 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Tree Edit Distance (GTED): A Faithful Evaluation Metric for Statement Autoformalization
Jul 10, 2025Statement autoformalization, the automated translation of statement from natural language into formal languages, has become a subject of extensive research, yet the development of robust automated evaluation metrics remains limited. Existing evaluation methods often lack semantic understanding, face challenges with high computational costs, and are constrained by the current progress of automated theorem proving. To address these issues, we propose GTED (Generalized Tree Edit Distance), a novel evaluation framework that first standardizes formal statements and converts them into operator trees, then determines the semantic similarity using the eponymous GTED metric. On the miniF2F and ProofNet benchmarks, GTED outperforms all baseline metrics by achieving the highest accuracy and Kappa scores, thus providing the community with a more faithful metric for automated evaluation. The code and experimental results are available at https://github.com/XiaoyangLiu-sjtu/GTED.
Hardware-software co-exploration with racetrack memory based in-memory computing for CNN inference in embedded systems
Jul 02, 2025Deep neural networks generate and process large volumes of data, posing challenges for low-resource embedded systems. In-memory computing has been demonstrated as an efficient computing infrastructure and shows promise for embedded AI applications. Among newly-researched memory technologies, racetrack memory is a non-volatile technology that allows high data density fabrication, making it a good fit for in-memory computing. However, integrating in-memory arithmetic circuits with memory cells affects both the memory density and power efficiency. It remains challenging to build efficient in-memory arithmetic circuits on racetrack memory within area and energy constraints. To this end, we present an efficient in-memory convolutional neural network (CNN) accelerator optimized for use with racetrack memory. We design a series of fundamental arithmetic circuits as in-memory computing cells suited for multiply-and-accumulate operations. Moreover, we explore the design space of racetrack memory based systems and CNN model architectures, employing co-design to improve the efficiency and performance of performing CNN inference in racetrack memory while maintaining model accuracy. Our designed circuits and model-system co-optimization strategies achieve a small memory bank area with significant improvements in energy and performance for racetrack memory based embedded systems.
Is Quantum Optimization Ready? An Effort Towards Neural Network Compression using Adiabatic Quantum Computing
May 22, 2025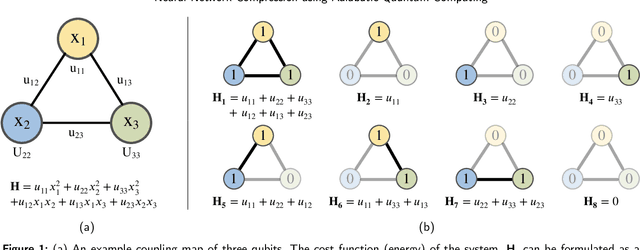
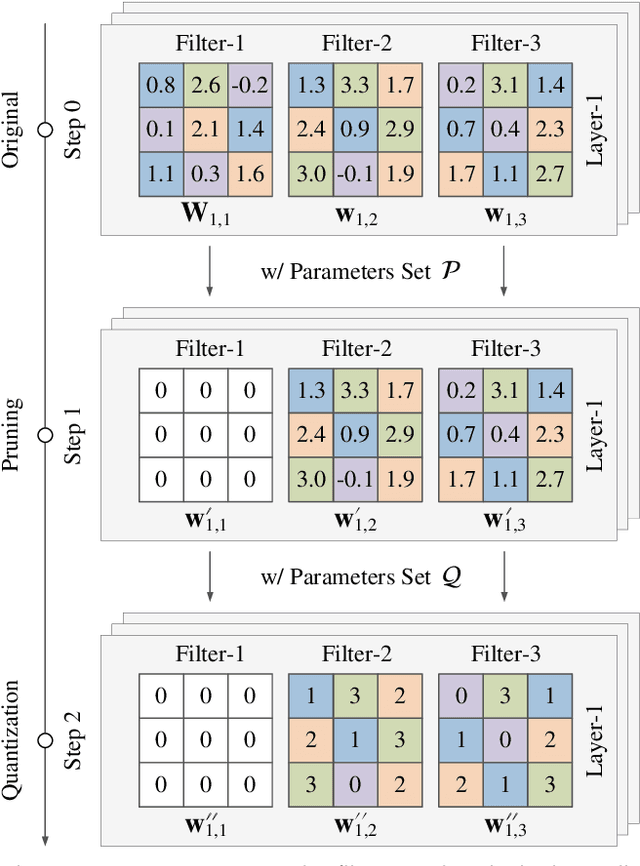
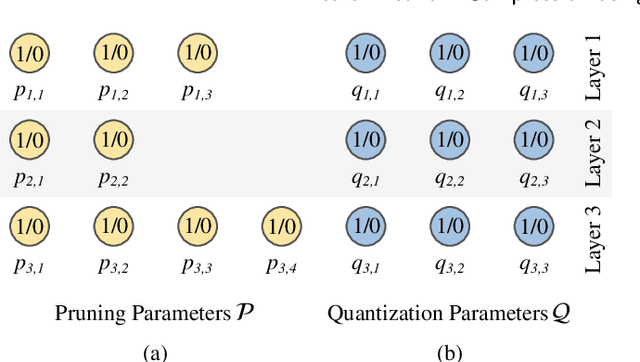
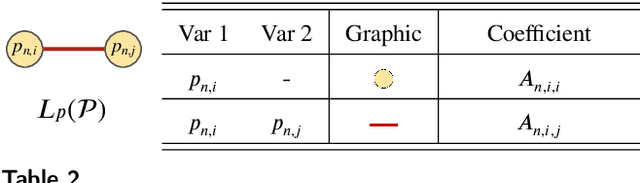
Quantum optimization is the most mature quantum computing technology to date, providing a promising approach towards efficiently solving complex combinatorial problems. Methods such as adiabatic quantum computing (AQC) have been employed in recent years on important optimization problems across various domains. In deep learning, deep neural networks (DNN) have reached immense sizes to support new predictive capabilities. Optimization of large-scale models is critical for sustainable deployment, but becomes increasingly challenging with ever-growing model sizes and complexity. While quantum optimization is suitable for solving complex problems, its application to DNN optimization is not straightforward, requiring thorough reformulation for compatibility with commercially available quantum devices. In this work, we explore the potential of adopting AQC for fine-grained pruning-quantization of convolutional neural networks. We rework established heuristics to formulate model compression as a quadratic unconstrained binary optimization (QUBO) problem, and assess the solution space offered by commercial quantum annealing devices. Through our exploratory efforts of reformulation, we demonstrate that AQC can achieve effective compression of practical DNN models. Experiments demonstrate that adiabatic quantum computing (AQC) not only outperforms classical algorithms like genetic algorithms and reinforcement learning in terms of time efficiency but also excels at identifying global optima.
Uncovering Critical Sets of Deep Neural Networks via Sample-Independent Critical Lifting
May 19, 2025This paper investigates the sample dependence of critical points for neural networks. We introduce a sample-independent critical lifting operator that associates a parameter of one network with a set of parameters of another, thus defining sample-dependent and sample-independent lifted critical points. We then show by example that previously studied critical embeddings do not capture all sample-independent lifted critical points. Finally, we demonstrate the existence of sample-dependent lifted critical points for sufficiently large sample sizes and prove that saddles appear among them.
Embedding principle of homogeneous neural network for classification problem
May 18, 2025Understanding the convergence points and optimization landscape of neural networks is crucial, particularly for homogeneous networks where Karush-Kuhn-Tucker (KKT) points of the associated maximum-margin problem often characterize solutions. This paper investigates the relationship between such KKT points across networks of different widths generated via neuron splitting. We introduce and formalize the \textbf{KKT point embedding principle}, establishing that KKT points of a homogeneous network's max-margin problem ($P_{\Phi}$) can be embedded into the KKT points of a larger network's problem ($P_{\tilde{\Phi}}$) via specific linear isometric transformations corresponding to neuron splitting. We rigorously prove this principle holds for neuron splitting in both two-layer and deep homogeneous networks. Furthermore, we connect this static embedding to the dynamics of gradient flow training with smooth losses. We demonstrate that trajectories initiated from appropriately mapped points remain mapped throughout training and that the resulting $\omega$-limit sets of directions are correspondingly mapped ($T(L(\theta(0))) = L(\boldsymbol{\eta}(0))$), thereby preserving the alignment with KKT directions dynamically when directional convergence occurs. Our findings offer insights into the effects of network width, parameter redundancy, and the structural connections between solutions found via optimization in homogeneous networks of varying sizes.
RoPETR: Improving Temporal Camera-Only 3D Detection by Integrating Enhanced Rotary Position Embedding
Apr 18, 2025This technical report introduces a targeted improvement to the StreamPETR framework, specifically aimed at enhancing velocity estimation, a critical factor influencing the overall NuScenes Detection Score. While StreamPETR exhibits strong 3D bounding box detection performance as reflected by its high mean Average Precision our analysis identified velocity estimation as a substantial bottleneck when evaluated on the NuScenes dataset. To overcome this limitation, we propose a customized positional embedding strategy tailored to enhance temporal modeling capabilities. Experimental evaluations conducted on the NuScenes test set demonstrate that our improved approach achieves a state-of-the-art NDS of 70.86% using the ViT-L backbone, setting a new benchmark for camera-only 3D object detection.
ATLAS: Autoformalizing Theorems through Lifting, Augmentation, and Synthesis of Data
Feb 08, 2025Autoformalization, the process of automatically translating natural language mathematics into machine-verifiable formal language, has demonstrated advancements with the progress of large language models (LLMs). However, a key obstacle to further advancements is the scarcity of paired datasets that align natural language with formal language. To address this challenge, we introduce ATLAS (Autoformalizing Theorems through Lifting, Augmentation, and Synthesis of Data), an iterative data generation framework designed to produce large-scale, high-quality parallel theorem statements. With the proposed ATLAS running for 10 iterations, we construct an undergraduate-level dataset comprising 300k theorem statements and develop the ATLAS translator, achieving accuracies of 80.59% (pass@8) and 92.99% (pass@128) on ProofNet, significantly outperforming the base model (23.99% and 47.17%) and InternLM2-Math-Plus-7B (50.94% and 80.32%). Furthermore, the ATLAS translator also achieves state-of-the-art performance on both the high-school-level miniF2F dataset and the graduate-level MathQual dataset introduced in this work. The datasets, model, and code will be released to the public soon.
SEER: Self-Explainability Enhancement of Large Language Models' Representations
Feb 07, 2025Explaining the hidden representations of Large Language Models (LLMs) is a perspective to understand LLMs' underlying inference logic and improve their reliability in application scenarios. However, previous methods introduce external ''black-box'' modules to explain ''black-box'' LLMs, increasing the potential uncertainty and failing to provide faithful explanations. In this paper, we propose a self-explaining method SEER, enhancing LLMs' explainability by aggregating the same concept and disentangling the different concepts in the representation space. In this way, SEER provides faithful explanations carried by representations synchronously with the LLMs' output. Additionally, we showcase the applications of SEER on trustworthiness-related tasks (e.g., the safety risks classification and detoxification tasks), where self-explained LLMs achieve consistent improvement in explainability and performance. More crucially, we theoretically analyze the improvement of SEER on LLMs' generalization ability through optimal transport theory.
Harnessing the Power of Vibration Motors to Develop Miniature Untethered Robotic Fishes
Jan 09, 2025



Miniature underwater robots play a crucial role in the exploration and development of marine resources, particularly in confined spaces and high-pressure deep-sea environments. This study presents the design, optimization, and performance of a miniature robotic fish, powered by the oscillation of bio-inspired fins. These fins feature a rigid-flexible hybrid structure and use an eccentric rotating mass (ERM) vibration motor as the excitation source to generate high-frequency unidirectional oscillations that induce acoustic streaming for propulsion. The drive mechanism, powered by miniature ERM vibration motors, eliminates the need for complex mechanical drive systems, enabling complete isolation of the entire drive system from the external environment and facilitating the miniaturization of the robotic fish. A compact, untethered robotic fish, measuring 85*60*45 mm^3, is equipped with three bio-inspired fins located at the pectoral and caudal positions. Experimental results demonstrate that the robotic fish achieves a maximum forward swimming speed of 1.36 body lengths (BL) per second powered by all fins and minimum turning radius of 0.6 BL when powered by a single fin. These results underscore the significance of employing the ERM vibration motor in advancing the development of highly maneuverable, miniature untethered underwater robots for various marine exploration tasks.
On Multi-Stage Loss Dynamics in Neural Networks: Mechanisms of Plateau and Descent Stages
Nov 06, 2024



The multi-stage phenomenon in the training loss curves of neural networks has been widely observed, reflecting the non-linearity and complexity inherent in the training process. In this work, we investigate the training dynamics of neural networks (NNs), with particular emphasis on the small initialization regime, identifying three distinct stages observed in the loss curve during training: the initial plateau stage, the initial descent stage, and the secondary plateau stage. Through rigorous analysis, we reveal the underlying challenges contributing to slow training during the plateau stages. While the proof and estimate for the emergence of the initial plateau were established in our previous work, the behaviors of the initial descent and secondary plateau stages had not been explored before. Here, we provide a more detailed proof for the initial plateau, followed by a comprehensive analysis of the initial descent stage dynamics. Furthermore, we examine the factors facilitating the network's ability to overcome the prolonged secondary plateau, supported by both experimental evidence and heuristic reasoning. Finally, to clarify the link between global training trends and local parameter adjustments, we use the Wasserstein distance to track the fine-scale evolution of weight amplitude distribution.