 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo OWL-ViT: Temporally-consistent open-world localization in video
Aug 22, 2023We present an architecture and a training recipe that adapts pre-trained open-world image models to localization in videos. Understanding the open visual world (without being constrained by fixed label spaces) is crucial for many real-world vision tasks. Contrastive pre-training on large image-text datasets has recently led to significant improvements for image-level tasks. For more structured tasks involving object localization applying pre-trained models is more challenging. This is particularly true for video tasks, where task-specific data is limited. We show successful transfer of open-world models by building on the OWL-ViT open-vocabulary detection model and adapting it to video by adding a transformer decoder. The decoder propagates object representations recurrently through time by using the output tokens for one frame as the object queries for the next. Our model is end-to-end trainable on video data and enjoys improved temporal consistency compared to tracking-by-detection baselines, while retaining the open-world capabilities of the backbone detector. We evaluate our model on the challenging TAO-OW benchmark and demonstrate that open-world capabilities, learned from large-scale image-text pre-training, can be transferred successfully to open-world localization across diverse videos.
One-shot Imitation Learning via Interaction Warping
Jun 21, 2023



Imitation learning of robot policies from few demonstrations is crucial in open-ended applications. We propose a new method, Interaction Warping, for learning SE(3) robotic manipulation policies from a single demonstration. We infer the 3D mesh of each object in the environment using shape warping, a technique for aligning point clouds across object instances. Then, we represent manipulation actions as keypoints on objects, which can be warped with the shape of the object. We show successful one-shot imitation learning on three simulated and real-world object re-arrangement tasks. We also demonstrate the ability of our method to predict object meshes and robot grasps in the wild.
DORSal: Diffusion for Object-centric Representations of Scenes $\textit{et al.}$
Jun 13, 2023Recent progress in 3D scene understanding enables scalable learning of representations across large datasets of diverse scenes. As a consequence, generalization to unseen scenes and objects, rendering novel views from just a single or a handful of input images, and controllable scene generation that supports editing, is now possible. However, training jointly on a large number of scenes typically compromises rendering quality when compared to single-scene optimized models such as NeRFs. In this paper, we leverage recent progress in diffusion models to equip 3D scene representation learning models with the ability to render high-fidelity novel views, while retaining benefits such as object-level scene editing to a large degree. In particular, we propose DORSal, which adapts a video diffusion architecture for 3D scene generation conditioned on object-centric slot-based representations of scenes. On both complex synthetic multi-object scenes and on the real-world large-scale Street View dataset, we show that DORSal enables scalable neural rendering of 3D scenes with object-level editing and improves upon existing approaches.
Sensitivity of Slot-Based Object-Centric Models to their Number of Slots
May 30, 2023



Self-supervised methods for learning object-centric representations have recently been applied successfully to various datasets. This progress is largely fueled by slot-based methods, whose ability to cluster visual scenes into meaningful objects holds great promise for compositional generalization and downstream learning. In these methods, the number of slots (clusters) $K$ is typically chosen to match the number of ground-truth objects in the data, even though this quantity is unknown in real-world settings. Indeed, the sensitivity of slot-based methods to $K$, and how this affects their learned correspondence to objects in the data has largely been ignored in the literature. In this work, we address this issue through a systematic study of slot-based methods. We propose using analogs to precision and recall based on the Adjusted Rand Index to accurately quantify model behavior over a large range of $K$. We find that, especially during training, incorrect choices of $K$ do not yield the desired object decomposition and, in fact, cause substantial oversegmentation or merging of separate objects (undersegmentation). We demonstrate that the choice of the objective function and incorporating instance-level annotations can moderately mitigate this behavior while still falling short of fully resolving this issue. Indeed, we show how this issue persists across multiple methods and datasets and stress its importance for future slot-based models.
AudioSlots: A slot-centric generative model for audio separation
May 09, 2023In a range of recent works, object-centric architectures have been shown to be suitable for unsupervised scene decomposition in the vision domain. Inspired by these methods we present AudioSlots, a slot-centric generative model for blind source separation in the audio domain. AudioSlots is built using permutation-equivariant encoder and decoder networks. The encoder network based on the Transformer architecture learns to map a mixed audio spectrogram to an unordered set of independent source embeddings. The spatial broadcast decoder network learns to generate the source spectrograms from the source embeddings. We train the model in an end-to-end manner using a permutation invariant loss function. Our results on Libri2Mix speech separation constitute a proof of concept that this approach shows promise. We discuss the results and limitations of our approach in detail, and further outline potential ways to overcome the limitations and directions for future work.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.
Invariant Slot Attention: Object Discovery with Slot-Centric Reference Frames
Feb 09, 2023



Automatically discovering composable abstractions from raw perceptual data is a long-standing challenge in machine learning. Recent slot-based neural networks that learn about objects in a self-supervised manner have made exciting progress in this direction. However, they typically fall short at adequately capturing spatial symmetries present in the visual world, which leads to sample inefficiency, such as when entangling object appearance and pose. In this paper, we present a simple yet highly effective method for incorporating spatial symmetries via slot-centric reference frames. We incorporate equivariance to per-object pose transformations into the attention and generation mechanism of Slot Attention by translating, scaling, and rotating position encodings. These changes result in little computational overhead, are easy to implement, and can result in large gains in terms of data efficiency and overall improvements to object discovery. We evaluate our method on a wide range of synthetic object discovery benchmarks namely CLEVR, Tetrominoes, CLEVRTex, Objects Room and MultiShapeNet, and show promising improvements on the challenging real-world Waymo Open dataset.
RUST: Latent Neural Scene Representations from Unposed Imagery
Nov 25, 2022



Inferring the structure of 3D scenes from 2D observations is a fundamental challenge in computer vision. Recently popularized approaches based on neural scene representations have achieved tremendous impact and have been applied across a variety of applications. One of the major remaining challenges in this space is training a single model which can provide latent representations which effectively generalize beyond a single scene. Scene Representation Transformer (SRT) has shown promise in this direction, but scaling it to a larger set of diverse scenes is challenging and necessitates accurately posed ground truth data. To address this problem, we propose RUST (Really Unposed Scene representation Transformer), a pose-free approach to novel view synthesis trained on RGB images alone. Our main insight is that one can train a Pose Encoder that peeks at the target image and learns a latent pose embedding which is used by the decoder for view synthesis. We perform an empirical investigation into the learned latent pose structure and show that it allows meaningful test-time camera transformations and accurate explicit pose readouts. Perhaps surprisingly, RUST achieves similar quality as methods which have access to perfect camera pose, thereby unlocking the potential for large-scale training of amortized neural scene representations.
Towards Better Out-of-Distribution Generalization of Neural Algorithmic Reasoning Tasks
Nov 01, 2022



In this paper, we study the OOD generalization of neural algorithmic reasoning tasks, where the goal is to learn an algorithm (e.g., sorting, breadth-first search, and depth-first search) from input-output pairs using deep neural networks. First, we argue that OOD generalization in this setting is significantly different than common OOD settings. For example, some phenomena in OOD generalization of image classifications such as \emph{accuracy on the line} are not observed here, and techniques such as data augmentation methods do not help as assumptions underlying many augmentation techniques are often violated. Second, we analyze the main challenges (e.g., input distribution shift, non-representative data generation, and uninformative validation metrics) of the current leading benchmark, i.e., CLRS \citep{deepmind2021clrs}, which contains 30 algorithmic reasoning tasks. We propose several solutions, including a simple-yet-effective fix to the input distribution shift and improved data generation. Finally, we propose an attention-based 2WL-graph neural network (GNN) processor which complements message-passing GNNs so their combination outperforms the state-of-the-art model by a 3% margin averaged over all algorithms. Our code is available at: \url{https://github.com/smahdavi4/clrs}.
SlotFormer: Unsupervised Visual Dynamics Simulation with Object-Centric Models
Oct 12, 2022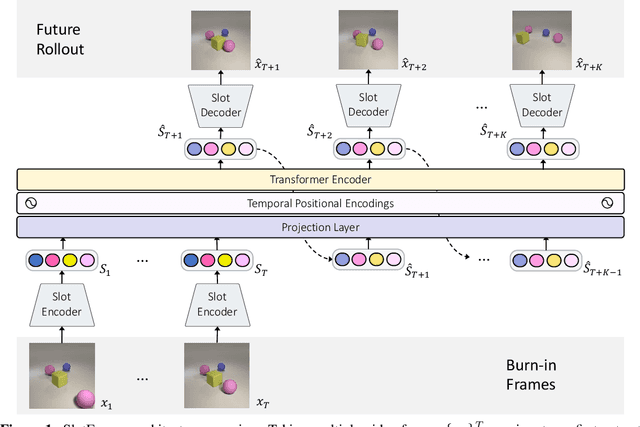
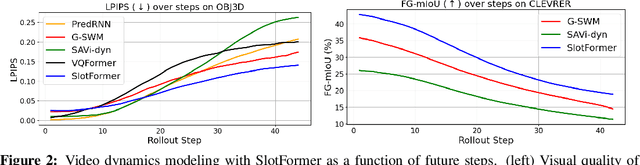
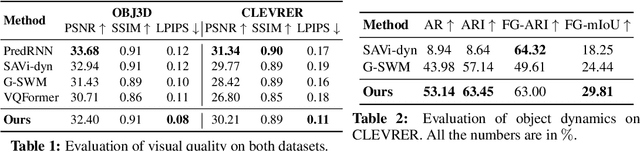
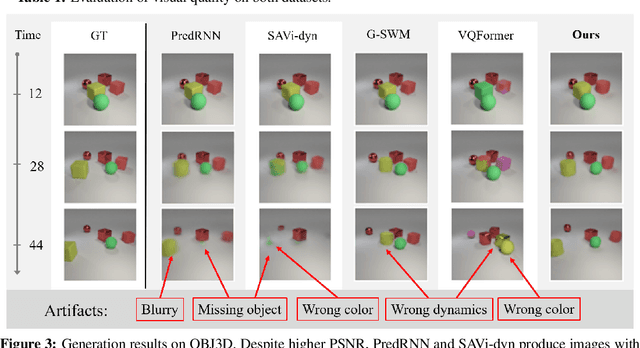
Understanding dynamics from visual observations is a challenging problem that requires disentangling individual objects from the scene and learning their interactions. While recent object-centric models can successfully decompose a scene into objects, modeling their dynamics effectively still remains a challenge. We address this problem by introducing SlotFormer -- a Transformer-based autoregressive model operating on learned object-centric representations. Given a video clip, our approach reasons over object features to model spatio-temporal relationships and predicts accurate future object states. In this paper, we successfully apply SlotFormer to perform video prediction on datasets with complex object interactions. Moreover, the unsupervised SlotFormer's dynamics model can be used to improve the performance on supervised downstream tasks, such as Visual Question Answering (VQA), and goal-conditioned planning. Compared to past works on dynamics modeling, our method achieves significantly better long-term synthesis of object dynamics, while retaining high quality visual generation. Besides, SlotFormer enables VQA models to reason about the future without object-level labels, even outperforming counterparts that use ground-truth annotations. Finally, we show its ability to serve as a world model for model-based planning, which is competitive with methods designed specifically for such tasks.