 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTS2C: Tight Box Mining with Surrounding Segmentation Context for Weakly Supervised Object Detection
Jul 13, 2018

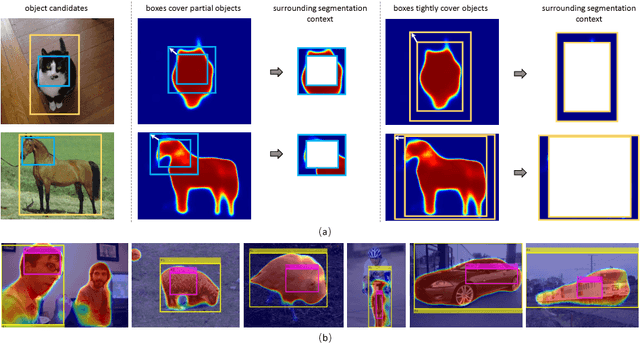
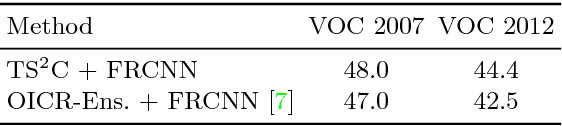
This work provides a simple approach to discover tight object bounding boxes with only image-level supervision, called Tight box mining with Surrounding Segmentation Context (TS2C). We observe that object candidates mined through current multiple instance learning methods are usually trapped to discriminative object parts, rather than the entire object. TS2C leverages surrounding segmentation context derived from weakly-supervised segmentation to suppress such low-quality distracting candidates and boost the high-quality ones. Specifically, TS2C is developed based on two key properties of desirable bounding boxes: 1) high purity, meaning most pixels in the box are with high object response, and 2) high completeness, meaning the box covers high object response pixels comprehensively. With such novel and computable criteria, more tight candidates can be discovered for learning a better object detector. With TS2C, we obtain 48.0% and 44.4% mAP scores on VOC 2007 and 2012 benchmarks, which are the new state-of-the-arts.
Survey of Face Detection on Low-quality Images
Apr 19, 2018
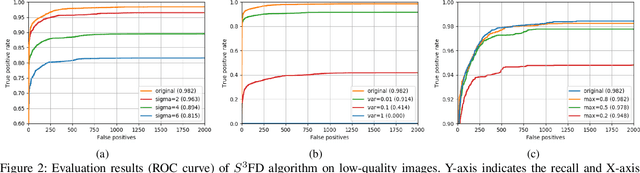
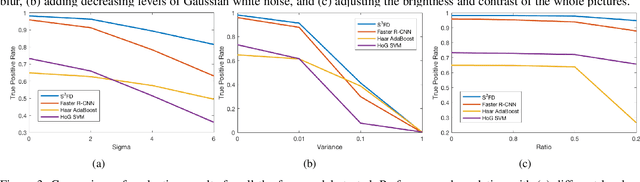
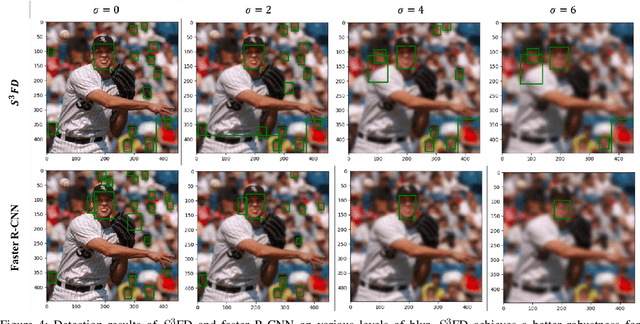
Face detection is a well-explored problem. Many challenges on face detectors like extreme pose, illumination, low resolution and small scales are studied in the previous work. However, previous proposed models are mostly trained and tested on good-quality images which are not always the case for practical applications like surveillance systems. In this paper, we first review the current state-of-the-art face detectors and their performance on benchmark dataset FDDB, and compare the design protocols of the algorithms. Secondly, we investigate their performance degradation while testing on low-quality images with different levels of blur, noise, and contrast. Our results demonstrate that both hand-crafted and deep-learning based face detectors are not robust enough for low-quality images. It inspires researchers to produce more robust design for face detection in the wild.
Unsupervised Representation Adversarial Learning Network: from Reconstruction to Generation
Apr 19, 2018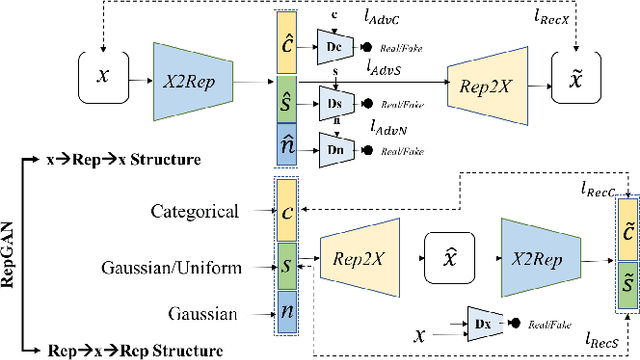


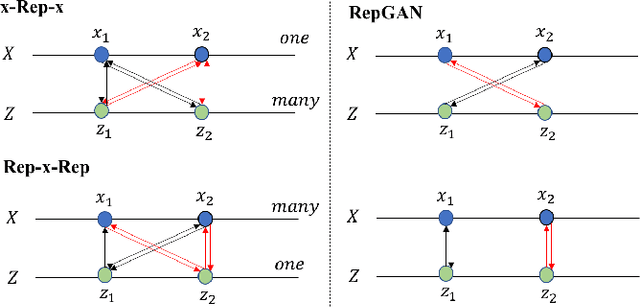
A good representation for arbitrarily complicated data should have the capability of semantic generation, clustering and reconstruction. Previous research has already achieved impressive performance on either one. This paper aims at learning a disentangled representation effective for all of them in an unsupervised way. To achieve all the three tasks together, we learn the forward and inverse mapping between data and representation on the basis of a symmetric adversarial process. In theory, we minimize the upper bound of the two conditional entropy loss between the latent variables and the observations together to achieve the cycle consistency. The newly proposed RepGAN is tested on MNIST, fashionMNIST, CelebA, and SVHN datasets to perform unsupervised or semi-supervised classification, generation and reconstruction tasks. The result demonstrates that RepGAN is able to learn a useful and competitive representation. To the author's knowledge, our work is the first one to achieve both a high unsupervised classification accuracy and low reconstruction error on MNIST.
Adversarial Complementary Learning for Weakly Supervised Object Localization
Apr 19, 2018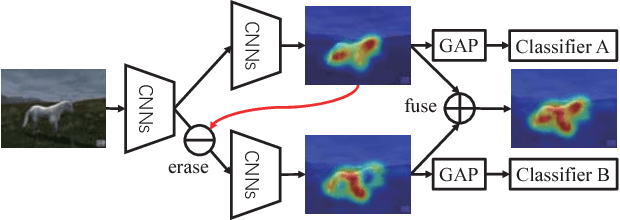
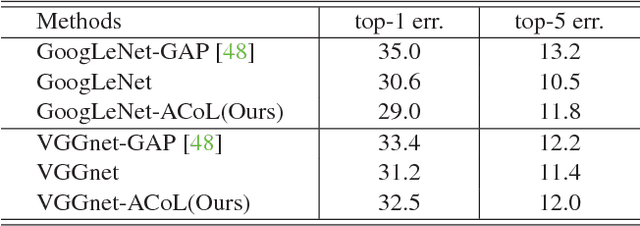

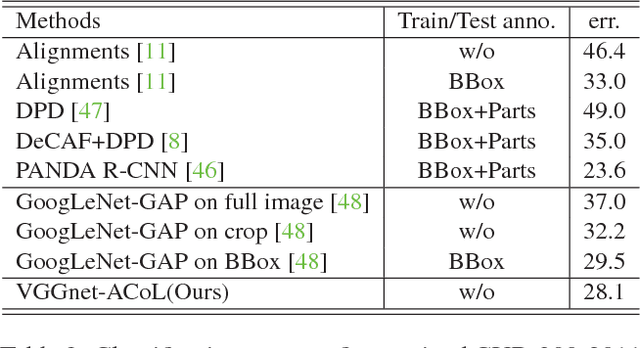
In this work, we propose Adversarial Complementary Learning (ACoL) to automatically localize integral objects of semantic interest with weak supervision. We first mathematically prove that class localization maps can be obtained by directly selecting the class-specific feature maps of the last convolutional layer, which paves a simple way to identify object regions. We then present a simple network architecture including two parallel-classifiers for object localization. Specifically, we leverage one classification branch to dynamically localize some discriminative object regions during the forward pass. Although it is usually responsive to sparse parts of the target objects, this classifier can drive the counterpart classifier to discover new and complementary object regions by erasing its discovered regions from the feature maps. With such an adversarial learning, the two parallel-classifiers are forced to leverage complementary object regions for classification and can finally generate integral object localization together. The merits of ACoL are mainly two-fold: 1) it can be trained in an end-to-end manner; 2) dynamically erasing enables the counterpart classifier to discover complementary object regions more effectively. We demonstrate the superiority of our ACoL approach in a variety of experiments. In particular, the Top-1 localization error rate on the ILSVRC dataset is 45.14%, which is the new state-of-the-art.
Deep GrabCut for Object Selection
Jul 14, 2017
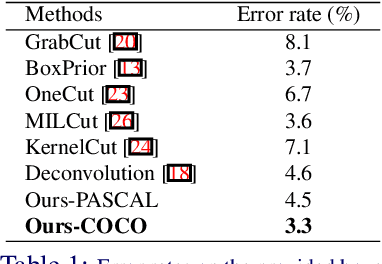
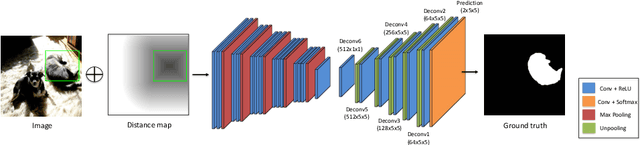
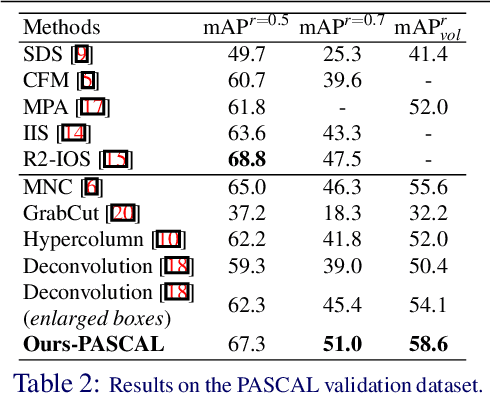
Most previous bounding-box-based segmentation methods assume the bounding box tightly covers the object of interest. However it is common that a rectangle input could be too large or too small. In this paper, we propose a novel segmentation approach that uses a rectangle as a soft constraint by transforming it into an Euclidean distance map. A convolutional encoder-decoder network is trained end-to-end by concatenating images with these distance maps as inputs and predicting the object masks as outputs. Our approach gets accurate segmentation results given sloppy rectangles while being general for both interactive segmentation and instance segmentation. We show our network extends to curve-based input without retraining. We further apply our network to instance-level semantic segmentation and resolve any overlap using a conditional random field. Experiments on benchmark datasets demonstrate the effectiveness of the proposed approaches.
Deep Image Matting
Apr 11, 2017
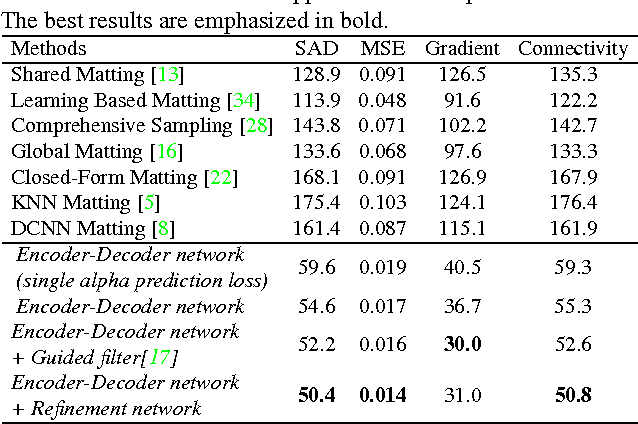

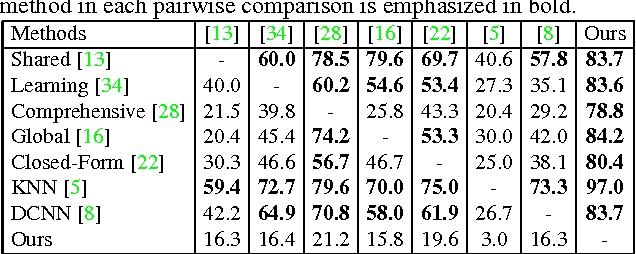
Image matting is a fundamental computer vision problem and has many applications. Previous algorithms have poor performance when an image has similar foreground and background colors or complicated textures. The main reasons are prior methods 1) only use low-level features and 2) lack high-level context. In this paper, we propose a novel deep learning based algorithm that can tackle both these problems. Our deep model has two parts. The first part is a deep convolutional encoder-decoder network that takes an image and the corresponding trimap as inputs and predict the alpha matte of the image. The second part is a small convolutional network that refines the alpha matte predictions of the first network to have more accurate alpha values and sharper edges. In addition, we also create a large-scale image matting dataset including 49300 training images and 1000 testing images. We evaluate our algorithm on the image matting benchmark, our testing set, and a wide variety of real images. Experimental results clearly demonstrate the superiority of our algorithm over previous methods.
Joint Intermodal and Intramodal Label Transfers for Extremely Rare or Unseen Classes
Mar 22, 2017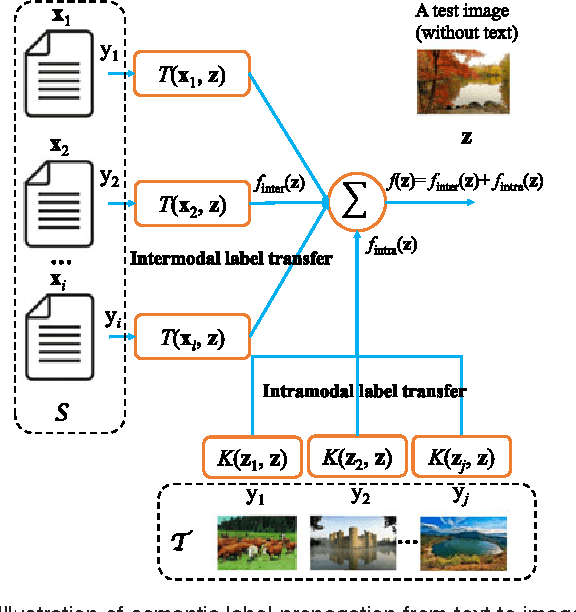
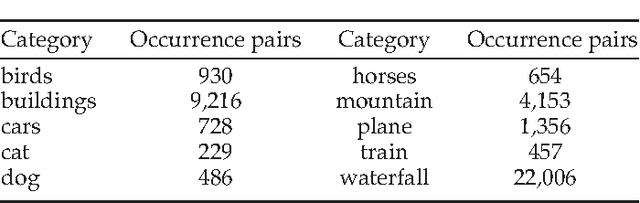
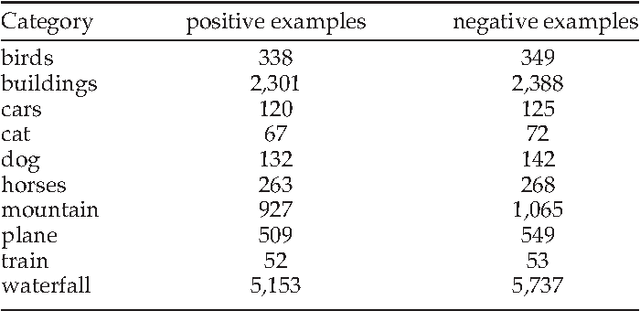
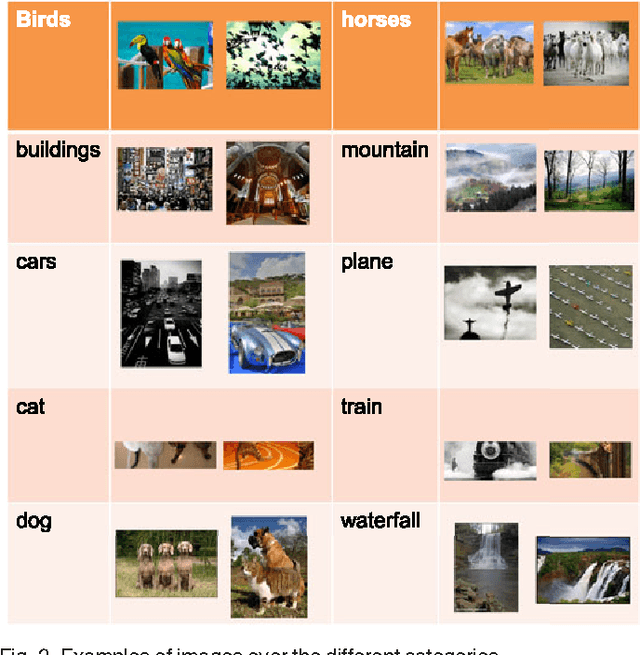
In this paper, we present a label transfer model from texts to images for image classification tasks. The problem of image classification is often much more challenging than text classification. On one hand, labeled text data is more widely available than the labeled images for classification tasks. On the other hand, text data tends to have natural semantic interpretability, and they are often more directly related to class labels. On the contrary, the image features are not directly related to concepts inherent in class labels. One of our goals in this paper is to develop a model for revealing the functional relationships between text and image features as to directly transfer intermodal and intramodal labels to annotate the images. This is implemented by learning a transfer function as a bridge to propagate the labels between two multimodal spaces. However, the intermodal label transfers could be undermined by blindly transferring the labels of noisy texts to annotate images. To mitigate this problem, we present an intramodal label transfer process, which complements the intermodal label transfer by transferring the image labels instead when relevant text is absent from the source corpus. In addition, we generalize the inter-modal label transfer to zero-shot learning scenario where there are only text examples available to label unseen classes of images without any positive image examples. We evaluate our algorithm on an image classification task and show the effectiveness with respect to the other compared algorithms.
Learning a Mixture of Deep Networks for Single Image Super-Resolution
Jan 03, 2017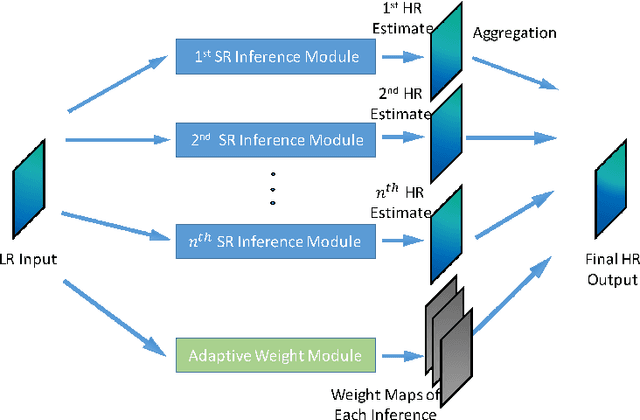
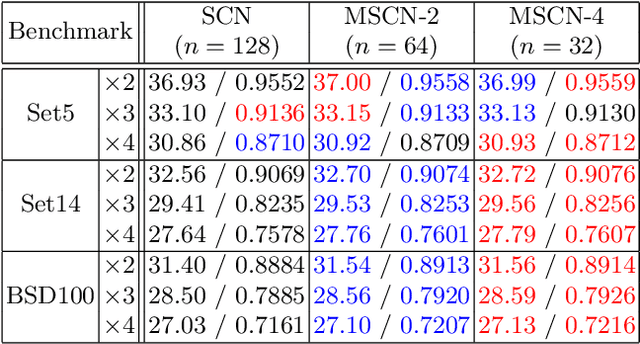
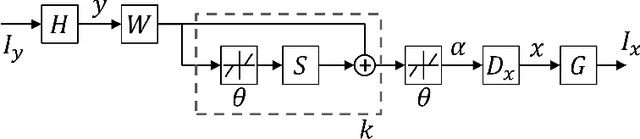
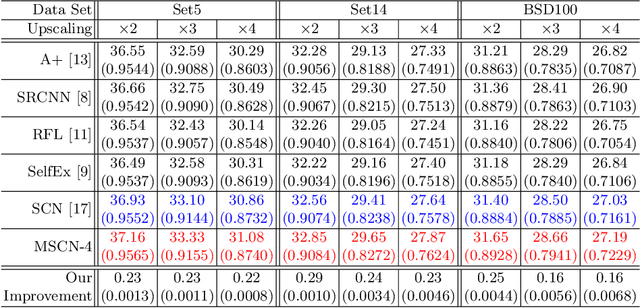
Single image super-resolution (SR) is an ill-posed problem which aims to recover high-resolution (HR) images from their low-resolution (LR) observations. The crux of this problem lies in learning the complex mapping between low-resolution patches and the corresponding high-resolution patches. Prior arts have used either a mixture of simple regression models or a single non-linear neural network for this propose. This paper proposes the method of learning a mixture of SR inference modules in a unified framework to tackle this problem. Specifically, a number of SR inference modules specialized in different image local patterns are first independently applied on the LR image to obtain various HR estimates, and the resultant HR estimates are adaptively aggregated to form the final HR image. By selecting neural networks as the SR inference module, the whole procedure can be incorporated into a unified network and be optimized jointly. Extensive experiments are conducted to investigate the relation between restoration performance and different network architectures. Compared with other current image SR approaches, our proposed method achieves state-of-the-arts restoration results on a wide range of images consistently while allowing more flexible design choices. The source codes are available in http://www.ifp.illinois.edu/~dingliu2/accv2016.
UnitBox: An Advanced Object Detection Network
Aug 04, 2016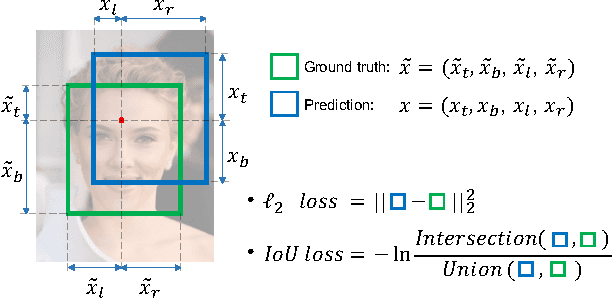
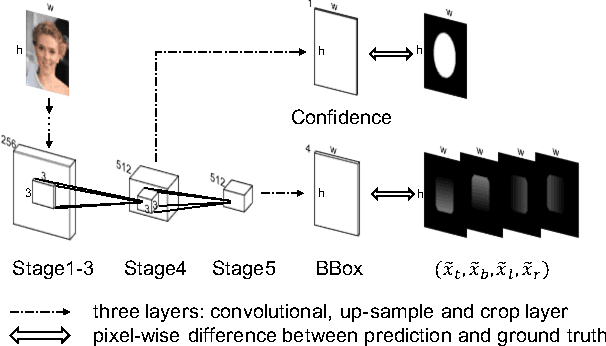

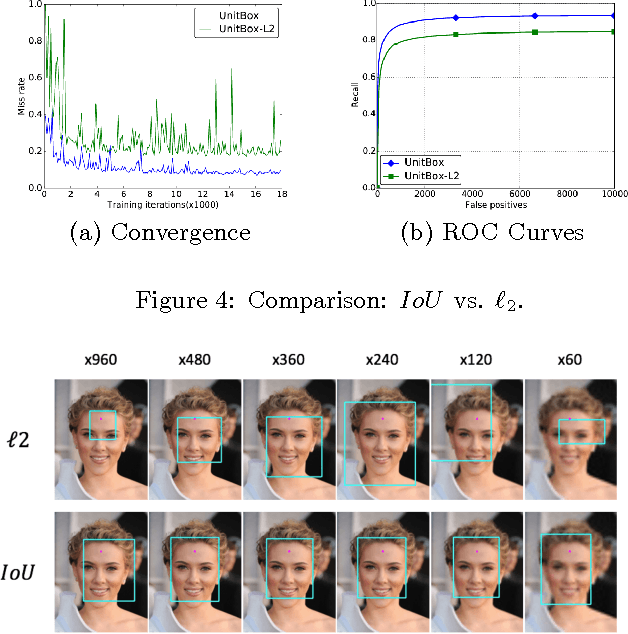
In present object detection systems, the deep convolutional neural networks (CNNs) are utilized to predict bounding boxes of object candidates, and have gained performance advantages over the traditional region proposal methods. However, existing deep CNN methods assume the object bounds to be four independent variables, which could be regressed by the $\ell_2$ loss separately. Such an oversimplified assumption is contrary to the well-received observation, that those variables are correlated, resulting to less accurate localization. To address the issue, we firstly introduce a novel Intersection over Union ($IoU$) loss function for bounding box prediction, which regresses the four bounds of a predicted box as a whole unit. By taking the advantages of $IoU$ loss and deep fully convolutional networks, the UnitBox is introduced, which performs accurate and efficient localization, shows robust to objects of varied shapes and scales, and converges fast. We apply UnitBox on face detection task and achieve the best performance among all published methods on the FDDB benchmark.
Deep Interactive Object Selection
Mar 13, 2016
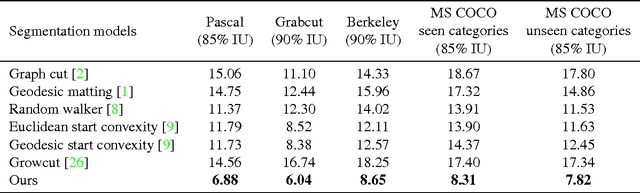

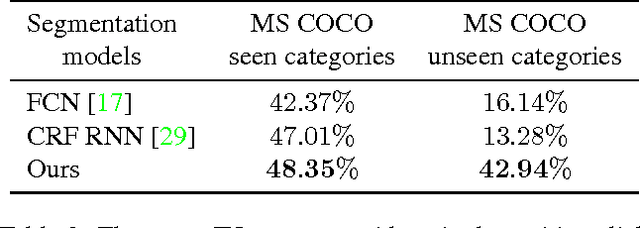
Interactive object selection is a very important research problem and has many applications. Previous algorithms require substantial user interactions to estimate the foreground and background distributions. In this paper, we present a novel deep learning based algorithm which has a much better understanding of objectness and thus can reduce user interactions to just a few clicks. Our algorithm transforms user provided positive and negative clicks into two Euclidean distance maps which are then concatenated with the RGB channels of images to compose (image, user interactions) pairs. We generate many of such pairs by combining several random sampling strategies to model user click patterns and use them to fine tune deep Fully Convolutional Networks (FCNs). Finally the output probability maps of our FCN 8s model is integrated with graph cut optimization to refine the boundary segments. Our model is trained on the PASCAL segmentation dataset and evaluated on other datasets with different object classes. Experimental results on both seen and unseen objects clearly demonstrate that our algorithm has a good generalization ability and is superior to all existing interactive object selection approaches.