 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks against a Satellite-borne Multispectral Cloud Detector
Dec 03, 2021
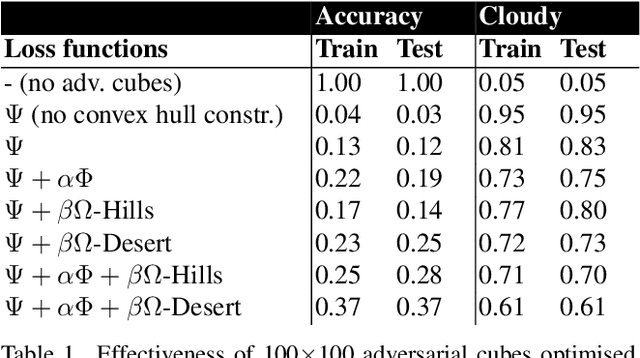

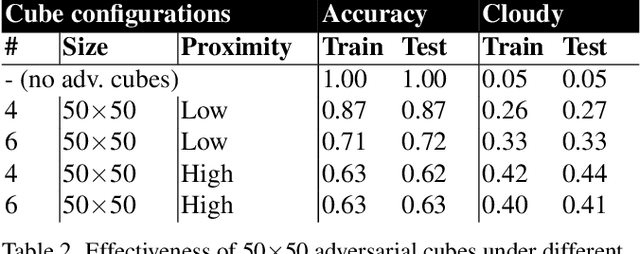
Data collected by Earth-observing (EO) satellites are often afflicted by cloud cover. Detecting the presence of clouds -- which is increasingly done using deep learning -- is crucial preprocessing in EO applications. In fact, advanced EO satellites perform deep learning-based cloud detection on board the satellites and downlink only clear-sky data to save precious bandwidth. In this paper, we highlight the vulnerability of deep learning-based cloud detection towards adversarial attacks. By optimising an adversarial pattern and superimposing it into a cloudless scene, we bias the neural network into detecting clouds in the scene. Since the input spectra of cloud detectors include the non-visible bands, we generated our attacks in the multispectral domain. This opens up the potential of multi-objective attacks, specifically, adversarial biasing in the cloud-sensitive bands and visual camouflage in the visible bands. We also investigated mitigation strategies against the adversarial attacks. We hope our work further builds awareness of the potential of adversarial attacks in the EO community.
Occlusion-Robust Object Pose Estimation with Holistic Representation
Oct 22, 2021
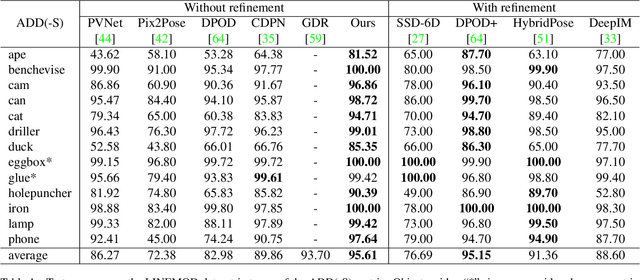
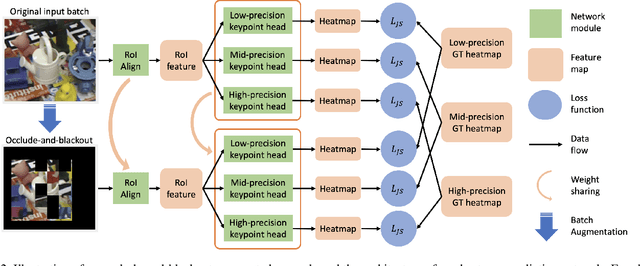
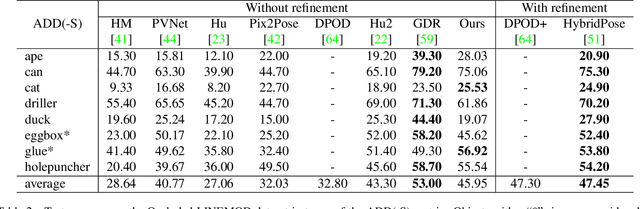
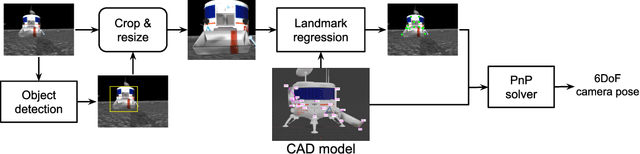
Practical object pose estimation demands robustness against occlusions to the target object. State-of-the-art (SOTA) object pose estimators take a two-stage approach, where the first stage predicts 2D landmarks using a deep network and the second stage solves for 6DOF pose from 2D-3D correspondences. Albeit widely adopted, such two-stage approaches could suffer from novel occlusions when generalising and weak landmark coherence due to disrupted features. To address these issues, we develop a novel occlude-and-blackout batch augmentation technique to learn occlusion-robust deep features, and a multi-precision supervision architecture to encourage holistic pose representation learning for accurate and coherent landmark predictions. We perform careful ablation tests to verify the impact of our innovations and compare our method to SOTA pose estimators. Without the need of any post-processing or refinement, our method exhibits superior performance on the LINEMOD dataset. On the YCB-Video dataset our method outperforms all non-refinement methods in terms of the ADD(-S) metric. We also demonstrate the high data-efficiency of our method. Our code is available at http://github.com/BoChenYS/ROPE
Robotic Vision for Space Mining
Sep 30, 2021


Future Moon bases will likely be constructed using resources mined from the surface of the Moon. The difficulty of maintaining a human workforce on the Moon and communications lag with Earth means that mining will need to be conducted using collaborative robots with a high degree of autonomy. In this paper, we explore the utility of robotic vision towards addressing several major challenges in autonomous mining in the lunar environment: lack of satellite positioning systems, navigation in hazardous terrain, and delicate robot interactions. Specifically, we describe and report the results of robotic vision algorithms that we developed for Phase 2 of the NASA Space Robotics Challenge, which was framed in the context of autonomous collaborative robots for mining on the Moon. The competition provided a simulated lunar environment that exhibits the complexities alluded to above. We show how machine learning-enabled vision could help alleviate the challenges posed by the lunar environment. A robust multi-robot coordinator was also developed to achieve long-term operation and effective collaboration between robots.
Physical Adversarial Attacks on an Aerial Imagery Object Detector
Aug 26, 2021
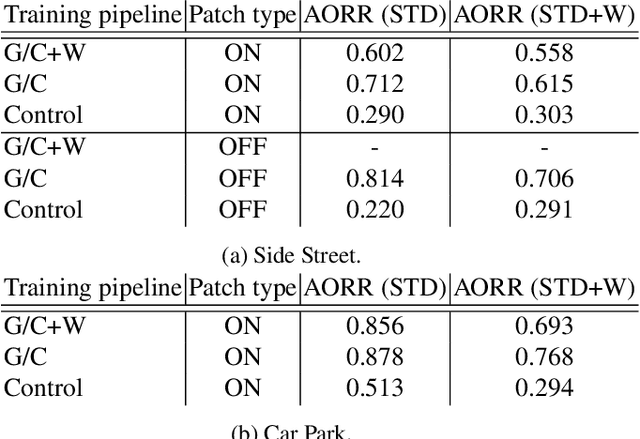

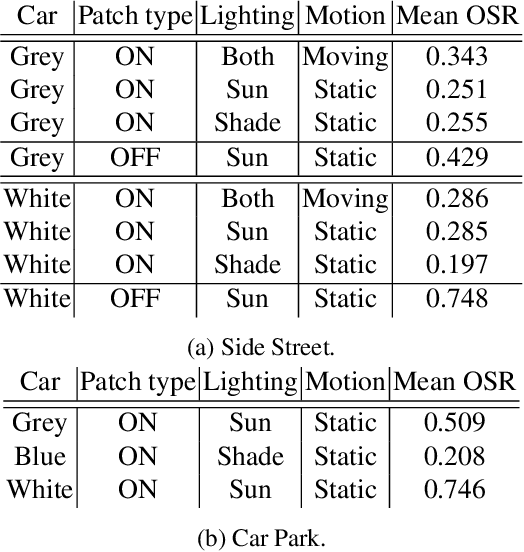
Deep neural networks (DNNs) have become essential for processing the vast amounts of aerial imagery collected using earth-observing satellite platforms. However, DNNs are vulnerable towards adversarial examples, and it is expected that this weakness also plagues DNNs for aerial imagery. In this work, we demonstrate one of the first efforts on physical adversarial attacks on aerial imagery, whereby adversarial patches were optimised, fabricated and installed on or near target objects (cars) to significantly reduce the efficacy of an object detector applied on overhead images. Physical adversarial attacks on aerial images, particularly those captured from satellite platforms, are challenged by atmospheric factors (lighting, weather, seasons) and the distance between the observer and target. To investigate the effects of these challenges, we devised novel experiments and metrics to evaluate the efficacy of physical adversarial attacks against object detectors in aerial scenes. Our results indicate the palpable threat posed by physical adversarial attacks towards DNNs for processing satellite imagery.
Quantum Annealing Formulation for Binary Neural Networks
Jul 05, 2021



Quantum annealing is a promising paradigm for building practical quantum computers. Compared to other approaches, quantum annealing technology has been scaled up to a larger number of qubits. On the other hand, deep learning has been profoundly successful in pushing the boundaries of AI. It is thus natural to investigate potentially game changing technologies such as quantum annealers to augment the capabilities of deep learning. In this work, we explore binary neural networks, which are lightweight yet powerful models typically intended for resource constrained devices. Departing from current training regimes for binary networks that smooth/approximate the activation functions to make the network differentiable, we devise a quadratic unconstrained binary optimization formulation for the training problem. While the problem is intractable, i.e., the cost to estimate the binary weights scales exponentially with network size, we show how the problem can be optimized directly on a quantum annealer, thereby opening up to the potential gains of quantum computing. We experimentally validated our formulation via simulation and testing on an actual quantum annealer (D-Wave Advantage), the latter to the extent allowable by the capacity of current technology.
A Spacecraft Dataset for Detection, Segmentation and Parts Recognition
Jun 15, 2021
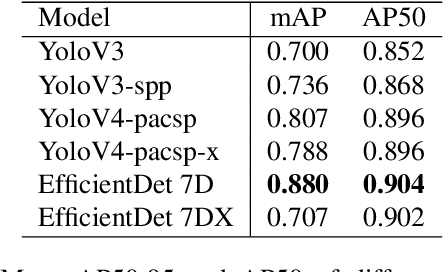

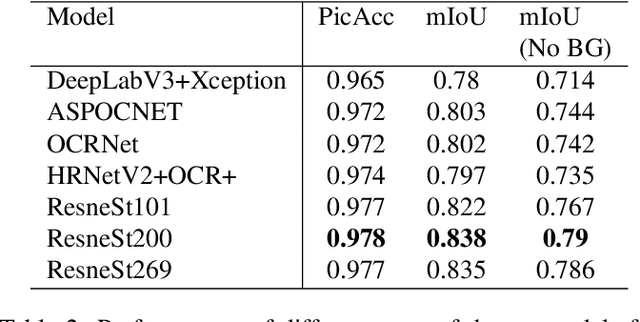
Virtually all aspects of modern life depend on space technology. Thanks to the great advancement of computer vision in general and deep learning-based techniques in particular, over the decades, the world witnessed the growing use of deep learning in solving problems for space applications, such as self-driving robot, tracers, insect-like robot on cosmos and health monitoring of spacecraft. These are just some prominent examples that has advanced space industry with the help of deep learning. However, the success of deep learning models requires a lot of training data in order to have decent performance, while on the other hand, there are very limited amount of publicly available space datasets for the training of deep learning models. Currently, there is no public datasets for space-based object detection or instance segmentation, partly because manually annotating object segmentation masks is very time consuming as they require pixel-level labelling, not to mention the challenge of obtaining images from space. In this paper, we aim to fill this gap by releasing a dataset for spacecraft detection, instance segmentation and part recognition. The main contribution of this work is the development of the dataset using images of space stations and satellites, with rich annotations including bounding boxes of spacecrafts and masks to the level of object parts, which are obtained with a mixture of automatic processes and manual efforts. We also provide evaluations with state-of-the-art methods in object detection and instance segmentation as a benchmark for the dataset. The link for downloading the proposed dataset can be found on https://github.com/Yurushia1998/SatelliteDataset.
Learning to Predict Repeatability of Interest Points
May 08, 2021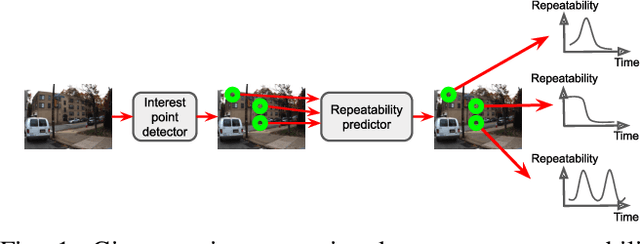
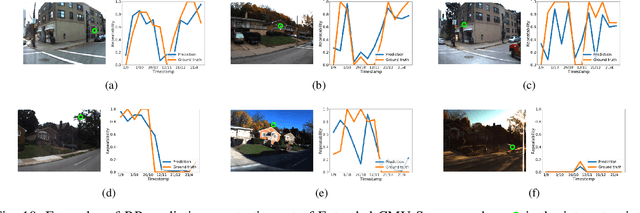
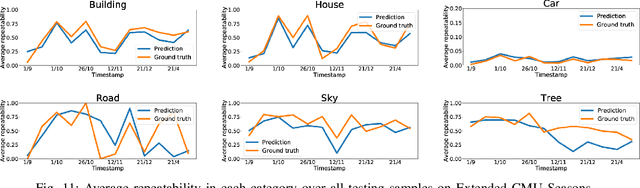
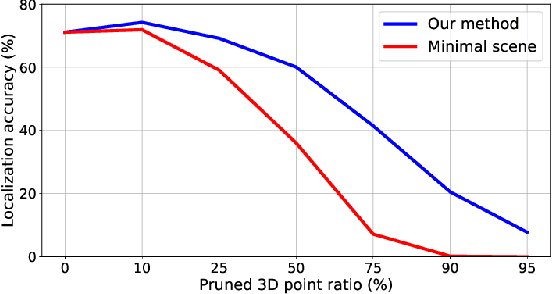
Many robotics applications require interest points that are highly repeatable under varying viewpoints and lighting conditions. However, this requirement is very challenging as the environment changes continuously and indefinitely, leading to appearance changes of interest points with respect to time. This paper proposes to predict the repeatability of an interest point as a function of time, which can tell us the lifespan of the interest point considering daily or seasonal variation. The repeatability predictor (RP) is formulated as a regressor trained on repeated interest points from multiple viewpoints over a long period of time. Through comprehensive experiments, we demonstrate that our RP can estimate when a new interest point is repeated, and also highlight an insightful analysis about this problem. For further comparison, we apply our RP to the map summarization under visual localization framework, which builds a compact representation of the full context map given the query time. The experimental result shows a careful selection of potentially repeatable interest points predicted by our RP can significantly mitigate the degeneration of localization accuracy from map summarization.
Spatiotemporal Registration for Event-based Visual Odometry
Mar 19, 2021
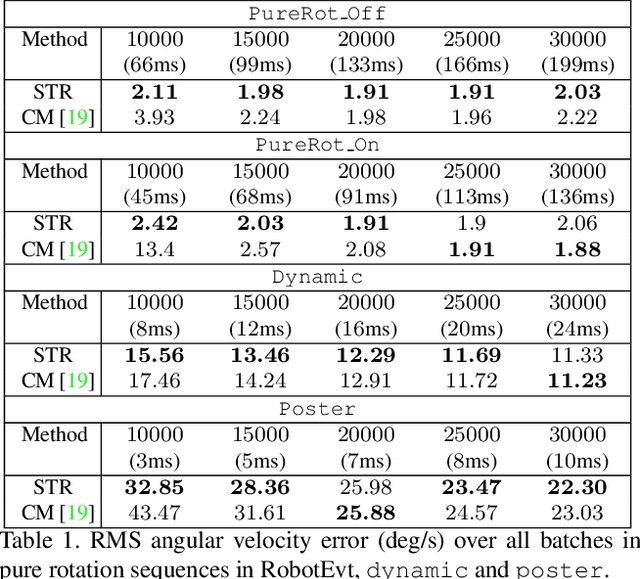
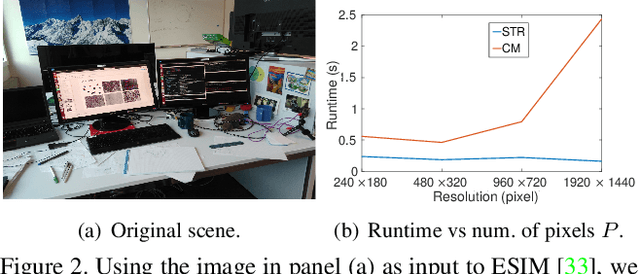
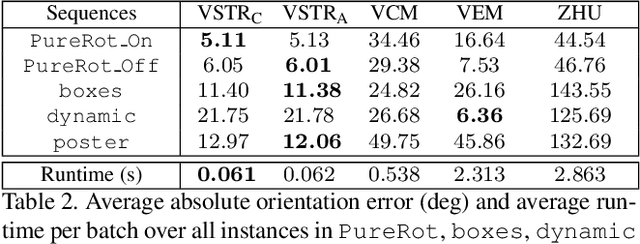
A useful application of event sensing is visual odometry, especially in settings that require high-temporal resolution. The state-of-the-art method of contrast maximisation recovers the motion from a batch of events by maximising the contrast of the image of warped events. However, the cost scales with image resolution and the temporal resolution can be limited by the need for large batch sizes to yield sufficient structure in the contrast image. In this work, we propose spatiotemporal registration as a compelling technique for event-based rotational motion estimation. We theoretcally justify the approach and establish its fundamental and practical advantages over contrast maximisation. In particular, spatiotemporal registration also produces feature tracks as a by-product, which directly supports an efficient visual odometry pipeline with graph-based optimisation for motion averaging. The simplicity of our visual odometry pipeline allows it to process more than 1 M events/second. We also contribute a new event dataset for visual odometry, where motion sequences with large velocity variations were acquired using a high-precision robot arm.
Rotation Coordinate Descent for Fast Globally Optimal Rotation Averaging
Mar 16, 2021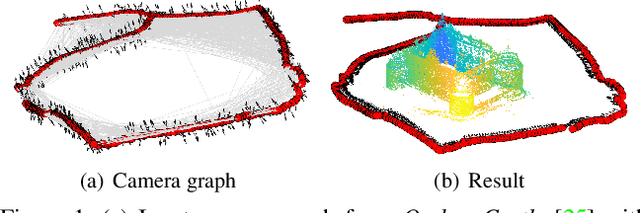
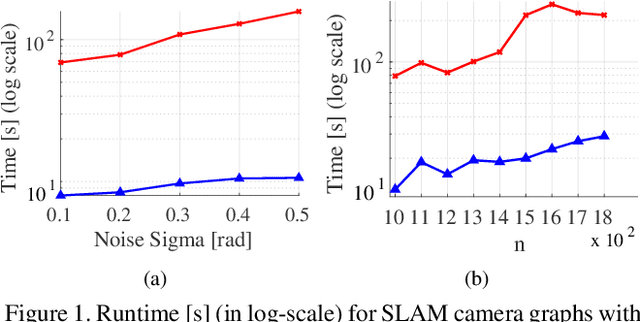
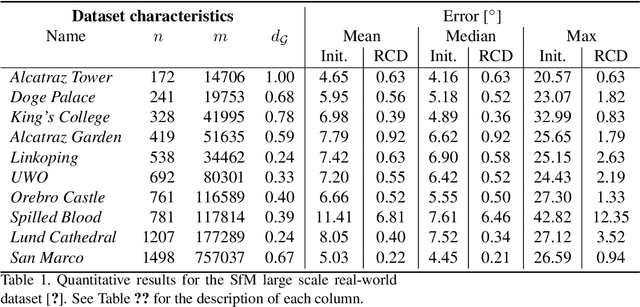
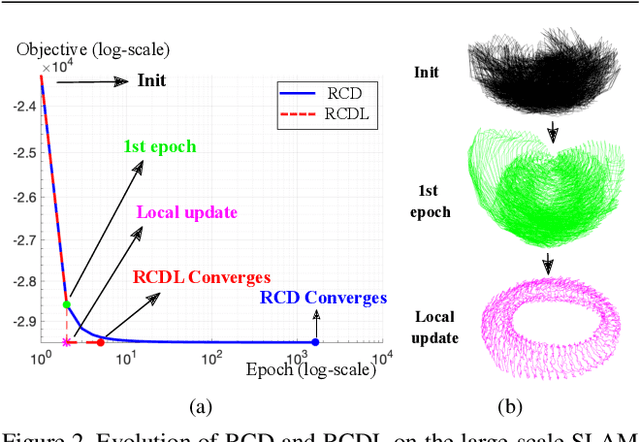
Under mild conditions on the noise level of the measurements, rotation averaging satisfies strong duality, which enables global solutions to be obtained via semidefinite programming (SDP) relaxation. However, generic solvers for SDP are rather slow in practice, even on rotation averaging instances of moderate size, thus developing specialised algorithms is vital. In this paper, we present a fast algorithm that achieves global optimality called rotation coordinate descent (RCD). Unlike block coordinate descent (BCD) which solves SDP by updating the semidefinite matrix in a row-by-row fashion, RCD directly maintains and updates all valid rotations throughout the iterations. This obviates the need to store a large dense semidefinite matrix. We mathematically prove the convergence of our algorithm and empirically show its superior efficiency over state-of-the-art global methods on a variety of problem configurations. Maintaining valid rotations also facilitates incorporating local optimisation routines for further speed-ups. Moreover, our algorithm is simple to implement; see supplementary material for a demonstration program.
Consensus Maximisation Using Influences of Monotone Boolean Functions
Mar 06, 2021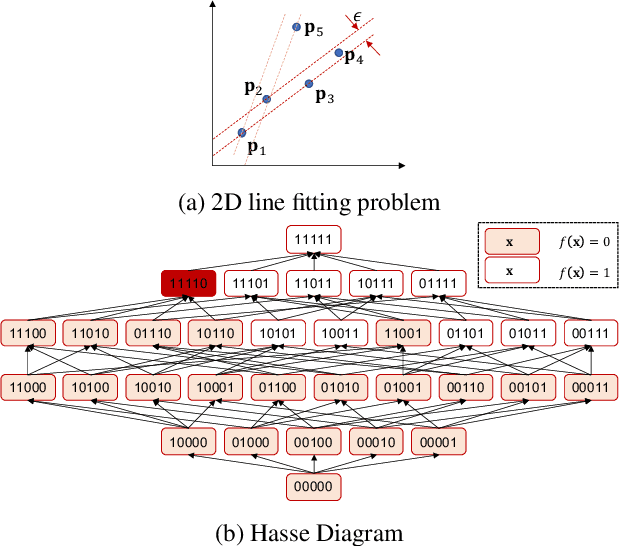
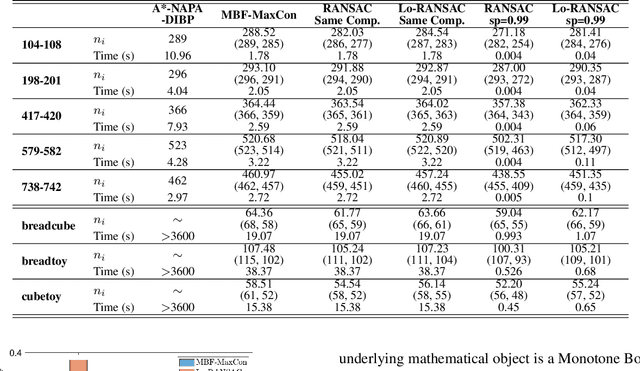
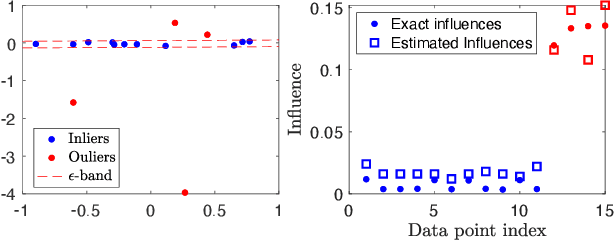
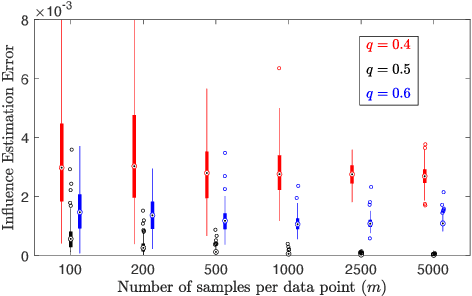
Consensus maximisation (MaxCon), which is widely used for robust fitting in computer vision, aims to find the largest subset of data that fits the model within some tolerance level. In this paper, we outline the connection between MaxCon problem and the abstract problem of finding the maximum upper zero of a Monotone Boolean Function (MBF) defined over the Boolean Cube. Then, we link the concept of influences (in a MBF) to the concept of outlier (in MaxCon) and show that influences of points belonging to the largest structure in data would generally be smaller under certain conditions. Based on this observation, we present an iterative algorithm to perform consensus maximisation. Results for both synthetic and real visual data experiments show that the MBF based algorithm is capable of generating a near optimal solution relatively quickly. This is particularly important where there are large number of outliers (gross or pseudo) in the observed data.