 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscribe-to-Diarize: Neural Speaker Diarization for Unlimited Number of Speakers using End-to-End Speaker-Attributed ASR
Oct 07, 2021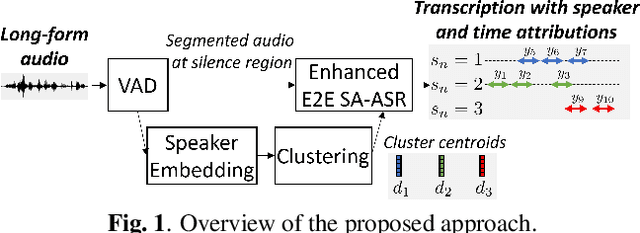
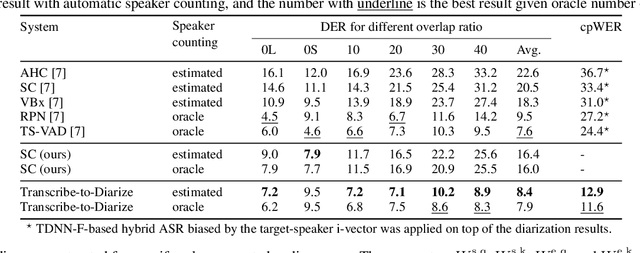
This paper presents Transcribe-to-Diarize, a new approach for neural speaker diarization that uses an end-to-end (E2E) speaker-attributed automatic speech recognition (SA-ASR). The E2E SA-ASR is a joint model that was recently proposed for speaker counting, multi-talker speech recognition, and speaker identification from monaural audio that contains overlapping speech. Although the E2E SA-ASR model originally does not estimate any time-related information, we show that the start and end times of each word can be estimated with sufficient accuracy from the internal state of the E2E SA-ASR by adding a small number of learnable parameters. Similar to the target-speaker voice activity detection (TS-VAD)-based diarization method, the E2E SA-ASR model is applied to estimate speech activity of each speaker while it has the advantages of (i) handling unlimited number of speakers, (ii) leveraging linguistic information for speaker diarization, and (iii) simultaneously generating speaker-attributed transcriptions. Experimental results on the LibriCSS and AMI corpora show that the proposed method achieves significantly better diarization error rate than various existing speaker diarization methods when the number of speakers is unknown, and achieves a comparable performance to TS-VAD when the number of speakers is given in advance. The proposed method simultaneously generates speaker-attributed transcription with state-of-the-art accuracy.
A Comparative Study of Modular and Joint Approaches for Speaker-Attributed ASR on Monaural Long-Form Audio
Jul 06, 2021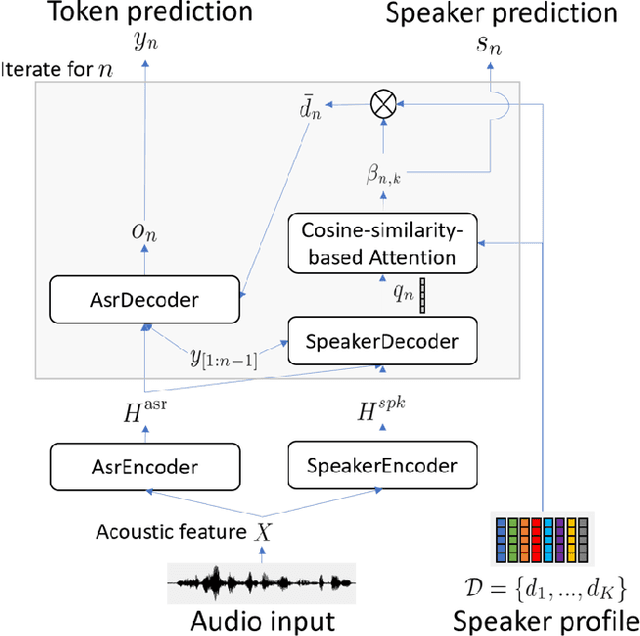
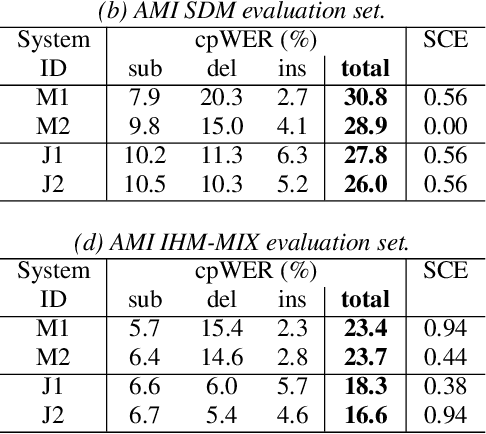
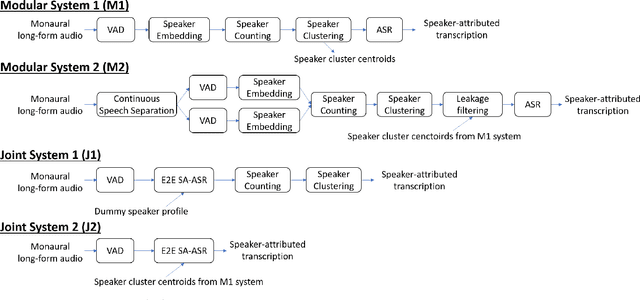
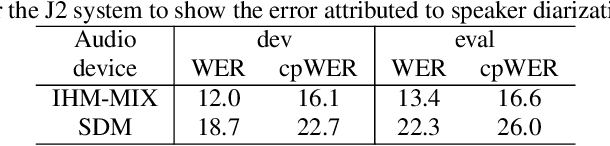
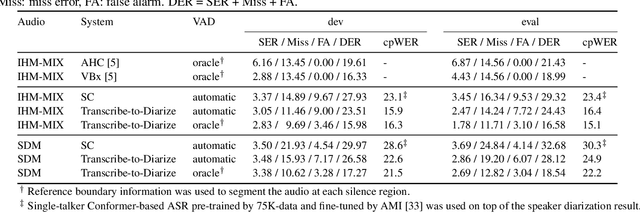
Speaker-attributed automatic speech recognition (SA-ASR) is a task to recognize "who spoke what" from multi-talker recordings. An SA-ASR system usually consists of multiple modules such as speech separation, speaker diarization and ASR. On the other hand, considering the joint optimization, an end-to-end (E2E) SA-ASR model has recently been proposed with promising results on simulation data. In this paper, we present our recent study on the comparison of such modular and joint approaches towards SA-ASR on real monaural recordings. We develop state-of-the-art SA-ASR systems for both modular and joint approaches by leveraging large-scale training data, including 75 thousand hours of ASR training data and the VoxCeleb corpus for speaker representation learning. We also propose a new pipeline that performs the E2E SA-ASR model after speaker clustering. Our evaluation on the AMI meeting corpus reveals that after fine-tuning with a small real data, the joint system performs 9.2--29.4% better in accuracy compared to the best modular system while the modular system performs better before such fine-tuning. We also conduct various error analyses to show the remaining issues for the monaural SA-ASR.
Investigation of Practical Aspects of Single Channel Speech Separation for ASR
Jul 05, 2021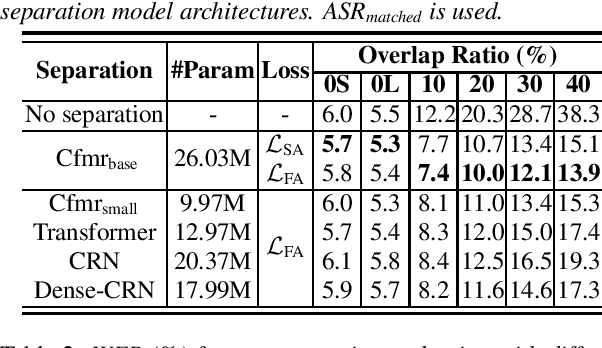
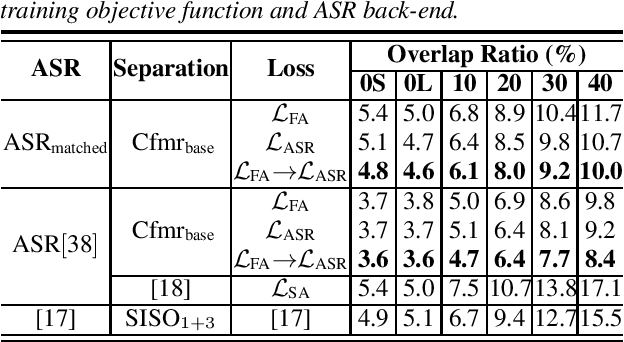
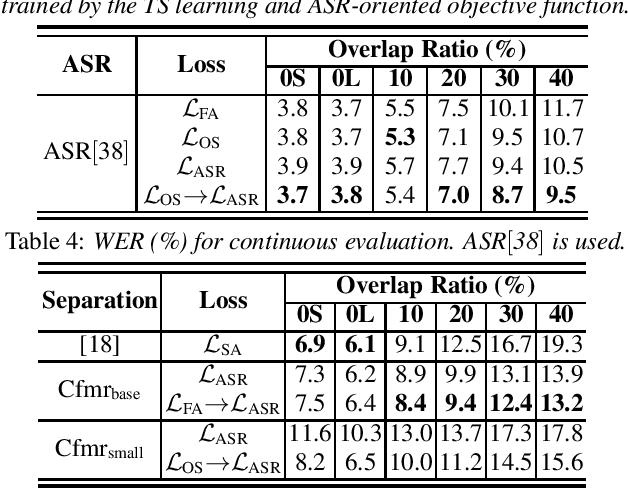
Speech separation has been successfully applied as a frontend processing module of conversation transcription systems thanks to its ability to handle overlapped speech and its flexibility to combine with downstream tasks such as automatic speech recognition (ASR). However, a speech separation model often introduces target speech distortion, resulting in a sub-optimum word error rate (WER). In this paper, we describe our efforts to improve the performance of a single channel speech separation system. Specifically, we investigate a two-stage training scheme that firstly applies a feature level optimization criterion for pretraining, followed by an ASR-oriented optimization criterion using an end-to-end (E2E) speech recognition model. Meanwhile, to keep the model light-weight, we introduce a modified teacher-student learning technique for model compression. By combining those approaches, we achieve a absolute average WER improvement of 2.70% and 0.77% using models with less than 10M parameters compared with the previous state-of-the-art results on the LibriCSS dataset for utterance-wise evaluation and continuous evaluation, respectively
Human Listening and Live Captioning: Multi-Task Training for Speech Enhancement
Jun 05, 2021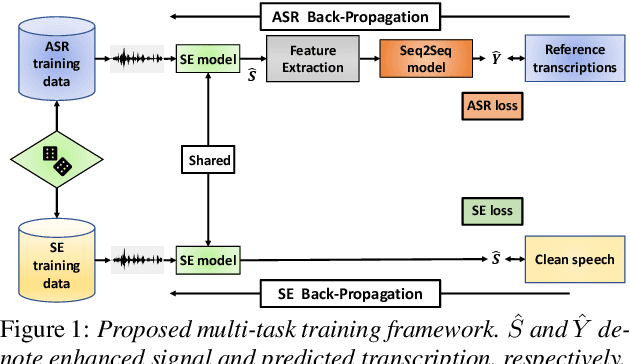
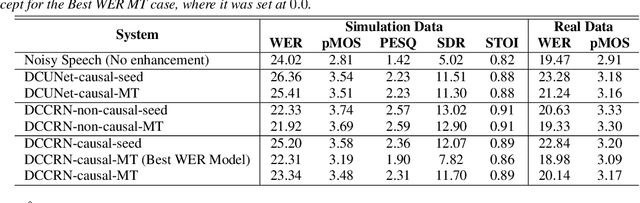
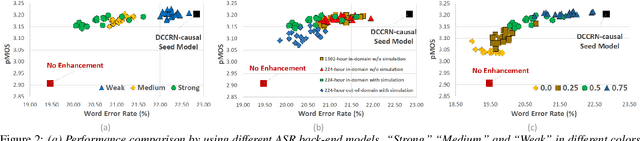
With the surge of online meetings, it has become more critical than ever to provide high-quality speech audio and live captioning under various noise conditions. However, most monaural speech enhancement (SE) models introduce processing artifacts and thus degrade the performance of downstream tasks, including automatic speech recognition (ASR). This paper proposes a multi-task training framework to make the SE models unharmful to ASR. Because most ASR training samples do not have corresponding clean signal references, we alternately perform two model update steps called SE-step and ASR-step. The SE-step uses clean and noisy signal pairs and a signal-based loss function. The ASR-step applies a pre-trained ASR model to training signals enhanced with the SE model. A cross-entropy loss between the ASR output and reference transcriptions is calculated to update the SE model parameters. Experimental results with realistic large-scale settings using ASR models trained on 75,000-hour data show that the proposed framework improves the word error rate for the SE output by 11.82% with little compromise in the SE quality. Performance analysis is also carried out by changing the ASR model, the data used for the ASR-step, and the schedule of the two update steps.
Large-Scale Pre-Training of End-to-End Multi-Talker ASR for Meeting Transcription with Single Distant Microphone
Apr 12, 2021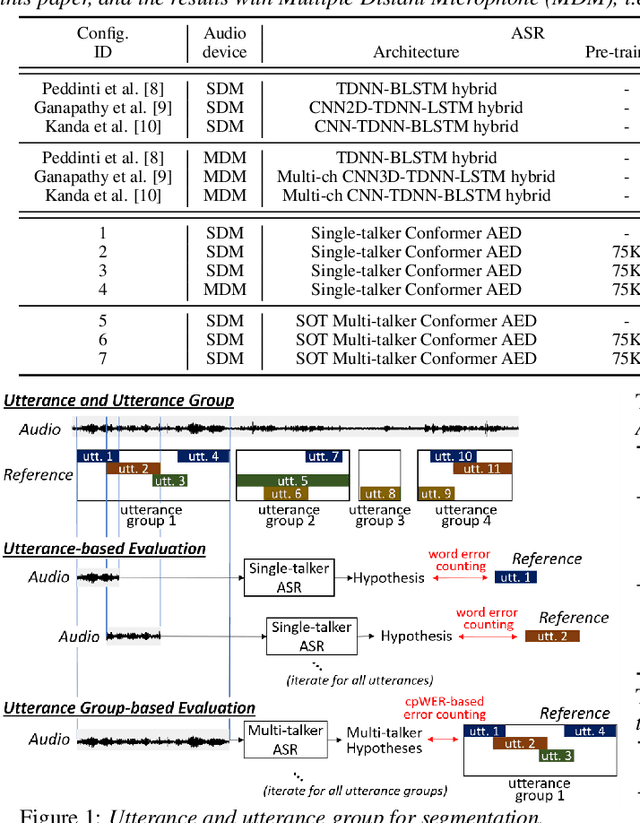


Transcribing meetings containing overlapped speech with only a single distant microphone (SDM) has been one of the most challenging problems for automatic speech recognition (ASR). While various approaches have been proposed, all previous studies on the monaural overlapped speech recognition problem were based on either simulation data or small-scale real data. In this paper, we extensively investigate a two-step approach where we first pre-train a serialized output training (SOT)-based multi-talker ASR by using large-scale simulation data and then fine-tune the model with a small amount of real meeting data. Experiments are conducted by utilizing 75 thousand (K) hours of our internal single-talker recording to simulate a total of 900K hours of multi-talker audio segments for supervised pre-training. With fine-tuning on the 70 hours of the AMI-SDM training data, our SOT ASR model achieves a word error rate (WER) of 21.2% for the AMI-SDM evaluation set while automatically counting speakers in each test segment. This result is not only significantly better than the previous state-of-the-art WER of 36.4% with oracle utterance boundary information but also better than a result by a similarly fine-tuned single-talker ASR model applied to beamformed audio.
End-to-End Speaker-Attributed ASR with Transformer
Apr 05, 2021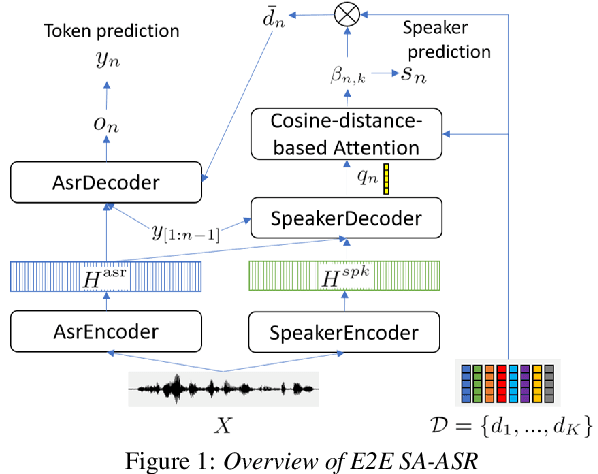
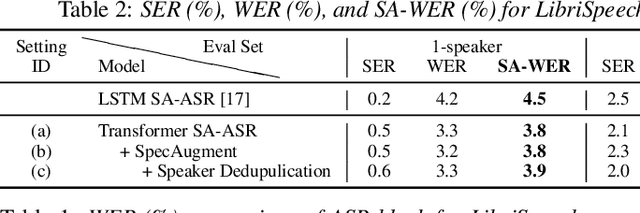
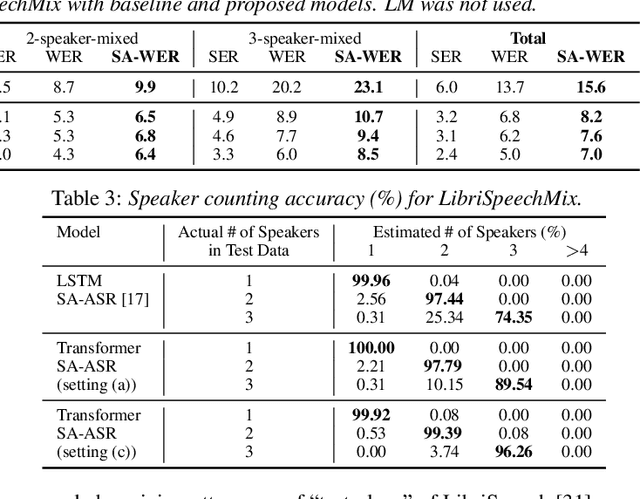
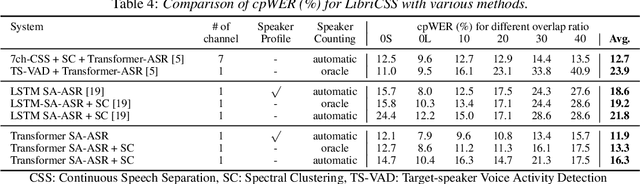
This paper presents our recent effort on end-to-end speaker-attributed automatic speech recognition, which jointly performs speaker counting, speech recognition and speaker identification for monaural multi-talker audio. Firstly, we thoroughly update the model architecture that was previously designed based on a long short-term memory (LSTM)-based attention encoder decoder by applying transformer architectures. Secondly, we propose a speaker deduplication mechanism to reduce speaker identification errors in highly overlapped regions. Experimental results on the LibriSpeechMix dataset shows that the transformer-based architecture is especially good at counting the speakers and that the proposed model reduces the speaker-attributed word error rate by 47% over the LSTM-based baseline. Furthermore, for the LibriCSS dataset, which consists of real recordings of overlapped speech, the proposed model achieves concatenated minimum-permutation word error rates of 11.9% and 16.3% with and without target speaker profiles, respectively, both of which are the state-of-the-art results for LibriCSS with the monaural setting.
Continuous Speech Separation with Ad Hoc Microphone Arrays
Mar 03, 2021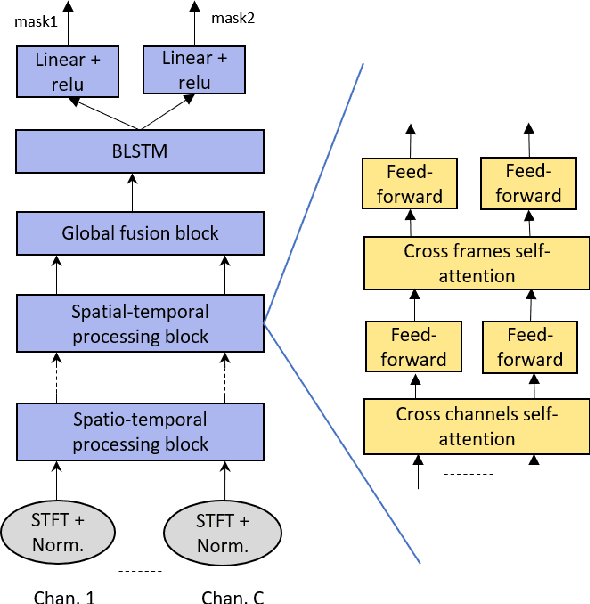

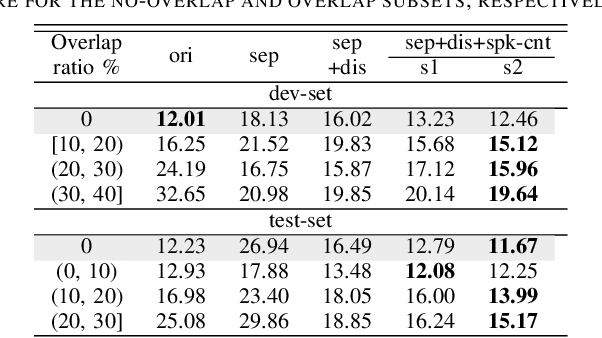
Speech separation has been shown effective for multi-talker speech recognition. Under the ad hoc microphone array setup where the array consists of spatially distributed asynchronous microphones, additional challenges must be overcome as the geometry and number of microphones are unknown beforehand. Prior studies show, with a spatial-temporalinterleaving structure, neural networks can efficiently utilize the multi-channel signals of the ad hoc array. In this paper, we further extend this approach to continuous speech separation. Several techniques are introduced to enable speech separation for real continuous recordings. First, we apply a transformer-based network for spatio-temporal modeling of the ad hoc array signals. In addition, two methods are proposed to mitigate a speech duplication problem during single talker segments, which seems more severe in the ad hoc array scenarios. One method is device distortion simulation for reducing the acoustic mismatch between simulated training data and real recordings. The other is speaker counting to detect the single speaker segments and merge the output signal channels. Experimental results for AdHoc-LibiCSS, a new dataset consisting of continuous recordings of concatenated LibriSpeech utterances obtained by multiple different devices, show the proposed separation method can significantly improve the ASR accuracy for overlapped speech with little performance degradation for single talker segments.
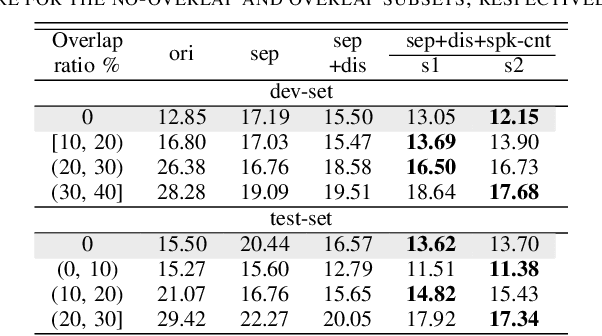
Hypothesis Stitcher for End-to-End Speaker-attributed ASR on Long-form Multi-talker Recordings
Jan 06, 2021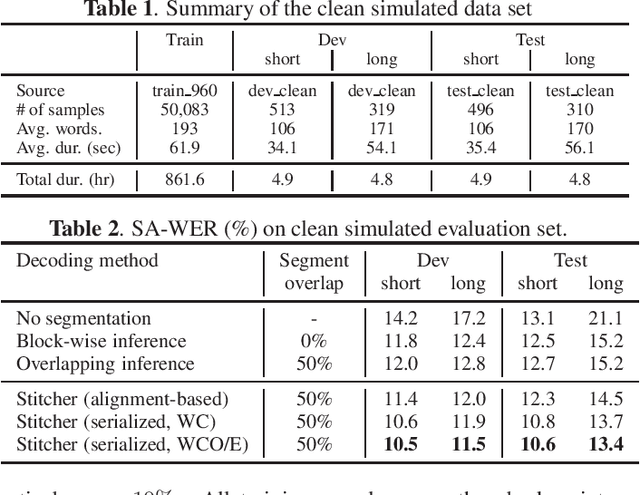
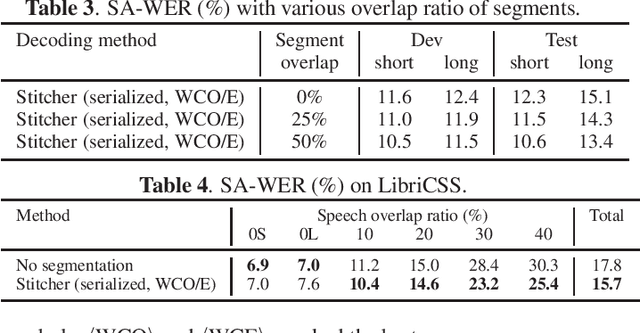
An end-to-end (E2E) speaker-attributed automatic speech recognition (SA-ASR) model was proposed recently to jointly perform speaker counting, speech recognition and speaker identification. The model achieved a low speaker-attributed word error rate (SA-WER) for monaural overlapped speech comprising an unknown number of speakers. However, the E2E modeling approach is susceptible to the mismatch between the training and testing conditions. It has yet to be investigated whether the E2E SA-ASR model works well for recordings that are much longer than samples seen during training. In this work, we first apply a known decoding technique that was developed to perform single-speaker ASR for long-form audio to our E2E SA-ASR task. Then, we propose a novel method using a sequence-to-sequence model, called hypothesis stitcher. The model takes multiple hypotheses obtained from short audio segments that are extracted from the original long-form input, and it then outputs a fused single hypothesis. We propose several architectural variations of the hypothesis stitcher model and compare them with the conventional decoding methods. Experiments using LibriSpeech and LibriCSS corpora show that the proposed method significantly improves SA-WER especially for long-form multi-talker recordings.
Minimum Bayes Risk Training for End-to-End Speaker-Attributed ASR
Nov 03, 2020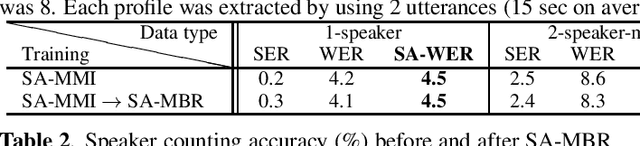
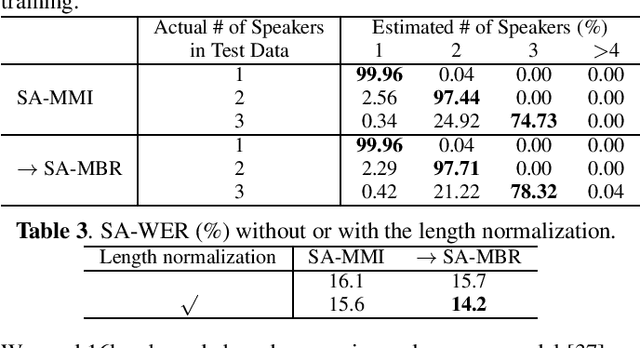
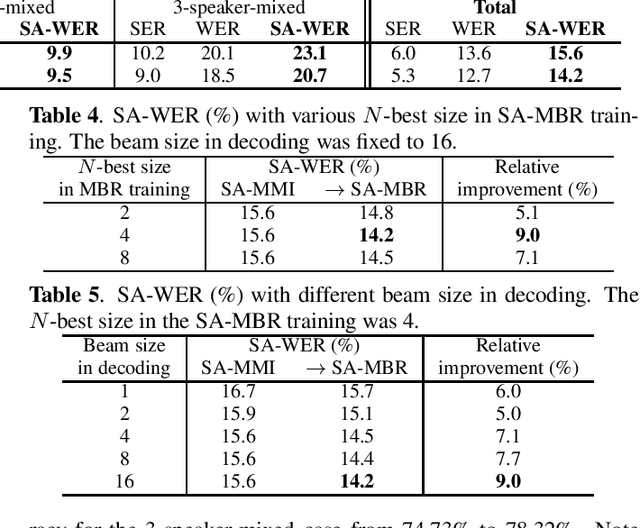
Recently, an end-to-end speaker-attributed automatic speech recognition (E2E SA-ASR) model was proposed as a joint model of speaker counting, speech recognition and speaker identification for monaural overlapped speech. In the previous study, the model parameters were trained based on the speaker-attributed maximum mutual information (SA-MMI) criterion, with which the joint posterior probability for multi-talker transcription and speaker identification are maximized over training data. Although SA-MMI training showed promising results for overlapped speech consisting of various numbers of speakers, the training criterion was not directly linked to the final evaluation metric, i.e., speaker-attributed word error rate (SA-WER). In this paper, we propose a speaker-attributed minimum Bayes risk (SA-MBR) training method where the parameters are trained to directly minimize the expected SA-WER over the training data. Experiments using the LibriSpeech corpus show that the proposed SA-MBR training reduces the SA-WER by 9.0 % relative compared with the SA-MMI-trained model.
Don't shoot butterfly with rifles: Multi-channel Continuous Speech Separation with Early Exit Transformer
Oct 23, 2020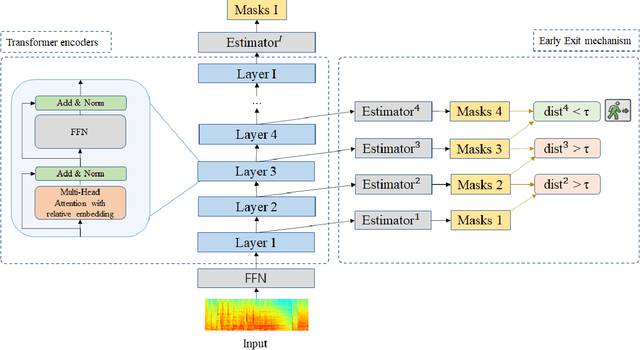
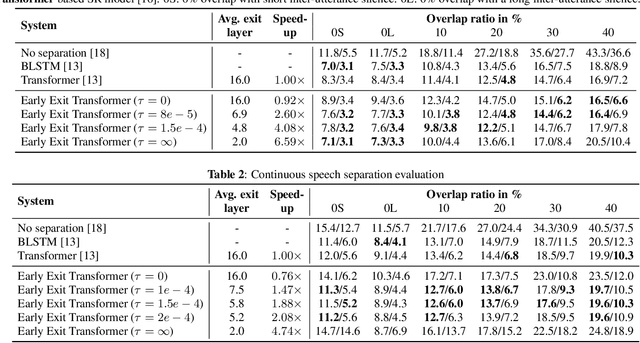
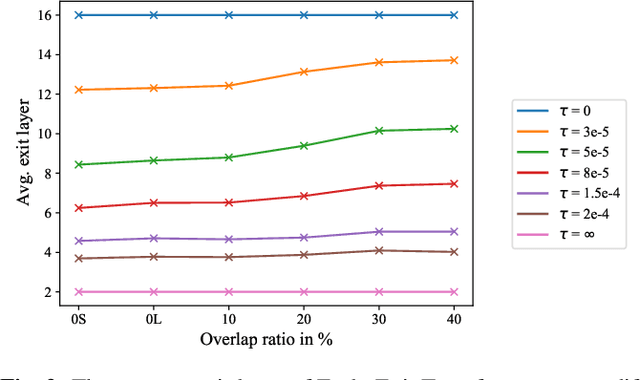
With its strong modeling capacity that comes from a multi-head and multi-layer structure, Transformer is a very powerful model for learning a sequential representation and has been successfully applied to speech separation recently. However, multi-channel speech separation sometimes does not necessarily need such a heavy structure for all time frames especially when the cross-talker challenge happens only occasionally. For example, in conversation scenarios, most regions contain only a single active speaker, where the separation task downgrades to a single speaker enhancement problem. It turns out that using a very deep network structure for dealing with signals with a low overlap ratio not only negatively affects the inference efficiency but also hurts the separation performance. To deal with this problem, we propose an early exit mechanism, which enables the Transformer model to handle different cases with adaptive depth. Experimental results indicate that not only does the early exit mechanism accelerate the inference, but it also improves the accuracy.