 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Community Detection with Deep Learning
May 26, 2021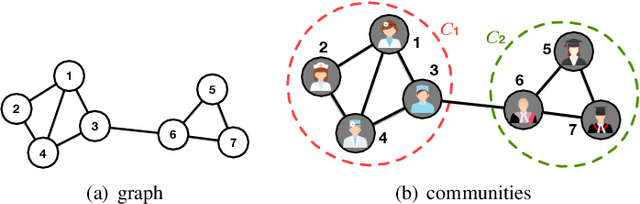
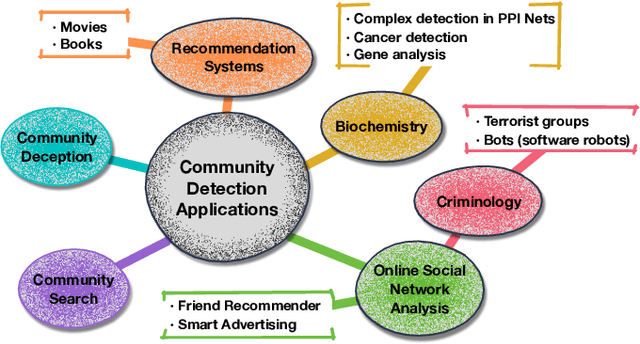
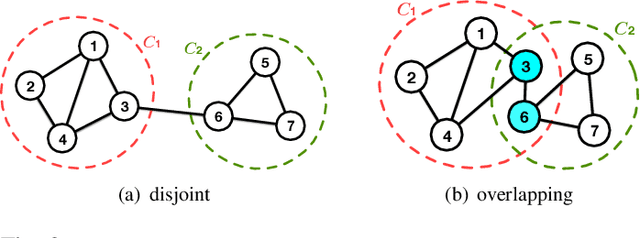
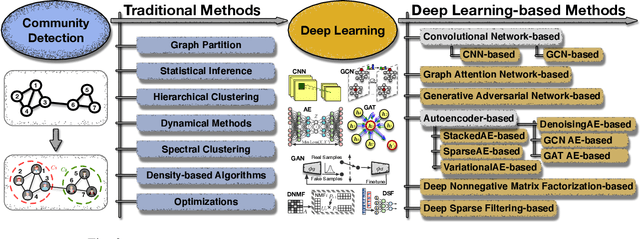
A community reveals the features and connections of its members that are different from those in other communities in a network. Detecting communities is of great significance in network analysis. Despite the classical spectral clustering and statistical inference methods, we notice a significant development of deep learning techniques for community detection in recent years with their advantages in handling high dimensional network data. Hence, a comprehensive overview of community detection's latest progress through deep learning is timely to both academics and practitioners. This survey devises and proposes a new taxonomy covering different categories of the state-of-the-art methods, including deep learning-based models upon deep neural networks, deep nonnegative matrix factorization and deep sparse filtering. The main category, i.e., deep neural networks, is further divided into convolutional networks, graph attention networks, generative adversarial networks and autoencoders. The survey also summarizes the popular benchmark data sets, model evaluation metrics, and open-source implementations to address experimentation settings. We then discuss the practical applications of community detection in various domains and point to implementation scenarios. Finally, we outline future directions by suggesting challenging topics in this fast-growing deep learning field.
RAIDER: Reinforcement-aided Spear Phishing Detector
May 17, 2021


Spear Phishing is a harmful cyber-attack facing business and individuals worldwide. Considerable research has been conducted recently into the use of Machine Learning (ML) techniques to detect spear-phishing emails. ML-based solutions may suffer from zero-day attacks; unseen attacks unaccounted for in the training data. As new attacks emerge, classifiers trained on older data are unable to detect these new varieties of attacks resulting in increasingly inaccurate predictions. Spear Phishing detection also faces scalability challenges due to the growth of the required features which is proportional to the number of the senders within a receiver mailbox. This differs from traditional phishing attacks which typically perform only a binary classification between phishing and benign emails. Therefore, we devise a possible solution to these problems, named RAIDER: Reinforcement AIded Spear Phishing DEtectoR. A reinforcement-learning based feature evaluation system that can automatically find the optimum features for detecting different types of attacks. By leveraging a reward and penalty system, RAIDER allows for autonomous features selection. RAIDER also keeps the number of features to a minimum by selecting only the significant features to represent phishing emails and detect spear-phishing attacks. After extensive evaluation of RAIDER over 11,000 emails and across 3 attack scenarios, our results suggest that using reinforcement learning to automatically identify the significant features could reduce the dimensions of the required features by 55% in comparison to existing ML-based systems. It also improves the accuracy of detecting spoofing attacks by 4% from 90% to 94%. In addition, RAIDER demonstrates reasonable detection accuracy even against a sophisticated attack named Known Sender in which spear-phishing emails greatly resemble those of the impersonated sender.
Robust Training Using Natural Transformation
May 10, 2021
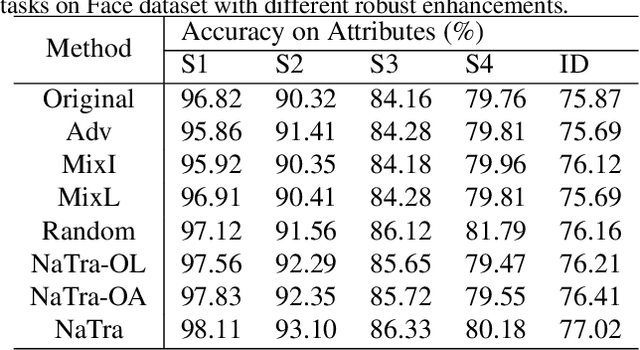

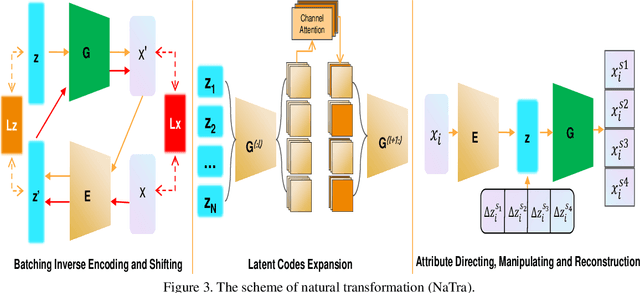
Previous robustness approaches for deep learning models such as data augmentation techniques via data transformation or adversarial training cannot capture real-world variations that preserve the semantics of the input, such as a change in lighting conditions. To bridge this gap, we present NaTra, an adversarial training scheme that is designed to improve the robustness of image classification algorithms. We target attributes of the input images that are independent of the class identification, and manipulate those attributes to mimic real-world natural transformations (NaTra) of the inputs, which are then used to augment the training dataset of the image classifier. Specifically, we apply \textit{Batch Inverse Encoding and Shifting} to map a batch of given images to corresponding disentangled latent codes of well-trained generative models. \textit{Latent Codes Expansion} is used to boost image reconstruction quality through the incorporation of extended feature maps. \textit{Unsupervised Attribute Directing and Manipulation} enables identification of the latent directions that correspond to specific attribute changes, and then produce interpretable manipulations of those attributes, thereby generating natural transformations to the input data. We demonstrate the efficacy of our scheme by utilizing the disentangled latent representations derived from well-trained GANs to mimic transformations of an image that are similar to real-world natural variations (such as lighting conditions or hairstyle), and train models to be invariant to these natural transformations. Extensive experiments show that our method improves generalization of classification models and increases its robustness to various real-world distortions
OCTOPUS: Overcoming Performance andPrivatization Bottlenecks in Distributed Learning
May 03, 2021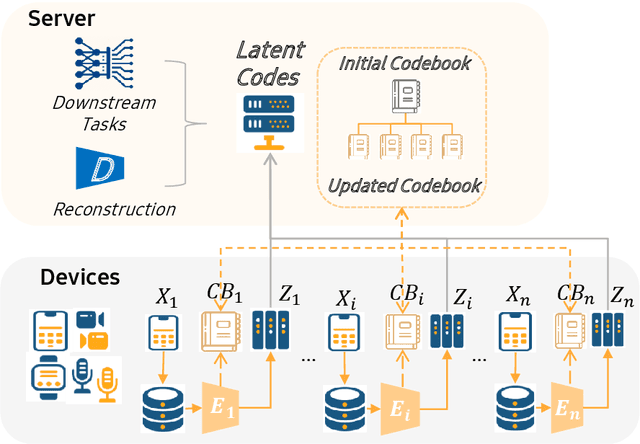

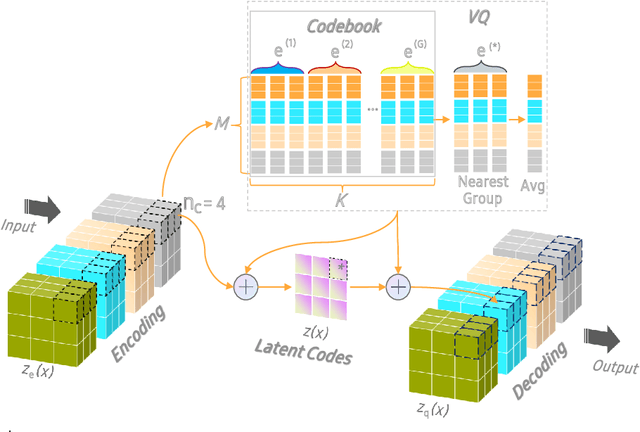
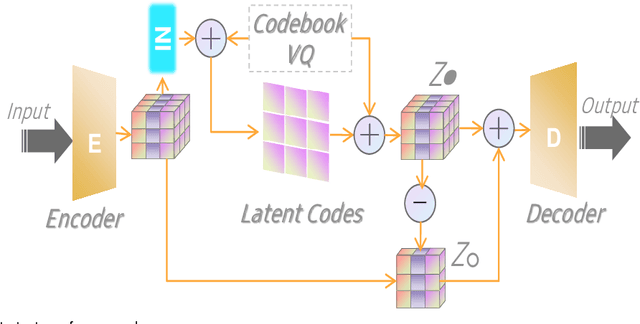
The diversity and quantity of the data warehousing, gathering data from distributed devices such as mobile phones, can enhance machine learning algorithms' success and robustness. Federated learning enables distributed participants to collaboratively learn a commonly-shared model while holding data locally. However, it is also faced with expensive communication and limitations due to the heterogeneity of distributed data sources and lack of access to global data. In this paper, we investigate a practical distributed learning scenario where multiple downstream tasks (e.g., classifiers) could be learned from dynamically-updated and non-iid distributed data sources, efficiently and providing local privatization. We introduce a new distributed learning scheme to address communication overhead via latent compression, leveraging global data while providing local privatization of local data without additional cost due to encryption or perturbation. This scheme divides the learning into (1) informative feature encoding, extracting and transmitting the latent space compressed representation features of local data at each node to address communication overhead; (2) downstream tasks centralized at the server using the encoded codes gathered from each node to address computing and storage overhead. Besides, a disentanglement strategy is applied to address the privatization of sensitive components of local data. Extensive experiments are conducted on image and speech datasets. The results demonstrate that downstream tasks on the compact latent representations can achieve comparable accuracy to centralized learning with the privatization of local data.
Confined Gradient Descent: Privacy-preserving Optimization for Federated Learning
Apr 27, 2021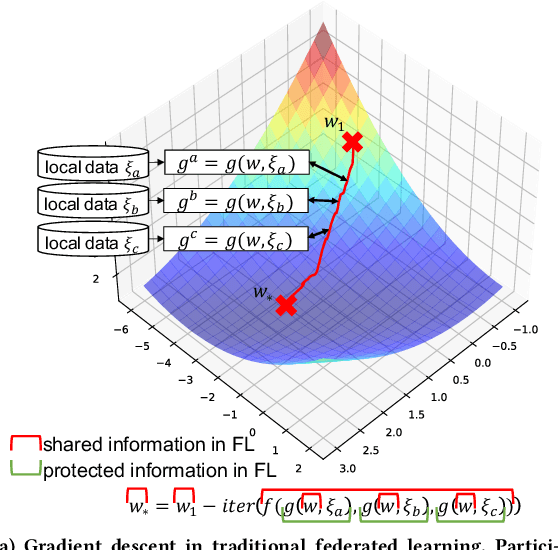
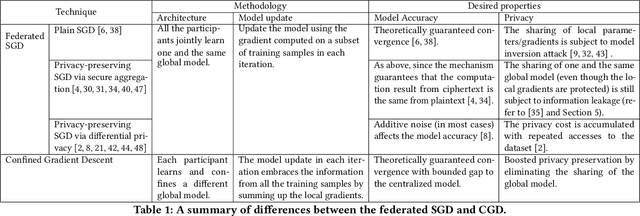
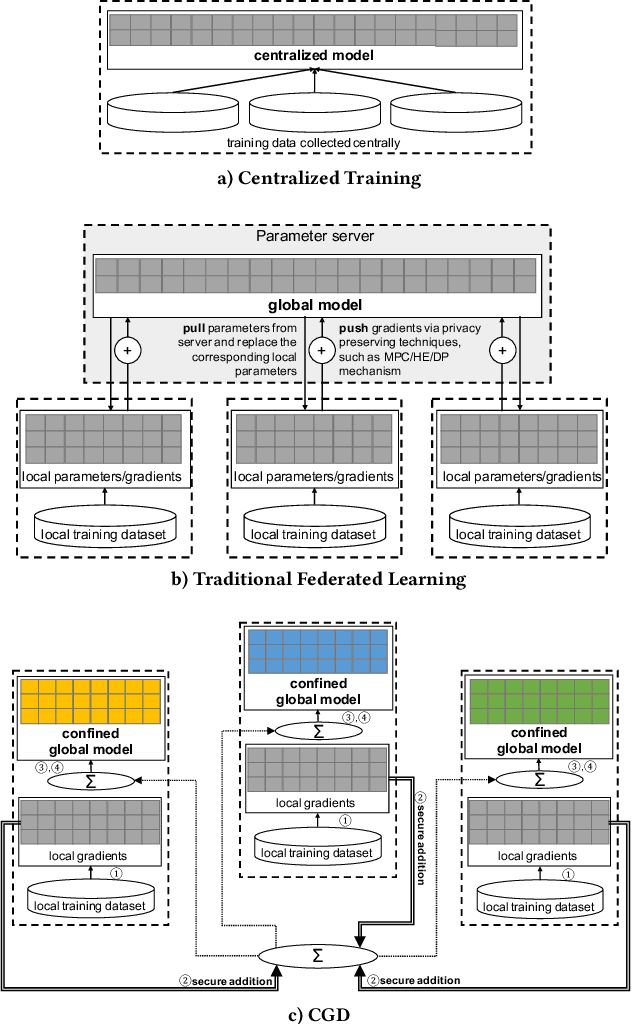

Federated learning enables multiple participants to collaboratively train a model without aggregating the training data. Although the training data are kept within each participant and the local gradients can be securely synthesized, recent studies have shown that such privacy protection is insufficient. The global model parameters that have to be shared for optimization are susceptible to leak information about training data. In this work, we propose Confined Gradient Descent (CGD) that enhances privacy of federated learning by eliminating the sharing of global model parameters. CGD exploits the fact that a gradient descent optimization can start with a set of discrete points and converges to another set at the neighborhood of the global minimum of the objective function. It lets the participants independently train on their local data, and securely share the sum of local gradients to benefit each other. We formally demonstrate CGD's privacy enhancement over traditional FL. We prove that less information is exposed in CGD compared to that of traditional FL. CGD also guarantees desired model accuracy. We theoretically establish a convergence rate for CGD. We prove that the loss of the proprietary models learned for each participant against a model learned by aggregated training data is bounded. Extensive experimental results on two real-world datasets demonstrate the performance of CGD is comparable with the centralized learning, with marginal differences on validation loss (mostly within 0.05) and accuracy (mostly within 1%).
Evaluation and Optimization of Distributed Machine Learning Techniques for Internet of Things
Mar 03, 2021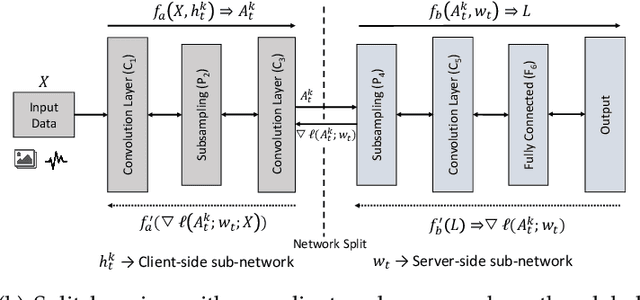
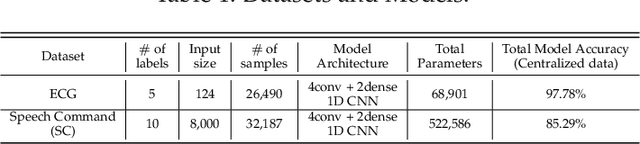
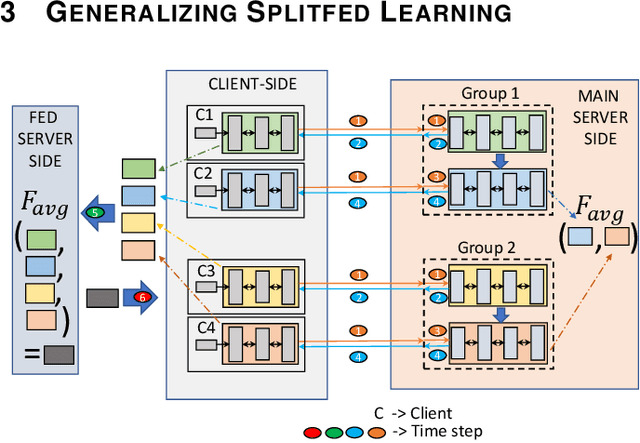
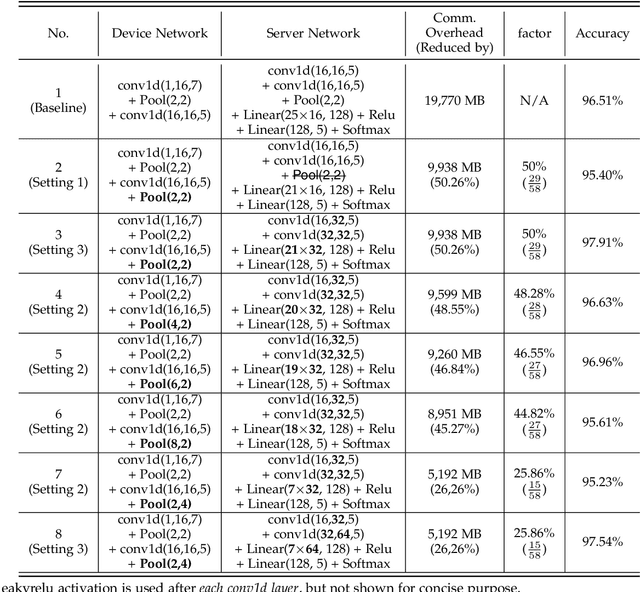
Federated learning (FL) and split learning (SL) are state-of-the-art distributed machine learning techniques to enable machine learning training without accessing raw data on clients or end devices. However, their \emph{comparative training performance} under real-world resource-restricted Internet of Things (IoT) device settings, e.g., Raspberry Pi, remains barely studied, which, to our knowledge, have not yet been evaluated and compared, rendering inconvenient reference for practitioners. This work firstly provides empirical comparisons of FL and SL in real-world IoT settings regarding (i) learning performance with heterogeneous data distributions and (ii) on-device execution overhead. Our analyses in this work demonstrate that the learning performance of SL is better than FL under an imbalanced data distribution but worse than FL under an extreme non-IID data distribution. Recently, FL and SL are combined to form splitfed learning (SFL) to leverage each of their benefits (e.g., parallel training of FL and lightweight on-device computation requirement of SL). This work then considers FL, SL, and SFL, and mount them on Raspberry Pi devices to evaluate their performance, including training time, communication overhead, power consumption, and memory usage. Besides evaluations, we apply two optimizations. Firstly, we generalize SFL by carefully examining the possibility of a hybrid type of model training at the server-side. The generalized SFL merges sequential (dependent) and parallel (independent) processes of model training and is thus beneficial for a system with large-scaled IoT devices, specifically at the server-side operations. Secondly, we propose pragmatic techniques to substantially reduce the communication overhead by up to four times for the SL and (generalized) SFL.
Token-Modification Adversarial Attacks for Natural Language Processing: A Survey
Mar 01, 2021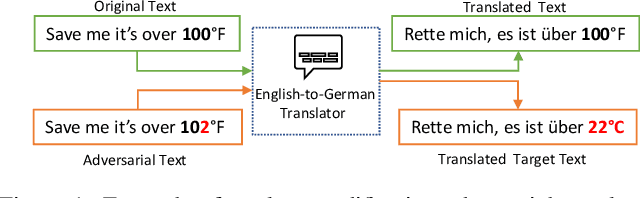
There are now many adversarial attacks for natural language processing systems. Of these, a vast majority achieve success by modifying individual document tokens, which we call here a \textit{token-modification} attack. Each token-modification attack is defined by a specific combination of fundamental \textit{components}, such as a constraint on the adversary or a particular search algorithm. Motivated by this observation, we survey existing token-modification attacks and extract the components of each. We use an attack-independent framework to structure our survey which results in an effective categorisation of the field and an easy comparison of components. We hope this survey will guide new researchers to this field and spark further research into the individual attack components.
DeepiSign: Invisible Fragile Watermark to Protect the Integrityand Authenticity of CNN
Jan 12, 2021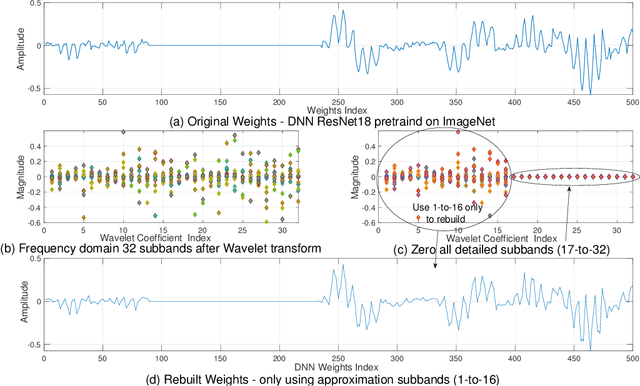
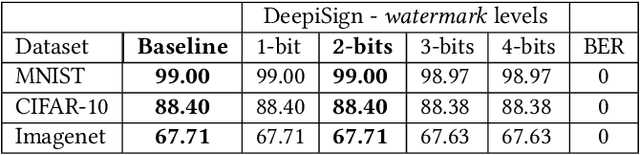
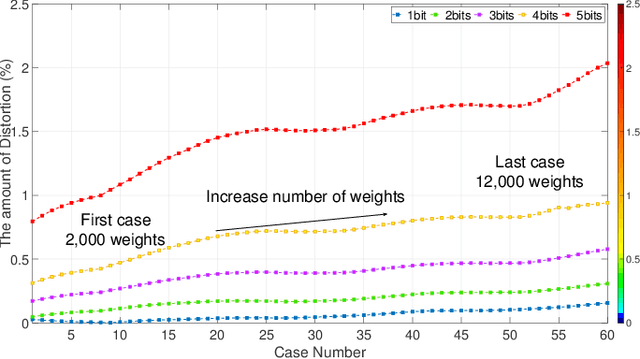

Convolutional Neural Networks (CNNs) deployed in real-life applications such as autonomous vehicles have shown to be vulnerable to manipulation attacks, such as poisoning attacks and fine-tuning. Hence, it is essential to ensure the integrity and authenticity of CNNs because compromised models can produce incorrect outputs and behave maliciously. In this paper, we propose a self-contained tamper-proofing method, called DeepiSign, to ensure the integrity and authenticity of CNN models against such manipulation attacks. DeepiSign applies the idea of fragile invisible watermarking to securely embed a secret and its hash value into a CNN model. To verify the integrity and authenticity of the model, we retrieve the secret from the model, compute the hash value of the secret, and compare it with the embedded hash value. To minimize the effects of the embedded secret on the CNN model, we use a wavelet-based technique to transform weights into the frequency domain and embed the secret into less significant coefficients. Our theoretical analysis shows that DeepiSign can hide up to 1KB secret in each layer with minimal loss of the model's accuracy. To evaluate the security and performance of DeepiSign, we performed experiments on four pre-trained models (ResNet18, VGG16, AlexNet, and MobileNet) using three datasets (MNIST, CIFAR-10, and Imagenet) against three types of manipulation attacks (targeted input poisoning, output poisoning, and fine-tuning). The results demonstrate that DeepiSign is verifiable without degrading the classification accuracy, and robust against representative CNN manipulation attacks.
HaS-Nets: A Heal and Select Mechanism to Defend DNNs Against Backdoor Attacks for Data Collection Scenarios
Dec 14, 2020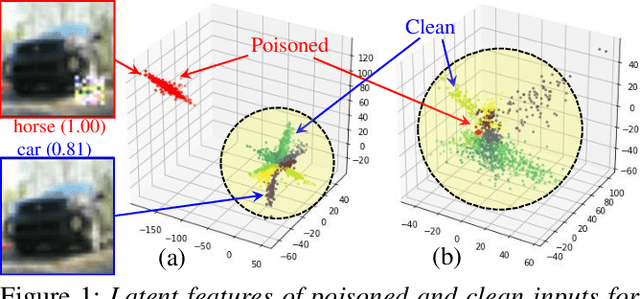
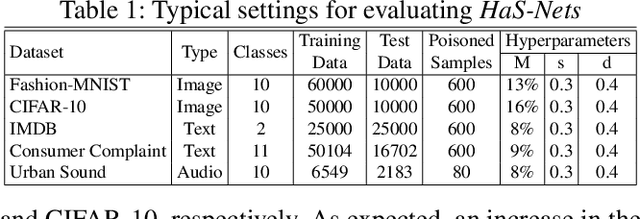

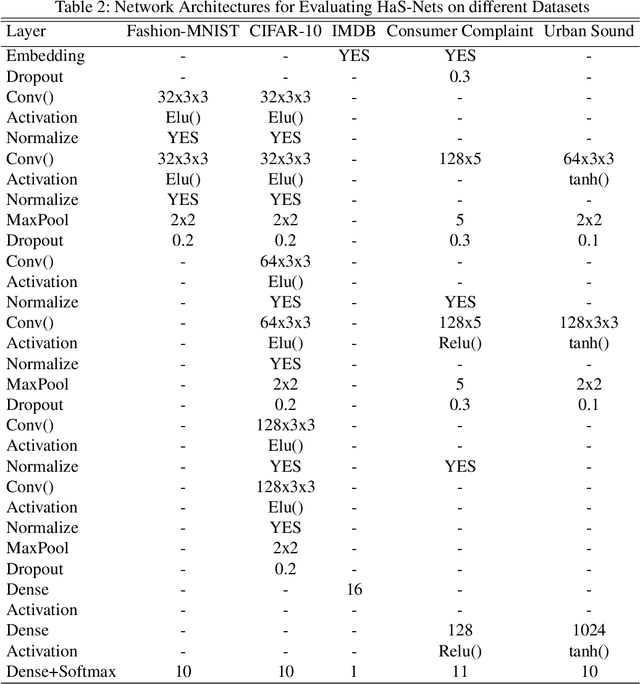
We have witnessed the continuing arms race between backdoor attacks and the corresponding defense strategies on Deep Neural Networks (DNNs). Most state-of-the-art defenses rely on the statistical sanitization of the "inputs" or "latent DNN representations" to capture trojan behaviour. In this paper, we first challenge the robustness of such recently reported defenses by introducing a novel variant of targeted backdoor attack, called "low-confidence backdoor attack". We also propose a novel defense technique, called "HaS-Nets". "Low-confidence backdoor attack" exploits the confidence labels assigned to poisoned training samples by giving low values to hide their presence from the defender, both during training and inference. We evaluate the attack against four state-of-the-art defense methods, viz., STRIP, Gradient-Shaping, Februus and ULP-defense, and achieve Attack Success Rate (ASR) of 99%, 63.73%, 91.2% and 80%, respectively. We next present "HaS-Nets" to resist backdoor insertion in the network during training, using a reasonably small healing dataset, approximately 2% to 15% of full training data, to heal the network at each iteration. We evaluate it for different datasets - Fashion-MNIST, CIFAR-10, Consumer Complaint and Urban Sound - and network architectures - MLPs, 2D-CNNs, 1D-CNNs. Our experiments show that "HaS-Nets" can decrease ASRs from over 90% to less than 15%, independent of the dataset, attack configuration and network architecture.
Decamouflage: A Framework to Detect Image-Scaling Attacks on Convolutional Neural Networks
Oct 08, 2020

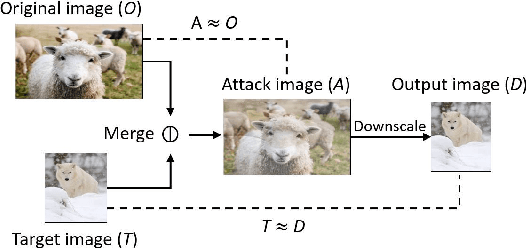

As an essential processing step in computer vision applications, image resizing or scaling, more specifically downsampling, has to be applied before feeding a normally large image into a convolutional neural network (CNN) model because CNN models typically take small fixed-size images as inputs. However, image scaling functions could be adversarially abused to perform a newly revealed attack called image-scaling attack, which can affect a wide range of computer vision applications building upon image-scaling functions. This work presents an image-scaling attack detection framework, termed as Decamouflage. Decamouflage consists of three independent detection methods: (1) rescaling, (2) filtering/pooling, and (3) steganalysis. While each of these three methods is efficient standalone, they can work in an ensemble manner not only to improve the detection accuracy but also to harden potential adaptive attacks. Decamouflage has a pre-determined detection threshold that is generic. More precisely, as we have validated, the threshold determined from one dataset is also applicable to other different datasets. Extensive experiments show that Decamouflage achieves detection accuracy of 99.9\% and 99.8\% in the white-box (with the knowledge of attack algorithms) and the black-box (without the knowledge of attack algorithms) settings, respectively. To corroborate the efficiency of Decamouflage, we have also measured its run-time overhead on a personal PC with an i5 CPU and found that Decamouflage can detect image-scaling attacks in milliseconds. Overall, Decamouflage can accurately detect image scaling attacks in both white-box and black-box settings with acceptable run-time overhead.