 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph is all you need? Lightweight data-agnostic neural architecture search without training
May 02, 2024



Neural architecture search (NAS) enables the automatic design of neural network models. However, training the candidates generated by the search algorithm for performance evaluation incurs considerable computational overhead. Our method, dubbed nasgraph, remarkably reduces the computational costs by converting neural architectures to graphs and using the average degree, a graph measure, as the proxy in lieu of the evaluation metric. Our training-free NAS method is data-agnostic and light-weight. It can find the best architecture among 200 randomly sampled architectures from NAS-Bench201 in 217 CPU seconds. Besides, our method is able to achieve competitive performance on various datasets including NASBench-101, NASBench-201, and NDS search spaces. We also demonstrate that nasgraph generalizes to more challenging tasks on Micro TransNAS-Bench-101.
From PEFT to DEFT: Parameter Efficient Finetuning for Reducing Activation Density in Transformers
Feb 02, 2024Pretrained Language Models (PLMs) have become the de facto starting point for fine-tuning on downstream tasks. However, as model sizes continue to increase, traditional fine-tuning of all parameters becomes challenging. To address this, parameter-efficient fine-tuning (PEFT) methods have gained popularity as a means to adapt PLMs effectively. In parallel, recent studies have revealed the presence of activation sparsity within the intermediate outputs of the multilayer perception (MLP) blocks in transformers. Low activation density enables efficient model inference on sparsity-aware hardware. Building upon this insight, in this work, we propose a novel density loss that encourages higher activation sparsity (equivalently, lower activation density) in the pre-trained models. We demonstrate the effectiveness of our approach by utilizing mainstream PEFT techniques including QLoRA, LoRA, Adapter, Prompt/Prefix Tuning to facilitate efficient model adaptation across diverse downstream tasks. Experiments show that our proposed method DEFT, Density-Efficient Fine-Tuning, can reduce the activation density consistently and up to $\boldsymbol{50.72\%}$ on RoBERTa$_\mathrm{Large}$, and $\boldsymbol {53.19\%}$ (encoder density) and $\boldsymbol{90.60\%}$ (decoder density) on Flan-T5$_\mathrm{XXL}$ ($\boldsymbol{11B}$) compared to PEFT using GLUE and QA (SQuAD) benchmarks respectively while maintaining competitive performance on downstream tasks. We also showcase that DEFT works complementary with quantized and pruned models
LakeBench: Benchmarks for Data Discovery over Data Lakes
Jul 09, 2023



Within enterprises, there is a growing need to intelligently navigate data lakes, specifically focusing on data discovery. Of particular importance to enterprises is the ability to find related tables in data repositories. These tables can be unionable, joinable, or subsets of each other. There is a dearth of benchmarks for these tasks in the public domain, with related work targeting private datasets. In LakeBench, we develop multiple benchmarks for these tasks by using the tables that are drawn from a diverse set of data sources such as government data from CKAN, Socrata, and the European Central Bank. We compare the performance of 4 publicly available tabular foundational models on these tasks. None of the existing models had been trained on the data discovery tasks that we developed for this benchmark; not surprisingly, their performance shows significant room for improvement. The results suggest that the establishment of such benchmarks may be useful to the community to build tabular models usable for data discovery in data lakes.
MILO: Model-Agnostic Subset Selection Framework for Efficient Model Training and Tuning
Feb 05, 2023



Training deep networks and tuning hyperparameters on large datasets is computationally intensive. One of the primary research directions for efficient training is to reduce training costs by selecting well-generalizable subsets of training data. Compared to simple adaptive random subset selection baselines, existing intelligent subset selection approaches are not competitive due to the time-consuming subset selection step, which involves computing model-dependent gradients and feature embeddings and applies greedy maximization of submodular objectives. Our key insight is that removing the reliance on downstream model parameters enables subset selection as a pre-processing step and enables one to train multiple models at no additional cost. In this work, we propose MILO, a model-agnostic subset selection framework that decouples the subset selection from model training while enabling superior model convergence and performance by using an easy-to-hard curriculum. Our empirical results indicate that MILO can train models $3\times - 10 \times$ faster and tune hyperparameters $20\times - 75 \times$ faster than full-dataset training or tuning without compromising performance.
Neural Capacitance: A New Perspective of Neural Network Selection via Edge Dynamics
Jan 14, 2022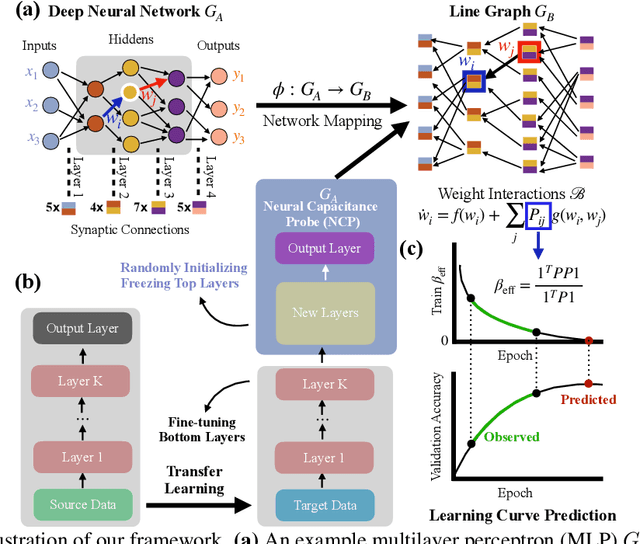
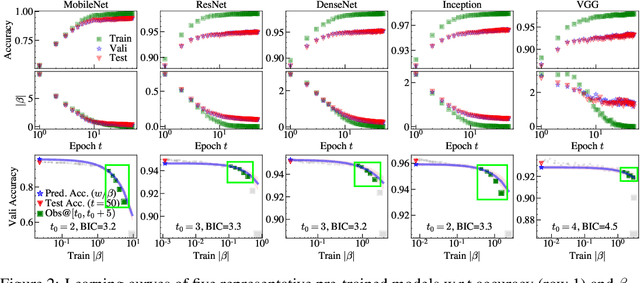
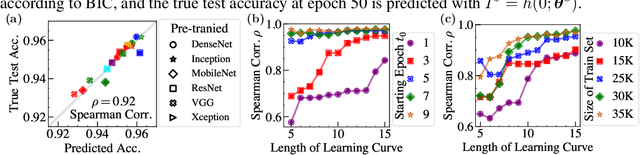
Efficient model selection for identifying a suitable pre-trained neural network to a downstream task is a fundamental yet challenging task in deep learning. Current practice requires expensive computational costs in model training for performance prediction. In this paper, we propose a novel framework for neural network selection by analyzing the governing dynamics over synaptic connections (edges) during training. Our framework is built on the fact that back-propagation during neural network training is equivalent to the dynamical evolution of synaptic connections. Therefore, a converged neural network is associated with an equilibrium state of a networked system composed of those edges. To this end, we construct a network mapping $\phi$, converting a neural network $G_A$ to a directed line graph $G_B$ that is defined on those edges in $G_A$. Next, we derive a neural capacitance metric $\beta_{\rm eff}$ as a predictive measure universally capturing the generalization capability of $G_A$ on the downstream task using only a handful of early training results. We carried out extensive experiments using 17 popular pre-trained ImageNet models and five benchmark datasets, including CIFAR10, CIFAR100, SVHN, Fashion MNIST and Birds, to evaluate the fine-tuning performance of our framework. Our neural capacitance metric is shown to be a powerful indicator for model selection based only on early training results and is more efficient than state-of-the-art methods.
Contrastive Explanations for Comparing Preferences of Reinforcement Learning Agents
Dec 17, 2021


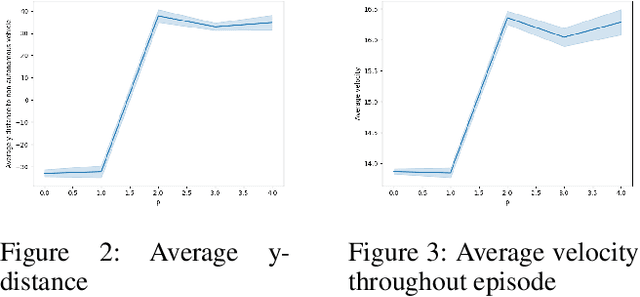
In complex tasks where the reward function is not straightforward and consists of a set of objectives, multiple reinforcement learning (RL) policies that perform task adequately, but employ different strategies can be trained by adjusting the impact of individual objectives on reward function. Understanding the differences in strategies between policies is necessary to enable users to choose between offered policies, and can help developers understand different behaviors that emerge from various reward functions and training hyperparameters in RL systems. In this work we compare behavior of two policies trained on the same task, but with different preferences in objectives. We propose a method for distinguishing between differences in behavior that stem from different abilities from those that are a consequence of opposing preferences of two RL agents. Furthermore, we use only data on preference-based differences in order to generate contrasting explanations about agents' preferences. Finally, we test and evaluate our approach on an autonomous driving task and compare the behavior of a safety-oriented policy and one that prefers speed.
Building Accurate Simple Models with Multihop
Sep 14, 2021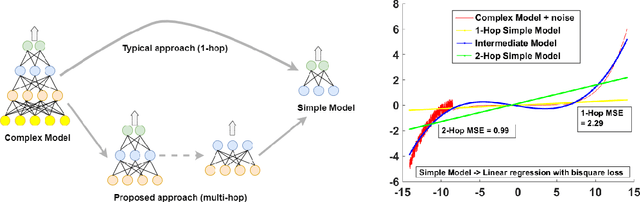
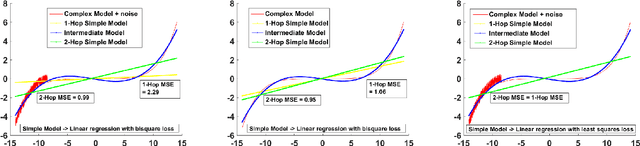
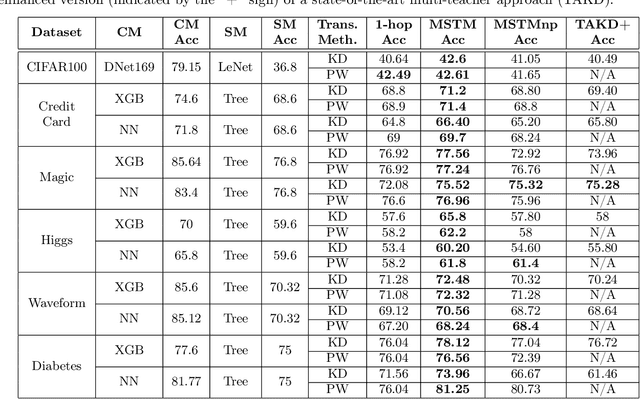
Knowledge transfer from a complex high performing model to a simpler and potentially low performing one in order to enhance its performance has been of great interest over the last few years as it finds applications in important problems such as explainable artificial intelligence, model compression, robust model building and learning from small data. Known approaches to this problem (viz. Knowledge Distillation, Model compression, ProfWeight, etc.) typically transfer information directly (i.e. in a single/one hop) from the complex model to the chosen simple model through schemes that modify the target or reweight training examples on which the simple model is trained. In this paper, we propose a meta-approach where we transfer information from the complex model to the simple model by dynamically selecting and/or constructing a sequence of intermediate models of decreasing complexity that are less intricate than the original complex model. Our approach can transfer information between consecutive models in the sequence using any of the previously mentioned approaches as well as work in 1-hop fashion, thus generalizing these approaches. In the experiments on real data, we observe that we get consistent gains for different choices of models over 1-hop, which on average is more than 2\% and reaches up to 8\% in a particular case. We also empirically analyze conditions under which the multi-hop approach is likely to be beneficial over the traditional 1-hop approach, and report other interesting insights. To the best of our knowledge, this is the first work that proposes such a multi-hop approach to perform knowledge transfer given a single high performing complex model, making it in our opinion, an important methodological contribution.
Learning to Rank Learning Curves
Jun 05, 2020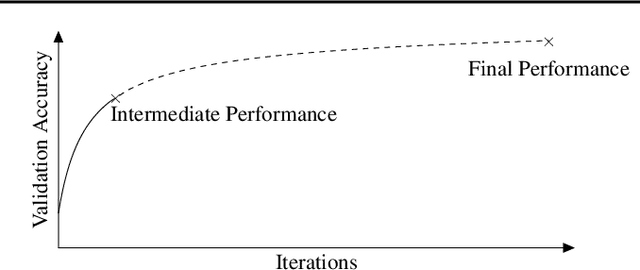
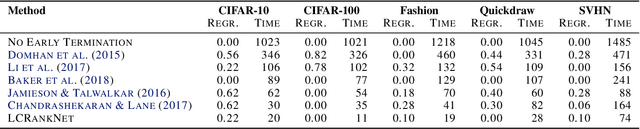
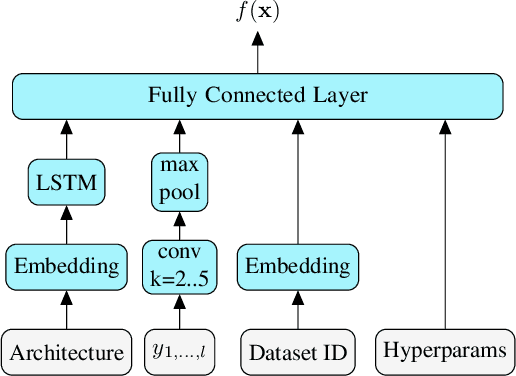
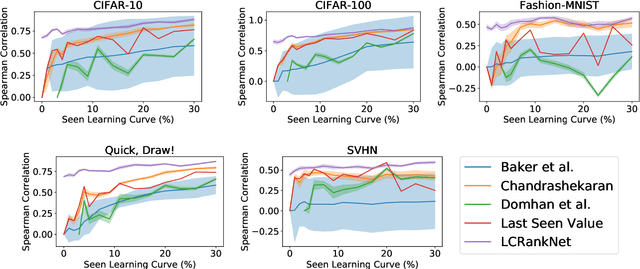
Many automated machine learning methods, such as those for hyperparameter and neural architecture optimization, are computationally expensive because they involve training many different model configurations. In this work, we present a new method that saves computational budget by terminating poor configurations early on in the training. In contrast to existing methods, we consider this task as a ranking and transfer learning problem. We qualitatively show that by optimizing a pairwise ranking loss and leveraging learning curves from other datasets, our model is able to effectively rank learning curves without having to observe many or very long learning curves. We further demonstrate that our method can be used to accelerate a neural architecture search by a factor of up to 100 without a significant performance degradation of the discovered architecture. In further experiments we analyze the quality of ranking, the influence of different model components as well as the predictive behavior of the model.
Learning Global Transparent Models from Local Contrastive Explanations
Feb 19, 2020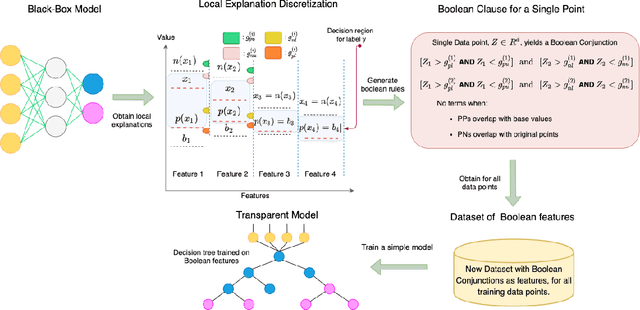
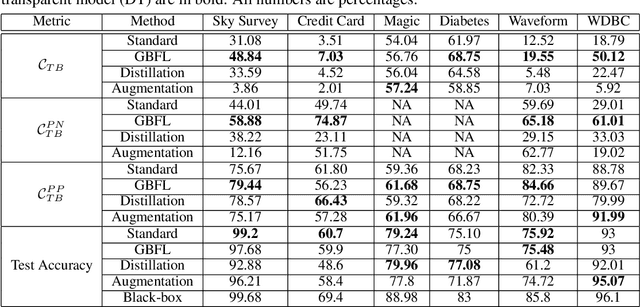
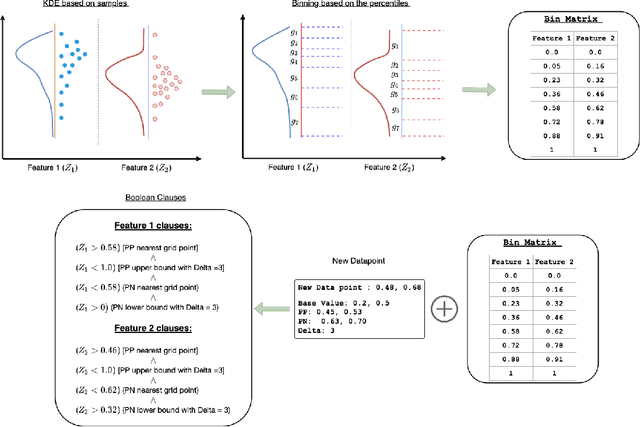
There is a rich and growing literature on producing local point wise contrastive/counterfactual explanations for complex models. These methods highlight what is important to justify the classification and/or produce a contrast point that alters the final classification. Other works try to build globally interpretable models like decision trees and rule lists directly by efficient model search using the data or by transferring information from a complex model using distillation-like methods. Although these interpretable global models can be useful, they may not be consistent with local explanations from a specific complex model of choice. In this work, we explore the question: Can we produce a transparent global model that is consistent with/derivable from local explanations? Based on a key insight we provide a novel method where every local contrastive/counterfactual explanation can be turned into a Boolean feature. These Boolean features are sparse conjunctions of binarized features. The dataset thus constructed is consistent with local explanations by design and one can train an interpretable model like a decision tree on it. We note that this approach strictly loses information due to reliance only on sparse local explanations, nonetheless, we demonstrate empirically that in many cases it can still be competitive with respect to the complex model's performance and also other methods that learn directly from the original dataset. Our approach also provides an avenue to benchmark local explanation methods in a quantitative manner.
How can AI Automate End-to-End Data Science?
Oct 22, 2019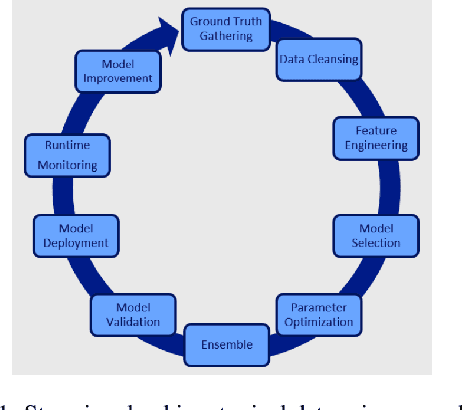
Data science is labor-intensive and human experts are scarce but heavily involved in every aspect of it. This makes data science time consuming and restricted to experts with the resulting quality heavily dependent on their experience and skills. To make data science more accessible and scalable, we need its democratization. Automated Data Science (AutoDS) is aimed towards that goal and is emerging as an important research and business topic. We introduce and define the AutoDS challenge, followed by a proposal of a general AutoDS framework that covers existing approaches but also provides guidance for the development of new methods. We categorize and review the existing literature from multiple aspects of the problem setup and employed techniques. Then we provide several views on how AI could succeed in automating end-to-end AutoDS. We hope this survey can serve as insightful guideline for the AutoDS field and provide inspiration for future research.