 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaMix: Meta-state Precision Searcher for Mixed-precision Activation Quantization
Nov 12, 2023



Mixed-precision quantization of efficient networks often suffer from activation instability encountered in the exploration of bit selections. To address this problem, we propose a novel method called MetaMix which consists of bit selection and weight training phases. The bit selection phase iterates two steps, (1) the mixed-precision-aware weight update, and (2) the bit-search training with the fixed mixed-precision-aware weights, both of which combined reduce activation instability in mixed-precision quantization and contribute to fast and high-quality bit selection. The weight training phase exploits the weights and step sizes trained in the bit selection phase and fine-tunes them thereby offering fast training. Our experiments with efficient and hard-to-quantize networks, i.e., MobileNet v2 and v3, and ResNet-18 on ImageNet show that our proposed method pushes the boundary of mixed-precision quantization, in terms of accuracy vs. operations, by outperforming both mixed- and single-precision SOTA methods.
MFOS: Model-Free & One-Shot Object Pose Estimation
Oct 03, 2023



Existing learning-based methods for object pose estimation in RGB images are mostly model-specific or category based. They lack the capability to generalize to new object categories at test time, hence severely hindering their practicability and scalability. Notably, recent attempts have been made to solve this issue, but they still require accurate 3D data of the object surface at both train and test time. In this paper, we introduce a novel approach that can estimate in a single forward pass the pose of objects never seen during training, given minimum input. In contrast to existing state-of-the-art approaches, which rely on task-specific modules, our proposed model is entirely based on a transformer architecture, which can benefit from recently proposed 3D-geometry general pretraining. We conduct extensive experiments and report state-of-the-art one-shot performance on the challenging LINEMOD benchmark. Finally, extensive ablations allow us to determine good practices with this relatively new type of architecture in the field.
AnyFlow: Arbitrary Scale Optical Flow with Implicit Neural Representation
Mar 29, 2023



To apply optical flow in practice, it is often necessary to resize the input to smaller dimensions in order to reduce computational costs. However, downsizing inputs makes the estimation more challenging because objects and motion ranges become smaller. Even though recent approaches have demonstrated high-quality flow estimation, they tend to fail to accurately model small objects and precise boundaries when the input resolution is lowered, restricting their applicability to high-resolution inputs. In this paper, we introduce AnyFlow, a robust network that estimates accurate flow from images of various resolutions. By representing optical flow as a continuous coordinate-based representation, AnyFlow generates outputs at arbitrary scales from low-resolution inputs, demonstrating superior performance over prior works in capturing tiny objects with detail preservation on a wide range of scenes. We establish a new state-of-the-art performance of cross-dataset generalization on the KITTI dataset, while achieving comparable accuracy on the online benchmarks to other SOTA methods.
Memory Efficient Patch-based Training for INR-based GANs
Jul 09, 2022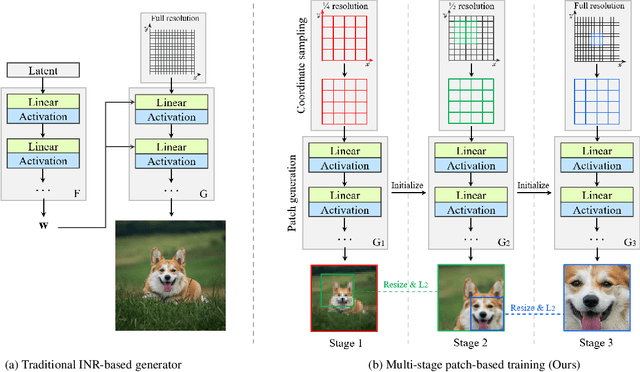
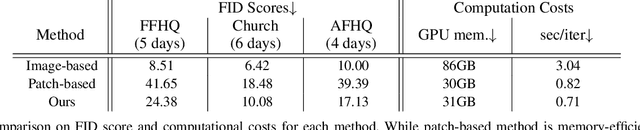


Recent studies have shown remarkable progress in GANs based on implicit neural representation (INR) - an MLP that produces an RGB value given its (x, y) coordinate. They represent an image as a continuous version of the underlying 2D signal instead of a 2D array of pixels, which opens new horizons for GAN applications (e.g., zero-shot super-resolution, image outpainting). However, training existing approaches require a heavy computational cost proportional to the image resolution, since they compute an MLP operation for every (x, y) coordinate. To alleviate this issue, we propose a multi-stage patch-based training, a novel and scalable approach that can train INR-based GANs with a flexible computational cost regardless of the image resolution. Specifically, our method allows to generate and discriminate by patch to learn the local details of the image and learn global structural information by a novel reconstruction loss to enable efficient GAN training. We conduct experiments on several benchmark datasets to demonstrate that our approach enhances baseline models in GPU memory while maintaining FIDs at a reasonable level.
On the Overlooked Significance of Underutilized Contextual Features in Recent News Recommendation Models
Dec 29, 2021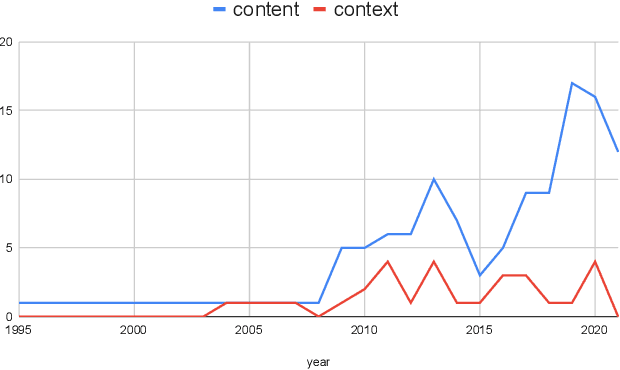
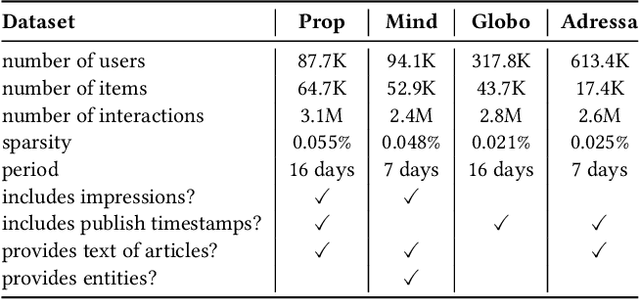
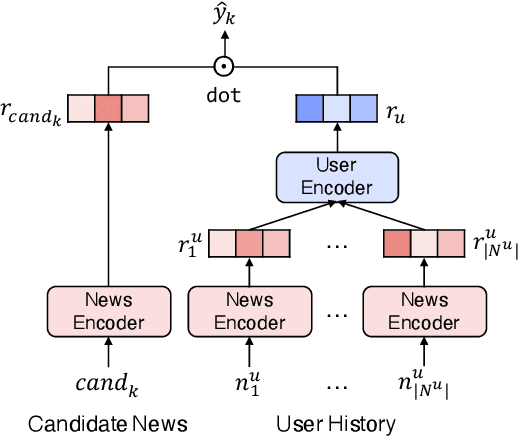
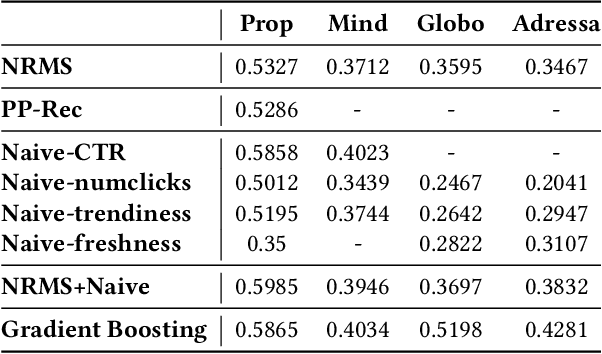
Personalized news recommendation aims to provide attractive articles for readers by predicting their likelihood of clicking on a certain article. To accurately predict this probability, plenty of studies have been proposed that actively utilize content features of articles, such as words, categories, or entities. However, we observed that the articles' contextual features, such as CTR (click-through-rate), popularity, or freshness, were either neglected or underutilized recently. To prove that this is the case, we conducted an extensive comparison between recent deep-learning models and naive contextual models that we devised and surprisingly discovered that the latter easily outperforms the former. Furthermore, our analysis showed that the recent tendency to apply overly sophisticated deep-learning operations to contextual features was actually hindering the recommendation performance. From this knowledge, we design a purposefully simple contextual module that can boost the previous news recommendation models by a large margin.
Fine-grained Semantics-aware Representation Enhancement for Self-supervised Monocular Depth Estimation
Aug 19, 2021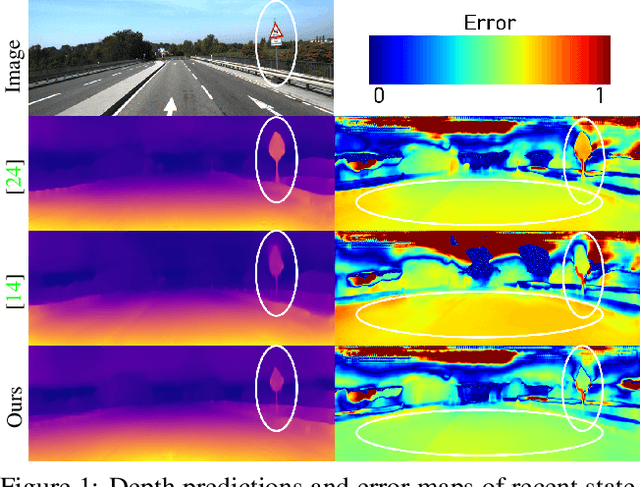
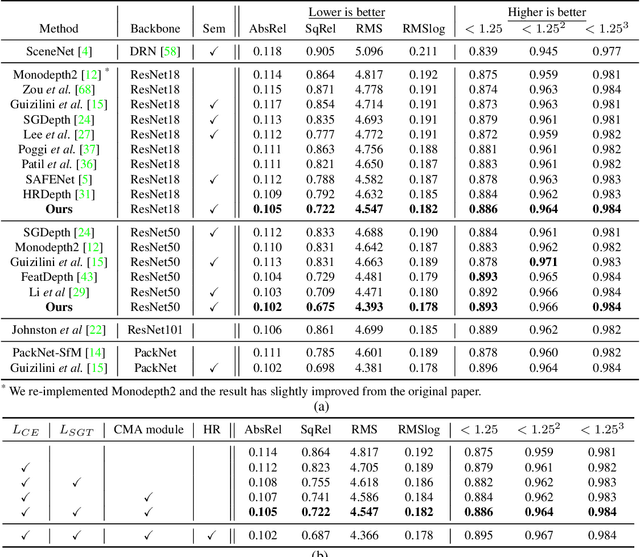
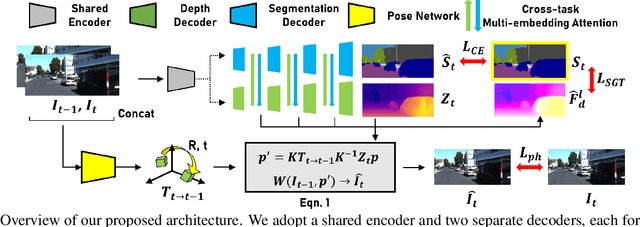
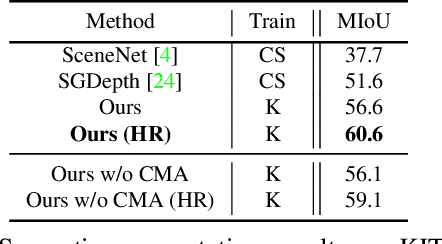
Self-supervised monocular depth estimation has been widely studied, owing to its practical importance and recent promising improvements. However, most works suffer from limited supervision of photometric consistency, especially in weak texture regions and at object boundaries. To overcome this weakness, we propose novel ideas to improve self-supervised monocular depth estimation by leveraging cross-domain information, especially scene semantics. We focus on incorporating implicit semantic knowledge into geometric representation enhancement and suggest two ideas: a metric learning approach that exploits the semantics-guided local geometry to optimize intermediate depth representations and a novel feature fusion module that judiciously utilizes cross-modality between two heterogeneous feature representations. We comprehensively evaluate our methods on the KITTI dataset and demonstrate that our method outperforms state-of-the-art methods. The source code is available at https://github.com/hyBlue/FSRE-Depth.
StyleMapGAN: Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing
Apr 30, 2021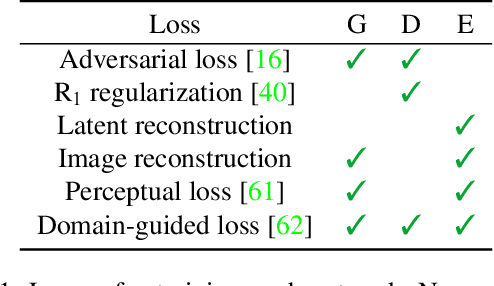
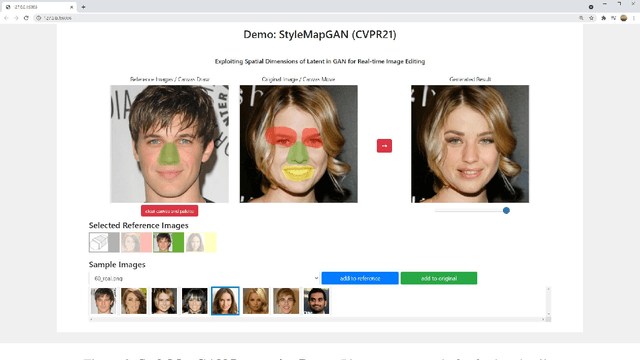
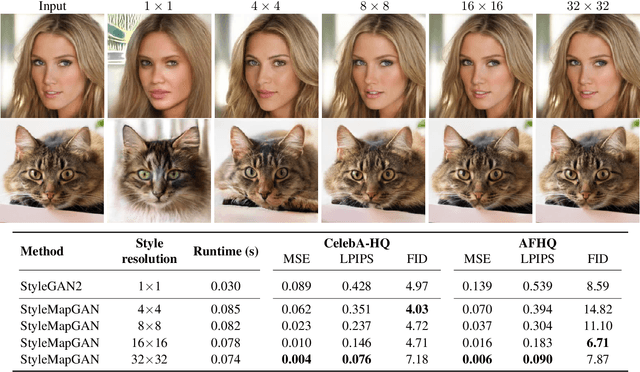
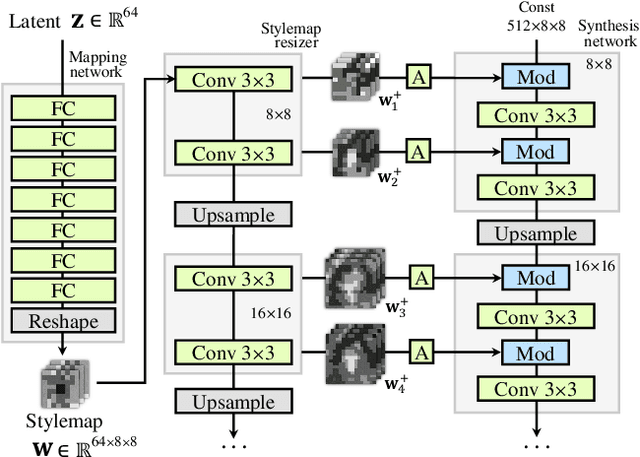
Generative adversarial networks (GANs) synthesize realistic images from random latent vectors. Although manipulating the latent vectors controls the synthesized outputs, editing real images with GANs suffers from i) time-consuming optimization for projecting real images to the latent vectors, ii) or inaccurate embedding through an encoder. We propose StyleMapGAN: the intermediate latent space has spatial dimensions, and a spatially variant modulation replaces AdaIN. It makes the embedding through an encoder more accurate than existing optimization-based methods while maintaining the properties of GANs. Experimental results demonstrate that our method significantly outperforms state-of-the-art models in various image manipulation tasks such as local editing and image interpolation. Last but not least, conventional editing methods on GANs are still valid on our StyleMapGAN. Source code is available at https://github.com/naver-ai/StyleMapGAN.
MEANTIME: Mixture of Attention Mechanisms with Multi-temporal Embeddings for Sequential Recommendation
Aug 21, 2020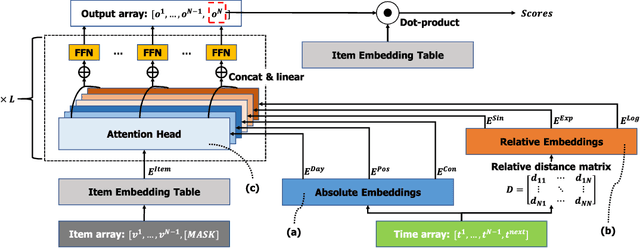
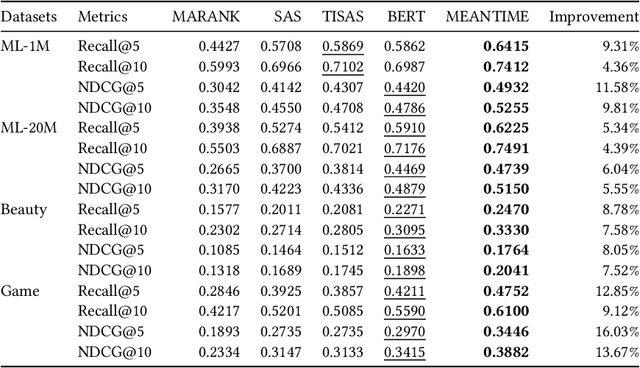
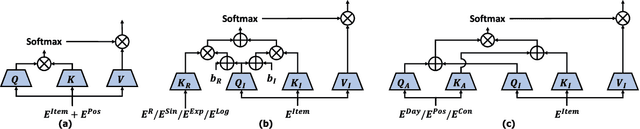

Recently, self-attention based models have achieved state-of-the-art performance in sequential recommendation task. Following the custom from language processing, most of these models rely on a simple positional embedding to exploit the sequential nature of the user's history. However, there are some limitations regarding the current approaches. First, sequential recommendation is different from language processing in that timestamp information is available. Previous models have not made good use of it to extract additional contextual information. Second, using a simple embedding scheme can lead to information bottleneck since the same embedding has to represent all possible contextual biases. Third, since previous models use the same positional embedding in each attention head, they can wastefully learn overlapping patterns. To address these limitations, we propose MEANTIME (MixturE of AtteNTIon mechanisms with Multi-temporal Embeddings) which employs multiple types of temporal embeddings designed to capture various patterns from the user's behavior sequence, and an attention structure that fully leverages such diversity. Experiments on real-world data show that our proposed method outperforms current state-of-the-art sequential recommendation methods, and we provide an extensive ablation study to analyze how the model gains from the diverse positional information.
PROFIT: A Novel Training Method for sub-4-bit MobileNet Models
Aug 11, 20204-bit and lower precision mobile models are required due to the ever-increasing demand for better energy efficiency in mobile devices. In this work, we report that the activation instability induced by weight quantization (AIWQ) is the key obstacle to sub-4-bit quantization of mobile networks. To alleviate the AIWQ problem, we propose a novel training method called PROgressive-Freezing Iterative Training (PROFIT), which attempts to freeze layers whose weights are affected by the instability problem stronger than the other layers. We also propose a differentiable and unified quantization method (DuQ) and a negative padding idea to support asymmetric activation functions such as h-swish. We evaluate the proposed methods by quantizing MobileNet-v1, v2, and v3 on ImageNet and report that 4-bit quantization offers comparable (within 1.48 % top-1 accuracy) accuracy to full precision baseline. In the ablation study of the 3-bit quantization of MobileNet-v3, our proposed method outperforms the state-of-the-art method by a large margin, 12.86 % of top-1 accuracy.
Tag2Pix: Line Art Colorization Using Text Tag With SECat and Changing Loss
Aug 16, 2019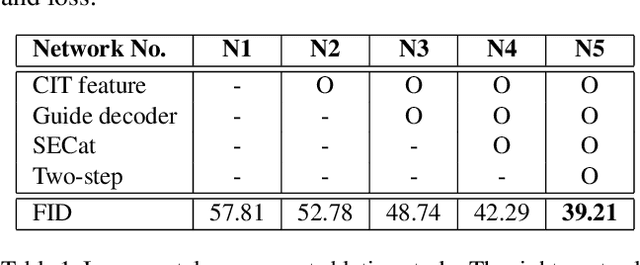

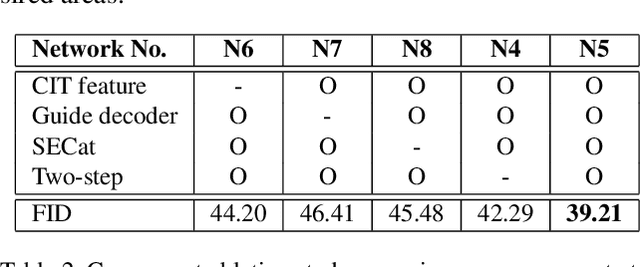

Line art colorization is expensive and challenging to automate. A GAN approach is proposed, called Tag2Pix, of line art colorization which takes as input a grayscale line art and color tag information and produces a quality colored image. First, we present the Tag2Pix line art colorization dataset. A generator network is proposed which consists of convolutional layers to transform the input line art, a pre-trained semantic extraction network, and an encoder for input color information. The discriminator is based on an auxiliary classifier GAN to classify the tag information as well as genuineness. In addition, we propose a novel network structure called SECat, which makes the generator properly colorize even small features such as eyes, and also suggest a novel two-step training method where the generator and discriminator first learn the notion of object and shape and then, based on the learned notion, learn colorization, such as where and how to place which color. We present both quantitative and qualitative evaluations which prove the effectiveness of the proposed method.