 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDITnet: A Lightweight Network for Unsupervised Domain Adaptation in Speaker Verification
Jun 15, 2022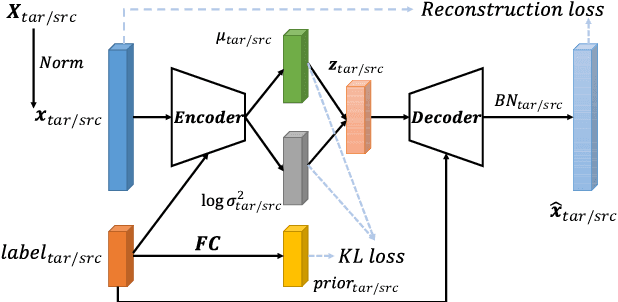
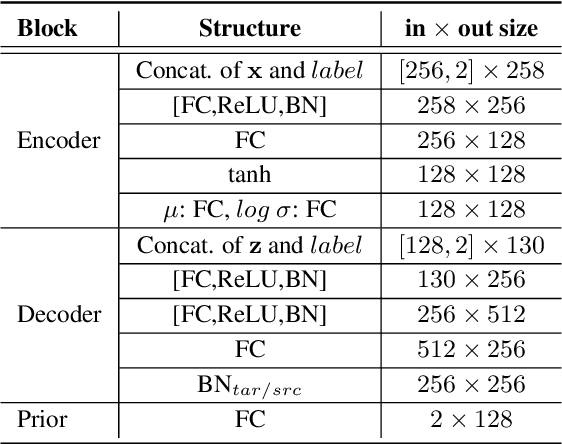
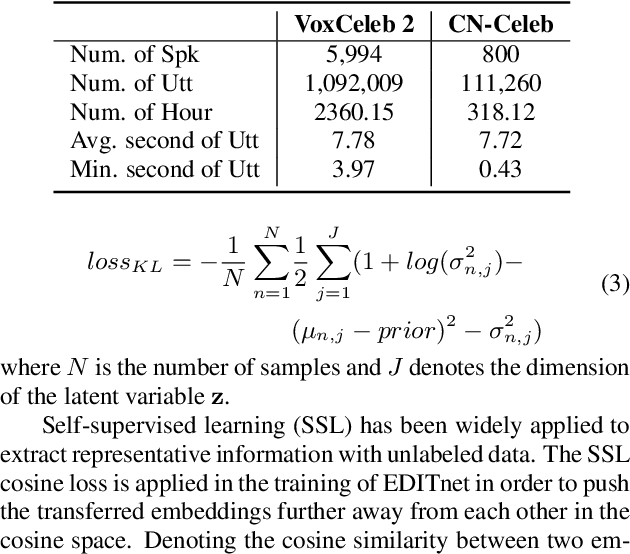
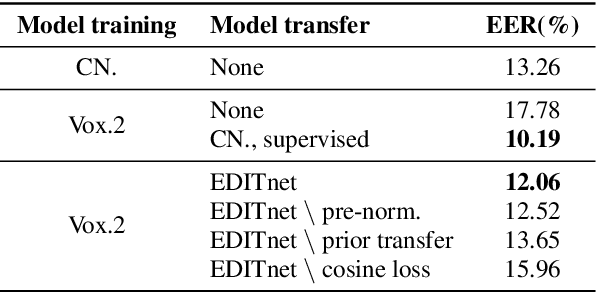
Performance degradation caused by language mismatch is a common problem when applying a speaker verification system on speech data in different languages. This paper proposes a domain transfer network, named EDITnet, to alleviate the language-mismatch problem on speaker embeddings without requiring speaker labels. The network leverages a conditional variational auto-encoder to transfer embeddings from the target domain into the source domain. A self-supervised learning strategy is imposed on the transferred embeddings so as to increase the cosine distance between embeddings from different speakers. In the training process of the EDITnet, the embedding extraction model is fixed without fine-tuning, which renders the training efficient and low-cost. Experiments on Voxceleb and CN-Celeb show that the embeddings transferred by EDITnet outperform the un-transferred ones by around 30% with the ECAPA-TDNN512. Performance improvement can also be achieved with other embedding extraction models, e.g., TDNN, SE-ResNet34.
Multivariate Empirical Mode Decomposition of EEG for Mental State Detection at Localized Brain Lobes
Jun 02, 2022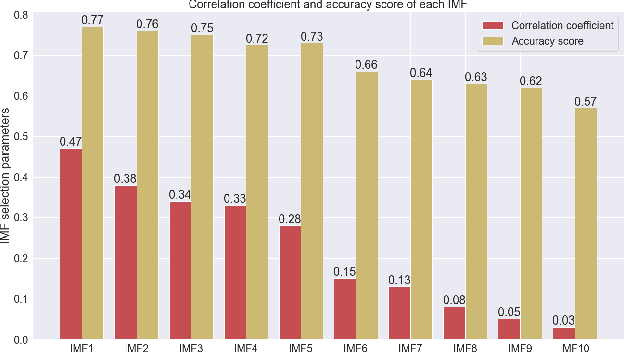
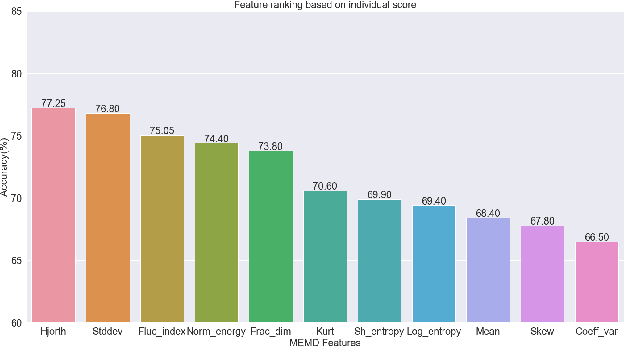
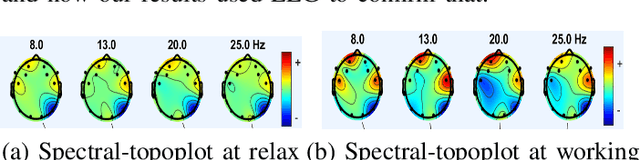
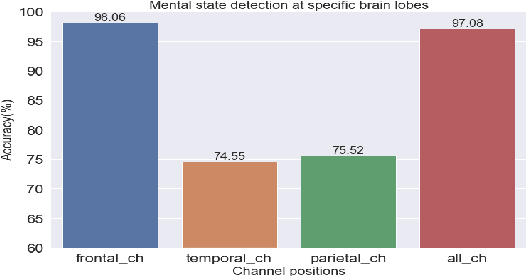
In this study, the Multivariate Empirical Mode Decomposition (MEMD) approach is applied to extract features from multi-channel EEG signals for mental state classification. MEMD is a data-adaptive analysis approach which is suitable particularly for multi-dimensional non-linear signals like EEG. Applying MEMD results in a set of oscillatory modes called intrinsic mode functions (IMFs). As the decomposition process is data-dependent, the IMFs vary in accordance with signal variation caused by functional brain activity. Among the extracted IMFs, it is found that those corresponding to high-oscillation modes are most useful for detecting different mental states. Non-linear features are computed from the IMFs that contribute most to mental state detection. These MEMD features show a significant performance gain over the conventional tempo-spectral features obtained by Fourier transform and Wavelet transform. The dominance of specific brain region is observed by analysing the MEMD features extracted from associated EEG channels. The frontal region is found to be most significant with a classification accuracy of 98.06%. This multi-dimensional decomposition approach upholds joint channel properties and produces most discriminative features for EEG based mental state detection.
MEMD-HHT based Emotion Detection from EEG using 3D CNN
Jun 02, 2022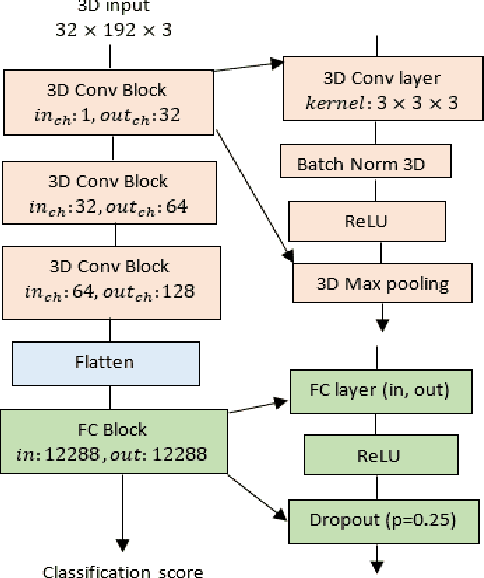
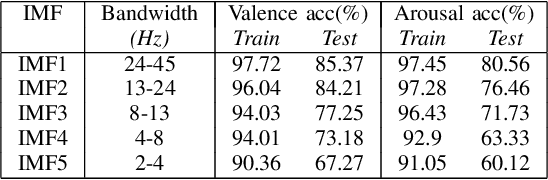
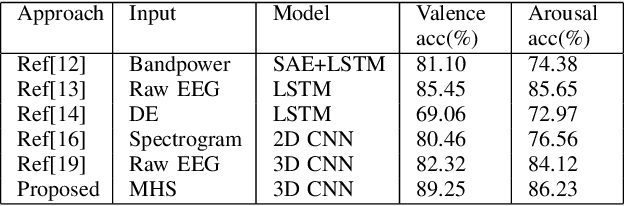
In this study, the Multivariate Empirical Mode Decomposition (MEMD) is applied to multichannel EEG to obtain scale-aligned intrinsic mode functions (IMFs) as input features for emotion detection. The IMFs capture local signal variation related to emotion changes. Among the extracted IMFs, the high oscillatory ones are found to be significant for the intended task. The Marginal Hilbert spectrum (MHS) is computed from the selected IMFs. A 3D convolutional neural network (CNN) is adopted to perform emotion detection with spatial-temporal-spectral feature representations that are constructed by stacking the multi-channel MHS over consecutive signal segments. The proposed approach is evaluated on the publicly available DEAP database. On binary classification of valence and arousal level (high versus low), the attained accuracies are 89.25% and 86.23% respectively, which significantly outperform previously reported systems with 2D CNN and/or conventional temporal and spectral features.
An Investigation on Applying Acoustic Feature Conversion to ASR of Adult and Child Speech
May 25, 2022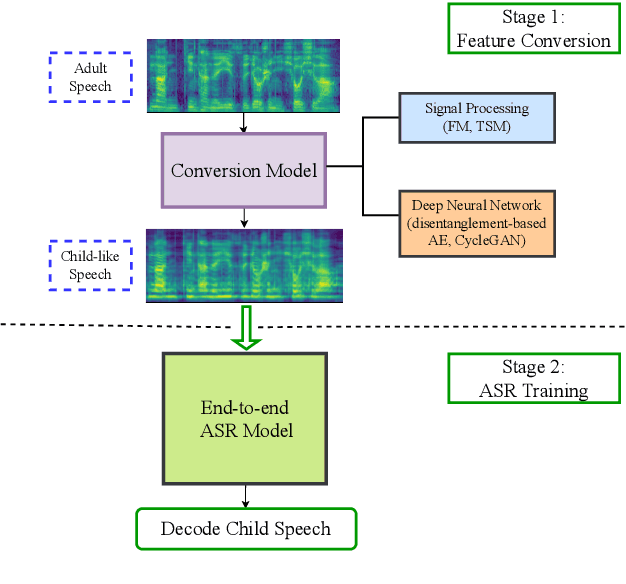
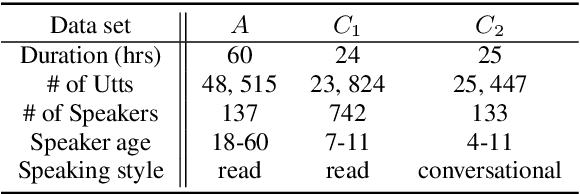
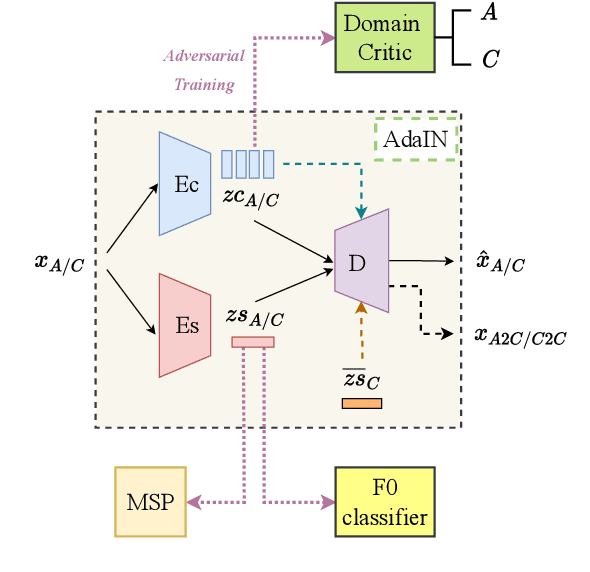
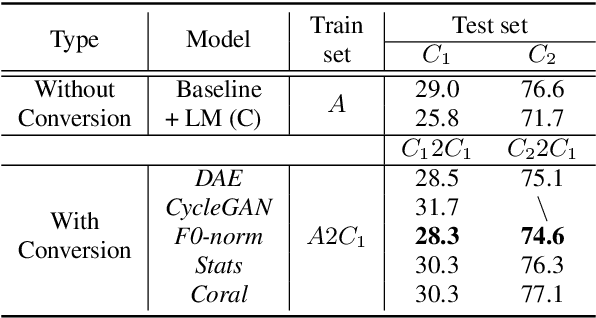
The performance of child speech recognition is generally less satisfactory compared to adult speech due to limited amount of training data. Significant performance degradation is expected when applying an automatic speech recognition (ASR) system trained on adult speech to child speech directly, as a result of domain mismatch. The present study is focused on adult-to-child acoustic feature conversion to alleviate this mismatch. Different acoustic feature conversion approaches, including deep neural network based and signal processing based, are investigated and compared under a fair experimental setting, in which converted acoustic features from the same amount of labeled adult speech are used to train the ASR models from scratch. Experimental results reveal that not all of the conversion methods lead to ASR performance gain. Specifically, as a classic unsupervised domain adaptation method, the statistic matching does not show an effectiveness. A disentanglement-based auto-encoder (DAE) conversion framework is found to be useful and the approach of F0 normalization achieves the best performance. It is noted that the F0 distribution of converted features is an important attribute to reflect the conversion quality, while utilizing an adult-child deep classification model to make judgment is shown to be inappropriate.
Unifying Cosine and PLDA Back-ends for Speaker Verification
Apr 22, 2022
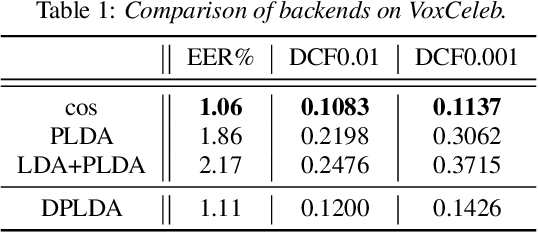
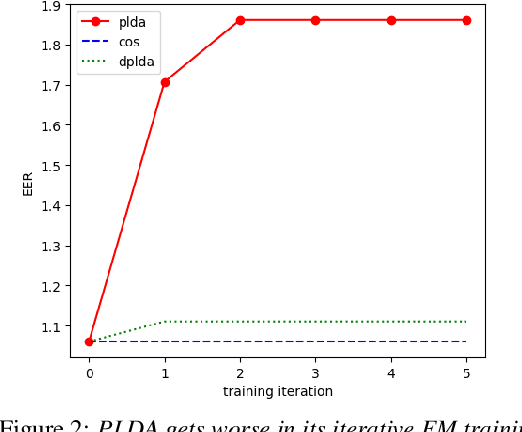
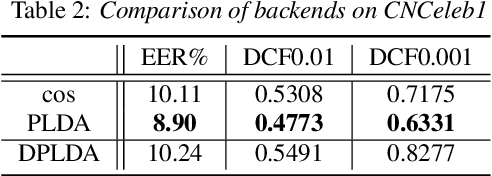
State-of-art speaker verification (SV) systems use a back-end model to score the similarity of speaker embeddings extracted from a neural network model. The commonly used back-end models are the cosine scoring and the probabilistic linear discriminant analysis (PLDA) scoring. With the recently developed neural embeddings, the theoretically more appealing PLDA approach is found to have no advantage against or even be inferior the simple cosine scoring in terms of SV system performance. This paper presents an investigation on the relation between the two scoring approaches, aiming to explain the above counter-intuitive observation. It is shown that the cosine scoring is essentially a special case of PLDA scoring. In other words, by properly setting the parameters of PLDA, the two back-ends become equivalent. As a consequence, the cosine scoring not only inherits the basic assumptions for the PLDA but also introduces additional assumptions on the properties of input embeddings. Experiments show that the dimensional independence assumption required by the cosine scoring contributes most to the performance gap between the two methods under the domain-matched condition. When there is severe domain mismatch and the dimensional independence assumption does not hold, the PLDA would perform better than the cosine for domain adaptation.
CorrectSpeech: A Fully Automated System for Speech Correction and Accent Reduction
Apr 12, 2022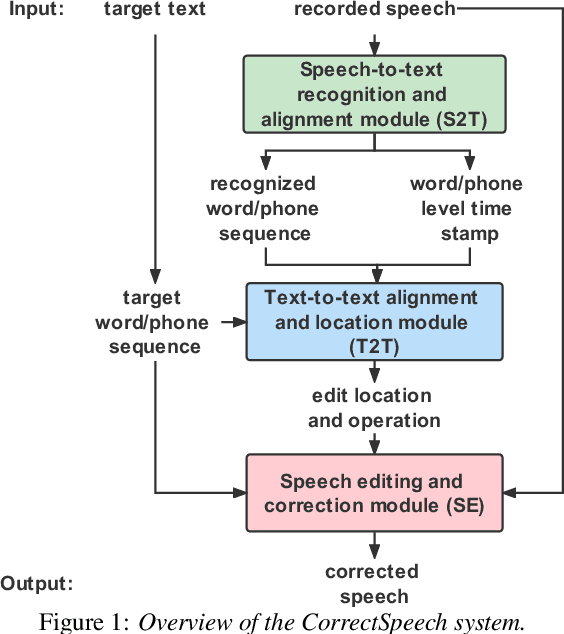
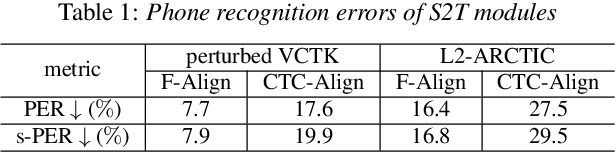
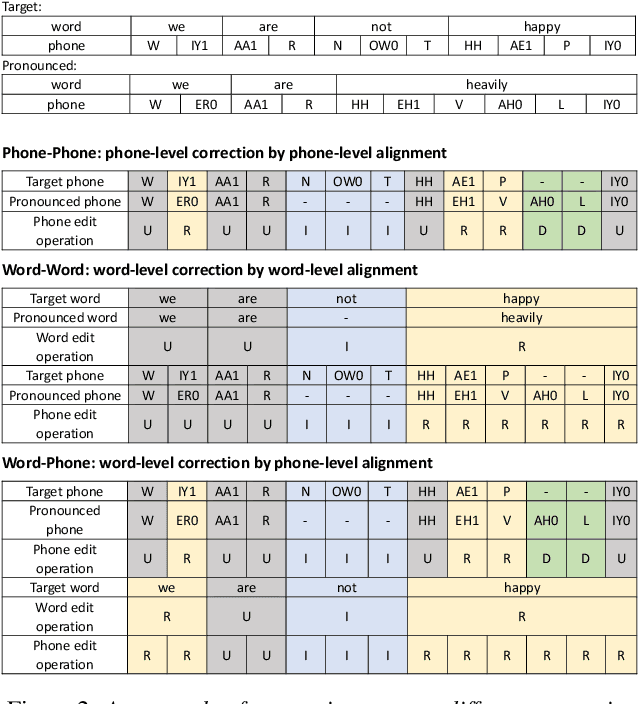
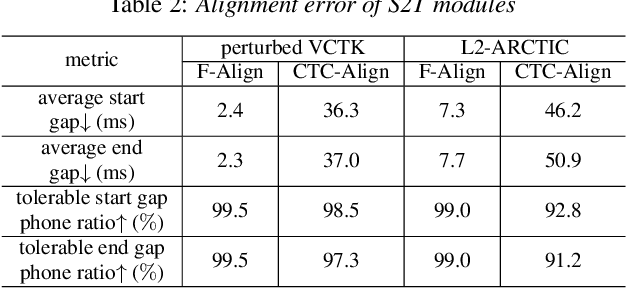
This study extends our previous work on text-based speech editing to developing a fully automated system for speech correction and accent reduction. Consider the application scenario that a recorded speech audio contains certain errors, e.g., inappropriate words, mispronunciations, that need to be corrected. The proposed system, named CorrectSpeech, performs the correction in three steps: recognizing the recorded speech and converting it into time-stamped symbol sequence, aligning recognized symbol sequence with target text to determine locations and types of required edit operations, and generating the corrected speech. Experiments show that the quality and naturalness of corrected speech depend on the performance of speech recognition and alignment modules, as well as the granularity level of editing operations. The proposed system is evaluated on two corpora: a manually perturbed version of VCTK and L2-ARCTIC. The results demonstrate that our system is able to correct mispronunciation and reduce accent in speech recordings. Audio samples are available online for demonstration https://daxintan-cuhk.github.io/CorrectSpeech/ .
Mixed-Phoneme BERT: Improving BERT with Mixed Phoneme and Sup-Phoneme Representations for Text to Speech
Mar 31, 2022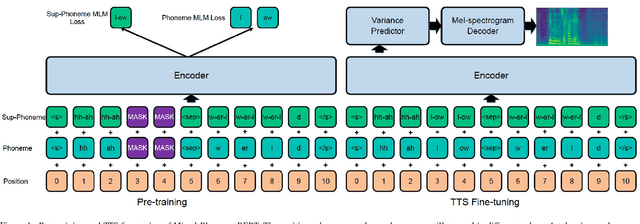
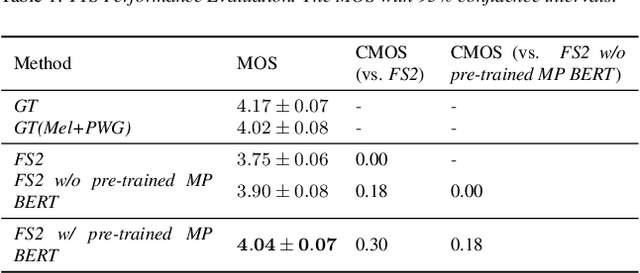

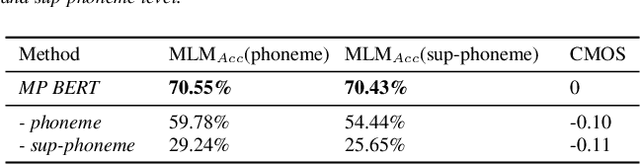
Recently, leveraging BERT pre-training to improve the phoneme encoder in text to speech (TTS) has drawn increasing attention. However, the works apply pre-training with character-based units to enhance the TTS phoneme encoder, which is inconsistent with the TTS fine-tuning that takes phonemes as input. Pre-training only with phonemes as input can alleviate the input mismatch but lack the ability to model rich representations and semantic information due to limited phoneme vocabulary. In this paper, we propose MixedPhoneme BERT, a novel variant of the BERT model that uses mixed phoneme and sup-phoneme representations to enhance the learning capability. Specifically, we merge the adjacent phonemes into sup-phonemes and combine the phoneme sequence and the merged sup-phoneme sequence as the model input, which can enhance the model capacity to learn rich contextual representations. Experiment results demonstrate that our proposed Mixed-Phoneme BERT significantly improves the TTS performance with 0.30 CMOS gain compared with the FastSpeech 2 baseline. The Mixed-Phoneme BERT achieves 3x inference speedup and similar voice quality to the previous TTS pre-trained model PnG BERT
Hierarchical Attention Network for Evaluating Therapist Empathy in Counseling Session
Mar 31, 2022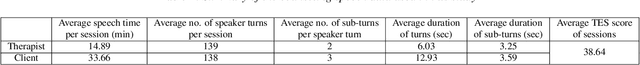
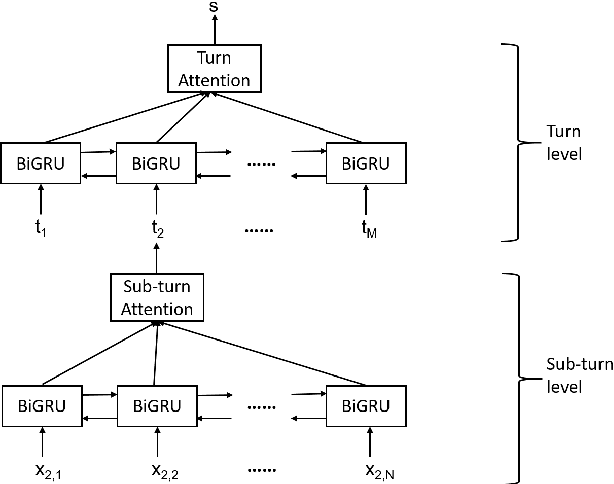
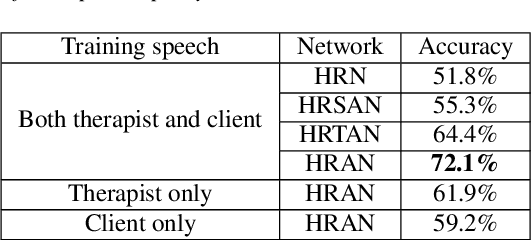
Counseling typically takes the form of spoken conversation between a therapist and a client. The empathy level expressed by the therapist is considered to be an essential quality factor of counseling outcome. This paper proposes a hierarchical recurrent network combined with two-level attention mechanisms to determine the therapist's empathy level solely from the acoustic features of conversational speech in a counseling session. The experimental results show that the proposed model can achieve an accuracy of 72.1% in classifying the therapist's empathy level as being "high" or "low". It is found that the speech from both the therapist and the client are contributing to predicting the empathy level that is subjectively rated by an expert observer. By analyzing speaker turns assigned with high attention weights, it is observed that 2 to 6 consecutive turns should be considered together to provide useful clues for detecting empathy, and the observer tends to take the whole session into consideration when rating the therapist empathy, instead of relying on a few specific speaker turns.
Automatic Detection of Speech Sound Disorder in Child Speech Using Posterior-based Speaker Representations
Mar 29, 2022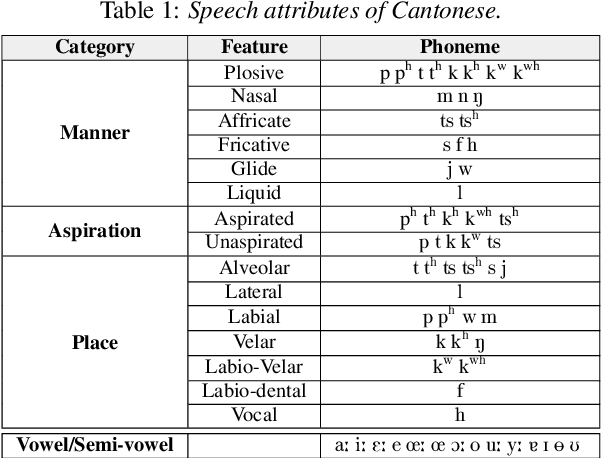
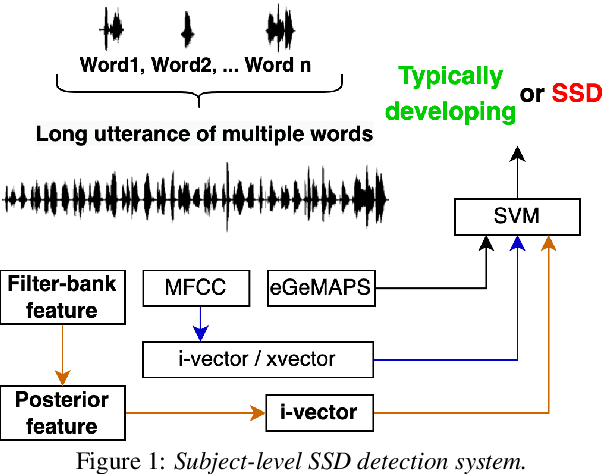
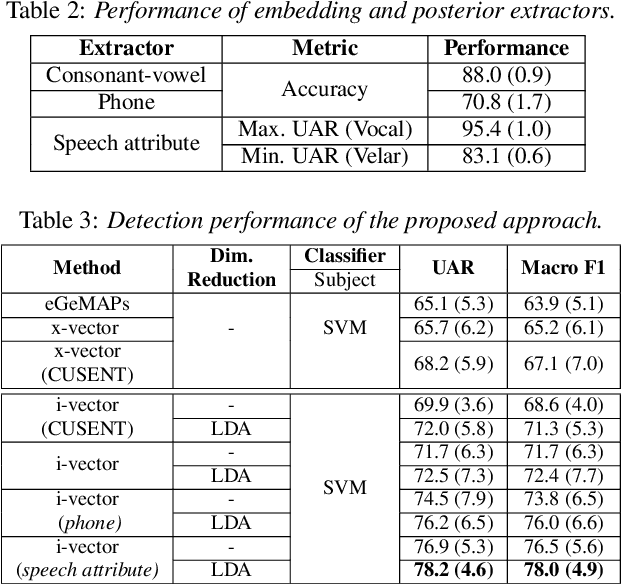
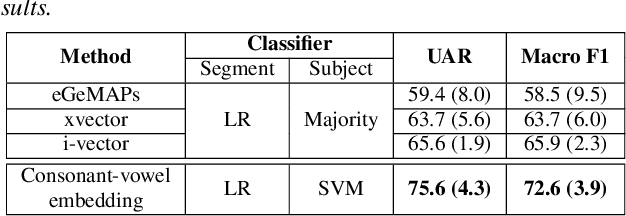
This paper presents a macroscopic approach to automatic detection of speech sound disorder (SSD) in child speech. Typically, SSD is manifested by persistent articulation and phonological errors on specific phonemes in the language. The disorder can be detected by focally analyzing the phonemes or the words elicited by the child subject. In the present study, instead of attempting to detect individual phone- and word-level errors, we propose to extract a subject-level representation from a long utterance that is constructed by concatenating multiple test words. The speaker verification approach, and posterior features generated by deep neural network models, are applied to derive various types of holistic representations. A linear classifier is trained to differentiate disordered speech in normal one. On the task of detecting SSD in Cantonese-speaking children, experimental results show that the proposed approach achieves improved detection performance over previous method that requires fusing phone-level detection results. Using articulatory posterior features to derive i-vectors from multiple-word utterances achieves an unweighted average recall of 78.2% and a macro F1 score of 78.0%.
Characterizing Therapist's Speaking Style in Relation to Empathy in Psychotherapy
Mar 24, 2022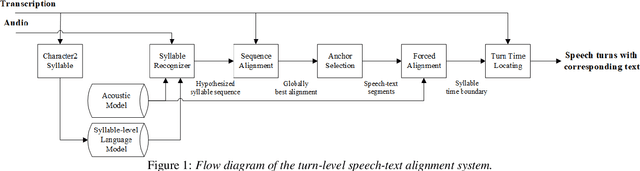
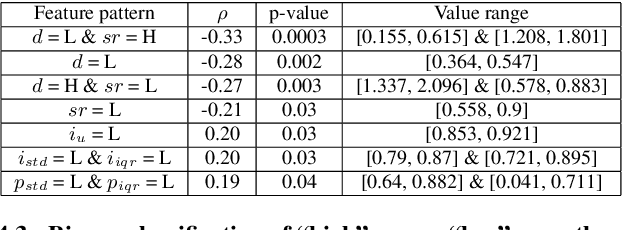
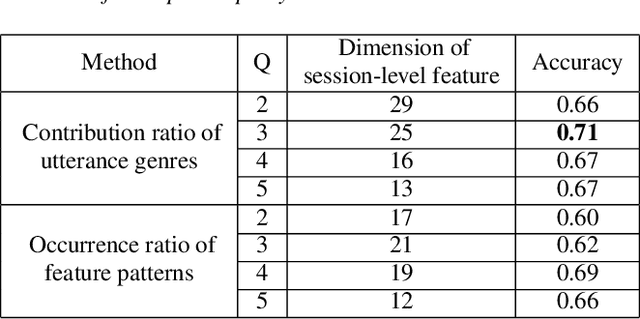
In conversation-based psychotherapy, therapists use verbal techniques to help clients express thoughts and feelings and change behaviors. In particular, how well therapists convey empathy is an essential quality index of psychotherapy sessions and is associated with psychotherapy outcome. In this paper, we analyze the prosody of therapist speech and attempt to associate the therapist's speaking style with subjectively perceived empathy. An automatic speech and text processing system is developed to segment long recordings of psychotherapy sessions into pause-delimited utterances with text transcriptions. Data-driven clustering is applied to the utterances from different therapists in multiple sessions. For each cluster, a typological representation of utterance genre is derived based on quantized prosodic feature parameters. Prominent speaking styles of the therapist can be observed and interpreted from salient utterance genres that are correlated with empathy. Using the salient utterance genres, an accuracy of 71% is achieved in classifying psychotherapy sessions into "high" and "low" empathy level. Analysis of results suggests that empathy level tends to be (1) low if therapists speak long utterances slowly or speak short utterances quickly; and (2) high if therapists talk to clients with a steady tone and volume.