 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Biases for Improving Transformers on Translation into Morphologically Rich Languages
Aug 11, 2022
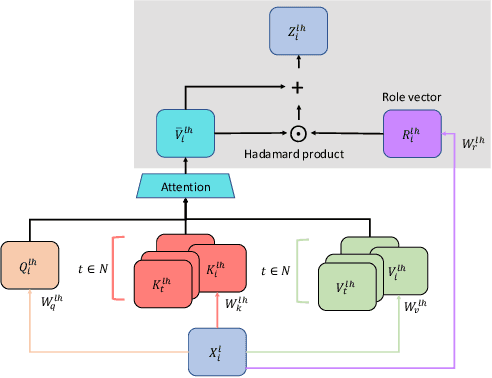

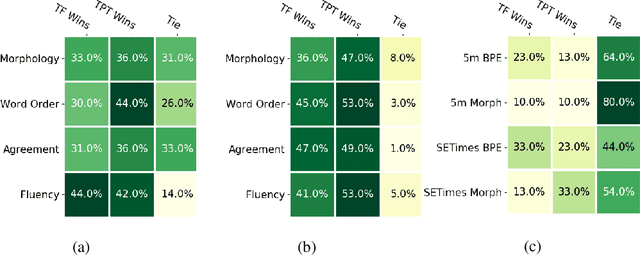
Machine translation has seen rapid progress with the advent of Transformer-based models. These models have no explicit linguistic structure built into them, yet they may still implicitly learn structured relationships by attending to relevant tokens. We hypothesize that this structural learning could be made more robust by explicitly endowing Transformers with a structural bias, and we investigate two methods for building in such a bias. One method, the TP-Transformer, augments the traditional Transformer architecture to include an additional component to represent structure. The second method imbues structure at the data level by segmenting the data with morphological tokenization. We test these methods on translating from English into morphologically rich languages, Turkish and Inuktitut, and consider both automatic metrics and human evaluations. We find that each of these two approaches allows the network to achieve better performance, but this improvement is dependent on the size of the dataset. In sum, structural encoding methods make Transformers more sample-efficient, enabling them to perform better from smaller amounts of data.
* Revised edition to 4th Workshop on Technologies for MT of Low Resource Languages
Enriching Transformers with Structured Tensor-Product Representations for Abstractive Summarization
Jun 02, 2021
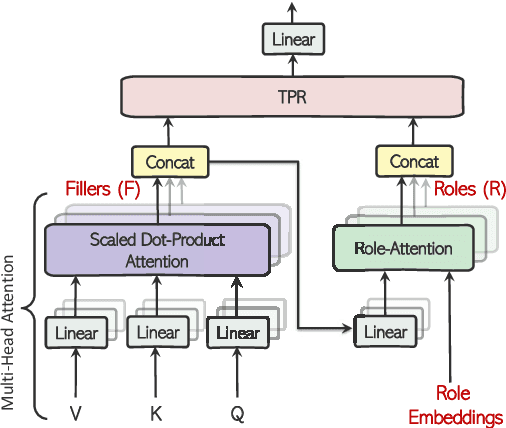
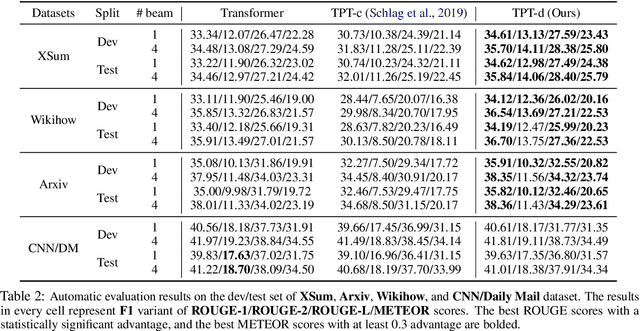
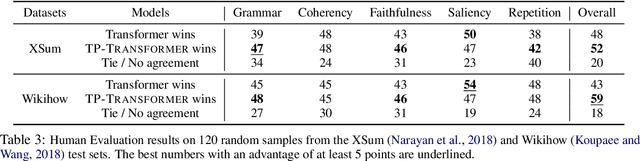
Abstractive summarization, the task of generating a concise summary of input documents, requires: (1) reasoning over the source document to determine the salient pieces of information scattered across the long document, and (2) composing a cohesive text by reconstructing these salient facts into a shorter summary that faithfully reflects the complex relations connecting these facts. In this paper, we adapt TP-TRANSFORMER (Schlag et al., 2019), an architecture that enriches the original Transformer (Vaswani et al., 2017) with the explicitly compositional Tensor Product Representation (TPR), for the task of abstractive summarization. The key feature of our model is a structural bias that we introduce by encoding two separate representations for each token to represent the syntactic structure (with role vectors) and semantic content (with filler vectors) separately. The model then binds the role and filler vectors into the TPR as the layer output. We argue that the structured intermediate representations enable the model to take better control of the contents (salient facts) and structures (the syntax that connects the facts) when generating the summary. Empirically, we show that our TP-TRANSFORMER outperforms the Transformer and the original TP-TRANSFORMER significantly on several abstractive summarization datasets based on both automatic and human evaluations. On several syntactic and semantic probing tasks, we demonstrate the emergent structural information in the role vectors and improved syntactic interpretability in the TPR layer outputs. Code and models are available at https://github.com/jiangycTarheel/TPT-Summ.
Ask what's missing and what's useful: Improving Clarification Question Generation using Global Knowledge
Apr 14, 2021
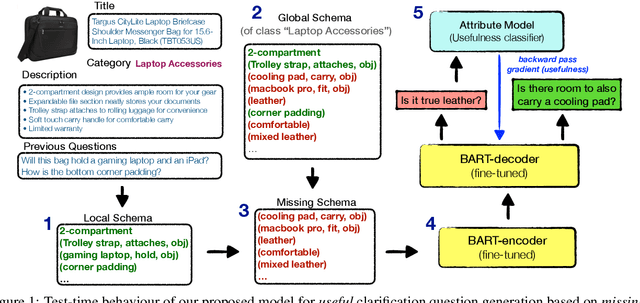
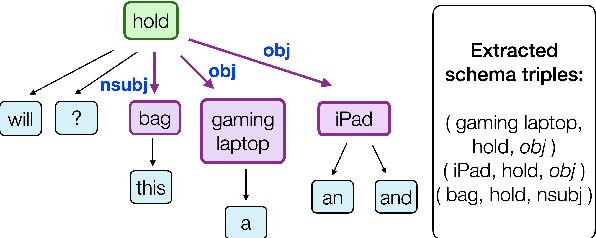
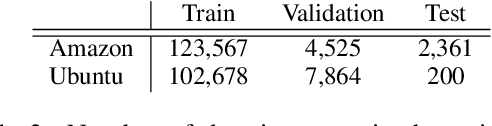
The ability to generate clarification questions i.e., questions that identify useful missing information in a given context, is important in reducing ambiguity. Humans use previous experience with similar contexts to form a global view and compare it to the given context to ascertain what is missing and what is useful in the context. Inspired by this, we propose a model for clarification question generation where we first identify what is missing by taking a difference between the global and the local view and then train a model to identify what is useful and generate a question about it. Our model outperforms several baselines as judged by both automatic metrics and humans.
Neuro-Symbolic Representations for Video Captioning: A Case for Leveraging Inductive Biases for Vision and Language
Nov 18, 2020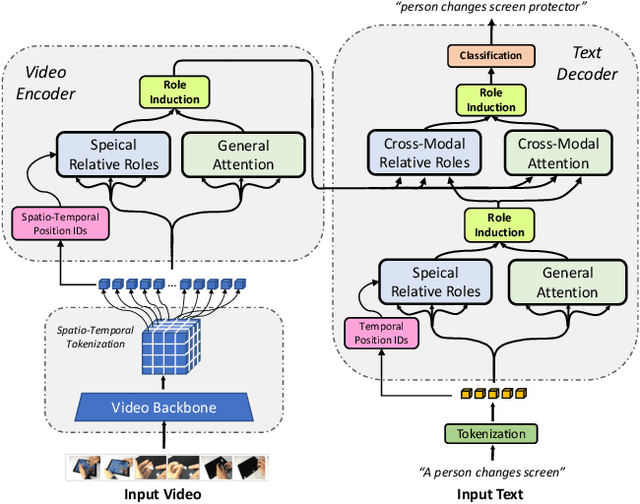
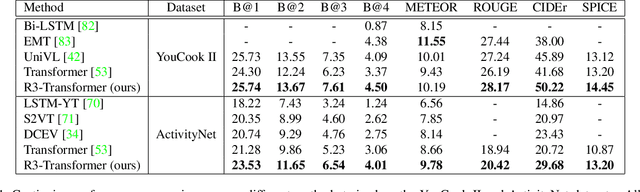
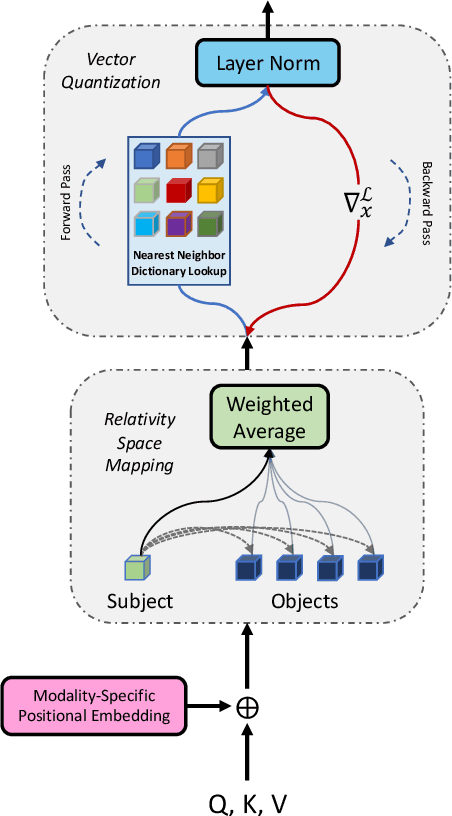
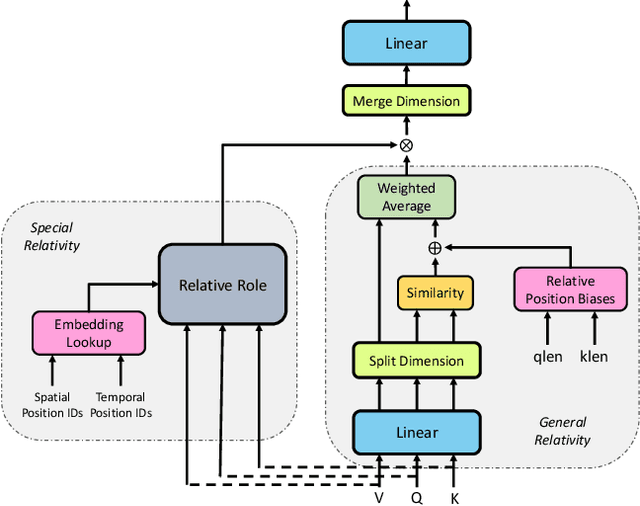
Neuro-symbolic representations have proved effective in learning structure information in vision and language. In this paper, we propose a new model architecture for learning multi-modal neuro-symbolic representations for video captioning. Our approach uses a dictionary learning-based method of learning relations between videos and their paired text descriptions. We refer to these relations as relative roles and leverage them to make each token role-aware using attention. This results in a more structured and interpretable architecture that incorporates modality-specific inductive biases for the captioning task. Intuitively, the model is able to learn spatial, temporal, and cross-modal relations in a given pair of video and text. The disentanglement achieved by our proposal gives the model more capacity to capture multi-modal structures which result in captions with higher quality for videos. Our experiments on two established video captioning datasets verifies the effectiveness of the proposed approach based on automatic metrics. We further conduct a human evaluation to measure the grounding and relevance of the generated captions and observe consistent improvement for the proposed model. The codes and trained models can be found at https://github.com/hassanhub/R3Transformer
Substance over Style: Document-Level Targeted Content Transfer
Oct 16, 2020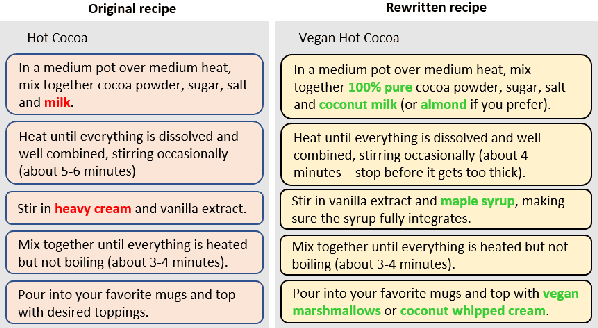
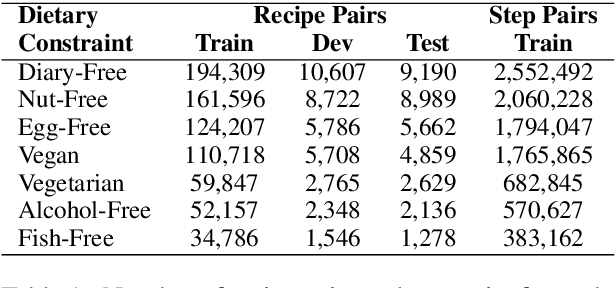
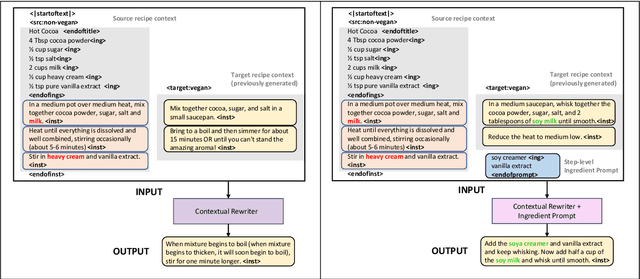

Existing language models excel at writing from scratch, but many real-world scenarios require rewriting an existing document to fit a set of constraints. Although sentence-level rewriting has been fairly well-studied, little work has addressed the challenge of rewriting an entire document coherently. In this work, we introduce the task of document-level targeted content transfer and address it in the recipe domain, with a recipe as the document and a dietary restriction (such as vegan or dairy-free) as the targeted constraint. We propose a novel model for this task based on the generative pre-trained language model (GPT-2) and train on a large number of roughly-aligned recipe pairs (https://github.com/microsoft/document-level-targeted-content-transfer). Both automatic and human evaluations show that our model out-performs existing methods by generating coherent and diverse rewrites that obey the constraint while remaining close to the original document. Finally, we analyze our model's rewrites to assess progress toward the goal of making language generation more attuned to constraints that are substantive rather than stylistic.
A Recipe for Creating Multimodal Aligned Datasets for Sequential Tasks
May 19, 2020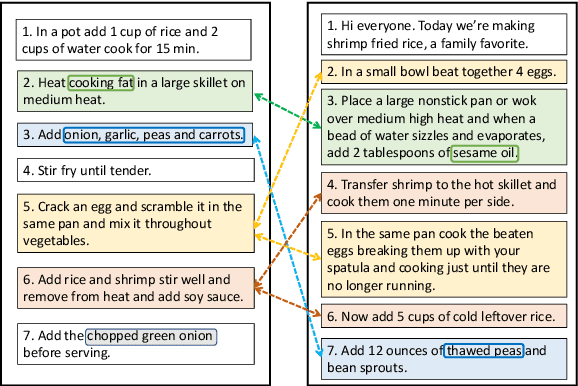
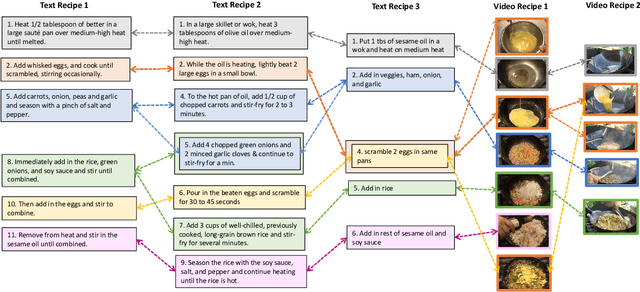
Many high-level procedural tasks can be decomposed into sequences of instructions that vary in their order and choice of tools. In the cooking domain, the web offers many partially-overlapping text and video recipes (i.e. procedures) that describe how to make the same dish (i.e. high-level task). Aligning instructions for the same dish across different sources can yield descriptive visual explanations that are far richer semantically than conventional textual instructions, providing commonsense insight into how real-world procedures are structured. Learning to align these different instruction sets is challenging because: a) different recipes vary in their order of instructions and use of ingredients; and b) video instructions can be noisy and tend to contain far more information than text instructions. To address these challenges, we first use an unsupervised alignment algorithm that learns pairwise alignments between instructions of different recipes for the same dish. We then use a graph algorithm to derive a joint alignment between multiple text and multiple video recipes for the same dish. We release the Microsoft Research Multimodal Aligned Recipe Corpus containing 150K pairwise alignments between recipes across 4,262 dishes with rich commonsense information.
* This paper has been accepted to be published at ACL 2020
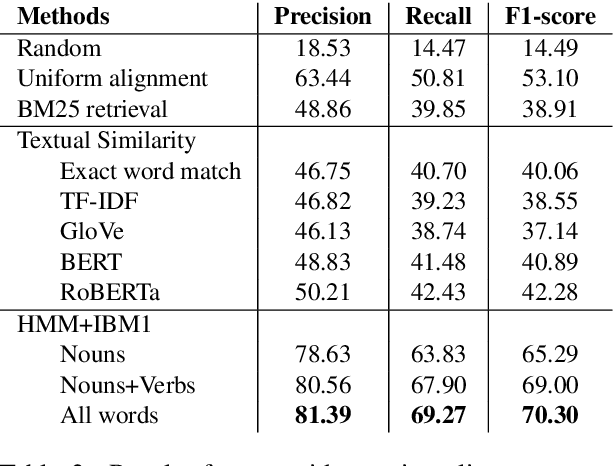
Unsupervised Common Question Generation from Multiple Documents using Reinforced Contrastive Coordinator
Nov 08, 2019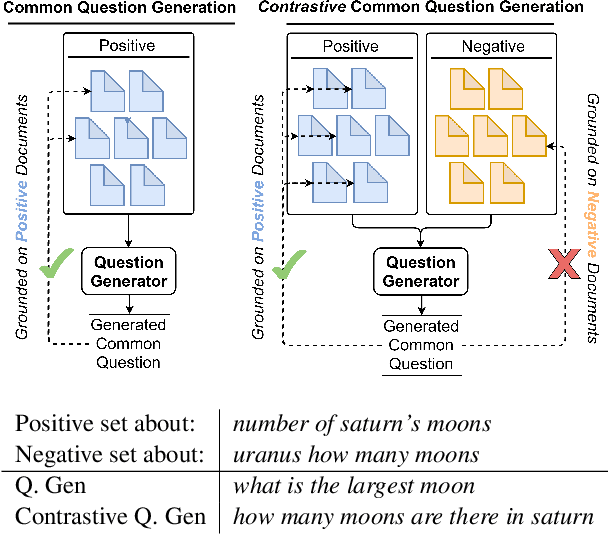
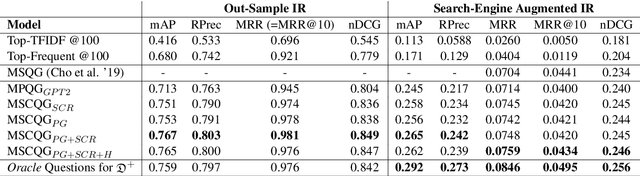
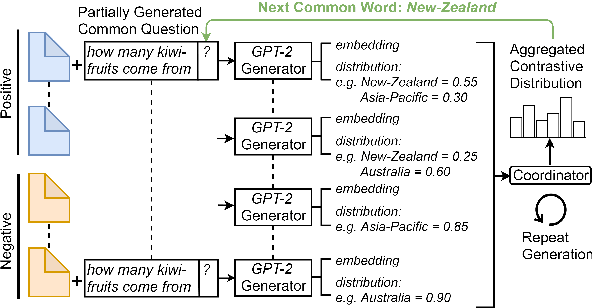
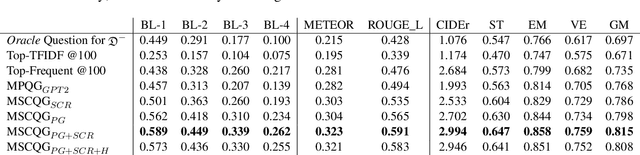
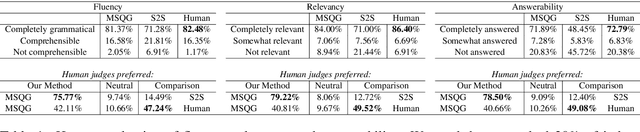
Web search engines today return a ranked list of document links in response to a user's query. However, when a user query is vague, the resultant documents span multiple subtopics. In such a scenario, it would be helpful if the search engine provided clarification options to the user's initial query in a way that each clarification option is closely related to the documents in one subtopic and is far away from the documents in all other subtopics. Motivated by this scenario, we address the task of contrastive common question generation where given a "positive" set of documents and a "negative" set of documents, we generate a question that is closely related to the "positive" set and is far away from the "negative" set. We propose Multi-Source Coordinated Question Generator (MSCQG), a novel coordinator model trained using reinforcement learning to optimize a reward based on document-question ranker score. We also develop an effective auxiliary objective, named Set-induced Contrastive Regularization (SCR) that draws the coordinator's generation behavior more closely toward "positive" documents and away from "negative" documents. We show that our model significantly outperforms strong retrieval baselines as well as a baseline model developed for a similar task, as measured by various metrics.
Generating a Common Question from Multiple Documents using Multi-source Encoder-Decoder Models
Oct 25, 2019
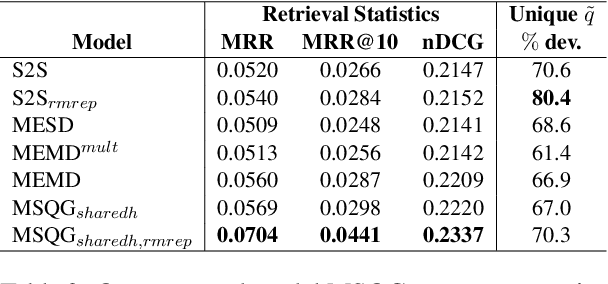
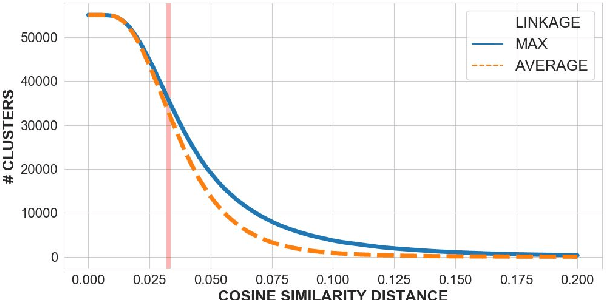
Ambiguous user queries in search engines result in the retrieval of documents that often span multiple topics. One potential solution is for the search engine to generate multiple refined queries, each of which relates to a subset of the documents spanning the same topic. A preliminary step towards this goal is to generate a question that captures common concepts of multiple documents. We propose a new task of generating common question from multiple documents and present simple variant of an existing multi-source encoder-decoder framework, called the Multi-Source Question Generator (MSQG). We first train an RNN-based single encoder-decoder generator from (single document, question) pairs. At test time, given multiple documents, the 'Distribute' step of our MSQG model predicts target word distributions for each document using the trained model. The 'Aggregate' step aggregates these distributions to generate a common question. This simple yet effective strategy significantly outperforms several existing baseline models applied to the new task when evaluated using automated metrics and human judgments on the MS-MARCO-QA dataset.
Answer-based Adversarial Training for Generating Clarification Questions
Apr 04, 2019


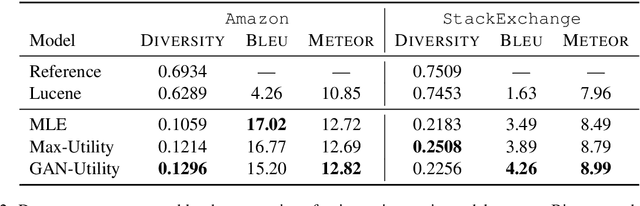
We present an approach for generating clarification questions with the goal of eliciting new information that would make the given textual context more complete. We propose that modeling hypothetical answers (to clarification questions) as latent variables can guide our approach into generating more useful clarification questions. We develop a Generative Adversarial Network (GAN) where the generator is a sequence-to-sequence model and the discriminator is a utility function that models the value of updating the context with the answer to the clarification question. We evaluate on two datasets, using both automatic metrics and human judgments of usefulness, specificity and relevance, showing that our approach outperforms both a retrieval-based model and ablations that exclude the utility model and the adversarial training.
Learning to Ask Good Questions: Ranking Clarification Questions using Neural Expected Value of Perfect Information
Jun 12, 2018
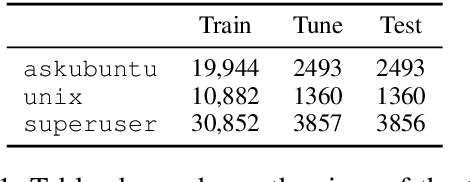
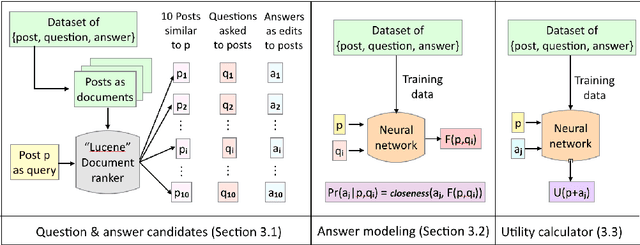
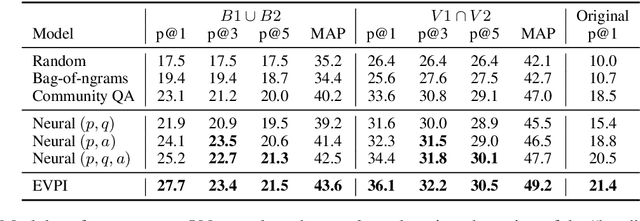
Inquiry is fundamental to communication, and machines cannot effectively collaborate with humans unless they can ask questions. In this work, we build a neural network model for the task of ranking clarification questions. Our model is inspired by the idea of expected value of perfect information: a good question is one whose expected answer will be useful. We study this problem using data from StackExchange, a plentiful online resource in which people routinely ask clarifying questions to posts so that they can better offer assistance to the original poster. We create a dataset of clarification questions consisting of ~77K posts paired with a clarification question (and answer) from three domains of StackExchange: askubuntu, unix and superuser. We evaluate our model on 500 samples of this dataset against expert human judgments and demonstrate significant improvements over controlled baselines.