 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Event Grounding
Feb 08, 2023



Event grounding aims at linking mention references in text corpora to events from a knowledge base (KB). Previous work on this task focused primarily on linking to a single KB event, thereby overlooking the hierarchical aspects of events. Events in documents are typically described at various levels of spatio-temporal granularity (Glavas et al. 2014). These hierarchical relations are utilized in downstream tasks of narrative understanding and schema construction. In this work, we present an extension to the event grounding task that requires tackling hierarchical event structures from the KB. Our proposed task involves linking a mention reference to a set of event labels from a subevent hierarchy in the KB. We propose a retrieval methodology that leverages event hierarchy through an auxiliary hierarchical loss (Murty et al. 2018). On an automatically created multilingual dataset from Wikipedia and Wikidata, our experiments demonstrate the effectiveness of the hierarchical loss against retrieve and re-rank baselines (Wu et al. 2020; Pratapa, Gupta, and Mitamura 2022). Furthermore, we demonstrate the systems' ability to aid hierarchical discovery among unseen events.
GSRFormer: Grounded Situation Recognition Transformer with Alternate Semantic Attention Refinement
Sep 01, 2022
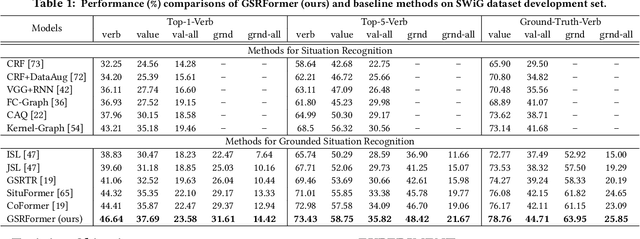

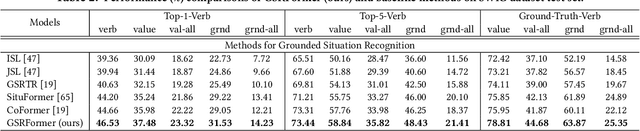
Grounded Situation Recognition (GSR) aims to generate structured semantic summaries of images for "human-like" event understanding. Specifically, GSR task not only detects the salient activity verb (e.g. buying), but also predicts all corresponding semantic roles (e.g. agent and goods). Inspired by object detection and image captioning tasks, existing methods typically employ a two-stage framework: 1) detect the activity verb, and then 2) predict semantic roles based on the detected verb. Obviously, this illogical framework constitutes a huge obstacle to semantic understanding. First, pre-detecting verbs solely without semantic roles inevitably fails to distinguish many similar daily activities (e.g., offering and giving, buying and selling). Second, predicting semantic roles in a closed auto-regressive manner can hardly exploit the semantic relations among the verb and roles. To this end, in this paper we propose a novel two-stage framework that focuses on utilizing such bidirectional relations within verbs and roles. In the first stage, instead of pre-detecting the verb, we postpone the detection step and assume a pseudo label, where an intermediate representation for each corresponding semantic role is learned from images. In the second stage, we exploit transformer layers to unearth the potential semantic relations within both verbs and semantic roles. With the help of a set of support images, an alternate learning scheme is designed to simultaneously optimize the results: update the verb using nouns corresponding to the image, and update nouns using verbs from support images. Extensive experimental results on challenging SWiG benchmarks show that our renovated framework outperforms other state-of-the-art methods under various metrics.
Multilingual Event Linking to Wikidata
Apr 13, 2022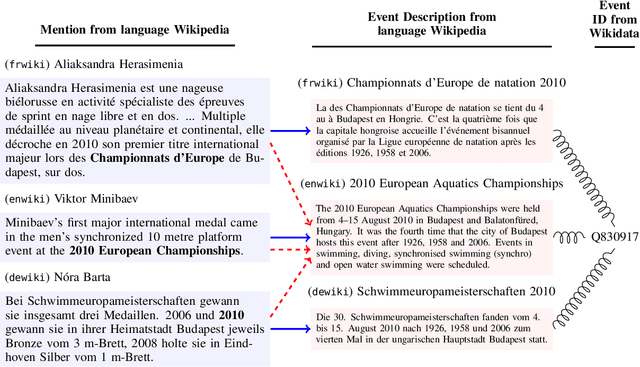
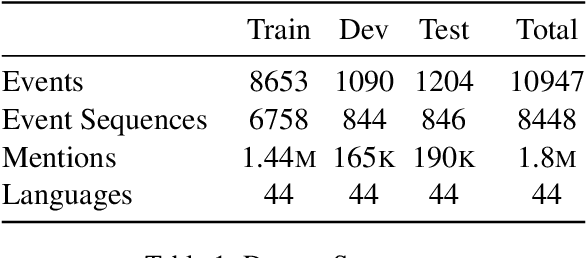


We present a task of multilingual linking of events to a knowledge base. We automatically compile a large-scale dataset for this task, comprising of 1.8M mentions across 44 languages referring to over 10.9K events from Wikidata. We propose two variants of the event linking task: 1) multilingual, where event descriptions are from the same language as the mention, and 2) crosslingual, where all event descriptions are in English. On the two proposed tasks, we compare multiple event linking systems including BM25+ (Lv and Zhai, 2011) and multilingual adaptations of the biencoder and crossencoder architectures from BLINK (Wu et al., 2020). In our experiments on the two task variants, we find both biencoder and crossencoder models significantly outperform the BM25+ baseline. Our results also indicate that the crosslingual task is in general more challenging than the multilingual task. To test the out-of-domain generalization of the proposed linking systems, we additionally create a Wikinews-based evaluation set. We present qualitative analysis highlighting various aspects captured by the proposed dataset, including the need for temporal reasoning over context and tackling diverse event descriptions across languages.
Cross-document Event Identity via Dense Annotation
Sep 14, 2021
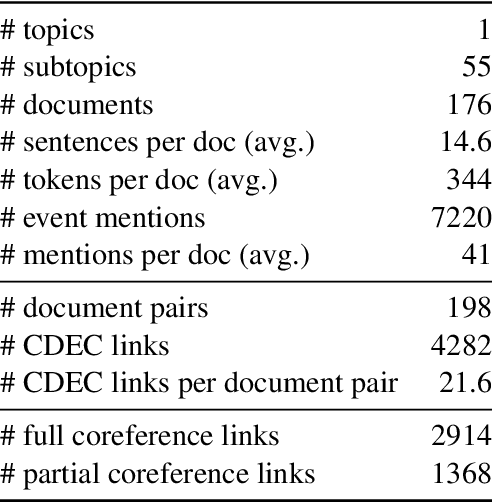


In this paper, we study the identity of textual events from different documents. While the complex nature of event identity is previously studied (Hovy et al., 2013), the case of events across documents is unclear. Prior work on cross-document event coreference has two main drawbacks. First, they restrict the annotations to a limited set of event types. Second, they insufficiently tackle the concept of event identity. Such annotation setup reduces the pool of event mentions and prevents one from considering the possibility of quasi-identity relations. We propose a dense annotation approach for cross-document event coreference, comprising a rich source of event mentions and a dense annotation effort between related document pairs. To this end, we design a new annotation workflow with careful quality control and an easy-to-use annotation interface. In addition to the links, we further collect overlapping event contexts, including time, location, and participants, to shed some light on the relation between identity decisions and context. We present an open-access dataset for cross-document event coreference, CDEC-WN, collected from English Wikinews and open-source our annotation toolkit to encourage further research on cross-document tasks.
Retrieve, Caption, Generate: Visual Grounding for Enhancing Commonsense in Text Generation Models
Sep 08, 2021
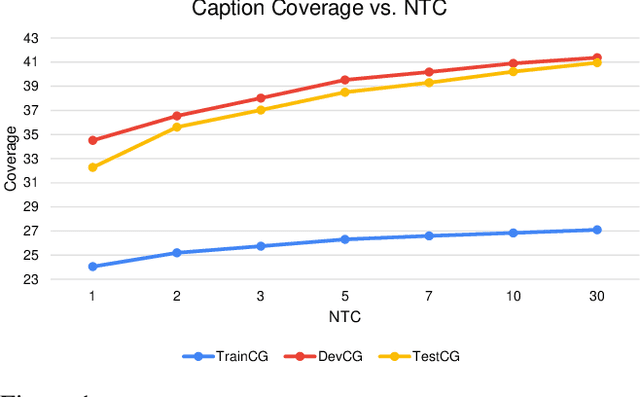
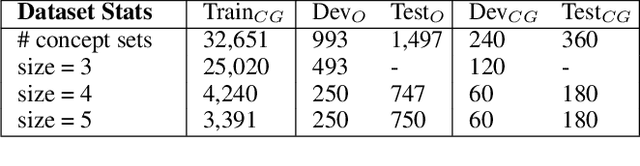
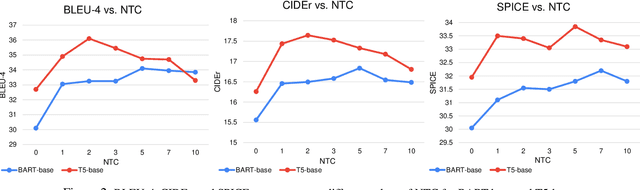
We investigate the use of multimodal information contained in images as an effective method for enhancing the commonsense of Transformer models for text generation. We perform experiments using BART and T5 on concept-to-text generation, specifically the task of generative commonsense reasoning, or CommonGen. We call our approach VisCTG: Visually Grounded Concept-to-Text Generation. VisCTG involves captioning images representing appropriate everyday scenarios, and using these captions to enrich and steer the generation process. Comprehensive evaluation and analysis demonstrate that VisCTG noticeably improves model performance while successfully addressing several issues of the baseline generations, including poor commonsense, fluency, and specificity.
A Survey of Data Augmentation Approaches for NLP
May 29, 2021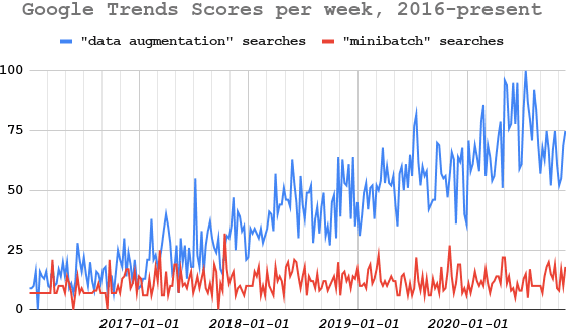
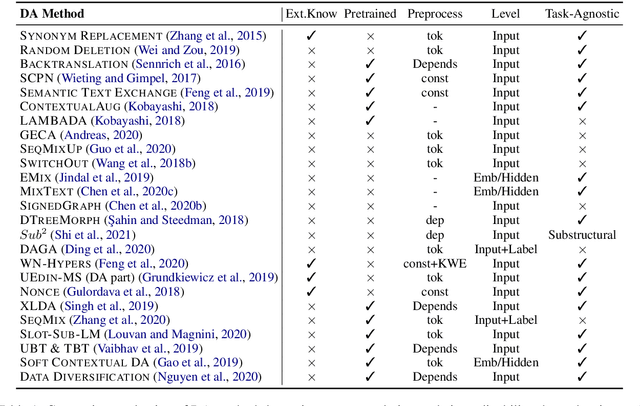
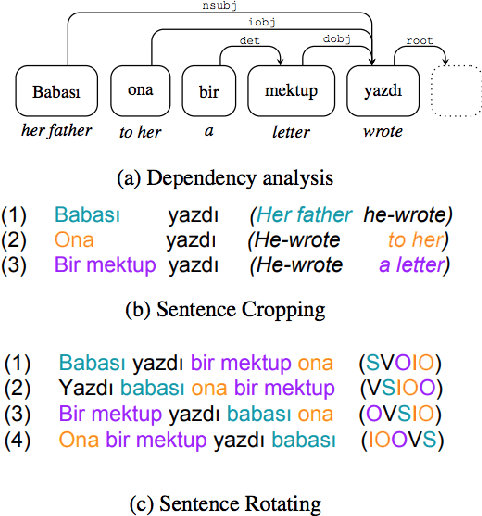
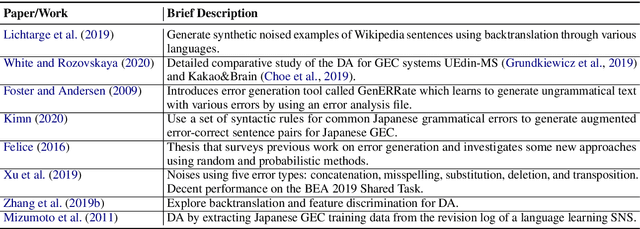
Data augmentation has recently seen increased interest in NLP due to more work in low-resource domains, new tasks, and the popularity of large-scale neural networks that require large amounts of training data. Despite this recent upsurge, this area is still relatively underexplored, perhaps due to the challenges posed by the discrete nature of language data. In this paper, we present a comprehensive and unifying survey of data augmentation for NLP by summarizing the literature in a structured manner. We first introduce and motivate data augmentation for NLP, and then discuss major methodologically representative approaches. Next, we highlight techniques that are used for popular NLP applications and tasks. We conclude by outlining current challenges and directions for future research. Overall, our paper aims to clarify the landscape of existing literature in data augmentation for NLP and motivate additional work in this area. We also present a GitHub repository with a paper list that will be continuously updated at https://github.com/styfeng/DataAug4NLP
NAREOR: The Narrative Reordering Problem
Apr 14, 2021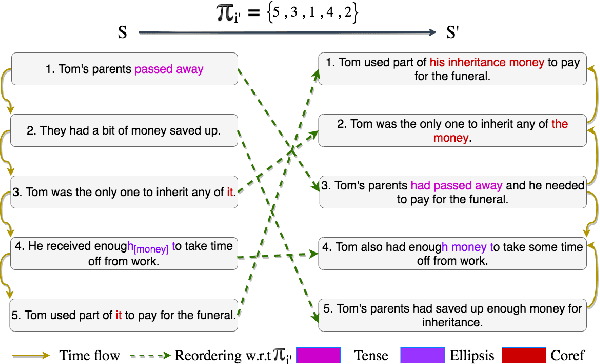

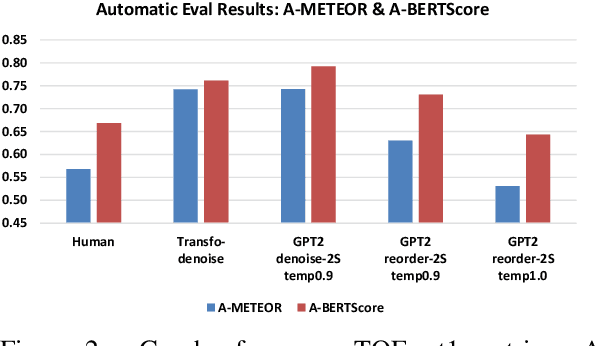
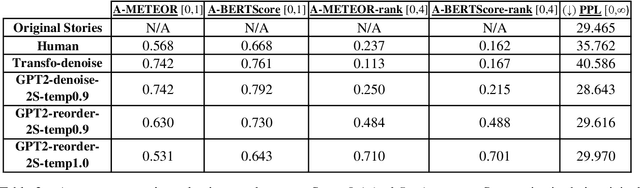
We propose the task of Narrative Reordering(NAREOR) which involves rewriting a given story in a different narrative order while preserving its plot, semantic, and temporal aspects. We present a dataset, NAREORC, with over 1000 human rewritings of stories within ROCStories in non-linear orders, and conduct a detailed analysis of it. Further, we propose novel initial task-specific training methods and evaluation metrics. We perform experiments on NAREORC using GPT-2 and Transformer models and conduct an extensive human evaluation. We demonstrate that NAREOR is a challenging task with potential for further exploration.
A Data-Centric Framework for Composable NLP Workflows
Mar 03, 2021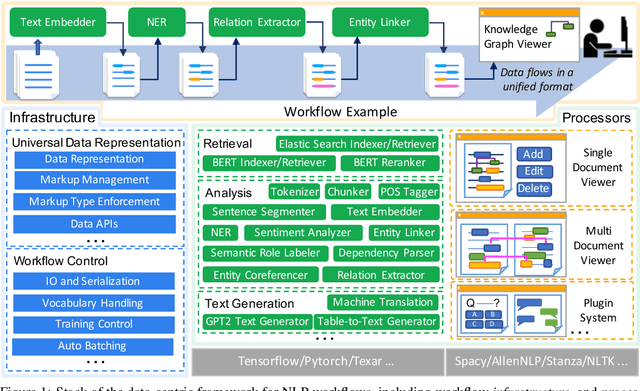
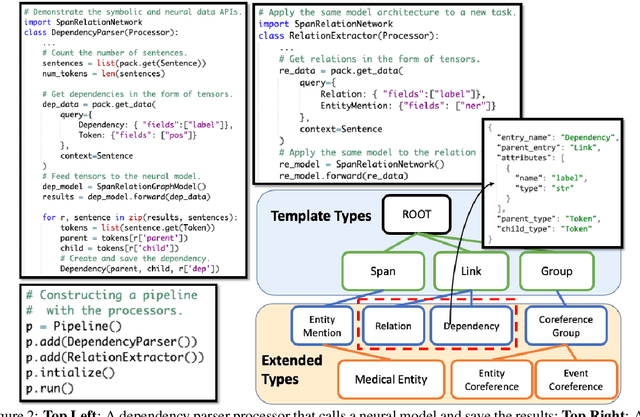
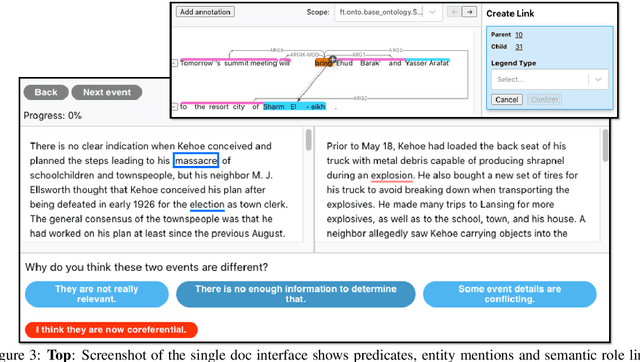
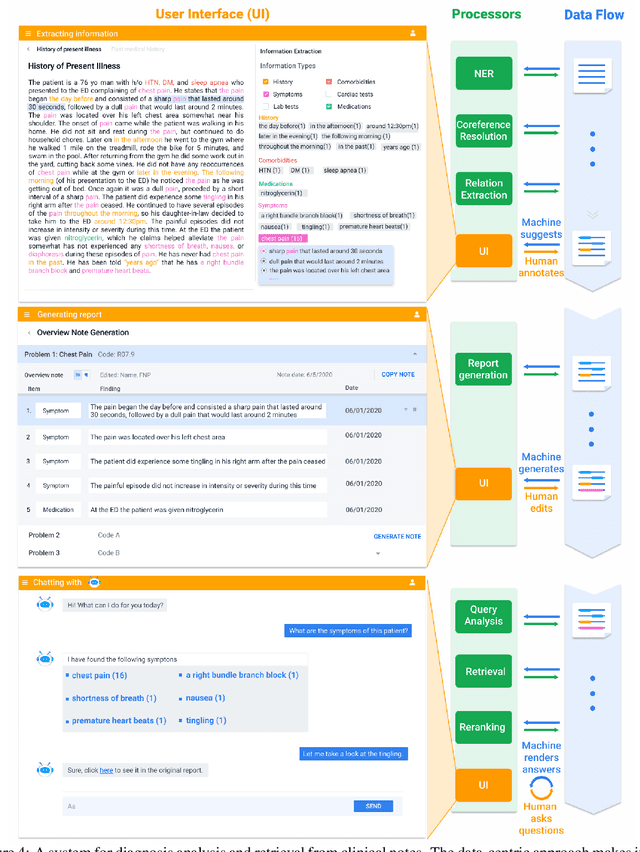
Empirical natural language processing (NLP) systems in application domains (e.g., healthcare, finance, education) involve interoperation among multiple components, ranging from data ingestion, human annotation, to text retrieval, analysis, generation, and visualization. We establish a unified open-source framework to support fast development of such sophisticated NLP workflows in a composable manner. The framework introduces a uniform data representation to encode heterogeneous results by a wide range of NLP tasks. It offers a large repository of processors for NLP tasks, visualization, and annotation, which can be easily assembled with full interoperability under the unified representation. The highly extensible framework allows plugging in custom processors from external off-the-shelf NLP and deep learning libraries. The whole framework is delivered through two modularized yet integratable open-source projects, namely Forte1 (for workflow infrastructure and NLP function processors) and Stave2 (for user interaction, visualization, and annotation).
Understanding the Role of Scene Graphs in Visual Question Answering
Jan 17, 2021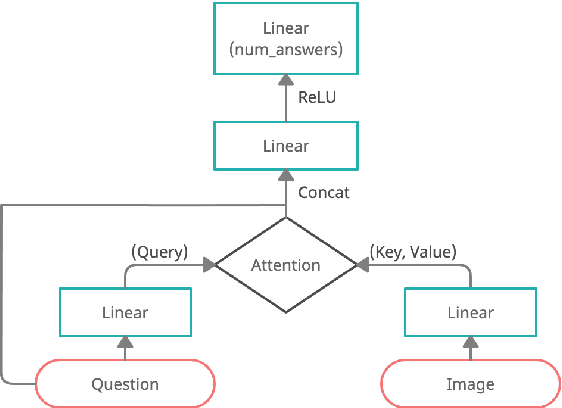
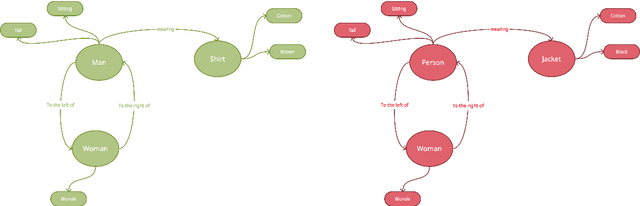
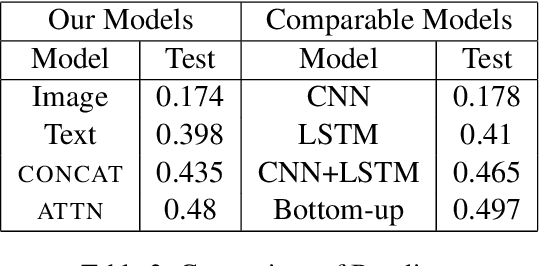
Visual Question Answering (VQA) is of tremendous interest to the research community with important applications such as aiding visually impaired users and image-based search. In this work, we explore the use of scene graphs for solving the VQA task. We conduct experiments on the GQA dataset which presents a challenging set of questions requiring counting, compositionality and advanced reasoning capability, and provides scene graphs for a large number of images. We adopt image + question architectures for use with scene graphs, evaluate various scene graph generation techniques for unseen images, propose a training curriculum to leverage human-annotated and auto-generated scene graphs, and build late fusion architectures to learn from multiple image representations. We present a multi-faceted study into the use of scene graphs for VQA, making this work the first of its kind.
GenAug: Data Augmentation for Finetuning Text Generators
Oct 10, 2020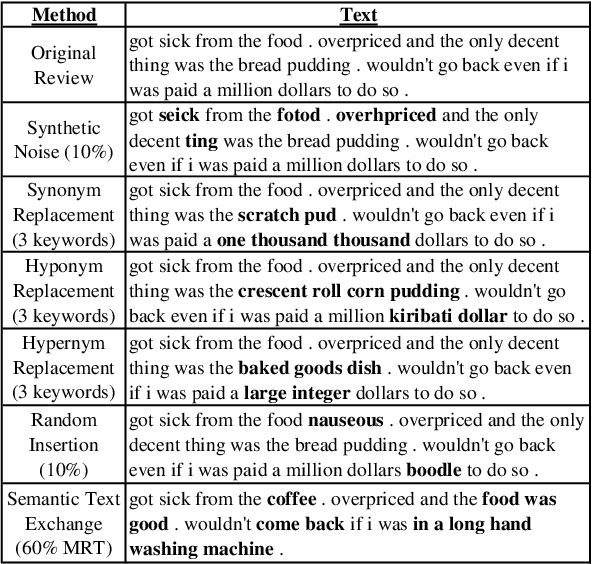
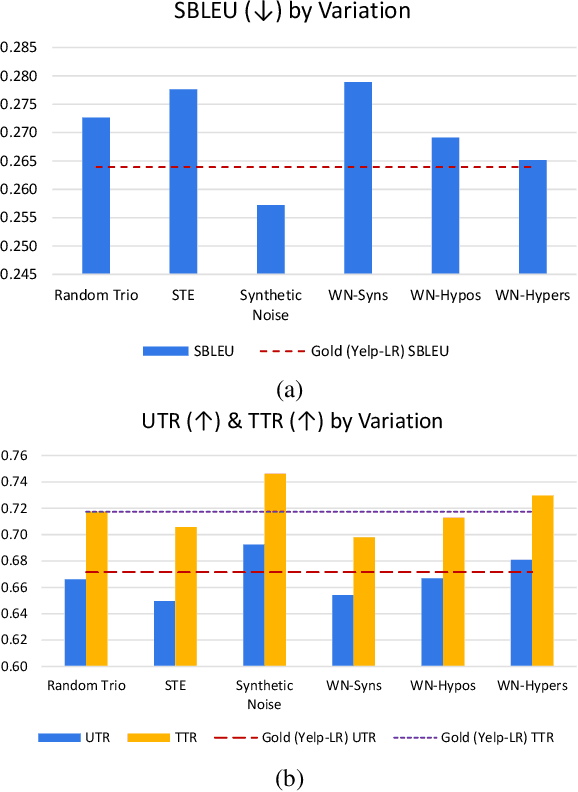
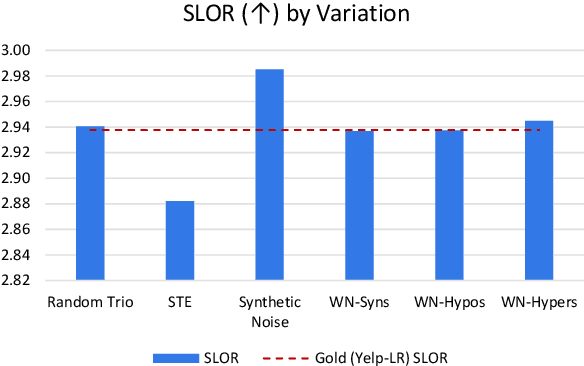
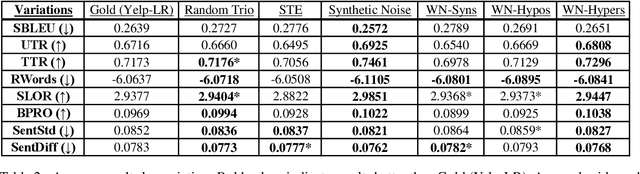
In this paper, we investigate data augmentation for text generation, which we call GenAug. Text generation and language modeling are important tasks within natural language processing, and are especially challenging for low-data regimes. We propose and evaluate various augmentation methods, including some that incorporate external knowledge, for finetuning GPT-2 on a subset of Yelp Reviews. We also examine the relationship between the amount of augmentation and the quality of the generated text. We utilize several metrics that evaluate important aspects of the generated text including its diversity and fluency. Our experiments demonstrate that insertion of character-level synthetic noise and keyword replacement with hypernyms are effective augmentation methods, and that the quality of generations improves to a peak at approximately three times the amount of original data.