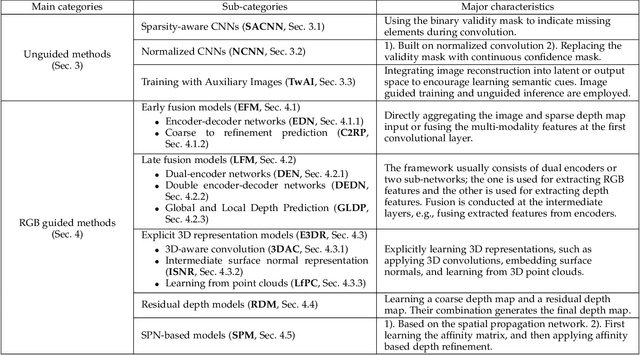
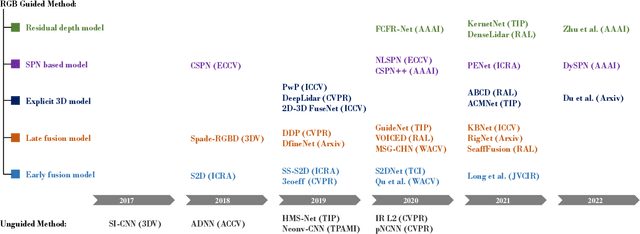
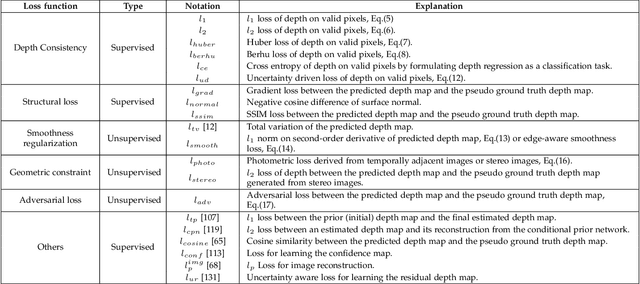
Depth completion aims at predicting dense pixel-wise depth from a sparse map captured from a depth sensor. It plays an essential role in various applications such as autonomous driving, 3D reconstruction, augmented reality, and robot navigation. Recent successes on the task have been demonstrated and dominated by deep learning based solutions. In this article, for the first time, we provide a comprehensive literature review that helps readers better grasp the research trends and clearly understand the current advances. We investigate the related studies from the design aspects of network architectures, loss functions, benchmark datasets, and learning strategies with a proposal of a novel taxonomy that categorizes existing methods. Besides, we present a quantitative comparison of model performance on two widely used benchmark datasets, including an indoor and an outdoor dataset. Finally, we discuss the challenges of prior works and provide readers with some insights for future research directions.
RGB-D SLAM in Indoor Planar Environments with Multiple Large Dynamic Objects
Mar 06, 2022
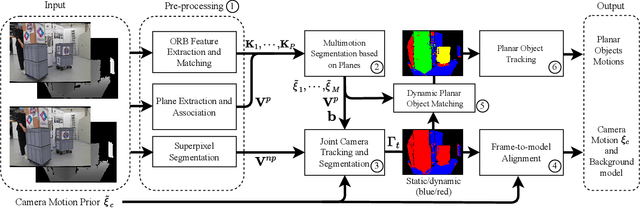

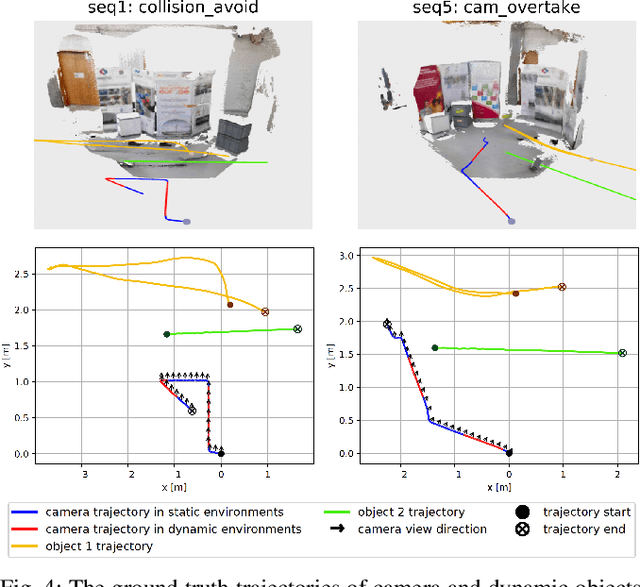
This work presents a novel dense RGB-D SLAM approach for dynamic planar environments that enables simultaneous multi-object tracking, camera localisation and background reconstruction. Previous dynamic SLAM methods either rely on semantic segmentation to directly detect dynamic objects; or assume that dynamic objects occupy a smaller proportion of the camera view than the static background and can, therefore, be removed as outliers. Our approach, however, enables dense SLAM when the camera view is largely occluded by multiple dynamic objects with the aid of camera motion prior. The dynamic planar objects are separated by their different rigid motions and tracked independently. The remaining dynamic non-planar areas are removed as outliers and not mapped into the background. The evaluation demonstrates that our approach outperforms the state-of-the-art methods in terms of localisation, mapping, dynamic segmentation and object tracking. We also demonstrate its robustness to large drift in the camera motion prior.
Abnormal Occupancy Grid Map Recognition using Attention Network
Oct 18, 2021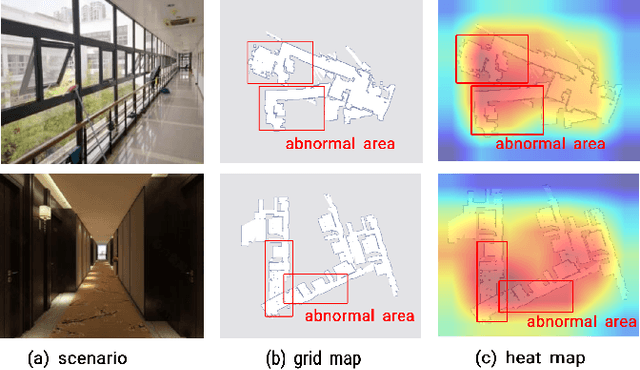
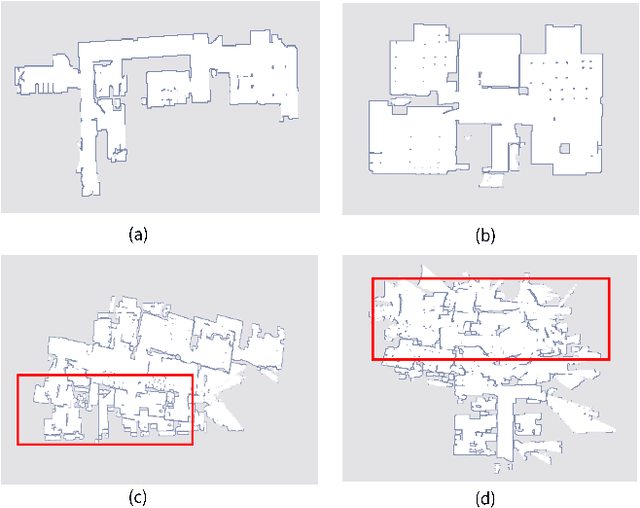
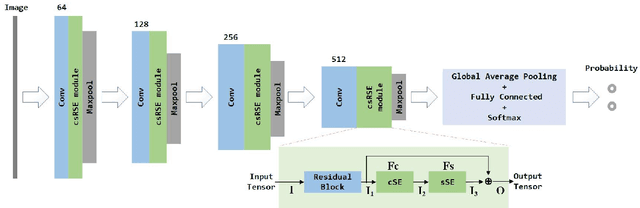

The occupancy grid map is a critical component of autonomous positioning and navigation in the mobile robotic system, as many other systems' performance depends heavily on it. To guarantee the quality of the occupancy grid maps, researchers previously had to perform tedious manual recognition for a long time. This work focuses on automatic abnormal occupancy grid map recognition using the residual neural networks and a novel attention mechanism module. We propose an effective channel and spatial Residual SE(csRSE) attention module, which contains a residual block for producing hierarchical features, followed by both channel SE (cSE) block and spatial SE (sSE) block for the sufficient information extraction along the channel and spatial pathways. To further summarize the occupancy grid map characteristics and experiment with our csRSE attention modules, we constructed a dataset called occupancy grid map dataset (OGMD) for our experiments. On this OGMD test dataset, we tested few variants of our proposed structure and compared them with other attention mechanisms. Our experimental results show that the proposed attention network can infer the abnormal map with state-of-the-art (SOTA) accuracy of 96.23% for abnormal occupancy grid map recognition.