 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetermining the utility of ultrafast nonlinear contrast enhanced and super resolution ultrasound for imaging microcirculation in the human small intestine
May 16, 2025The regulation of intestinal blood flow is critical to gastrointestinal function. Imaging the intestinal mucosal micro-circulation in vivo has the potential to provide new insight into the gut physiology and pathophysiology. We aimed to determine whether ultrafast contrast enhanced ultrasound (CEUS) and super-resolution ultrasound localisation microscopy (SRUS/ULM) could be a useful tool for imaging the small intestine microcirculation in vivo non-invasively and for detecting changes in blood flow in the duodenum. Ultrafast CEUS and SRUS/ULM were used to image the small intestinal microcirculation in a cohort of 20 healthy volunteers (BMI<25). Participants were imaged while conscious and either having been fasted, or following ingestion of a liquid meal or water control, or under acute stress. For the first time we have performed ultrafast CEUS and ULM on the human small intestine, providing unprecedented resolution images of the intestinal microcirculation. We evaluated flow speed inside small vessels in healthy volunteers (2.78 +/- 0.05 mm/s, mean +/- SEM) and quantified changes in the perfusion of this microcirculation in response to nutrient ingestion. Perfusion of the microvasculature of the intestinal mucosa significantly increased post-prandially (36.2% +/- 12.2%, mean +/- SEM, p<0.05). The feasibility of 3D SRUS/ULM was also demonstrated. This study demonstrates the potential utility of ultrafast CEUS for assessing perfusion and detecting changes in blood flow in the duodenum. SRUS/ULM also proved a useful tool to image the microvascular blood flow in vivo non-invasively and to evaluate blood speed inside the microvasculature of the human small intestine.
Integrating Deep Unfolding with Direct Diffusion Bridges for Computed Tomography Reconstruction
Sep 14, 2024



Computed Tomography (CT) is widely used in healthcare for detailed imaging. However, Low-dose CT, despite reducing radiation exposure, often results in images with compromised quality due to increased noise. Traditional methods, including preprocessing, post-processing, and model-based approaches that leverage physical principles, are employed to improve the quality of image reconstructions from noisy projections or sinograms. Recently, deep learning has significantly advanced the field, with diffusion models outperforming both traditional methods and other deep learning approaches. These models effectively merge deep learning with physics, serving as robust priors for the inverse problem in CT. However, they typically require prolonged computation times during sampling. This paper introduces the first approach to merge deep unfolding with Direct Diffusion Bridges (DDBs) for CT, integrating the physics into the network architecture and facilitating the transition from degraded to clean images by bypassing excessively noisy intermediate stages commonly encountered in diffusion models. Moreover, this approach includes a tailored training procedure that eliminates errors typically accumulated during sampling. The proposed approach requires fewer sampling steps and demonstrates improved fidelity metrics, outperforming many existing state-of-the-art techniques.
Adversarial Deep-Unfolding Network for MA-XRF Super-Resolution on Old Master Paintings Using Minimal Training Data
Sep 14, 2024High-quality element distribution maps enable precise analysis of the material composition and condition of Old Master paintings. These maps are typically produced from data acquired through Macro X-ray fluorescence (MA-XRF) scanning, a non-invasive technique that collects spectral information. However, MA-XRF is often limited by a trade-off between acquisition time and resolution. Achieving higher resolution requires longer scanning times, which can be impractical for detailed analysis of large artworks. Super-resolution MA-XRF provides an alternative solution by enhancing the quality of MA-XRF scans while reducing the need for extended scanning sessions. This paper introduces a tailored super-resolution approach to improve MA-XRF analysis of Old Master paintings. Our method proposes a novel adversarial neural network architecture for MA-XRF, inspired by the Learned Iterative Shrinkage-Thresholding Algorithm. It is specifically designed to work in an unsupervised manner, making efficient use of the limited available data. This design avoids the need for extensive datasets or pre-trained networks, allowing it to be trained using just a single high-resolution RGB image alongside low-resolution MA-XRF data. Numerical results demonstrate that our method outperforms existing state-of-the-art super-resolution techniques for MA-XRF scans of Old Master paintings.
Enhancing super-resolution ultrasound localisation through multi-frame deconvolution exploiting spatiotemporal coherence
Jul 08, 2024Super-resolution ultrasound imaging through microbubble (MB) localisation and tracking, also known as ultrasound localisation microscopy, allows non-invasive sub-diffraction resolution imaging of microvasculature in animals and humans. The number of MBs localised from the acquired contrast-enhanced ultrasound (CEUS) images and the localisation precision directly influence the quality of the resulting super-resolution microvasculature images. However, non-negligible noise present in the CEUS images can make localising MBs challenging. To enhance the MB localisation performance, we propose a Multi-Frame Deconvolution (MF-Decon) framework that can exploit the spatiotemporal coherence inherent in the CEUS data, with new spatial and temporal regularisers designed based on total variation (TV) and regularisation by denoising (RED). Based on the MF-Decon framework, we introduce two novel methods: MF-Decon with spatial and temporal TVs (MF-Decon+3DTV) and MF-Decon with spatial RED and temporal TV (MF-Decon+RED+TV). Results from in silico simulations indicate that our methods outperform two widely used methods using deconvolution or normalised cross-correlation across all evaluation metrics, including precision, recall, $F_1$ score, mean and standard localisation errors. In particular, our methods improve MB localisation precision by up to 39% and recall by up to 12%. Super-resolution microvasculature maps generated with our methods on a publicly available in vivo rat brain dataset show less noise, better contrast, higher resolution and more vessel structures.
Enhanced Generative Recommendation via Content and Collaboration Integration
Mar 27, 2024Generative recommendation has emerged as a promising paradigm aimed at augmenting recommender systems with recent advancements in generative artificial intelligence. This task has been formulated as a sequence-to-sequence generation process, wherein the input sequence encompasses data pertaining to the user's previously interacted items, and the output sequence denotes the generative identifier for the suggested item. However, existing generative recommendation approaches still encounter challenges in (i) effectively integrating user-item collaborative signals and item content information within a unified generative framework, and (ii) executing an efficient alignment between content information and collaborative signals. In this paper, we introduce content-based collaborative generation for recommender systems, denoted as ColaRec. To capture collaborative signals, the generative item identifiers are derived from a pretrained collaborative filtering model, while the user is represented through the aggregation of interacted items' content. Subsequently, the aggregated textual description of items is fed into a language model to encapsulate content information. This integration enables ColaRec to amalgamate collaborative signals and content information within an end-to-end framework. Regarding the alignment, we propose an item indexing task to facilitate the mapping between the content-based semantic space and the interaction-based collaborative space. Additionally, a contrastive loss is introduced to ensure that items with similar collaborative GIDs possess comparable content representations, thereby enhancing alignment. To validate the efficacy of ColaRec, we conduct experiments on three benchmark datasets. Empirical results substantiate the superior performance of ColaRec.
A Fast Automatic Method for Deconvoluting Macro X-ray Fluorescence Data Collected from Easel Paintings
Oct 31, 2022Macro X-ray Fluorescence (MA-XRF) scanning is increasingly widely used by researchers in heritage science to analyse easel paintings as one of a suite of non-invasive imaging techniques. The task of processing the resulting MA-XRF datacube generated in order to produce individual chemical element maps is called MA-XRF deconvolution. While there are several existing methods that have been proposed for MA-XRF deconvolution, they require a degree of manual intervention from the user that can affect the final results. The state-of-the-art AFRID approach can automatically deconvolute the datacube without user input, but it has a long processing time and does not exploit spatial dependency. In this paper, we propose two versions of a fast automatic deconvolution (FAD) method for MA-XRF datacubes collected from easel paintings with ADMM (alternating direction method of multipliers) and FISTA (fast iterative shrinkage-thresholding algorithm). The proposed FAD method not only automatically analyses the datacube and produces element distribution maps of high-quality with spatial dependency considered, but also significantly reduces the running time. The results generated on the MA-XRF datacubes collected from two easel paintings from the National Gallery, London, verify the performance of the proposed FAD method.
Beyond Keywords and Relevance: A Personalized Ad Retrieval Framework in E-Commerce Sponsored Search
Apr 23, 2018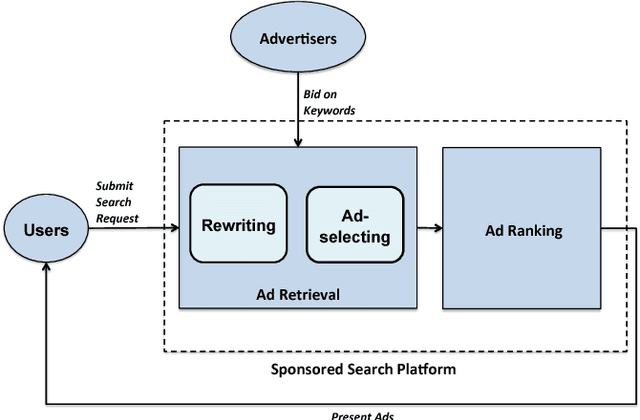

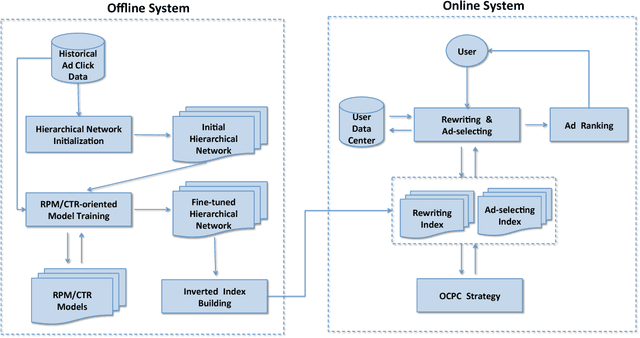
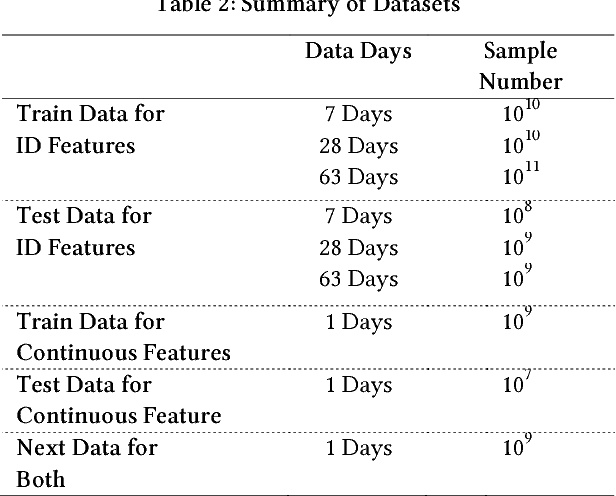
On most sponsored search platforms, advertisers bid on some keywords for their advertisements (ads). Given a search request, ad retrieval module rewrites the query into bidding keywords, and uses these keywords as keys to select Top N ads through inverted indexes. In this way, an ad will not be retrieved even if queries are related when the advertiser does not bid on corresponding keywords. Moreover, most ad retrieval approaches regard rewriting and ad-selecting as two separated tasks, and focus on boosting relevance between search queries and ads. Recently, in e-commerce sponsored search more and more personalized information has been introduced, such as user profiles, long-time and real-time clicks. Personalized information makes ad retrieval able to employ more elements (e.g. real-time clicks) as search signals and retrieval keys, however it makes ad retrieval more difficult to measure ads retrieved through different signals. To address these problems, we propose a novel ad retrieval framework beyond keywords and relevance in e-commerce sponsored search. Firstly, we employ historical ad click data to initialize a hierarchical network representing signals, keys and ads, in which personalized information is introduced. Then we train a model on top of the hierarchical network by learning the weights of edges. Finally we select the best edges according to the model, boosting RPM/CTR. Experimental results on our e-commerce platform demonstrate that our ad retrieval framework achieves good performance.