 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Lancet: Image Editing with Compositional Representation Transplant
Apr 03, 2025Diffusion models are widely used for image editing tasks. Existing editing methods often design a representation manipulation procedure by curating an edit direction in the text embedding or score space. However, such a procedure faces a key challenge: overestimating the edit strength harms visual consistency while underestimating it fails the editing task. Notably, each source image may require a different editing strength, and it is costly to search for an appropriate strength via trial-and-error. To address this challenge, we propose Concept Lancet (CoLan), a zero-shot plug-and-play framework for principled representation manipulation in diffusion-based image editing. At inference time, we decompose the source input in the latent (text embedding or diffusion score) space as a sparse linear combination of the representations of the collected visual concepts. This allows us to accurately estimate the presence of concepts in each image, which informs the edit. Based on the editing task (replace/add/remove), we perform a customized concept transplant process to impose the corresponding editing direction. To sufficiently model the concept space, we curate a conceptual representation dataset, CoLan-150K, which contains diverse descriptions and scenarios of visual terms and phrases for the latent dictionary. Experiments on multiple diffusion-based image editing baselines show that methods equipped with CoLan achieve state-of-the-art performance in editing effectiveness and consistency preservation.
An Overview of Low-Rank Structures in the Training and Adaptation of Large Models
Mar 25, 2025The rise of deep learning has revolutionized data processing and prediction in signal processing and machine learning, yet the substantial computational demands of training and deploying modern large-scale deep models present significant challenges, including high computational costs and energy consumption. Recent research has uncovered a widespread phenomenon in deep networks: the emergence of low-rank structures in weight matrices and learned representations during training. These implicit low-dimensional patterns provide valuable insights for improving the efficiency of training and fine-tuning large-scale models. Practical techniques inspired by this phenomenon, such as low-rank adaptation (LoRA) and training, enable significant reductions in computational cost while preserving model performance. In this paper, we present a comprehensive review of recent advances in exploiting low-rank structures for deep learning and shed light on their mathematical foundations. Mathematically, we present two complementary perspectives on understanding the low-rankness in deep networks: (i) the emergence of low-rank structures throughout the whole optimization dynamics of gradient and (ii) the implicit regularization effects that induce such low-rank structures at convergence. From a practical standpoint, studying the low-rank learning dynamics of gradient descent offers a mathematical foundation for understanding the effectiveness of LoRA in fine-tuning large-scale models and inspires parameter-efficient low-rank training strategies. Furthermore, the implicit low-rank regularization effect helps explain the success of various masked training approaches in deep neural networks, ranging from dropout to masked self-supervised learning.
Token Statistics Transformer: Linear-Time Attention via Variational Rate Reduction
Dec 23, 2024



The attention operator is arguably the key distinguishing factor of transformer architectures, which have demonstrated state-of-the-art performance on a variety of tasks. However, transformer attention operators often impose a significant computational burden, with the computational complexity scaling quadratically with the number of tokens. In this work, we propose a novel transformer attention operator whose computational complexity scales linearly with the number of tokens. We derive our network architecture by extending prior work which has shown that a transformer style architecture naturally arises by "white-box" architecture design, where each layer of the network is designed to implement an incremental optimization step of a maximal coding rate reduction objective (MCR$^2$). Specifically, we derive a novel variational form of the MCR$^2$ objective and show that the architecture that results from unrolled gradient descent of this variational objective leads to a new attention module called Token Statistics Self-Attention (TSSA). TSSA has linear computational and memory complexity and radically departs from the typical attention architecture that computes pairwise similarities between tokens. Experiments on vision, language, and long sequence tasks show that simply swapping TSSA for standard self-attention, which we refer to as the Token Statistics Transformer (ToST), achieves competitive performance with conventional transformers while being significantly more computationally efficient and interpretable. Our results also somewhat call into question the conventional wisdom that pairwise similarity style attention mechanisms are critical to the success of transformer architectures. Code will be available at https://github.com/RobinWu218/ToST.
PaCE: Parsimonious Concept Engineering for Large Language Models
Jun 06, 2024



Large Language Models (LLMs) are being used for a wide variety of tasks. While they are capable of generating human-like responses, they can also produce undesirable output including potentially harmful information, racist or sexist language, and hallucinations. Alignment methods are designed to reduce such undesirable output, via techniques such as fine-tuning, prompt engineering, and representation engineering. However, existing methods face several challenges: some require costly fine-tuning for every alignment task; some do not adequately remove undesirable concepts, failing alignment; some remove benign concepts, lowering the linguistic capabilities of LLMs. To address these issues, we propose Parsimonious Concept Engineering (PaCE), a novel activation engineering framework for alignment. First, to sufficiently model the concepts, we construct a large-scale concept dictionary in the activation space, in which each atom corresponds to a semantic concept. Then, given any alignment task, we instruct a concept partitioner to efficiently annotate the concepts as benign or undesirable. Finally, at inference time, we decompose the LLM activations along the concept dictionary via sparse coding, to accurately represent the activation as a linear combination of the benign and undesirable components. By removing the latter ones from the activation, we reorient the behavior of LLMs towards alignment goals. We conduct experiments on tasks such as response detoxification, faithfulness enhancement, and sentiment revising, and show that PaCE achieves state-of-the-art alignment performance while maintaining linguistic capabilities.
Image Clustering via the Principle of Rate Reduction in the Age of Pretrained Models
Jun 09, 2023



The advent of large pre-trained models has brought about a paradigm shift in both visual representation learning and natural language processing. However, clustering unlabeled images, as a fundamental and classic machine learning problem, still lacks effective solution, particularly for large-scale datasets. In this paper, we propose a novel image clustering pipeline that leverages the powerful feature representation of large pre-trained models such as CLIP and cluster images effectively and efficiently at scale. We show that the pre-trained features are significantly more structured by further optimizing the rate reduction objective. The resulting features may significantly improve the clustering accuracy, e.g., from 57\% to 66\% on ImageNet-1k. Furthermore, by leveraging CLIP's image-text binding, we show how the new clustering method leads to a simple yet effective self-labeling algorithm that successfully works on unlabeled large datasets such as MS-COCO and LAION-Aesthetics. We will release the code in https://github.com/LeslieTrue/CPP.
Unsupervised Manifold Linearizing and Clustering
Jan 04, 2023Clustering data lying close to a union of low-dimensional manifolds, with each manifold as a cluster, is a fundamental problem in machine learning. When the manifolds are assumed to be linear subspaces, many methods succeed using low-rank and sparse priors, which have been studied extensively over the past two decades. Unfortunately, most real-world datasets can not be well approximated by linear subspaces. On the other hand, several works have proposed to identify the manifolds by learning a feature map such that the data transformed by the map lie in a union of linear subspaces, even though the original data are from non-linear manifolds. However, most works either assume knowledge of the membership of samples to clusters, or are shown to learn trivial representations. In this paper, we propose to simultaneously perform clustering and learn a union-of-subspace representation via Maximal Coding Rate Reduction. Experiments on synthetic and realistic datasets show that the proposed method achieves clustering accuracy comparable with state-of-the-art alternatives, while being more scalable and learning geometrically meaningful representations.
Efficient Maximal Coding Rate Reduction by Variational Forms
Mar 31, 2022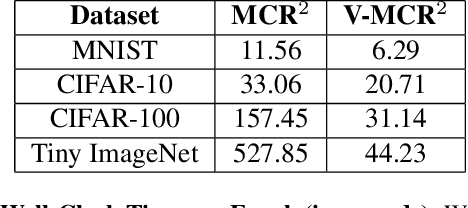
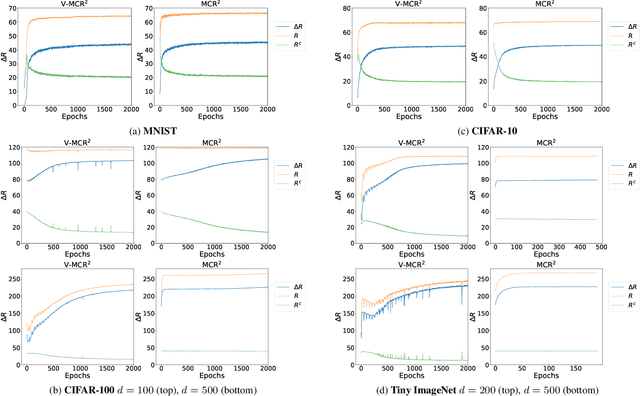
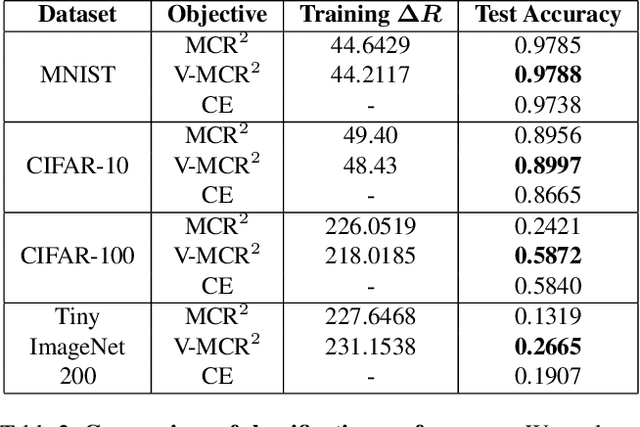
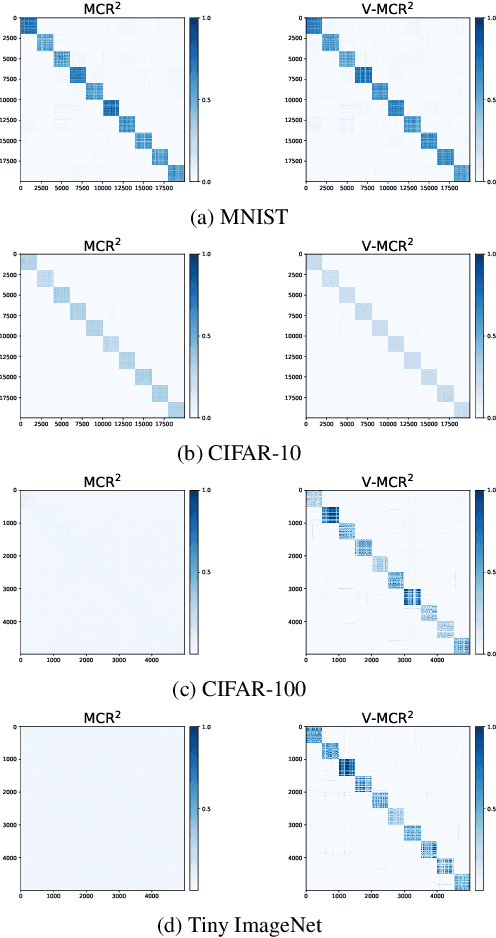
The principle of Maximal Coding Rate Reduction (MCR$^2$) has recently been proposed as a training objective for learning discriminative low-dimensional structures intrinsic to high-dimensional data to allow for more robust training than standard approaches, such as cross-entropy minimization. However, despite the advantages that have been shown for MCR$^2$ training, MCR$^2$ suffers from a significant computational cost due to the need to evaluate and differentiate a significant number of log-determinant terms that grows linearly with the number of classes. By taking advantage of variational forms of spectral functions of a matrix, we reformulate the MCR$^2$ objective to a form that can scale significantly without compromising training accuracy. Experiments in image classification demonstrate that our proposed formulation results in a significant speed up over optimizing the original MCR$^2$ objective directly and often results in higher quality learned representations. Further, our approach may be of independent interest in other models that require computation of log-determinant forms, such as in system identification or normalizing flow models.
Boosting RANSAC via Dual Principal Component Pursuit
Oct 06, 2021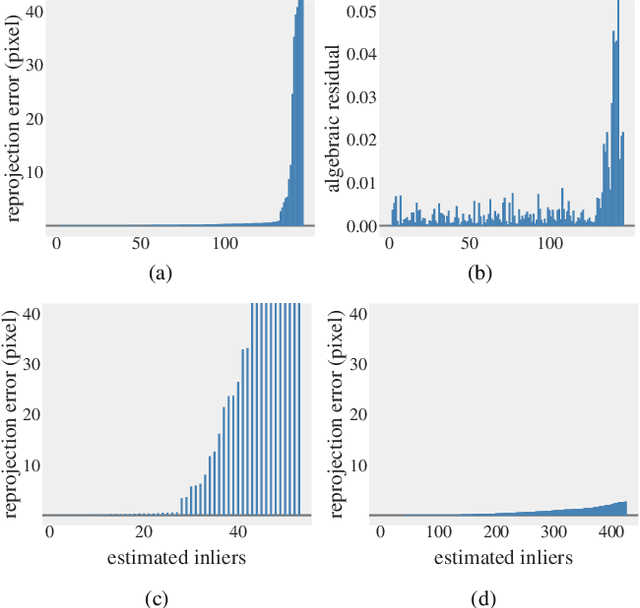


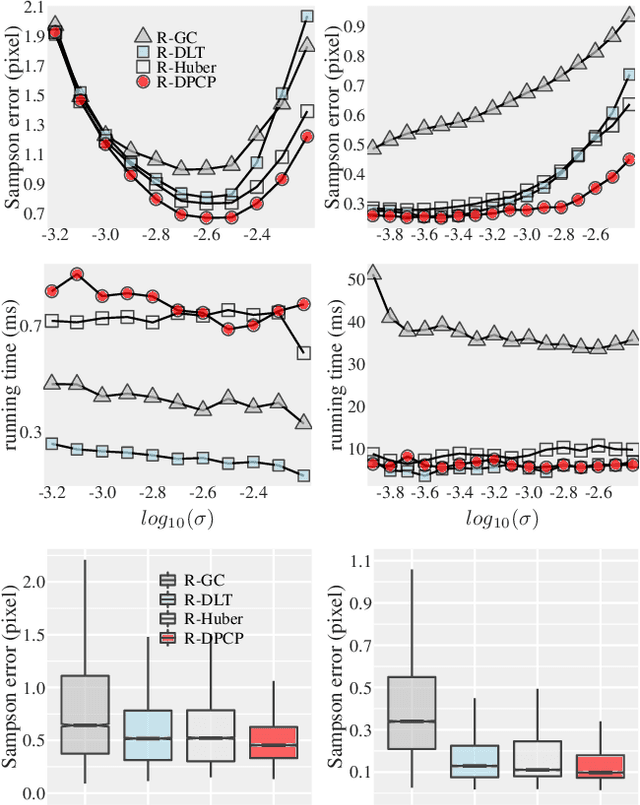
In this paper, we revisit the problem of local optimization in RANSAC. Once a so-far-the-best model has been found, we refine it via Dual Principal Component Pursuit (DPCP), a robust subspace learning method with strong theoretical support and efficient algorithms. The proposed DPCP-RANSAC has far fewer parameters than existing methods and is scalable. Experiments on estimating two-view homographies, fundamental and essential matrices, and three-view homographic tensors using large-scale datasets show that our approach consistently has higher accuracy than state-of-the-art alternatives.
Learning to Parse Wireframes in Images of Man-Made Environments
Jul 15, 2020

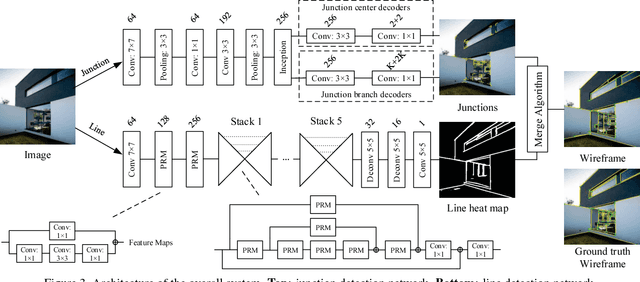
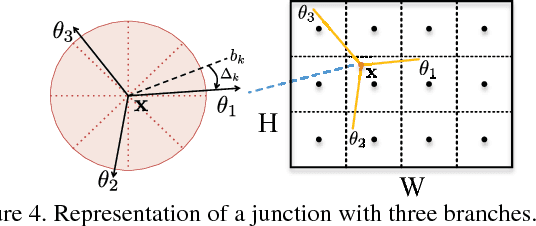
In this paper, we propose a learning-based approach to the task of automatically extracting a "wireframe" representation for images of cluttered man-made environments. The wireframe (see Fig. 1) contains all salient straight lines and their junctions of the scene that encode efficiently and accurately large-scale geometry and object shapes. To this end, we have built a very large new dataset of over 5,000 images with wireframes thoroughly labelled by humans. We have proposed two convolutional neural networks that are suitable for extracting junctions and lines with large spatial support, respectively. The networks trained on our dataset have achieved significantly better performance than state-of-the-art methods for junction detection and line segment detection, respectively. We have conducted extensive experiments to evaluate quantitatively and qualitatively the wireframes obtained by our method, and have convincingly shown that effectively and efficiently parsing wireframes for images of man-made environments is a feasible goal within reach. Such wireframes could benefit many important visual tasks such as feature correspondence, 3D reconstruction, vision-based mapping, localization, and navigation. The data and source code are available at https://github.com/huangkuns/wireframe.
* CVPR 2018