 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
May 21, 2025



Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that, for the first time, integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink's core innovations include: \textbf{(i) Structured Data Generation}, by establishing an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model's tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate AgentThink significantly boosts overall reasoning scores by \textbf{53.91\%} and enhances answer accuracy by \textbf{33.54\%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models.
Fast Camera Image Denoising on Mobile GPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

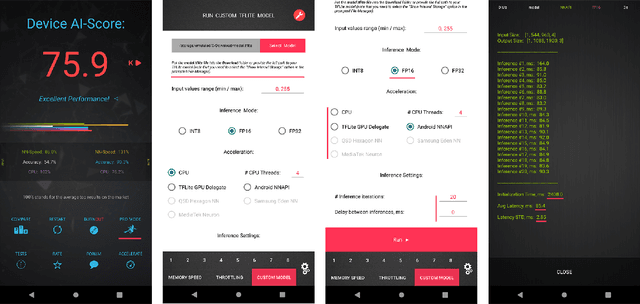
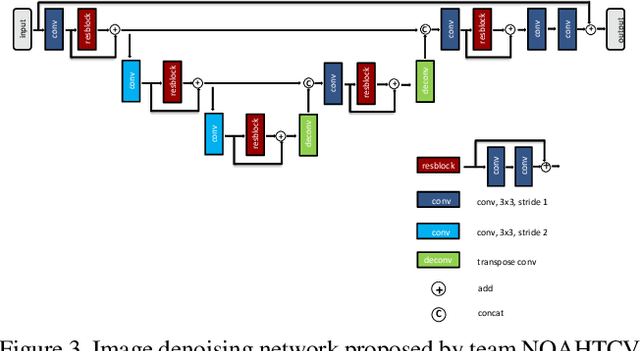
Image denoising is one of the most critical problems in mobile photo processing. While many solutions have been proposed for this task, they are usually working with synthetic data and are too computationally expensive to run on mobile devices. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image denoising solution that can demonstrate high efficiency on smartphone GPUs. For this, the participants were provided with a novel large-scale dataset consisting of noisy-clean image pairs captured in the wild. The runtime of all models was evaluated on the Samsung Exynos 2100 chipset with a powerful Mali GPU capable of accelerating floating-point and quantized neural networks. The proposed solutions are fully compatible with any mobile GPU and are capable of processing 480p resolution images under 40-80 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
Fair DARTS: Eliminating Unfair Advantages in Differentiable Architecture Search
Nov 27, 2019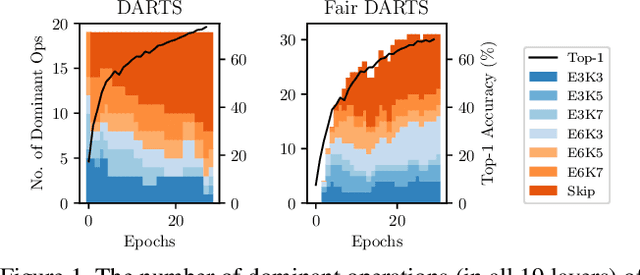

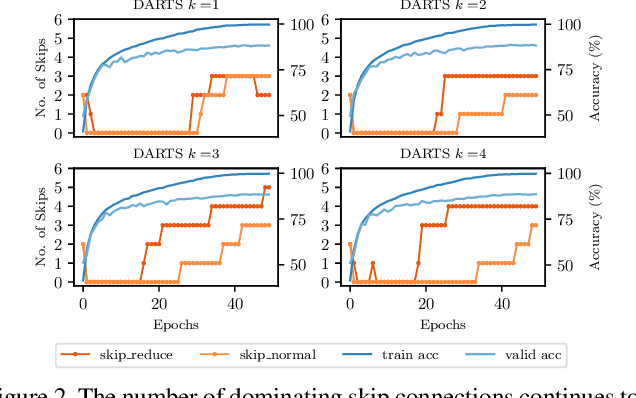
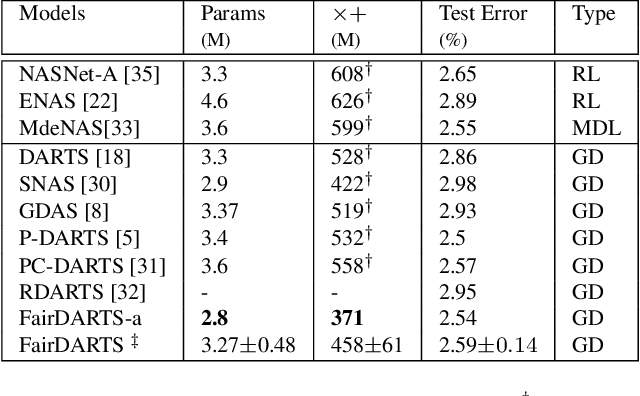
Differential Architecture Search (DARTS) is now a widely disseminated weight-sharing neural architecture search method. However, there are two fundamental weaknesses remain untackled. First, we observe that the well-known aggregation of skip connections during optimization is caused by an unfair advantage in an exclusive competition. Second, there is a non-negligible incongruence when discretizing continuous architectural weights to a one-hot representation. Because of these two reasons, DARTS delivers a biased solution that might not even be suboptimal. In this paper, we present a novel approach to curing both frailties. Specifically, as unfair advantages in a pure exclusive competition easily induce a monopoly, we relax the choice of operations to be collaborative, where we let each operation have an equal opportunity to develop its strength. We thus call our method Fair DARTS. Moreover, we propose a zero-one loss to directly reduce the discretization gap. Experiments are performed on two mainstream search spaces, in which we achieve new state-of-the-art networks on ImageNet. Our code is available on https://github.com/xiaomi-automl/fairdarts.