 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization to translation shifts: a study in architectures and augmentations
Jul 05, 2022
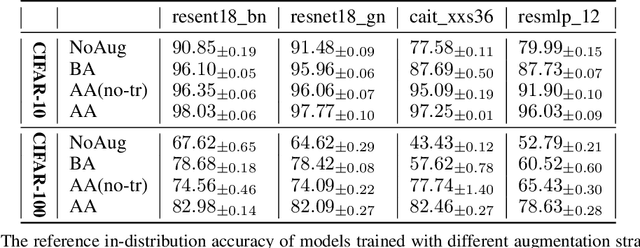
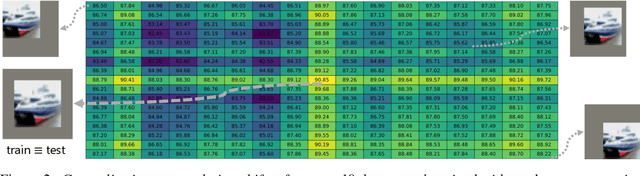

We provide a detailed evaluation of various image classification architectures (convolutional, vision transformer, and fully connected MLP networks) and data augmentation techniques towards generalization to large spacial translation shifts. We make the following observations: (a) In the absence of data augmentation, all architectures, including convolutional networks suffer degradation in performance when evaluated on translated test distributions. Understandably, both the in-distribution accuracy as well as degradation to shifts is significantly worse for non-convolutional architectures. (b) Across all architectures, even a minimal augmentation of $4$ pixel random crop improves the robustness of performance to much larger magnitude shifts of up to $1/4$ of image size ($8$-$16$ pixels) in the test data -- suggesting a form of meta generalization from augmentation. For non-convolutional architectures, while the absolute accuracy is still low, we see dramatic improvements in robustness to large translation shifts. (c) With sufficiently advanced augmentation ($4$ pixel crop+RandAugmentation+Erasing+MixUp) pipeline all architectures can be trained to have competitive performance, both in terms of in-distribution accuracy as well as generalization to large translation shifts.
Unveiling Transformers with LEGO: a synthetic reasoning task
Jun 09, 2022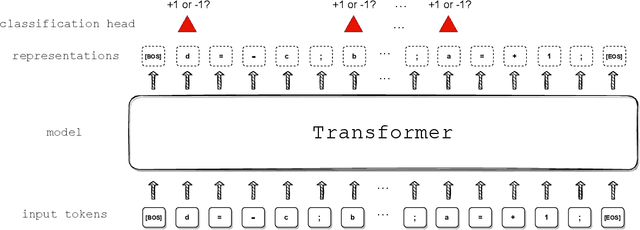
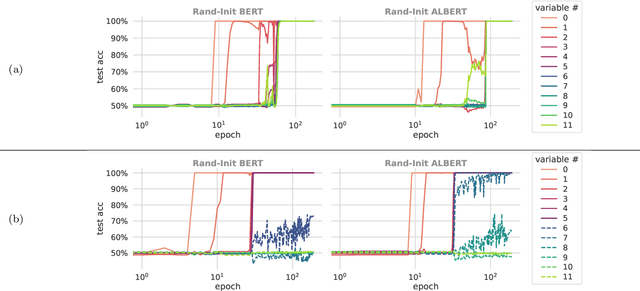
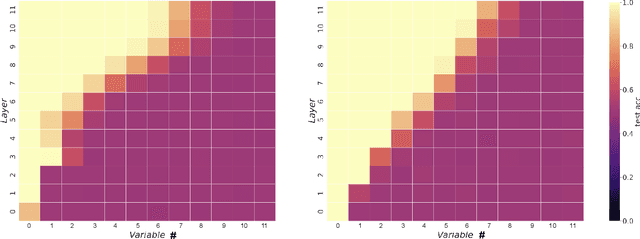
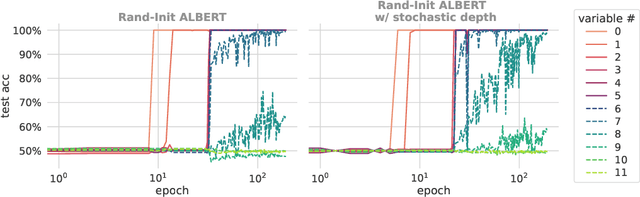
We propose a synthetic task, LEGO (Learning Equality and Group Operations), that encapsulates the problem of following a chain of reasoning, and we study how the transformer architecture learns this task. We pay special attention to data effects such as pretraining (on seemingly unrelated NLP tasks) and dataset composition (e.g., differing chain length at training and test time), as well as architectural variants such as weight-tied layers or adding convolutional components. We study how the trained models eventually succeed at the task, and in particular, we are able to understand (to some extent) some of the attention heads as well as how the information flows in the network. Based on these observations we propose a hypothesis that here pretraining helps merely due to being a smart initialization rather than some deep knowledge stored in the network. We also observe that in some data regime the trained transformer finds "shortcut" solutions to follow the chain of reasoning, which impedes the model's ability to generalize to simple variants of the main task, and moreover we find that one can prevent such shortcut with appropriate architecture modification or careful data preparation. Motivated by our findings, we begin to explore the task of learning to execute C programs, where a convolutional modification to transformers, namely adding convolutional structures in the key/query/value maps, shows an encouraging edge.
Data Augmentation as Feature Manipulation: a story of desert cows and grass cows
Mar 03, 2022
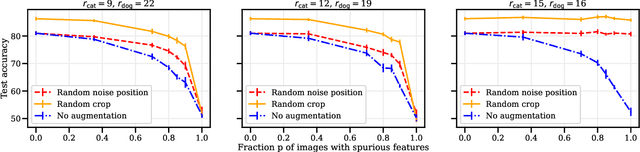
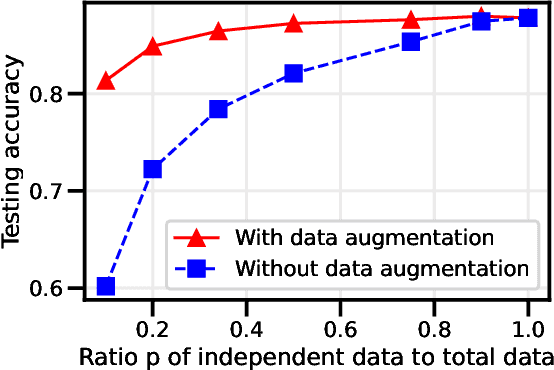
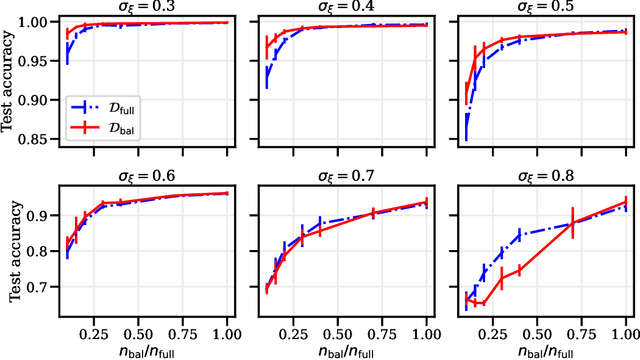
Data augmentation is a cornerstone of the machine learning pipeline, yet its theoretical underpinnings remain unclear. Is it merely a way to artificially augment the data set size? Or is it about encouraging the model to satisfy certain invariance? In this work we consider another angle, and we study the effect of data augmentation on the dynamic of the learning process. We find that data augmentation can alter the relative importance of various features, effectively making certain informative but hard to learn features more likely to be captured in the learning process. Importantly, we show that this effect is more pronounced for non-linear models, such as neural networks. Our main contribution is a detailed analysis of data augmentation on the learning dynamic for a two layer convolutional neural network in the recently proposed multi-view model by Allen-Zhu and Li [2020]. We complement this analysis with further experimental evidence that data augmentation can be viewed as a form of feature manipulation.
Inductive Bias of Multi-Channel Linear Convolutional Networks with Bounded Weight Norm
Feb 24, 2021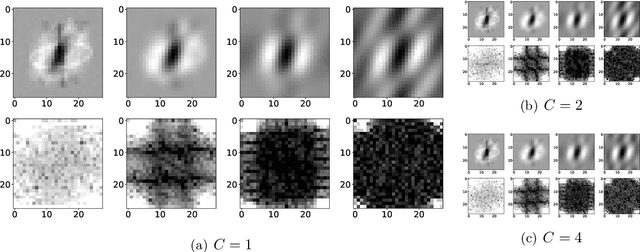
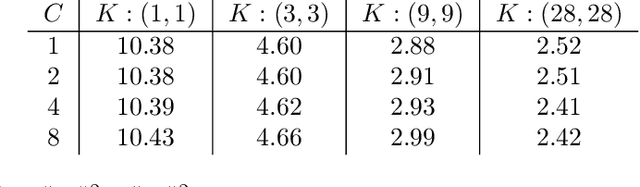

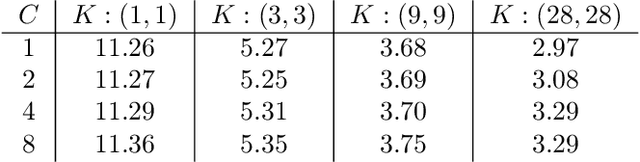
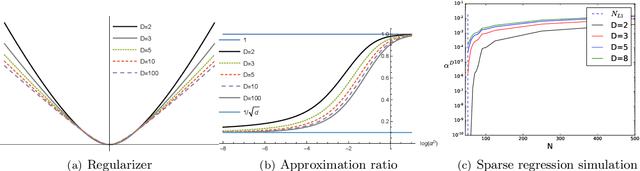
We study the function space characterization of the inductive bias resulting from controlling the $\ell_2$ norm of the weights in linear convolutional networks. We view this in terms of an induced regularizer in the function space given by the minimum norm of weights required to realize a linear function. For two layer linear convolutional networks with $C$ output channels and kernel size $K$, we show the following: (a) If the inputs to the network have a single channel, the induced regularizer for any $K$ is a norm given by a semidefinite program (SDP) that is independent of the number of output channels $C$. We further validate these results through a binary classification task on MNIST. (b) In contrast, for networks with multi-channel inputs, multiple output channels can be necessary to merely realize all matrix-valued linear functions and thus the inductive bias does depend on $C$. Further, for sufficiently large $C$, the induced regularizer for $K=1$ and $K=D$ are the nuclear norm and the $\ell_{2,1}$ group-sparse norm, respectively, of the Fourier coefficients -- both of which promote sparse structures.
NeurIPS 2020 Competition: Predicting Generalization in Deep Learning
Dec 14, 2020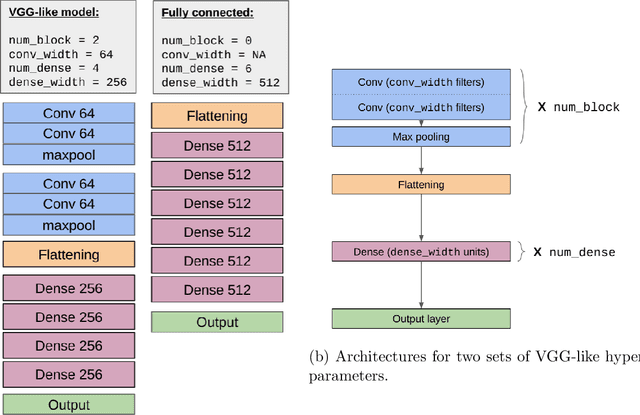
Understanding generalization in deep learning is arguably one of the most important questions in deep learning. Deep learning has been successfully adopted to a large number of problems ranging from pattern recognition to complex decision making, but many recent researchers have raised many concerns about deep learning, among which the most important is generalization. Despite numerous attempts, conventional statistical learning approaches have yet been able to provide a satisfactory explanation on why deep learning works. A recent line of works aims to address the problem by trying to predict the generalization performance through complexity measures. In this competition, we invite the community to propose complexity measures that can accurately predict generalization of models. A robust and general complexity measure would potentially lead to a better understanding of deep learning's underlying mechanism and behavior of deep models on unseen data, or shed light on better generalization bounds. All these outcomes will be important for making deep learning more robust and reliable.
Implicit Bias in Deep Linear Classification: Initialization Scale vs Training Accuracy
Jul 13, 2020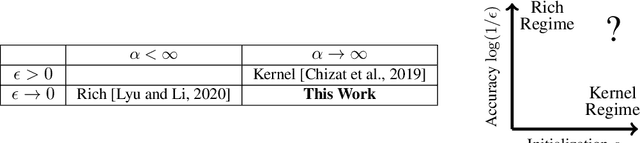
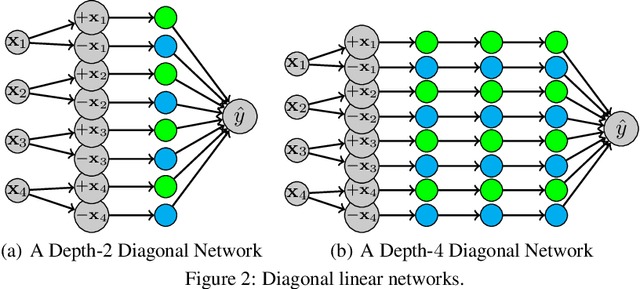
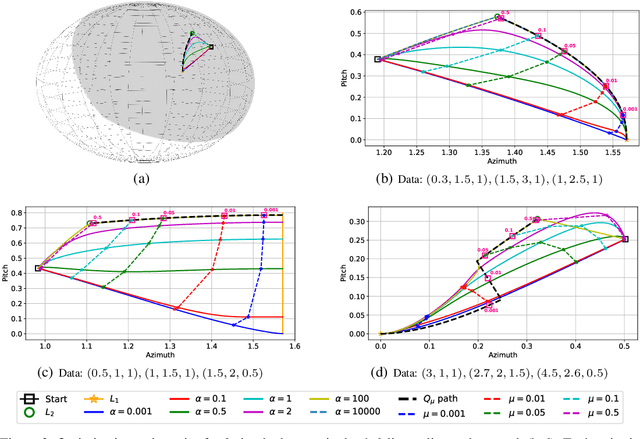
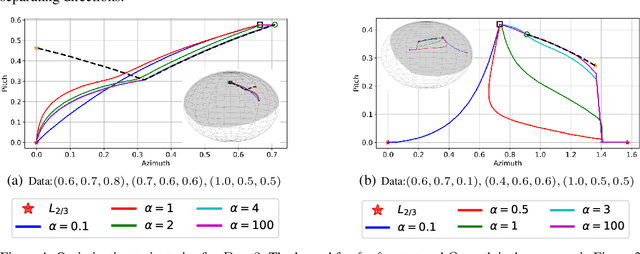
We provide a detailed asymptotic study of gradient flow trajectories and their implicit optimization bias when minimizing the exponential loss over "diagonal linear networks". This is the simplest model displaying a transition between "kernel" and non-kernel ("rich" or "active") regimes. We show how the transition is controlled by the relationship between the initialization scale and how accurately we minimize the training loss. Our results indicate that some limit behaviors of gradient descent only kick in at ridiculous training accuracies (well beyond $10^{-100}$). Moreover, the implicit bias at reasonable initialization scales and training accuracies is more complex and not captured by these limits.
Mirrorless Mirror Descent: A More Natural Discretization of Riemannian Gradient Flow
Apr 24, 2020We present a direct (primal only) derivation of Mirror Descent as a "partial" discretization of gradient flow on a Riemannian manifold where the metric tensor is the Hessian of the Mirror Descent potential function. We argue that this discretization is more faithful to the geometry than Natural Gradient Descent, which is obtained by a "full" forward Euler discretization. This view helps shed light on the relationship between the methods and allows generalizing Mirror Descent to any Riemannian geometry, even when the metric tensor is not a Hessian, and thus there is no "dual."
Kernel and Rich Regimes in Overparametrized Models
Feb 24, 2020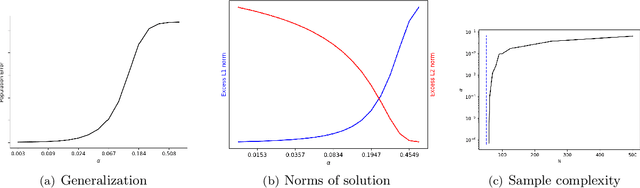
A recent line of work studies overparametrized neural networks in the "kernel regime," i.e. when the network behaves during training as a kernelized linear predictor, and thus training with gradient descent has the effect of finding the minimum RKHS norm solution. This stands in contrast to other studies which demonstrate how gradient descent on overparametrized multilayer networks can induce rich implicit biases that are not RKHS norms. Building on an observation by Chizat and Bach, we show how the scale of the initialization controls the transition between the "kernel" (aka lazy) and "rich" (aka active) regimes and affects generalization properties in multilayer homogeneous models. We also highlight an interesting role for the width of a model in the case that the predictor is not identically zero at initialization. We provide a complete and detailed analysis for a family of simple depth-$D$ models that already exhibit an interesting and meaningful transition between the kernel and rich regimes, and we also demonstrate this transition empirically for more complex matrix factorization models and multilayer non-linear networks.
Implicit Regularization of Normalization Methods
Nov 23, 2019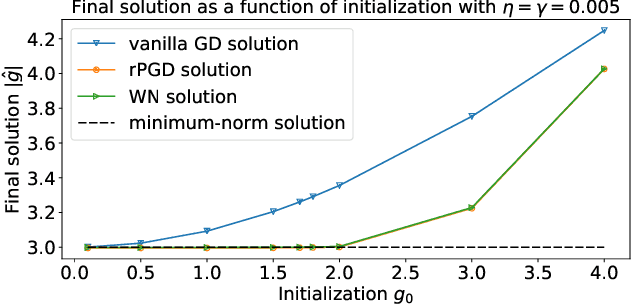
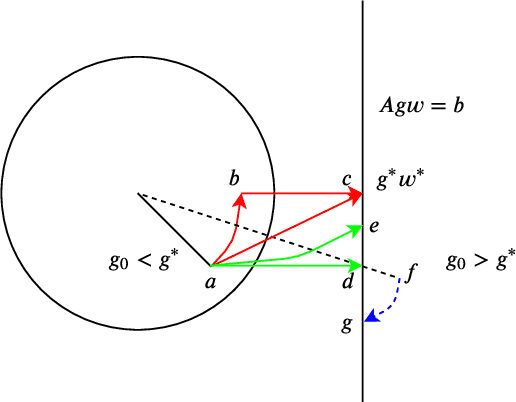
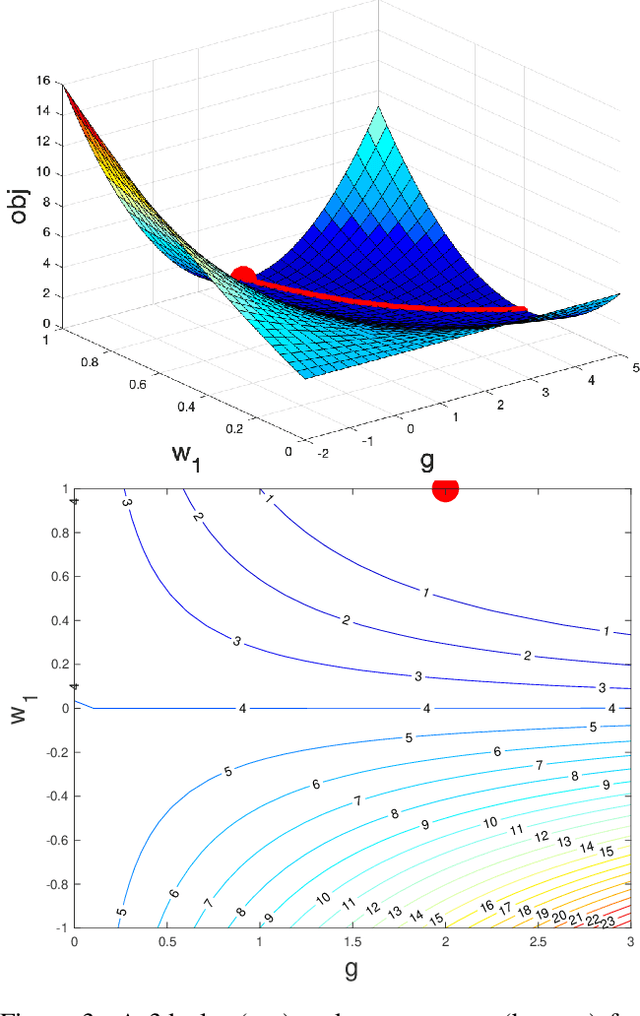
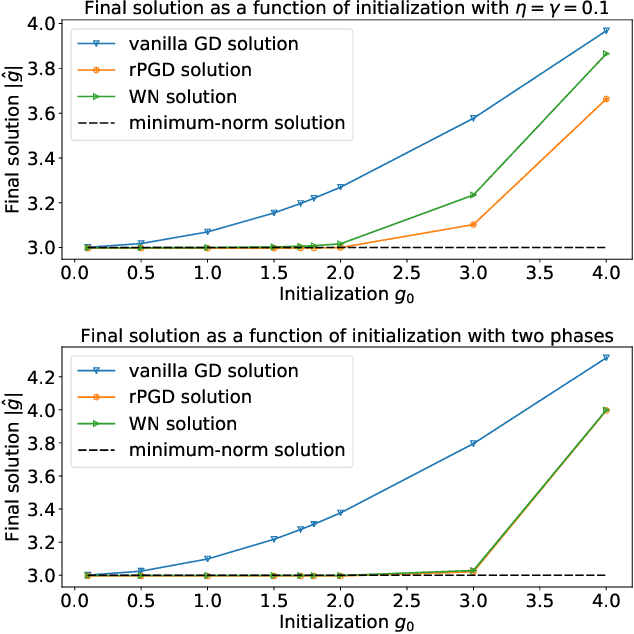
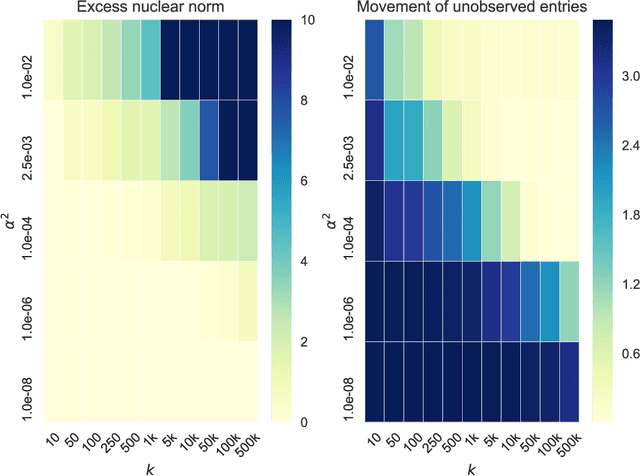
Normalization methods such as batch normalization are commonly used in overparametrized models like neural networks. Here, we study the weight normalization (WN) method (Salimans & Kingma, 2016) and a variant called reparametrized projected gradient descent (rPGD) for overparametrized least squares regression and some more general loss functions. WN and rPGD reparametrize the weights with a scale $g$ and a unit vector such that the objective function becomes \emph{non-convex}. We show that this non-convex formulation has beneficial regularization effects compared to gradient descent on the original objective. We show that these methods adaptively regularize the weights and \emph{converge with exponential rate} to the minimum $\ell_2$ norm solution (or close to it) even for initializations \emph{far from zero}. This is different from the behavior of gradient descent, which only converges to the min norm solution when started at zero, and is more sensitive to initialization. Some of our proof techniques are different from many related works; for instance we find explicit invariants along the gradient flow paths. We verify our results experimentally and suggest that there may be a similar phenomenon for nonlinear problems such as matrix sensing.
Kernel and Deep Regimes in Overparametrized Models
Jun 13, 2019
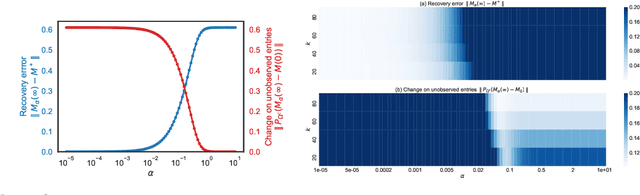
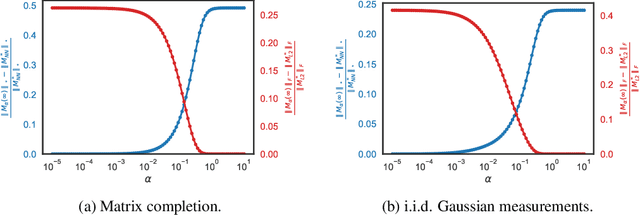
A recent line of work studies overparametrized neural networks in the ``kernel regime,'' i.e.~when the network behaves during training as a kernelized linear predictor, and thus training with gradient descent has the effect of finding the minimum RKHS norm solution. This stands in contrast to other studies which demonstrate how gradient descent on overparametrized multilayer networks can induce rich implicit biases that are not RKHS norms. Building on an observation by Chizat and Bach, we show how the scale of the initialization controls the transition between the ``kernel'' (aka lazy) and ``deep'' (aka active) regimes and affects generalization properties in multilayer homogeneous models. We provide a complete and detailed analysis for a simple two-layer model that already exhibits an interesting and meaningful transition between the kernel and deep regimes, and we demonstrate the transition for more complex matrix factorization models.