 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA simple uniformly optimal method without line search for convex optimization
Oct 27, 2023



Line search (or backtracking) procedures have been widely employed into first-order methods for solving convex optimization problems, especially those with unknown problem parameters (e.g., Lipschitz constant). In this paper, we show that line search is superfluous in attaining the optimal rate of convergence for solving a convex optimization problem whose parameters are not given a priori. In particular, we present a novel accelerated gradient descent type algorithm called auto-conditioned fast gradient method (AC-FGM) that can achieve an optimal $\mathcal{O}(1/k^2)$ rate of convergence for smooth convex optimization without requiring the estimate of a global Lipschitz constant or the employment of line search procedures. We then extend AC-FGM to solve convex optimization problems with H\"{o}lder continuous gradients and show that it automatically achieves the optimal rates of convergence uniformly for all problem classes with the desired accuracy of the solution as the only input. Finally, we report some encouraging numerical results that demonstrate the advantages of AC-FGM over the previously developed parameter-free methods for convex optimization.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
Accelerated stochastic approximation with state-dependent noise
Jul 13, 2023



We consider a class of stochastic smooth convex optimization problems under rather general assumptions on the noise in the stochastic gradient observation. As opposed to the classical problem setting in which the variance of noise is assumed to be uniformly bounded, herein we assume that the variance of stochastic gradients is related to the "sub-optimality" of the approximate solutions delivered by the algorithm. Such problems naturally arise in a variety of applications, in particular, in the well-known generalized linear regression problem in statistics. However, to the best of our knowledge, none of the existing stochastic approximation algorithms for solving this class of problems attain optimality in terms of the dependence on accuracy, problem parameters, and mini-batch size. We discuss two non-Euclidean accelerated stochastic approximation routines--stochastic accelerated gradient descent (SAGD) and stochastic gradient extrapolation (SGE)--which carry a particular duality relationship. We show that both SAGD and SGE, under appropriate conditions, achieve the optimal convergence rate, attaining the optimal iteration and sample complexities simultaneously. However, corresponding assumptions for the SGE algorithm are more general; they allow, for instance, for efficient application of the SGE to statistical estimation problems under heavy tail noises and discontinuous score functions. We also discuss the application of the SGE to problems satisfying quadratic growth conditions, and show how it can be used to recover sparse solutions. Finally, we report on some simulation experiments to illustrate numerical performance of our proposed algorithms in high-dimensional settings.
Elucidating Interfacial Dynamics of Ti-Al Systems Using Molecular Dynamics Simulation and Markov State Modeling
Jul 03, 2023Due to their remarkable mechanical and chemical properties, Ti-Al based materials are attracting considerable interest in numerous fields of engineering, such as automotive, aerospace, and defense. With their low density, high strength, and resistance to corrosion and oxidation, these intermetallic alloys and compound metal-metallic composites have found diverse applications. The present study delves into the interfacial dynamics of these Ti-Al systems, particularly focusing on the behavior of Ti and Al atoms in the presence of TiAl$_3$ grain boundaries under experimental heat treatment conditions. Using a combination of Molecular Dynamics and Markov State Model analyses, we scrutinize the kinetic processes involved in the formation of TiAl$_3$. The Molecular Dynamics simulation indicates that at the early stage of heat treatment, the predominating process is the diffusion of Al atoms towards the Ti surface through the TiAl$_3$ grain boundaries. The Markov State Modeling identifies three distinct dynamic states of Al atoms within the Ti/Al mixture that forms during the process, each exhibiting a unique spatial distribution. Using transition timescales as a qualitative measure of the rapidness of the dynamics, it is observed that the Al dynamics is significantly less rapid near the Ti surface compared to the Al surface. Put together, the results offer a comprehensive understanding of the interfacial dynamics and reveals a three-stage diffusion mechanism. The process initiates with the premelting of Al, proceeds with the prevalent diffusion of Al atoms towards the Ti surface, and eventually ceases as the Ti concentration within the mixture progressively increases. The insights gained from this study could contribute significantly to the control and optimization of manufacturing processes for these high-performing Ti-Al based materials.
Token Boosting for Robust Self-Supervised Visual Transformer Pre-training
Apr 12, 2023



Learning with large-scale unlabeled data has become a powerful tool for pre-training Visual Transformers (VTs). However, prior works tend to overlook that, in real-world scenarios, the input data may be corrupted and unreliable. Pre-training VTs on such corrupted data can be challenging, especially when we pre-train via the masked autoencoding approach, where both the inputs and masked ``ground truth" targets can potentially be unreliable in this case. To address this limitation, we introduce the Token Boosting Module (TBM) as a plug-and-play component for VTs that effectively allows the VT to learn to extract clean and robust features during masked autoencoding pre-training. We provide theoretical analysis to show how TBM improves model pre-training with more robust and generalizable representations, thus benefiting downstream tasks. We conduct extensive experiments to analyze TBM's effectiveness, and results on four corrupted datasets demonstrate that TBM consistently improves performance on downstream tasks.
Dynamic Spatio-Temporal Specialization Learning for Fine-Grained Action Recognition
Sep 03, 2022
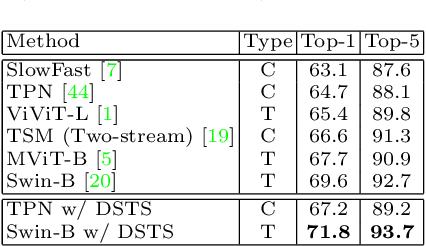
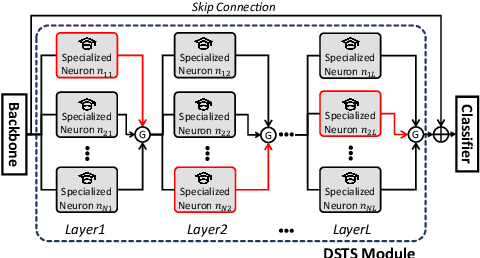
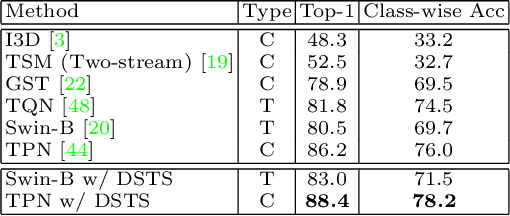
The goal of fine-grained action recognition is to successfully discriminate between action categories with subtle differences. To tackle this, we derive inspiration from the human visual system which contains specialized regions in the brain that are dedicated towards handling specific tasks. We design a novel Dynamic Spatio-Temporal Specialization (DSTS) module, which consists of specialized neurons that are only activated for a subset of samples that are highly similar. During training, the loss forces the specialized neurons to learn discriminative fine-grained differences to distinguish between these similar samples, improving fine-grained recognition. Moreover, a spatio-temporal specialization method further optimizes the architectures of the specialized neurons to capture either more spatial or temporal fine-grained information, to better tackle the large range of spatio-temporal variations in the videos. Lastly, we design an Upstream-Downstream Learning algorithm to optimize our model's dynamic decisions during training, improving the performance of our DSTS module. We obtain state-of-the-art performance on two widely-used fine-grained action recognition datasets.
ERA: Expert Retrieval and Assembly for Early Action Prediction
Jul 22, 2022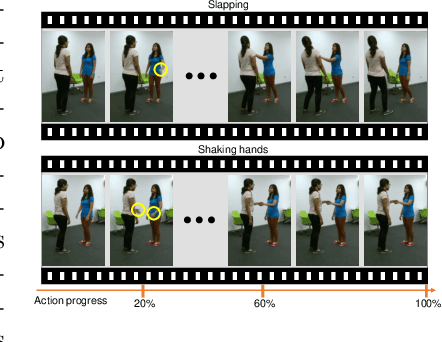
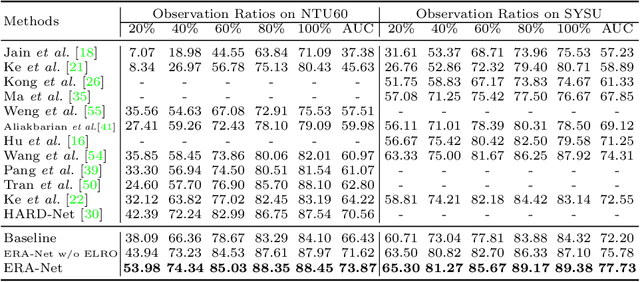
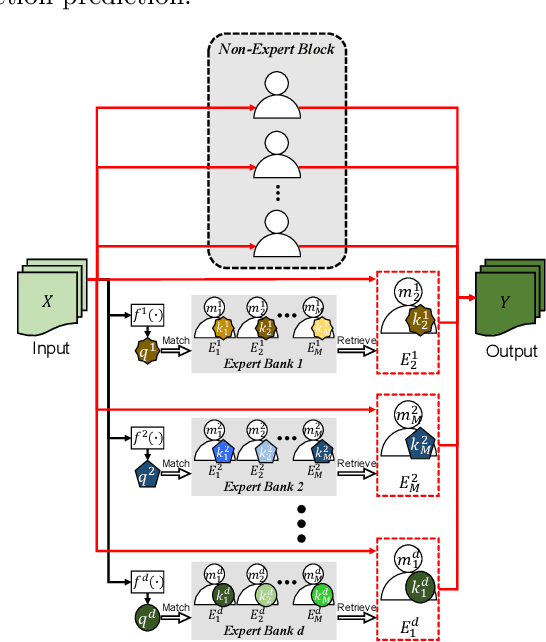

Early action prediction aims to successfully predict the class label of an action before it is completely performed. This is a challenging task because the beginning stages of different actions can be very similar, with only minor subtle differences for discrimination. In this paper, we propose a novel Expert Retrieval and Assembly (ERA) module that retrieves and assembles a set of experts most specialized at using discriminative subtle differences, to distinguish an input sample from other highly similar samples. To encourage our model to effectively use subtle differences for early action prediction, we push experts to discriminate exclusively between samples that are highly similar, forcing these experts to learn to use subtle differences that exist between those samples. Additionally, we design an effective Expert Learning Rate Optimization method that balances the experts' optimization and leads to better performance. We evaluate our ERA module on four public action datasets and achieve state-of-the-art performance.
Stochastic first-order methods for average-reward Markov decision processes
May 19, 2022
We study the problem of average-reward Markov decision processes (AMDPs) and develop novel first-order methods with strong theoretical guarantees for both policy evaluation and optimization. Existing on-policy evaluation methods suffer from sub-optimal convergence rates as well as failure in handling insufficiently random policies, e.g., deterministic policies, for lack of exploration. To remedy these issues, we develop a novel variance-reduced temporal difference (VRTD) method with linear function approximation for randomized policies along with optimal convergence guarantees, and an exploratory variance-reduced temporal difference (EVRTD) method for insufficiently random policies with comparable convergence guarantees. We further establish linear convergence rate on the bias of policy evaluation, which is essential for improving the overall sample complexity of policy optimization. On the other hand, compared with intensive research interest in finite sample analysis of policy gradient methods for discounted MDPs, existing studies on policy gradient methods for AMDPs mostly focus on regret bounds under restrictive assumptions on the underlying Markov processes (see, e.g., Abbasi-Yadkori et al., 2019), and they often lack guarantees on the overall sample complexities. Towards this end, we develop an average-reward variant of the stochastic policy mirror descent (SPMD) (Lan, 2022). We establish the first $\widetilde{\mathcal{O}}(\epsilon^{-2})$ sample complexity for solving AMDPs with policy gradient method under both the generative model (with unichain assumption) and Markovian noise model (with ergodic assumption). This bound can be further improved to $\widetilde{\mathcal{O}}(\epsilon^{-1})$ for solving regularized AMDPs. Our theoretical advantages are corroborated by numerical experiments.
Accelerated and instance-optimal policy evaluation with linear function approximation
Dec 24, 2021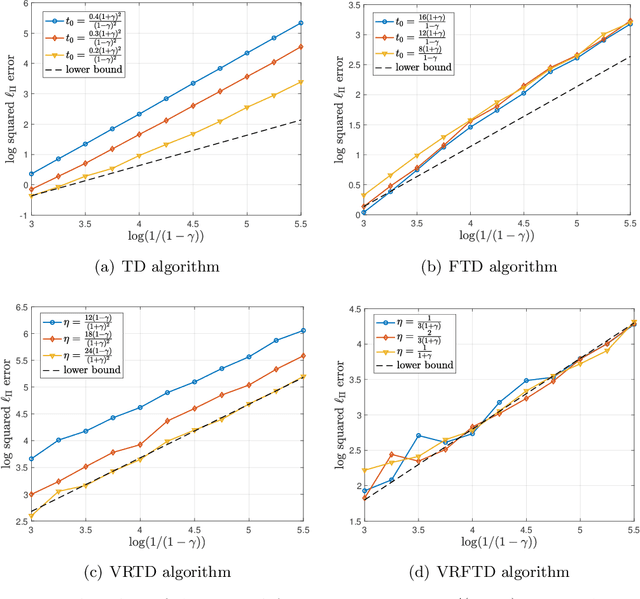
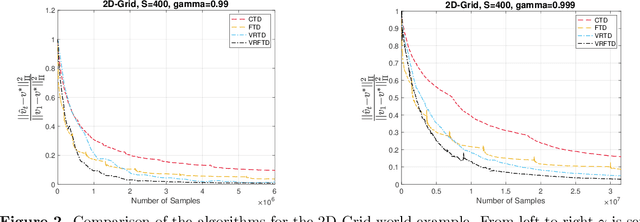
We study the problem of policy evaluation with linear function approximation and present efficient and practical algorithms that come with strong optimality guarantees. We begin by proving lower bounds that establish baselines on both the deterministic error and stochastic error in this problem. In particular, we prove an oracle complexity lower bound on the deterministic error in an instance-dependent norm associated with the stationary distribution of the transition kernel, and use the local asymptotic minimax machinery to prove an instance-dependent lower bound on the stochastic error in the i.i.d. observation model. Existing algorithms fail to match at least one of these lower bounds: To illustrate, we analyze a variance-reduced variant of temporal difference learning, showing in particular that it fails to achieve the oracle complexity lower bound. To remedy this issue, we develop an accelerated, variance-reduced fast temporal difference algorithm (VRFTD) that simultaneously matches both lower bounds and attains a strong notion of instance-optimality. Finally, we extend the VRFTD algorithm to the setting with Markovian observations, and provide instance-dependent convergence results that match those in the i.i.d. setting up to a multiplicative factor that is proportional to the mixing time of the chain. Our theoretical guarantees of optimality are corroborated by numerical experiments.
Faster Algorithm and Sharper Analysis for Constrained Markov Decision Process
Oct 20, 2021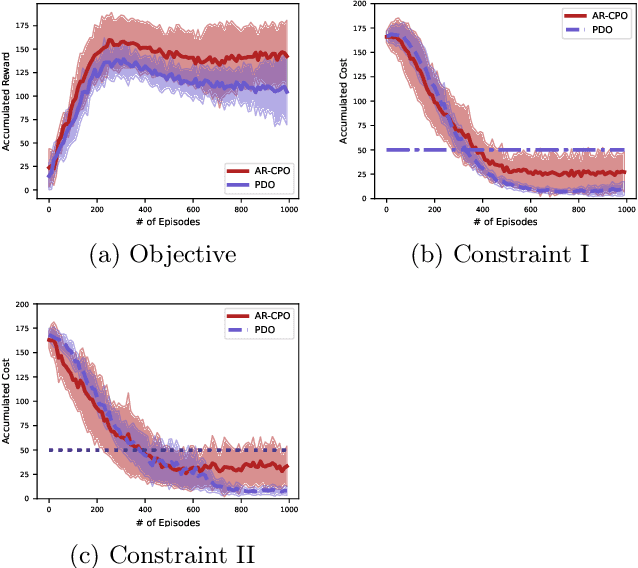
The problem of constrained Markov decision process (CMDP) is investigated, where an agent aims to maximize the expected accumulated discounted reward subject to multiple constraints on its utilities/costs. A new primal-dual approach is proposed with a novel integration of three ingredients: entropy regularized policy optimizer, dual variable regularizer, and Nesterov's accelerated gradient descent dual optimizer, all of which are critical to achieve a faster convergence. The finite-time error bound of the proposed approach is characterized. Despite the challenge of the nonconcave objective subject to nonconcave constraints, the proposed approach is shown to converge to the global optimum with a complexity of $\tilde{\mathcal O}(1/\epsilon)$ in terms of the optimality gap and the constraint violation, which improves the complexity of the existing primal-dual approach by a factor of $\mathcal O(1/\epsilon)$ \citep{ding2020natural,paternain2019constrained}. This is the first demonstration that nonconcave CMDP problems can attain the complexity lower bound of $\mathcal O(1/\epsilon)$ for convex optimization subject to convex constraints. Our primal-dual approach and non-asymptotic analysis are agnostic to the RL optimizer used, and thus are more flexible for practical applications. More generally, our approach also serves as the first algorithm that provably accelerates constrained nonconvex optimization with zero duality gap by exploiting the geometries such as the gradient dominance condition, for which the existing acceleration methods for constrained convex optimization are not applicable.