 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Image Generation: A Comprehensive Survey
Dec 17, 2022Image and video synthesis has become a blooming topic in computer vision and machine learning communities along with the developments of deep generative models, due to its great academic and application value. Many researchers have been devoted to synthesizing high-fidelity human images as one of the most commonly seen object categories in daily lives, where a large number of studies are performed based on various deep generative models, task settings and applications. Thus, it is necessary to give a comprehensive overview on these variant methods on human image generation. In this paper, we divide human image generation techniques into three paradigms, i.e., data-driven methods, knowledge-guided methods and hybrid methods. For each route, the most representative models and the corresponding variants are presented, where the advantages and characteristics of different methods are summarized in terms of model architectures and input/output requirements. Besides, the main public human image datasets and evaluation metrics in the literature are also summarized. Furthermore, due to the wide application potentials, two typical downstream usages of synthesized human images are covered, i.e., data augmentation for person recognition tasks and virtual try-on for fashion customers. Finally, we discuss the challenges and potential directions of human image generation to shed light on future research.
BEVBert: Topo-Metric Map Pre-training for Language-guided Navigation
Dec 08, 2022Existing approaches for vision-and-language navigation (VLN) are mainly based on cross-modal reasoning over discrete views. However, this scheme may hamper an agent's spatial and numerical reasoning because of incomplete objects within a single view and duplicate observations across views. A potential solution is mapping discrete views into a unified birds's-eye view, which can aggregate partial and duplicate observations. Existing metric maps could achieve this goal, but they suffer from less expressive semantics (e.g. usually predefined labels) and limited map size, which weakens an agent's language grounding and long-term planning ability. Inspired by the robotics community, we introduce hybrid topo-metric maps into VLN, where a topological map is used for long-term planning and a metric map for short-term reasoning. Beyond mapping with more expressive deep features, we further design a pre-training framework via the hybrid map to learn language-informed map representations, which enhances cross-modal grounding and facilitates the final language-guided navigation goal. Extensive experiments demonstrate the effectiveness of the map-based route for VLN, and the proposed method sets the new state-of-the-art on three VLN benchmarks.
Semantic-aware One-shot Face Re-enactment with Dense Correspondence Estimation
Nov 23, 2022



One-shot face re-enactment is a challenging task due to the identity mismatch between source and driving faces. Specifically, the suboptimally disentangled identity information of driving subjects would inevitably interfere with the re-enactment results and lead to face shape distortion. To solve this problem, this paper proposes to use 3D Morphable Model (3DMM) for explicit facial semantic decomposition and identity disentanglement. Instead of using 3D coefficients alone for re-enactment control, we take the advantage of the generative ability of 3DMM to render textured face proxies. These proxies contain abundant yet compact geometric and semantic information of human faces, which enable us to compute the face motion field between source and driving images by estimating the dense correspondence. In this way, we could approximate re-enactment results by warping source images according to the motion field, and a Generative Adversarial Network (GAN) is adopted to further improve the visual quality of warping results. Extensive experiments on various datasets demonstrate the advantages of the proposed method over existing start-of-the-art benchmarks in both identity preservation and re-enactment fulfillment.
Vision Transformer with Super Token Sampling
Nov 21, 2022Vision transformer has achieved impressive performance for many vision tasks. However, it may suffer from high redundancy in capturing local features for shallow layers. Local self-attention or early-stage convolutions are thus utilized, which sacrifice the capacity to capture long-range dependency. A challenge then arises: can we access efficient and effective global context modeling at the early stages of a neural network? To address this issue, we draw inspiration from the design of superpixels, which reduces the number of image primitives in subsequent processing, and introduce super tokens into vision transformer. Super tokens attempt to provide a semantically meaningful tessellation of visual content, thus reducing the token number in self-attention as well as preserving global modeling. Specifically, we propose a simple yet strong super token attention (STA) mechanism with three steps: the first samples super tokens from visual tokens via sparse association learning, the second performs self-attention on super tokens, and the last maps them back to the original token space. STA decomposes vanilla global attention into multiplications of a sparse association map and a low-dimensional attention, leading to high efficiency in capturing global dependencies. Based on STA, we develop a hierarchical vision transformer. Extensive experiments demonstrate its strong performance on various vision tasks. In particular, without any extra training data or label, it achieves 86.4% top-1 accuracy on ImageNet-1K with less than 100M parameters. It also achieves 53.9 box AP and 46.8 mask AP on the COCO detection task, and 51.9 mIOU on the ADE20K semantic segmentation task. Code will be released at https://github.com/hhb072/SViT.
HumanDiffusion: a Coarse-to-Fine Alignment Diffusion Framework for Controllable Text-Driven Person Image Generation
Nov 11, 2022



Text-driven person image generation is an emerging and challenging task in cross-modality image generation. Controllable person image generation promotes a wide range of applications such as digital human interaction and virtual try-on. However, previous methods mostly employ single-modality information as the prior condition (e.g. pose-guided person image generation), or utilize the preset words for text-driven human synthesis. Introducing a sentence composed of free words with an editable semantic pose map to describe person appearance is a more user-friendly way. In this paper, we propose HumanDiffusion, a coarse-to-fine alignment diffusion framework, for text-driven person image generation. Specifically, two collaborative modules are proposed, the Stylized Memory Retrieval (SMR) module for fine-grained feature distillation in data processing and the Multi-scale Cross-modality Alignment (MCA) module for coarse-to-fine feature alignment in diffusion. These two modules guarantee the alignment quality of the text and image, from image-level to feature-level, from low-resolution to high-resolution. As a result, HumanDiffusion realizes open-vocabulary person image generation with desired semantic poses. Extensive experiments conducted on DeepFashion demonstrate the superiority of our method compared with previous approaches. Moreover, better results could be obtained for complicated person images with various details and uncommon poses.
Pointly-Supervised Panoptic Segmentation
Oct 25, 2022In this paper, we propose a new approach to applying point-level annotations for weakly-supervised panoptic segmentation. Instead of the dense pixel-level labels used by fully supervised methods, point-level labels only provide a single point for each target as supervision, significantly reducing the annotation burden. We formulate the problem in an end-to-end framework by simultaneously generating panoptic pseudo-masks from point-level labels and learning from them. To tackle the core challenge, i.e., panoptic pseudo-mask generation, we propose a principled approach to parsing pixels by minimizing pixel-to-point traversing costs, which model semantic similarity, low-level texture cues, and high-level manifold knowledge to discriminate panoptic targets. We conduct experiments on the Pascal VOC and the MS COCO datasets to demonstrate the approach's effectiveness and show state-of-the-art performance in the weakly-supervised panoptic segmentation problem. Codes are available at https://github.com/BraveGroup/PSPS.git.
Cross-Domain Cross-Set Few-Shot Learning via Learning Compact and Aligned Representations
Jul 16, 2022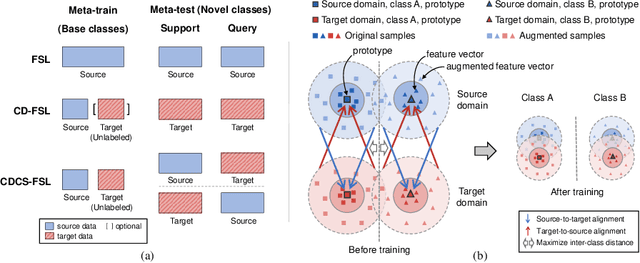
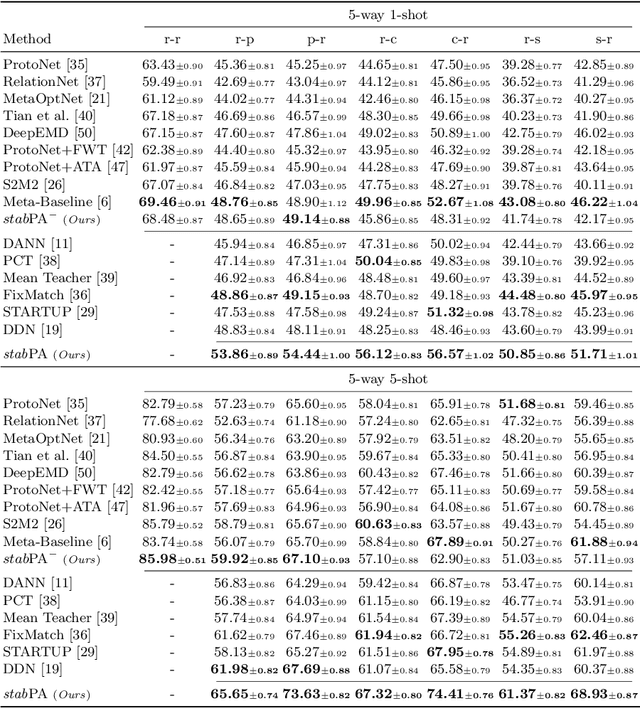
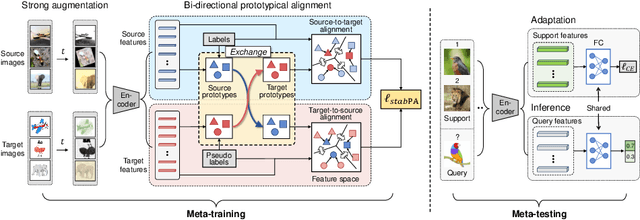
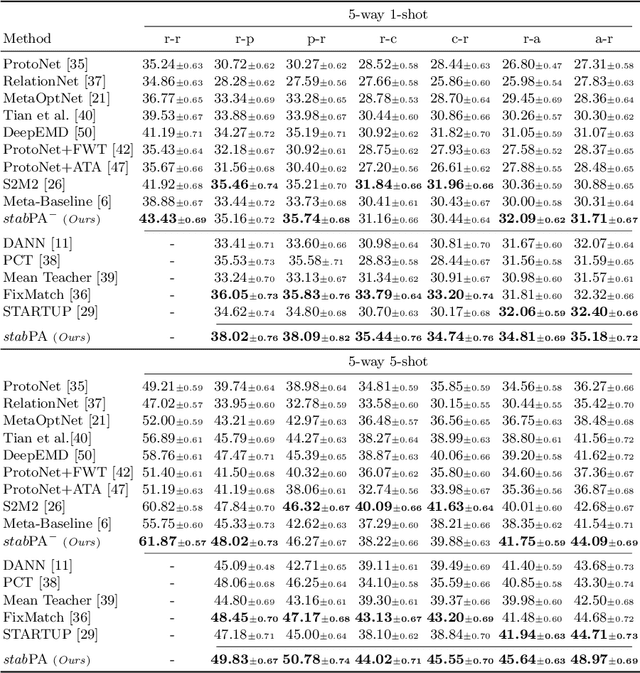
Few-shot learning (FSL) aims to recognize novel queries with only a few support samples through leveraging prior knowledge from a base dataset. In this paper, we consider the domain shift problem in FSL and aim to address the domain gap between the support set and the query set. Different from previous cross-domain FSL work (CD-FSL) that considers the domain shift between base and novel classes, the new problem, termed cross-domain cross-set FSL (CDSC-FSL), requires few-shot learners not only to adapt to the new domain, but also to be consistent between different domains within each novel class. To this end, we propose a novel approach, namely stabPA, to learn prototypical compact and cross-domain aligned representations, so that the domain shift and few-shot learning can be addressed simultaneously. We evaluate our approach on two new CDCS-FSL benchmarks built from the DomainNet and Office-Home datasets respectively. Remarkably, our approach outperforms multiple elaborated baselines by a large margin, e.g., improving 5-shot accuracy by 6.0 points on average on DomainNet. Code is available at https://github.com/WentaoChen0813/CDCS-FSL
Disentangled Federated Learning for Tackling Attributes Skew via Invariant Aggregation and Diversity Transferring
Jun 14, 2022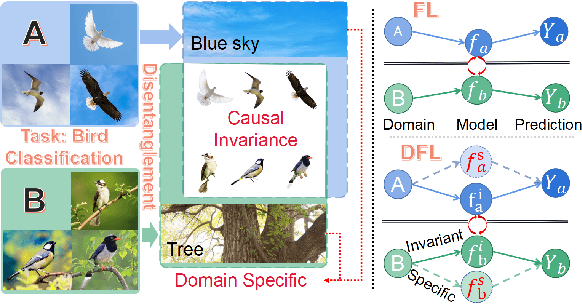

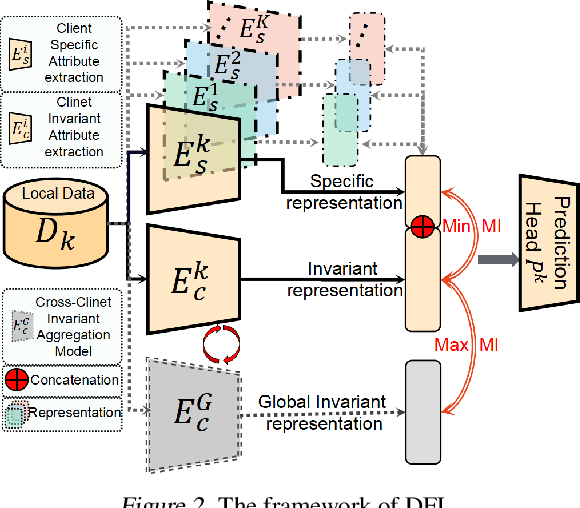
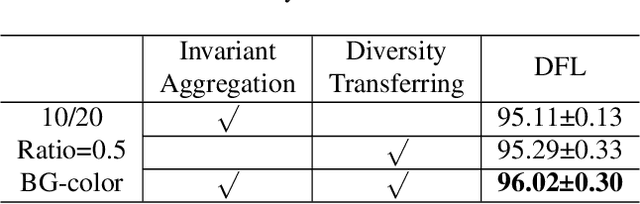
Attributes skew hinders the current federated learning (FL) frameworks from consistent optimization directions among the clients, which inevitably leads to performance reduction and unstable convergence. The core problems lie in that: 1) Domain-specific attributes, which are non-causal and only locally valid, are indeliberately mixed into global aggregation. 2) The one-stage optimizations of entangled attributes cannot simultaneously satisfy two conflicting objectives, i.e., generalization and personalization. To cope with these, we proposed disentangled federated learning (DFL) to disentangle the domain-specific and cross-invariant attributes into two complementary branches, which are trained by the proposed alternating local-global optimization independently. Importantly, convergence analysis proves that the FL system can be stably converged even if incomplete client models participate in the global aggregation, which greatly expands the application scope of FL. Extensive experiments verify that DFL facilitates FL with higher performance, better interpretability, and faster convergence rate, compared with SOTA FL methods on both manually synthesized and realistic attributes skew datasets.
Generalizable Person Re-Identification via Self-Supervised Batch Norm Test-Time Adaption
Mar 28, 2022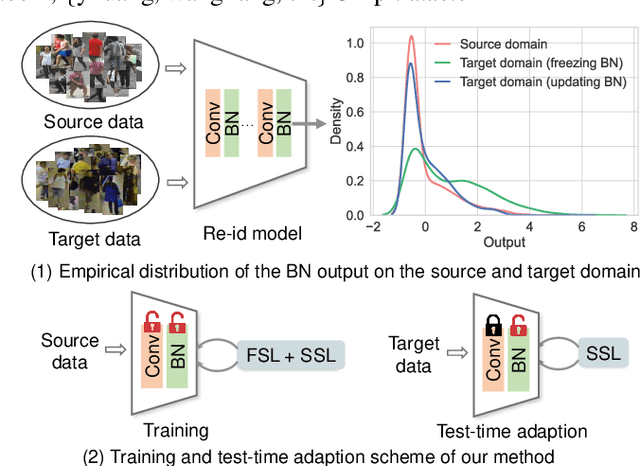
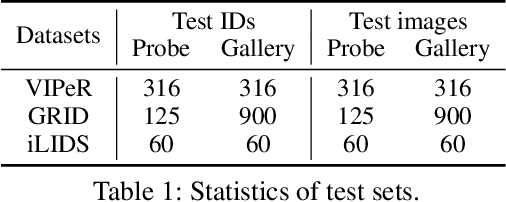
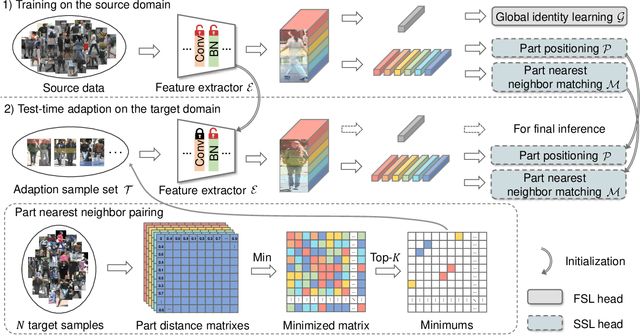
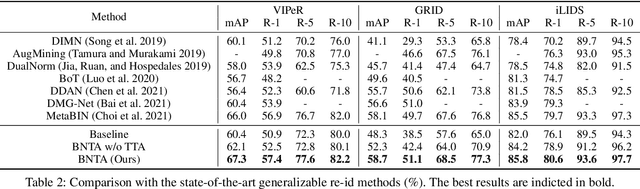
In this paper, we investigate the generalization problem of person re-identification (re-id), whose major challenge is the distribution shift on an unseen domain. As an important tool of regularizing the distribution, batch normalization (BN) has been widely used in existing methods. However, they neglect that BN is severely biased to the training domain and inevitably suffers the performance drop if directly generalized without being updated. To tackle this issue, we propose Batch Norm Test-time Adaption (BNTA), a novel re-id framework that applies the self-supervised strategy to update BN parameters adaptively. Specifically, BNTA quickly explores the domain-aware information within unlabeled target data before inference, and accordingly modulates the feature distribution normalized by BN to adapt to the target domain. This is accomplished by two designed self-supervised auxiliary tasks, namely part positioning and part nearest neighbor matching, which help the model mine the domain-aware information with respect to the structure and identity of body parts, respectively. To demonstrate the effectiveness of our method, we conduct extensive experiments on three re-id datasets and confirm the superior performance to the state-of-the-art methods.
Self-Supervised Predictive Learning: A Negative-Free Method for Sound Source Localization in Visual Scenes
Mar 25, 2022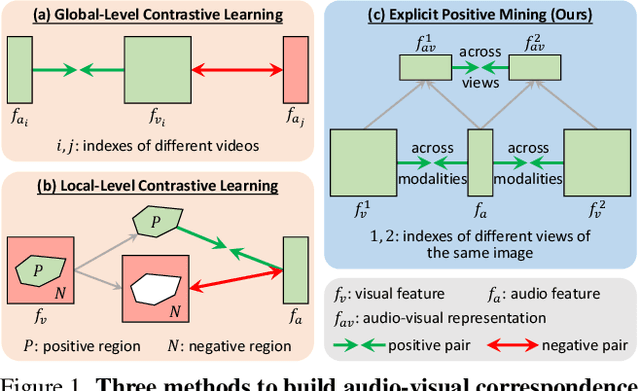
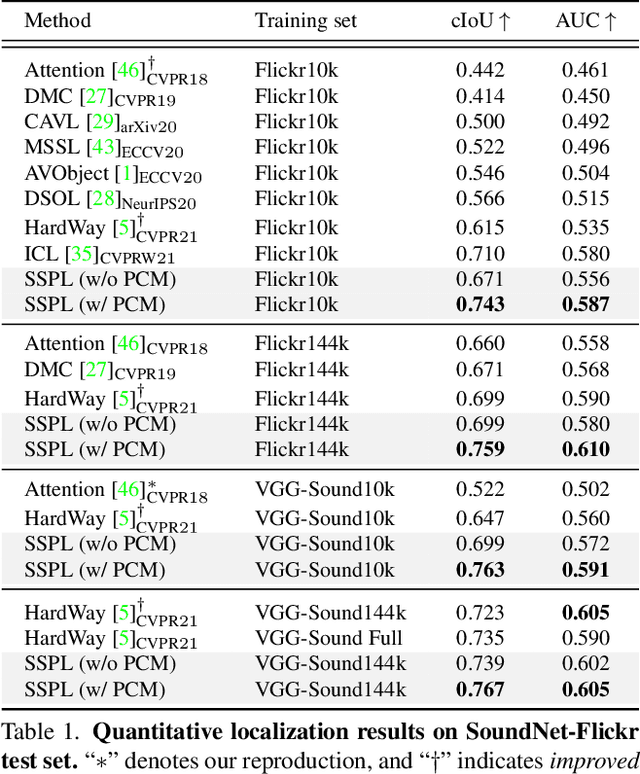
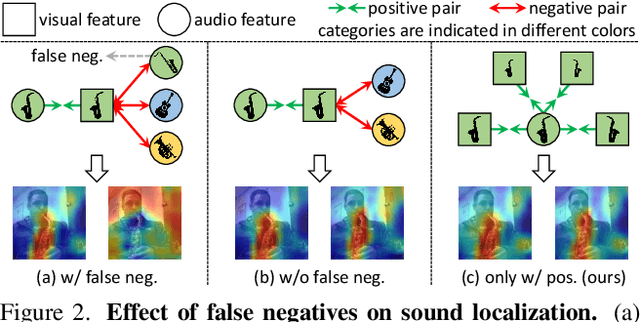
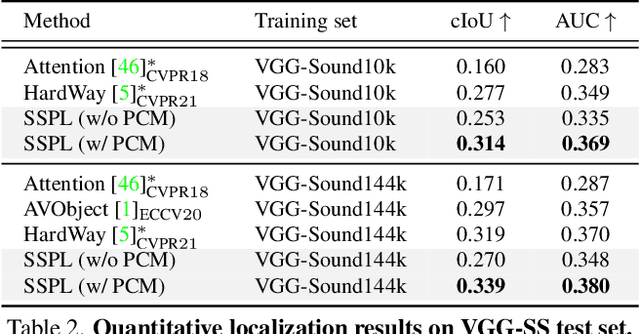
Sound source localization in visual scenes aims to localize objects emitting the sound in a given image. Recent works showing impressive localization performance typically rely on the contrastive learning framework. However, the random sampling of negatives, as commonly adopted in these methods, can result in misalignment between audio and visual features and thus inducing ambiguity in localization. In this paper, instead of following previous literature, we propose Self-Supervised Predictive Learning (SSPL), a negative-free method for sound localization via explicit positive mining. Specifically, we first devise a three-stream network to elegantly associate sound source with two augmented views of one corresponding video frame, leading to semantically coherent similarities between audio and visual features. Second, we introduce a novel predictive coding module for audio-visual feature alignment. Such a module assists SSPL to focus on target objects in a progressive manner and effectively lowers the positive-pair learning difficulty. Experiments show surprising results that SSPL outperforms the state-of-the-art approach on two standard sound localization benchmarks. In particular, SSPL achieves significant improvements of 8.6% cIoU and 3.4% AUC on SoundNet-Flickr compared to the previous best. Code is available at: https://github.com/zjsong/SSPL.