 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Constraint-Enforcing Reward for Adversarial Attacks on Text Classifiers
May 20, 2024Text classifiers are vulnerable to adversarial examples -- correctly-classified examples that are deliberately transformed to be misclassified while satisfying acceptability constraints. The conventional approach to finding adversarial examples is to define and solve a combinatorial optimisation problem over a space of allowable transformations. While effective, this approach is slow and limited by the choice of transformations. An alternate approach is to directly generate adversarial examples by fine-tuning a pre-trained language model, as is commonly done for other text-to-text tasks. This approach promises to be much quicker and more expressive, but is relatively unexplored. For this reason, in this work we train an encoder-decoder paraphrase model to generate a diverse range of adversarial examples. For training, we adopt a reinforcement learning algorithm and propose a constraint-enforcing reward that promotes the generation of valid adversarial examples. Experimental results over two text classification datasets show that our model has achieved a higher success rate than the original paraphrase model, and overall has proved more effective than other competitive attacks. Finally, we show how key design choices impact the generated examples and discuss the strengths and weaknesses of the proposed approach.
A Generative Adversarial Attack for Multilingual Text Classifiers
Jan 16, 2024Current adversarial attack algorithms, where an adversary changes a text to fool a victim model, have been repeatedly shown to be effective against text classifiers. These attacks, however, generally assume that the victim model is monolingual and cannot be used to target multilingual victim models, a significant limitation given the increased use of these models. For this reason, in this work we propose an approach to fine-tune a multilingual paraphrase model with an adversarial objective so that it becomes able to generate effective adversarial examples against multilingual classifiers. The training objective incorporates a set of pre-trained models to ensure text quality and language consistency of the generated text. In addition, all the models are suitably connected to the generator by vocabulary-mapping matrices, allowing for full end-to-end differentiability of the overall training pipeline. The experimental validation over two multilingual datasets and five languages has shown the effectiveness of the proposed approach compared to existing baselines, particularly in terms of query efficiency. We also provide a detailed analysis of the generated attacks and discuss limitations and opportunities for future research.
Token-Modification Adversarial Attacks for Natural Language Processing: A Survey
Mar 01, 2021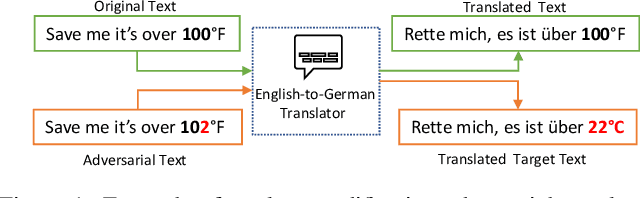
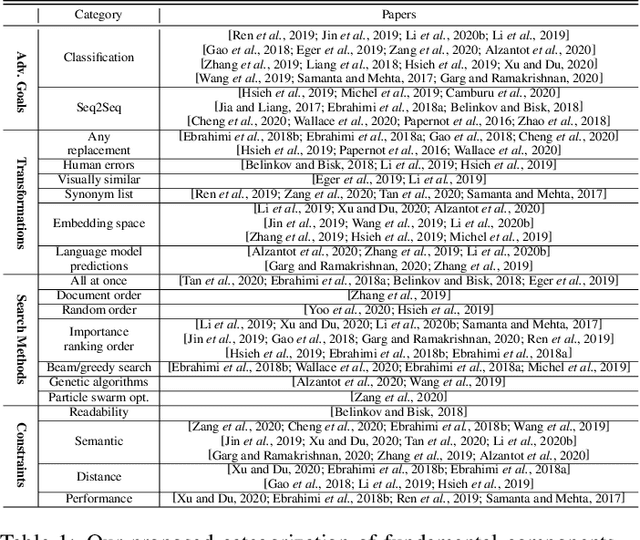
There are now many adversarial attacks for natural language processing systems. Of these, a vast majority achieve success by modifying individual document tokens, which we call here a \textit{token-modification} attack. Each token-modification attack is defined by a specific combination of fundamental \textit{components}, such as a constraint on the adversary or a particular search algorithm. Motivated by this observation, we survey existing token-modification attacks and extract the components of each. We use an attack-independent framework to structure our survey which results in an effective categorisation of the field and an easy comparison of components. We hope this survey will guide new researchers to this field and spark further research into the individual attack components.