 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Language Models with Just Forward Passes
May 27, 2023



Fine-tuning language models (LMs) has yielded success on diverse downstream tasks, but as LMs grow in size, backpropagation requires a prohibitively large amount of memory. Zeroth-order (ZO) methods can in principle estimate gradients using only two forward passes but are theorized to be catastrophically slow for optimizing large models. In this work, we propose a memory-efficient zerothorder optimizer (MeZO), adapting the classical ZO-SGD method to operate in-place, thereby fine-tuning LMs with the same memory footprint as inference. For example, with a single A100 80GB GPU, MeZO can train a 30-billion parameter model, whereas fine-tuning with backpropagation can train only a 2.7B LM with the same budget. We conduct comprehensive experiments across model types (masked and autoregressive LMs), model scales (up to 66B), and downstream tasks (classification, multiple-choice, and generation). Our results demonstrate that (1) MeZO significantly outperforms in-context learning and linear probing; (2) MeZO achieves comparable performance to fine-tuning with backpropagation across multiple tasks, with up to 12x memory reduction; (3) MeZO is compatible with both full-parameter and parameter-efficient tuning techniques such as LoRA and prefix tuning; (4) MeZO can effectively optimize non-differentiable objectives (e.g., maximizing accuracy or F1). We support our empirical findings with theoretical insights, highlighting how adequate pre-training and task prompts enable MeZO to fine-tune huge models, despite classical ZO analyses suggesting otherwise.
Enabling Large Language Models to Generate Text with Citations
May 24, 2023



Large language models (LLMs) have emerged as a widely-used tool for information seeking, but their generated outputs are prone to hallucination. In this work, we aim to enable LLMs to generate text with citations, improving their factual correctness and verifiability. Existing work mainly relies on commercial search engines and human evaluation, making it challenging to reproduce and compare with different modeling approaches. We propose ALCE, the first benchmark for Automatic LLMs' Citation Evaluation. ALCE collects a diverse set of questions and retrieval corpora and requires building end-to-end systems to retrieve supporting evidence and generate answers with citations. We build automatic metrics along three dimensions -- fluency, correctness, and citation quality -- and demonstrate their strong correlation with human judgements. Our experiments with state-of-the-art LLMs and novel prompting strategies show that current systems have considerable room for improvements -- for example, on the ELI5 dataset, even the best model has 49% of its generations lacking complete citation support. Our extensive analyses further highlight promising future directions, including developing better retrievers, advancing long-context LLMs, and improving the ability to synthesize information from multiple sources.
What In-Context Learning "Learns" In-Context: Disentangling Task Recognition and Task Learning
May 16, 2023



Large language models (LLMs) exploit in-context learning (ICL) to solve tasks with only a few demonstrations, but its mechanisms are not yet well-understood. Some works suggest that LLMs only recall already learned concepts from pre-training, while others hint that ICL performs implicit learning over demonstrations. We characterize two ways through which ICL leverages demonstrations. Task recognition (TR) captures the extent to which LLMs can recognize a task through demonstrations -- even without ground-truth labels -- and apply their pre-trained priors, whereas task learning (TL) is the ability to capture new input-label mappings unseen in pre-training. Using a wide range of classification datasets and three LLM families (GPT-3, LLaMA and OPT), we design controlled experiments to disentangle the roles of TR and TL in ICL. We show that (1) models can achieve non-trivial performance with only TR, and TR does not further improve with larger models or more demonstrations; (2) LLMs acquire TL as the model scales, and TL's performance consistently improves with more demonstrations in context. Our findings unravel two different forces behind ICL and we advocate for discriminating them in future ICL research due to their distinct nature.
STM-UNet: An Efficient U-shaped Architecture Based on Swin Transformer and Multi-scale MLP for Medical Image Segmentation
Apr 25, 2023



Automated medical image segmentation can assist doctors to diagnose faster and more accurate. Deep learning based models for medical image segmentation have made great progress in recent years. However, the existing models fail to effectively leverage Transformer and MLP for improving U-shaped architecture efficiently. In addition, the multi-scale features of the MLP have not been fully extracted in the bottleneck of U-shaped architecture. In this paper, we propose an efficient U-shaped architecture based on Swin Transformer and multi-scale MLP, namely STM-UNet. Specifically, the Swin Transformer block is added to skip connection of STM-UNet in form of residual connection, which can enhance the modeling ability of global features and long-range dependency. Meanwhile, a novel PCAS-MLP with parallel convolution module is designed and placed into the bottleneck of our architecture to contribute to the improvement of segmentation performance. The experimental results on ISIC 2016 and ISIC 2018 demonstrate the effectiveness of our proposed method. Our method also outperforms several state-of-the-art methods in terms of IoU and Dice. Our method has achieved a better trade-off between high segmentation accuracy and low model complexity.
The CRINGE Loss: Learning what language not to model
Nov 10, 2022Standard language model training employs gold human documents or human-human interaction data, and treats all training data as positive examples. Growing evidence shows that even with very large amounts of positive training data, issues remain that can be alleviated with relatively small amounts of negative data -- examples of what the model should not do. In this work, we propose a novel procedure to train with such data called the CRINGE loss (ContRastive Iterative Negative GEneration). We show the effectiveness of this approach across three different experiments on the tasks of safe generation, contradiction avoidance, and open-domain dialogue. Our models outperform multiple strong baselines and are conceptually simple, easy to train and implement.
Transformer-based dimensionality reduction
Oct 15, 2022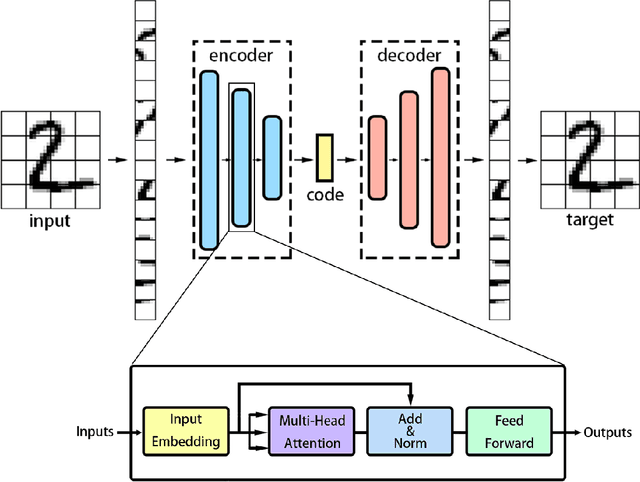
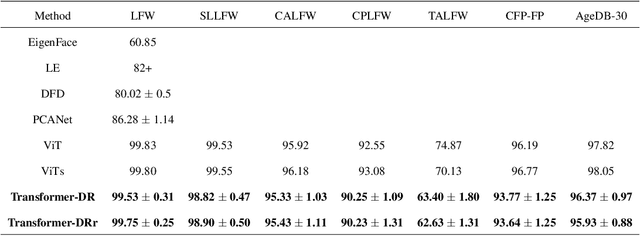
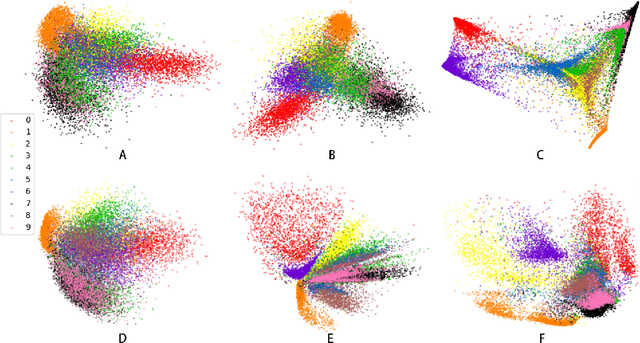

Recently, Transformer is much popular and plays an important role in the fields of Machine Learning (ML), Natural Language Processing (NLP), and Computer Vision (CV), etc. In this paper, based on the Vision Transformer (ViT) model, a new dimensionality reduction (DR) model is proposed, named Transformer-DR. From data visualization, image reconstruction and face recognition, the representation ability of Transformer-DR after dimensionality reduction is studied, and it is compared with some representative DR methods to understand the difference between Transformer-DR and existing DR methods. The experimental results show that Transformer-DR is an effective dimensionality reduction method.
Automatic Label Sequence Generation for Prompting Sequence-to-sequence Models
Sep 20, 2022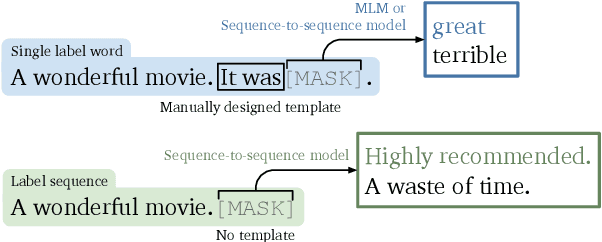
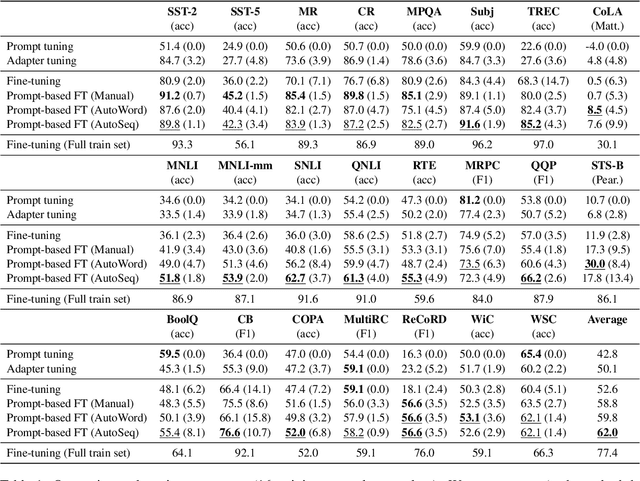


Prompting, which casts downstream applications as language modeling tasks, has shown to be sample efficient compared to standard fine-tuning with pre-trained models. However, one pitfall of prompting is the need of manually-designed patterns, whose outcome can be unintuitive and requires large validation sets to tune. To tackle the challenge, we propose AutoSeq, a fully automatic prompting method: (1) We adopt natural language prompts on sequence-to-sequence models, enabling free-form generation and larger label search space; (2) We propose label sequences -- phrases with indefinite lengths to verbalize the labels -- which eliminate the need of manual templates and are more expressive than single label words; (3) We use beam search to automatically generate a large amount of label sequence candidates and propose contrastive re-ranking to get the best combinations. AutoSeq significantly outperforms other no-manual-design methods, such as soft prompt tuning, adapter tuning, and automatic search on single label words; the generated label sequences are even better than curated manual ones on a variety of tasks. Our method reveals the potential of sequence-to-sequence models in few-shot learning and sheds light on a path to generic and automatic prompting. The source code of this paper can be obtained from https://github.com/thunlp/Seq2Seq-Prompt.
Recovering Private Text in Federated Learning of Language Models
May 17, 2022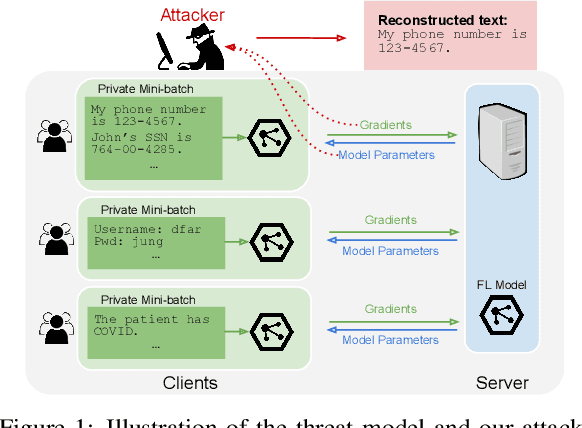
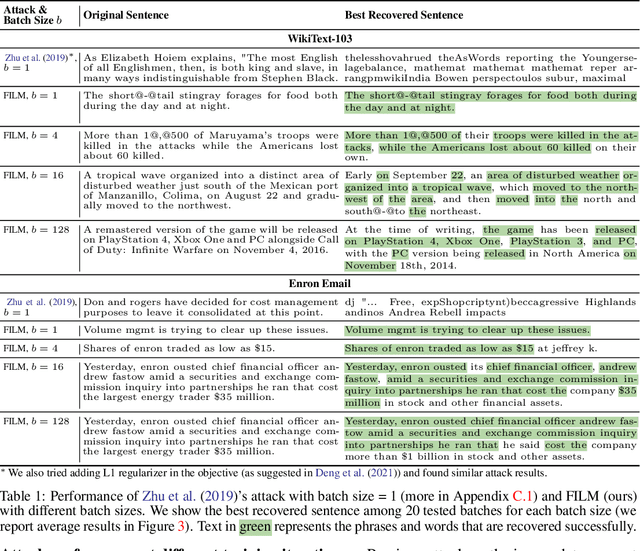
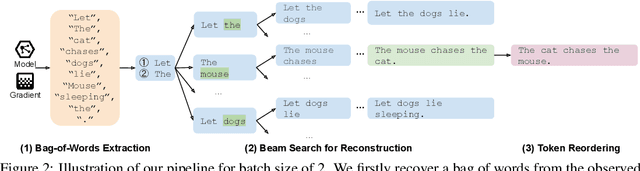

Federated learning allows distributed users to collaboratively train a model while keeping each user's data private. Recently, a growing body of work has demonstrated that an eavesdropping attacker can effectively recover image data from gradients transmitted during federated learning. However, little progress has been made in recovering text data. In this paper, we present a novel attack method FILM for federated learning of language models -- for the first time, we show the feasibility of recovering text from large batch sizes of up to 128 sentences. Different from image-recovery methods which are optimized to match gradients, we take a distinct approach that first identifies a set of words from gradients and then directly reconstructs sentences based on beam search and a prior-based reordering strategy. The key insight of our attack is to leverage either prior knowledge in pre-trained language models or memorization during training. Despite its simplicity, we demonstrate that FILM can work well with several large-scale datasets -- it can extract single sentences with high fidelity even for large batch sizes and recover multiple sentences from the batch successfully if the attack is applied iteratively. We hope our results can motivate future work in developing stronger attacks as well as new defense methods for training language models in federated learning. Our code is publicly available at https://github.com/Princeton-SysML/FILM.
Should You Mask 15% in Masked Language Modeling?
Feb 16, 2022



Masked language models conventionally use a masking rate of 15% due to the belief that more masking would provide insufficient context to learn good representations, and less masking would make training too expensive. Surprisingly, we find that masking up to 40% of input tokens can outperform the 15% baseline, and even masking 80% can preserve most of the performance, as measured by fine-tuning on downstream tasks. Increasing the masking rates has two distinct effects, which we investigate through careful ablations: (1) A larger proportion of input tokens are corrupted, reducing the context size and creating a harder task, and (2) models perform more predictions, which benefits training. We observe that larger models in particular favor higher masking rates, as they have more capacity to perform the harder task. We also connect our findings to sophisticated masking schemes such as span masking and PMI masking, as well as BERT's curious 80-10-10 corruption strategy, and find that simple uniform masking with [MASK] replacements can be competitive at higher masking rates. Our results contribute to a better understanding of masked language modeling and point to new avenues for efficient pre-training.
Ditch the Gold Standard: Re-evaluating Conversational Question Answering
Dec 16, 2021

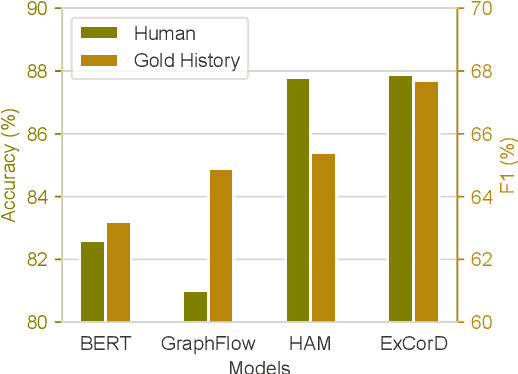
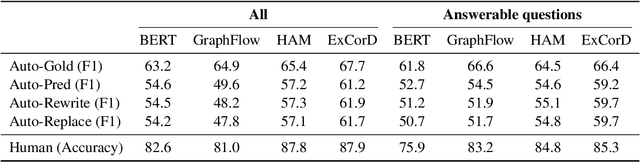
Conversational question answering (CQA) systems aim to provide natural-language answers to users in information-seeking conversations. Existing CQA benchmarks compare models with pre-collected human-human conversations, using ground-truth answers provided in conversational history. It remains unclear whether we can rely on this static evaluation for model development and whether current systems can well generalize to real-world human-machine conversations. In this work, we conduct the first large-scale human evaluation of state-of-the-art CQA systems, where human evaluators converse with models and judge the correctness of their answers. We find that the distribution of human-machine conversations differs drastically from that of human-human conversations, and there is a disagreement between human and gold-history evaluation in terms of model ranking. We further investigate how to improve automatic evaluations, and propose a question rewriting mechanism based on predicted history, which better correlates with human judgments. Finally, we discuss the impact of various modeling strategies and future directions towards better conversational question answering systems.