 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoMem: Training Long-Context Memory Agents with Answer-Conditioned Information Gain
Jun 02, 2026Long-context tasks require LLMs to identify and preserve answer-relevant information from large contexts. Chunk-wise memory agents address this issue by sequentially reading document chunks, updating a compact memory, and generating the final answer from the accumulated memory. However, existing RL-based chunk-wise agents either rely on sparse final-answer rewards or use lexical intermediate rewards for memory and retrieval actions. These signals supervise task success or local overlap, but do not directly evaluate whether the final memory supports the ground-truth answer. We propose InfoMem, a reward mechanism for training chunk-wise memory agents that evaluates final-memory utility using answer-conditioned information. InfoMem measures how much the final memory increases the model's per-token log-likelihood of the ground-truth answer. To stabilize RL optimization, InfoMem applies this signal only to successful trajectories and normalizes it before reward composition. Under the same GRPO framework and training budget, InfoMem improves long-context memory-agent performance over comparable memory-agent RL baselines. Analyses show that effective final-memory rewards should operate on successful trajectories, be normalized before reward composition, and be conditioned on the answer rather than the query. Our code is available at https://github.com/GenSouKa1/InfoMem.
EvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience
Jan 23, 2026The development of native computer-use agents (CUA) represents a significant leap in multimodal AI. However, their potential is currently bottlenecked by the constraints of static data scaling. Existing paradigms relying primarily on passive imitation of static datasets struggle to capture the intricate causal dynamics inherent in long-horizon computer tasks. In this work, we introduce EvoCUA, a native computer use agentic model. Unlike static imitation, EvoCUA integrates data generation and policy optimization into a self-sustaining evolutionary cycle. To mitigate data scarcity, we develop a verifiable synthesis engine that autonomously generates diverse tasks coupled with executable validators. To enable large-scale experience acquisition, we design a scalable infrastructure orchestrating tens of thousands of asynchronous sandbox rollouts. Building on these massive trajectories, we propose an iterative evolving learning strategy to efficiently internalize this experience. This mechanism dynamically regulates policy updates by identifying capability boundaries -- reinforcing successful routines while transforming failure trajectories into rich supervision through error analysis and self-correction. Empirical evaluations on the OSWorld benchmark demonstrate that EvoCUA achieves a success rate of 56.7%, establishing a new open-source state-of-the-art. Notably, EvoCUA significantly outperforms the previous best open-source model, OpenCUA-72B (45.0%), and surpasses leading closed-weights models such as UI-TARS-2 (53.1%). Crucially, our results underscore the generalizability of this approach: the evolving paradigm driven by learning from experience yields consistent performance gains across foundation models of varying scales, establishing a robust and scalable path for advancing native agent capabilities.
Lumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling
Jul 23, 2025
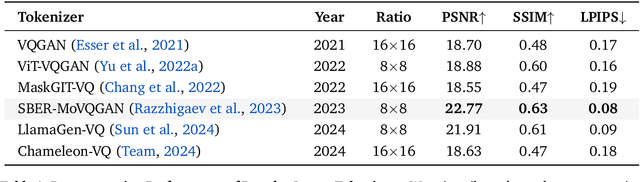
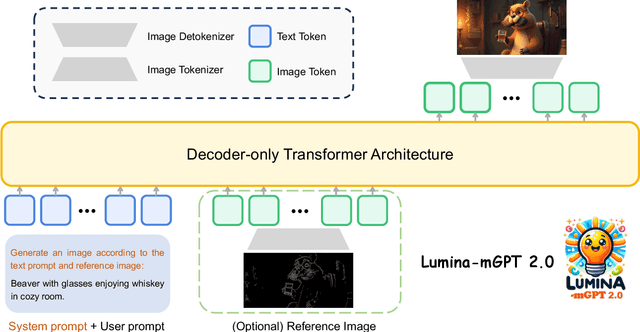

We present Lumina-mGPT 2.0, a stand-alone, decoder-only autoregressive model that revisits and revitalizes the autoregressive paradigm for high-quality image generation and beyond. Unlike existing approaches that rely on pretrained components or hybrid architectures, Lumina-mGPT 2.0 is trained entirely from scratch, enabling unrestricted architectural design and licensing freedom. It achieves generation quality on par with state-of-the-art diffusion models such as DALL-E 3 and SANA, while preserving the inherent flexibility and compositionality of autoregressive modeling. Our unified tokenization scheme allows the model to seamlessly handle a wide spectrum of tasks-including subject-driven generation, image editing, controllable synthesis, and dense prediction-within a single generative framework. To further boost usability, we incorporate efficient decoding strategies like inference-time scaling and speculative Jacobi sampling to improve quality and speed, respectively. Extensive evaluations on standard text-to-image benchmarks (e.g., GenEval, DPG) demonstrate that Lumina-mGPT 2.0 not only matches but in some cases surpasses diffusion-based models. Moreover, we confirm its multi-task capabilities on the Graph200K benchmark, with the native Lumina-mGPT 2.0 performing exceptionally well. These results position Lumina-mGPT 2.0 as a strong, flexible foundation model for unified multimodal generation. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-mGPT-2.0.