 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Neural Networks with Learnable Non-Linear Activation Functions via Lookup-Based FPGA Acceleration
Aug 23, 2025Learned activation functions in models like Kolmogorov-Arnold Networks (KANs) outperform fixed-activation architectures in terms of accuracy and interpretability; however, their computational complexity poses critical challenges for energy-constrained edge AI deployments. Conventional CPUs/GPUs incur prohibitive latency and power costs when evaluating higher order activations, limiting deployability under ultra-tight energy budgets. We address this via a reconfigurable lookup architecture with edge FPGAs. By coupling fine-grained quantization with adaptive lookup tables, our design minimizes energy-intensive arithmetic operations while preserving activation fidelity. FPGA reconfigurability enables dynamic hardware specialization for learned functions, a key advantage for edge systems that require post-deployment adaptability. Evaluations using KANs - where unique activation functions play a critical role - demonstrate that our FPGA-based design achieves superior computational speed and over $10^4$ times higher energy efficiency compared to edge CPUs and GPUs, while maintaining matching accuracy and minimal footprint overhead. This breakthrough positions our approach as a practical enabler for energy-critical edge AI, where computational intensity and power constraints traditionally preclude the use of adaptive activation networks.
Hardware-software co-exploration with racetrack memory based in-memory computing for CNN inference in embedded systems
Jul 02, 2025Deep neural networks generate and process large volumes of data, posing challenges for low-resource embedded systems. In-memory computing has been demonstrated as an efficient computing infrastructure and shows promise for embedded AI applications. Among newly-researched memory technologies, racetrack memory is a non-volatile technology that allows high data density fabrication, making it a good fit for in-memory computing. However, integrating in-memory arithmetic circuits with memory cells affects both the memory density and power efficiency. It remains challenging to build efficient in-memory arithmetic circuits on racetrack memory within area and energy constraints. To this end, we present an efficient in-memory convolutional neural network (CNN) accelerator optimized for use with racetrack memory. We design a series of fundamental arithmetic circuits as in-memory computing cells suited for multiply-and-accumulate operations. Moreover, we explore the design space of racetrack memory based systems and CNN model architectures, employing co-design to improve the efficiency and performance of performing CNN inference in racetrack memory while maintaining model accuracy. Our designed circuits and model-system co-optimization strategies achieve a small memory bank area with significant improvements in energy and performance for racetrack memory based embedded systems.
Atrial Fibrillation Detection Using Weight-Pruned, Log-Quantised Convolutional Neural Networks
Jun 14, 2022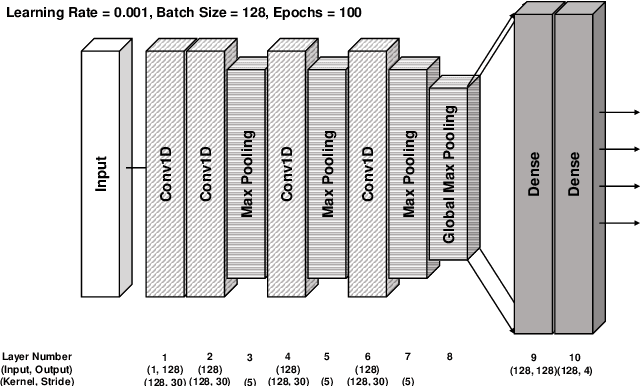
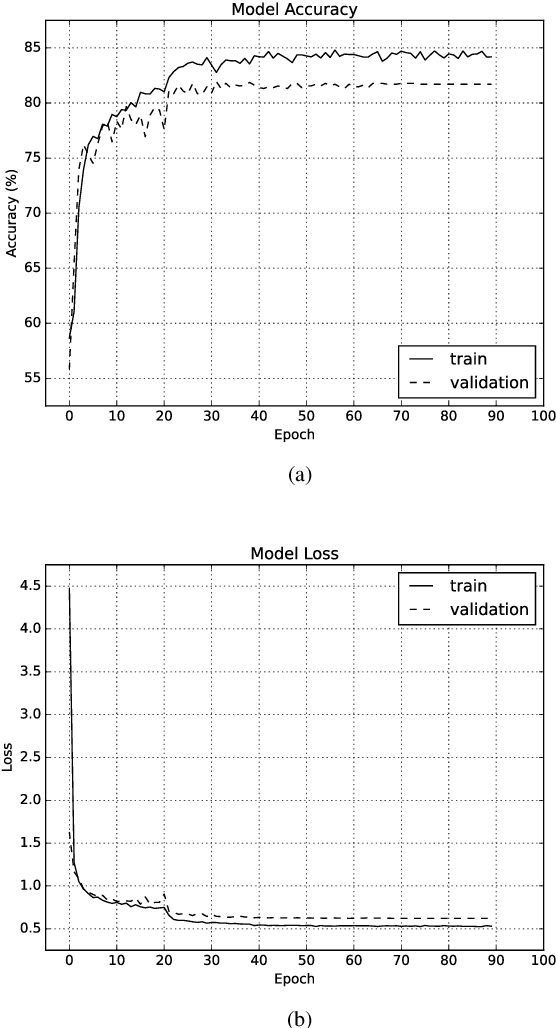
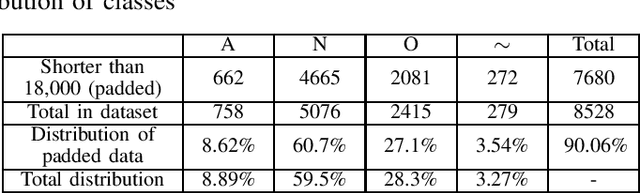
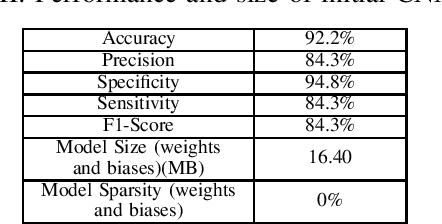
Deep neural networks (DNN) are a promising tool in medical applications. However, the implementation of complex DNNs on battery-powered devices is challenging due to high energy costs for communication. In this work, a convolutional neural network model is developed for detecting atrial fibrillation from electrocardiogram (ECG) signals. The model demonstrates high performance despite being trained on limited, variable-length input data. Weight pruning and logarithmic quantisation are combined to introduce sparsity and reduce model size, which can be exploited for reduced data movement and lower computational complexity. The final model achieved a 91.1% model compression ratio while maintaining high model accuracy of 91.7% and less than 1% loss.